IEEE TPAMI 2025 | 從像素到像素:一種全新的零樣本圖像去噪方法
作者丨CSJJJ@知乎(已授權)
來源丨https://zhuanlan.zhihu.com/p/27397737911
編輯丨極市平台
提出一種全新的從像素到像素(Pixel2Pixel)零樣本圖像去噪方法,借鑒傳統Non-Local Means方法深度挖掘圖像的自相似性,構建像素庫(Pixel Bank),在此基礎上利用隨機采樣策略生成大量偽實例(噪聲樣本圖像),最終實現高效零樣本圖像去噪。此外,理論證明了提出方法的有效性和對噪聲的泛化能力。

論文地址: Pixel2Pixel: A Pixelwise Approach for Zero-shot Single Image Denoising
項目地址:https://github.com/qingma2016/Pixel2Pixel
1. 引言
近年來,基於深度學習的方法憑藉其卓越性能主導了圖像去噪領域。監督學習方法通過大規模成對數據集訓練網絡,取得了最佳效果,但其對噪聲-乾淨或噪聲-噪聲圖像對的依賴導致數據收集耗時且複雜。為緩解這一問題,自監督去噪方法通過挖掘噪聲圖像內部監督信號,避免了乾淨數據的需求,但仍需大量訓練圖像,且對真實噪聲的泛化能力不足,尤其面對未知噪聲類型時性能顯著下降。
進一步減少數據依賴的零樣本方法成為研究熱點。這類方法聚焦於單張噪聲圖像生成訓練對及高效網絡設計,例如通過添加隨機噪聲或下采樣構造數據,並採用U-Net等輕量架構。然而,現有方法存在明顯局限:一方面,基於像素獨立噪聲假設的模型難以應對真實噪聲的空間相關性(由圖像信號處理器引入);另一方面,數據生成策略過度依賴局部平滑性假設(如Neighbor2Neighbor的鄰域相似性、Noise2Fast的方向性約束),忽略了自然圖像中廣泛存在的非局部自相似性——即圖像中重復出現的相似結構塊。這種局限性導致傳統方法在真實噪聲場景下性能受限。
 圖1 不同的圖像去噪方法框架。
圖1 不同的圖像去噪方法框架。針對上述挑戰,本文提出Pixel2Pixel,一種創新性零樣本去噪框架,其核心貢獻體現在理論與方法兩方面:
理論層面:我們首次證明,在Noise2Noise範式下,全局最小化器本質上是條件風險最小化器。這一發現表明,統計模式可在比整圖更微觀的層面被捕捉,且通過選擇合適的損失函數(如基於噪聲統計特性的L1或Huber損失),可等效實現Noise2Clean式的優化目標,為無監督學習提供了新的理論支撐。
