人類程序員,最晚2031年下崗?
讓智能體先通往AGI,已經成為共識。OpenAI連番推出昂貴的新功能,o1-Pro比普通版貴了10倍,比R1貴了上百倍。Grok則悄悄上線了DeeperSearch。讓它們率先替代碼農和研究員,似乎正在成為大模型兌現商業價值最現實的方向;其他行業可以踩在他們的肩上。
也許人類員工可以稍微鬆口氣。儘管今年Meta和微軟再次開啟大規模裁員,但被裁的都是績效考核不如人類同事的。被AI智能體同事大面積地頂替下去,至少要到2028年,更可能是2031年。
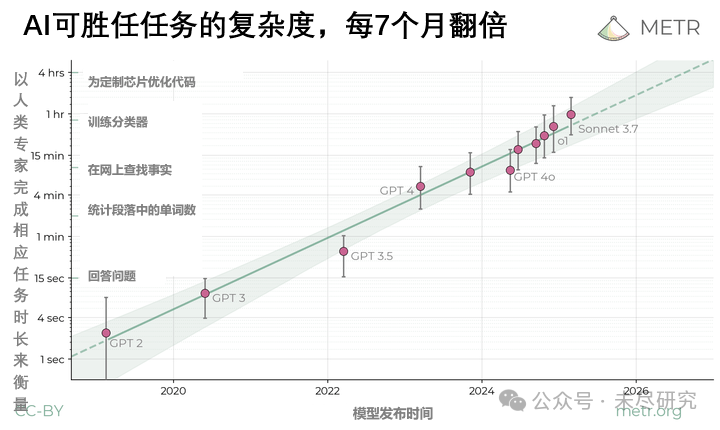
如果有一個智能體的「摩亞定律」,用來衡量智能體所能解決的任務的複雜程度——以人類專家完成相同任務所需時長來量化——為人類完成工作所節省的時間越來越長,準確率越來越高,這個摩亞定律,終有一天會通向完全替代人類完成複雜問題。
最近,研究機構METR發現,目前的智能體,還沒辦法替代人類,去完成那些本該人類花1小時以上的時間才能完成的軟件任務。不過,智能體解決複雜任務的能力在進步,相當於為人類專家節省的時間,平均每7個月翻一番。2028年後,它們就有50%的成功率,完成人類本該在1個月內(約160工作時)完成的任務了。
這與最近OpenAI和Anthropic的說法不同,從奧特曼到阿莫迪,都在說今年內智能體編程可以勝過人類。但研究認為,AI只能勝任人類不用4分鐘就能完成的任務,也就是說最簡單的任務。
METR(模型評估與風險研究)是美國人工智能安全研究所聯盟(AISIC)的成員機構,為OpenAI、Anthropic等提供部署前的非正式評估。創始人Beth Barnes之前在OpenAI研究對齊問題,「圖靈三巨頭」之一的本吉奧(Yoshua Bengio)是該機構顧問。
為什麼從1個月算起?這家機構解釋說,那是新員工入職後可以為公司創造經濟價值的時間。當前,各種大模型的測試基準正在迅速飽和,更要命的是,它無法準確反映真實社會經濟價值。
不滿於此,METR提出了HCAST(人類校準自主軟件任務)。這是一個包含189項機器學習工程、網絡安全、軟件工程和一般推理任務的基準測試集,分別由人類專家(擁有全球排名前100大學學位,具有5年以上相關專業經驗)與智能體去執行。人類專家與智能體在相同的條件下工作,然後再比一比,人類完成這些任務需要多少時間,智能體完成這些任務的成功率有多高。HCAST的任務主要覆蓋了數分鐘到幾小時的人類任務,為覆蓋需要更短(對應早期大模型)與更長時間的任務,研究又引入了單步任務SWAA與長時任務RE-Bench。
結論是,人類專家耗時不到4分鐘的任務,目前的智能體幾乎100%都能成功;但是連人類專家都要耗時4個小時以上的,那麼成功率就降到了10%以下。不過,智能體的進步也很顯著。GPT-3時代的模型,在超過1分鐘任務上全部失敗;GPT-4能以50%的成功率完成4分鐘的任務;Claude 3.7 Sonnet在相同的成功率下,把上限推高到了59分鐘,但要提升到80%成功率,就只能完成15分鐘左右的任務。
簡言之,把它們放到真實世界,想要完全自主地完成多步驟長時序的現實任務,還不夠穩定和好用。也就是說,至少在今年內,不能對智能體完成多步驟的任務抱有太高的預期。
前EleutherAI研究員Herbie Bradley大量試用了Operator和Anthropic的computer-use後,非常認同METR這種簡單的衡量方法。他認為「t-AGI」(智能體能夠自主可靠地完成本該由人類t時間內完成的任務)的擴展,是評估AGI經濟效用的重要標準。
METR發現,如果以50%的成功率為基準,那麼,過去6年來前沿大模型的t-AGI平均每7個月翻倍。遵循這個趨勢,到2027年或2028年左右,智能體有50%的成功率完成人類本該1個月完成的任務。會有僱主去使用這樣的智能體省下一名碼農的月薪成本嗎?