方法層面:提出兩大核心技術:
非局部像素庫構建:通過大範圍滑動窗口搜索相似像素,聚合圖像全局自相似性,形成冗餘特徵庫。相較於傳統方法局限於較小鄰域或固定方向采樣,該方法能夠挖掘非局部的結構相似性(如建築物紋理、生物顯微結構的重覆模式),為噪聲抑制提供豐富先驗。
像素級隨機采樣策略:從像素庫中隨機選擇不連續位置像素生成偽訓練對。該策略通過空間置換打破噪聲的空間相關性,同時保留真實信號的非局部一致性。例如,在顯微圖像中,隨機采樣可有效分離螢光噪聲的空間關聯性,提升去噪信噪比。
2. 方法
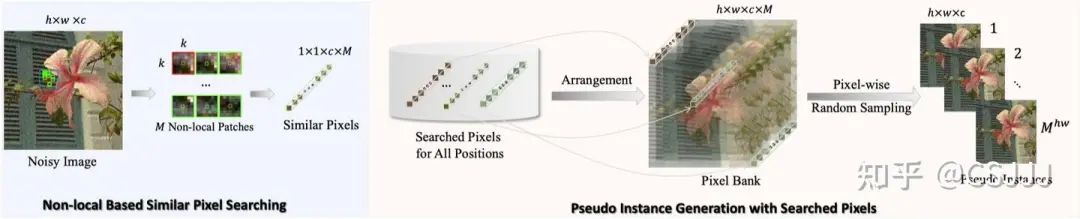 圖2 提出的Pixel2Pixel框架概述。左側:基於非局部的相似像素搜索。右側:使用搜索得到的像素生成偽實例。
圖2 提出的Pixel2Pixel框架概述。左側:基於非局部的相似像素搜索。右側:使用搜索得到的像素生成偽實例。2.1 像素點搜索
我們方法構建訓練樣本的主要思想如圖2所示。給定一個噪聲圖像,對於中的每個像素,我們提取一個局部塊,並在的足夠大窗口內搜索個與相似的非局部塊。考慮到噪聲的多樣化統計特性,我們選擇適當的距離來衡量塊的相似性。特別地,對於零均值噪聲,我們使用距離;對於非零均值噪聲中佔主導地位的乾淨像素,我們使用距離。在對非局部塊進行排名後,我們從每個塊中提取中心像素,創建一個張量。這種技術旨在利用圖像的NSS先驗,尋找與相似但不同的像素。直接使用進行搜索可能會得到相同的像素匹配,無法為網絡訓練提供新信息。通過對中所有像素重覆此過程,我們生成了一個張量,稱為「像素庫」。
2.2 像素點采樣
構建像素庫後,我們能夠使用逐像素隨機采樣策略抽取大量樣本(總共個),我們稱之為「偽實例」。這種方法在防止網絡過度擬合方面非常有效。在每次訓練迭代中,網絡隨機抽取一對(總共有對,對於每個空間位置,我們確保兩次采樣的像素不同)進行訓練。在創建偽實例對時,Pixel2Pixel打亂了噪聲圖像中像素的原始空間排列。這個過程不限於鄰近像素形成對,有助於減少真實噪聲圖像中鄰近像素間噪聲的空間相關性。這種策略顯著增強了該算法在真實世界噪聲圖像上的去噪效果。
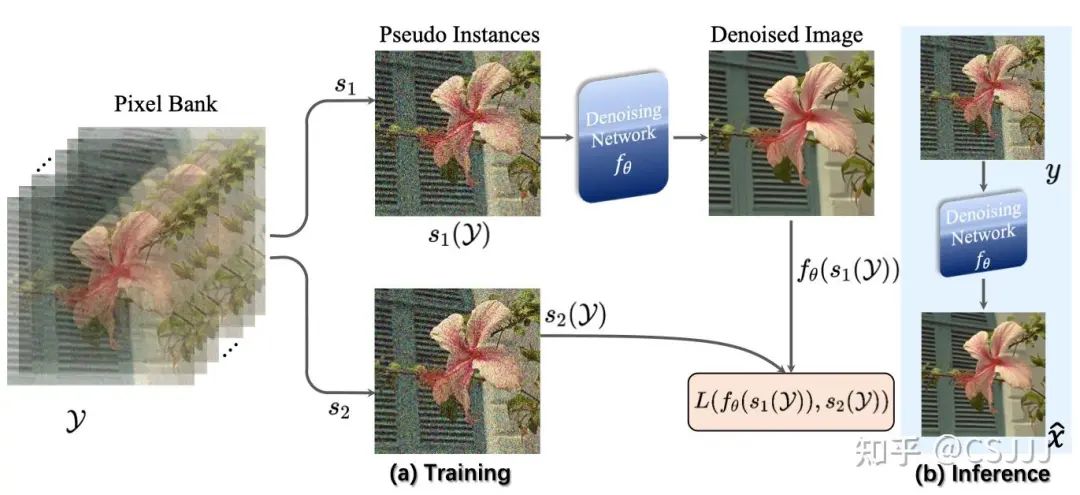
圖3 網絡訓練和推理。(a) 網絡訓練:在每次迭代之前,我們通過逐像素隨機采樣從像素庫中抽取兩個偽實例和進行網絡訓練。(b) 網絡推理:使用訓練好的去噪網絡和原始噪聲圖像進行推理。
2.3 網絡訓練
接下來,我們詳細介紹我們的網絡架構、訓練方案和使用的損失函數。我們的神經網絡使用一個簡單的CNN架構,包含五層,每層的卷積有64個通道,每個卷積層後面跟著一個leaky ReLU激活層。在最後一層,我們使用的卷積。值得注意的是,我們的網絡設計省略了殘差連接,並避免使用殘差損失,因為這會導致性能下降。
如圖3所示,在我們的網絡訓練過程中,我們不使用噪聲圖像作為固定輸入,而是在每次迭代中隨機從像素庫中抽取兩個偽實例作為輸入和輸出。這種增加樣本隨機性的方法顯著提高了網絡性能。與以前的方法如Neighbour2Neighbour或ZS-N2N不同,我們的訓練樣本可能有對應像素在噪聲圖像中位置更遠。我們根據噪聲的統計特性選擇合適的損失函數。具體來說,對於零均值噪聲,我們使用損失,而對於非零均值噪聲中佔主導地位的乾淨像素,我們使用損失。
3. 實驗
3.1 合成噪聲
零均值噪聲: 在表1中,我們展示了不同方法的去噪性能。值得注意的是,BM3D需要輸入特定的噪聲水平。對於高斯噪聲,我們直接輸入實際噪聲水平,而對於泊鬆噪聲,我們使用基於估計的噪聲水平。對於零樣本方法,傳統方法BM3D在已知噪聲水平(高斯)下表現優秀,但在未知噪聲水平(泊鬆)下效果減弱。對於基於深度學習的方法,DIP遠遠落後於其它方法,而S2S在較高噪聲水平下表現出色,儘管其成功很大程度上依賴於其集成策略,這往往會導致圖像過度平滑。ZS-N2N在較低噪聲水平下表現良好,但在較高噪聲水平下性能顯著下降,這是由於其降采樣策略在訓練和測試圖像之間造成的噪聲水平不匹配。相比之下,我們的Pixel2Pixel方法在大多數情況下始終實現最佳或接近最佳的性能,突顯出最為穩健的選擇。在圖4中,我們展示了不同方法在高斯噪聲上的去噪效果。
 圖4 在Kodak24 數據集上高斯去噪的實驗結果。上中下的噪聲等級分別為10、25和50。
圖4 在Kodak24 數據集上高斯去噪的實驗結果。上中下的噪聲等級分別為10、25和50。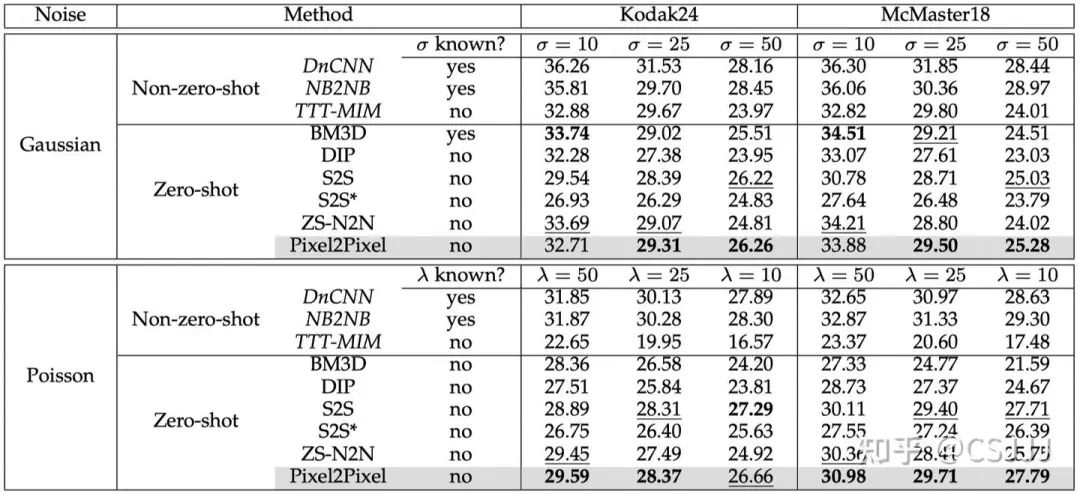
表1 高斯噪聲和泊鬆噪聲在Kodak24和McMaster18數據集上的平均峰值信噪比(PSNR)。最佳和次佳結果分別以粗體和下劃線表示。