但是,現實情況會更複雜,且追求更高的成功率,如果要讓智能體真正自主做到這一切,METR認為更可能是2031年前。
但是,即使這一天還沒有來臨,矽谷的碼農也該瑟瑟發抖了。如果將GoogleL4級別的工程師的平均年薪,除以每年2000小時,則每小時薪酬約144美元。目前超過80%由智能體成功完成的任務,它們的推理成本低於人類專家的10%;它們在本該由人類專家在30秒內完成的任務上,性價比顯著。幸虧目前的智能體,想要完成現實世界的任務,尤其是長時序任務,還離不開人類留在整個工作循環中。
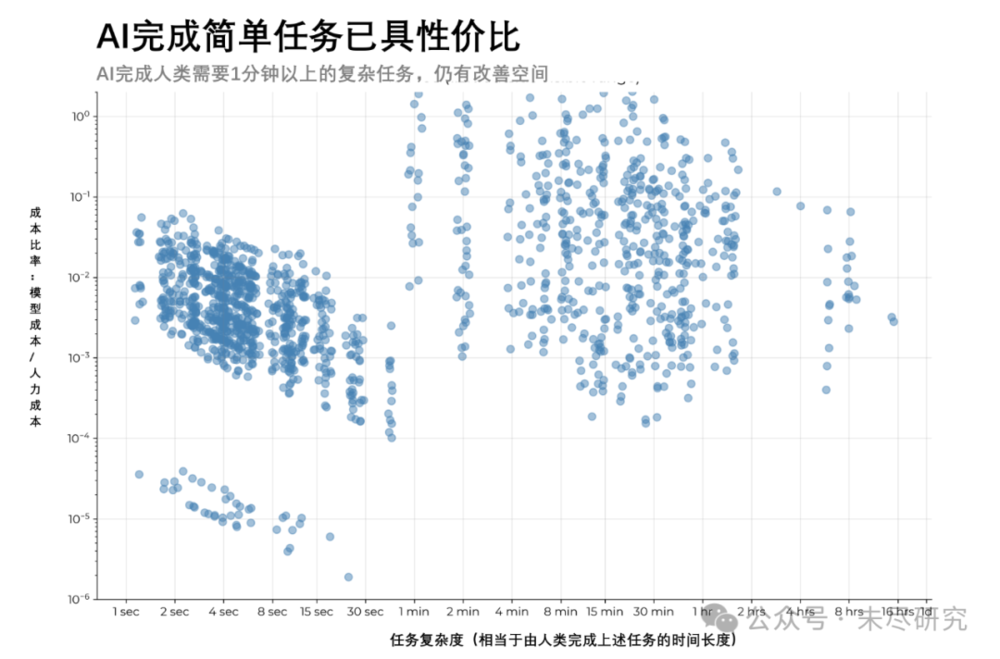
(說明:對應1460個成功完成的任務,縱坐標代表任務的複雜度,即人類完成該任務的時長,橫坐標代表任務由智能體完成任務的性價比,即模型成本與人類薪酬的比例。)
今年,卡帕西(Andrej Karpathy)就已經很享受了Vibe coding了,即一種依靠直覺和創意用自然語言調動代碼的編程方式。他只需要偶爾花點時間通讀一下他一時間沒看懂的代碼;有時候針對模型無法自己解決的Bug,動手修改一下。
但是,也許對智能體來說,更重要的是通過類似Vibe coding趨勢,幾乎削平了必須構築於編程之上的其他領域的陡峭的初始學習曲線。Google最新的人形機器人通用模型Gemini Robotics-ER,也是通過現場寫代碼來完成物理世界任務的。
R1落後4個月
METR在論文中測試的模型,幾乎都來自它的合作方OpenAI與Anthropic。不過,該機構也額外測試了基於第三方託管的DeepSeek的V3與R1等模型。研究也承認可能自己沒有完全激發R1的最高性能。
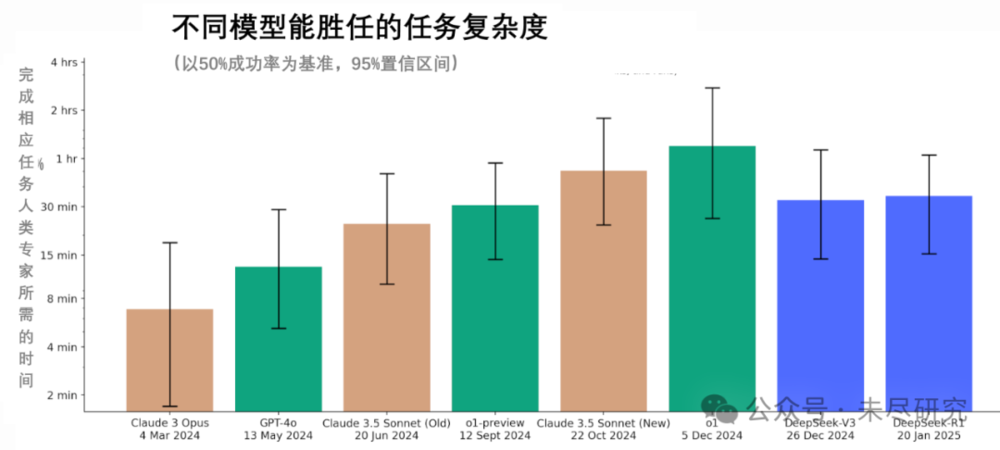
在測試中,DeepSeek-R1能夠以50%的成功率,完成人類專家需要35分鐘才能完成的任務,略高於V3的33分鐘的成績,低於早於其發佈的新版Claude 3.5 Sonnet和o1模型。從這個基準上看,R1大概處於全球最前沿的大模型在9月份時的水平,差距約為4個月。
該機構還發現,在引入思維鏈後,DeepSeek旗下基礎模型V3到推理模型R1,對完成人類任務時長的提升,跨度不及OpenAI從GPT-4o到o1-preview。
也許要等R2發佈的時候再試試,在追求性價比的同時,中國企業能否把t-AGI的提升速度也一起擴展了。
參考論文:
Measuring AI Ability to Complete Long Tasks
HCAST:Human-Calibrated Autonomy Software Tasks