乾淨像素佔主導的非零均值噪聲: 我們主要考慮三種不同類型的非零均值噪聲:伯努利噪聲、椒鹽噪聲和脈衝噪聲。在處理以乾淨像素為主的非零均值噪聲時,我們採用損失函數。為了保持公平比較,我們也將其他方法的損失函數調整為它們各自的變體。如表2中所示,ZS-N2N在處理非零均值噪聲時遇到困難。這個限制來源於它的方法,在原始噪聲圖像中的區域內沿主對角線和反對角線平均像素以創建降采樣對。這種方法無意中改變了噪聲的性質,影響了去噪效果。例如,在椒鹽噪聲的情況下,這種降采樣技術會將值為0和1的噪聲像素轉換為中間值。另一方面,S2S在處理伯努利噪聲方面表現出色,這歸功於其訓練過程中涉及通過伯努利采樣原始噪聲圖像生成圖像。我們的Pixel2Pixel方法在處理椒鹽噪聲和脈衝噪聲方面達到了最佳性能。在圖5中,我們展示了用於非零均值噪聲去除的去噪圖像的定性比較。結果清楚地表明,我們的方法在所有測試方法中提供了有競爭力的視覺質量。值得注意的是,對於伯努利噪聲,儘管S2S方法獲得了更高的PSNR分數,但由於它是50個網絡測試結果的平均值,出現了過度平滑的問題。

圖5 非零均值噪聲去除的視覺結果。上圖:在Kodak24的「img04」圖像上進行伯努利去噪,噪聲概率為。下圖:在McMaster18的「im13」圖像上進行脈衝去噪,噪聲概率為。
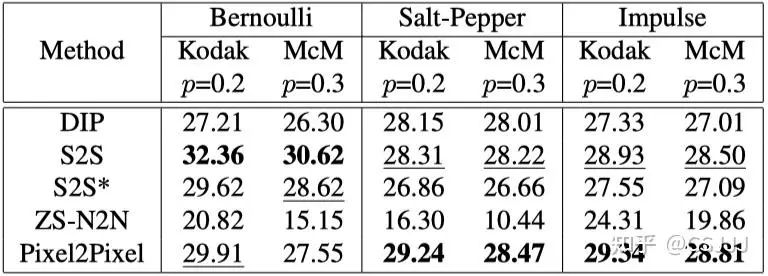 表2 伯努利噪聲、椒鹽噪聲和脈衝噪聲在Kodak24和McMaster18數據集上的平均峰值信噪比(PSNR)得分。
表2 伯努利噪聲、椒鹽噪聲和脈衝噪聲在Kodak24和McMaster18數據集上的平均峰值信噪比(PSNR)得分。3.2 真實噪聲
相機噪聲: 我們在PolyU數據集和SIDD數據集上進行評估。對於每個數據集,我們並從每張圖像的中心提取一個的區域。不同方法在處理真實相機噪聲方面的去噪性能總結在表3中。與合成噪聲不同,在處理真實相機噪聲方面,DIP的表現優於S2S和ZS-N2N。我們的方法在兩個數據集上都取得了最佳性能。這歸功於S2S、ZS-N2N和我們的方法都基於不同像素點噪聲獨立的假設。然而,真實噪聲圖像中相鄰像素的噪聲總是顯示出相關性,這在S2S和ZS-N2N算法的設計中沒有考慮到。相比之下,我們的方法從非局部塊的中心像素創建像素庫,並從像素庫中隨機抽樣形成偽實例,有效地打破了噪聲的空間相關性。在圖6中,我們提供了去噪圖像在相機噪聲去除方面的定性比較。結果顯示,儘管原始噪聲圖像中的噪聲不強烈,S2S和ZS-N2N仍導致圖像質量受損。這種不足源於它們依賴噪聲獨立的假設,忽略了真實圖像中噪聲的固有空間相關性。在構建訓練數據時的這種疏忽導致它們在處理真實相機噪聲方面的效果降低。顯然,我們的方法脫穎而出,取得了優越的主觀和客觀結果。
 表3 真實相機噪聲去噪的實驗結果
表3 真實相機噪聲去噪的實驗結果 圖6 我們的方法與其它對比方法在真實世界PloyU數據集的一個樣本上的視覺比較。
圖6 我們的方法與其它對比方法在真實世界PloyU數據集的一個樣本上的視覺比較。顯微鏡噪聲: 我們還使用螢光顯微數據集(FMD)來評估比較方法在顯微鏡噪聲上的性能。FMD數據集由使用商業共聚焦、雙光子和寬場顯微鏡拍攝的圖像組成,這些顯微鏡對細胞、斑馬魚和小鼠腦組織等代表性生物樣本進行成像。我們選擇三個類別進行測試:光子BPAE、光子Mice和共聚焦BPAE,每個類別包含20張圖像。表4中顯示了不同方法的結果,我們的方法在各個類別中和平均所有類別中都達到了最佳性能,取得了顯著的提升。
 表4 真實顯微噪聲去噪的實驗結果
表4 真實顯微噪聲去噪的實驗結果3.3 計算複雜度
我們比較了零樣本去噪方法的計算效率。表5詳細說明了使用不同方法對Kodak24數據集中單張圖像進行去噪所需的平均時間,以及網絡參數和PSNR分數。值得注意的是,對於BM3D,我們報告的是CPU運行時間,而基於深度學習的方法報告的是GPU運行時間。表格顯示,在所有基於深度學習的方法中,ZS-N2N具有最少的參數數量和最短的計算時間,但其性能較差。另一方面,S2S方法在去噪質量方面表現出高性能,但代價是顯著的計算資源消耗,使其在處理時間和資源利用方面成為較低效的選擇。Pixel2Pixel方法作為一個強大的解決方案,實現了高質量性能和計算效率之間的令人稱讚的平衡。其網絡參數和計算時間略高於ZS-N2N,但在去噪能力方面顯著優於後者。這使Pixel2Pixel成為在性能和效率都受重視的場景中的最佳選擇。
 表5 不同方法的計算效率、網絡參數和PSNR。
表5 不同方法的計算效率、網絡參數和PSNR。4. 結論
本文提出了Pixel2Pixel,一種零樣本去噪方法,不需要除噪聲圖像本身之外的任何額外訓練數據。通過為每個像素點搜索相似像素(基於塊評估相似性),我們構建了一個像素庫。然後通過逐像素隨機采樣生成訓練樣本。構建像素庫並通過從像素庫中逐像素隨機采樣生成訓練圖像可以減少相鄰像素間噪聲的空間相關性,從而增強算法處理真實世界噪聲圖像的能力。我們使用了一個只有五層的網絡,使訓練過程非常快。廣泛的實驗表明,Pixel2Pixel的性能超過了現有的基於深度學習的零樣本去噪方法,特別是在存在真實相機噪聲和真實顯微鏡噪聲的情況下。