OpenAI 發佈新一代語音模型,讓 AI 智能體語音表達更自然
IT之家 3 月 21 日消息,OpenAI 昨日(3 月 20 日)發佈博文,宣佈推出語音轉文本(speech-to-text)和文本轉語音(text-to-speech)模型,提升語音處理能力,支持開發者構建更精準、可定製的語音交互系統,進一步推動人工智能語音技術的商業化應用。
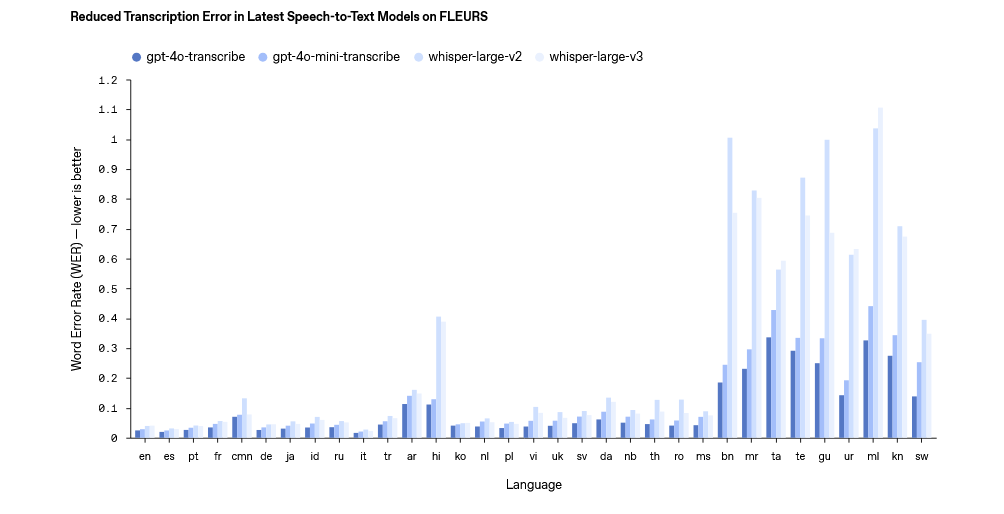
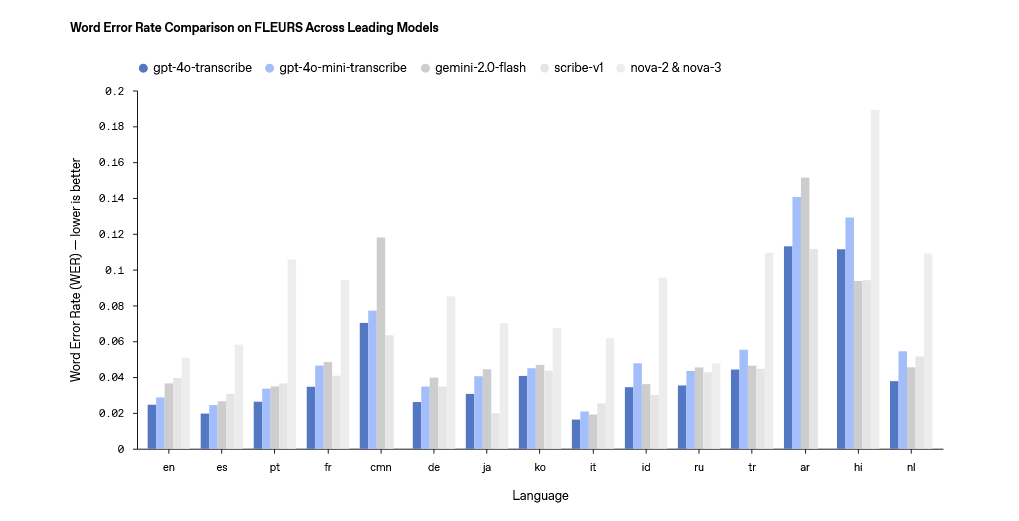
在語音轉文本模型上,OpenAI 主要推出了 gpt-4o-transcribe 和 gpt-4o-mini-transcribe 兩個模型,官方表示在單詞錯誤率(WER)、語言識別和準確性上超越現有 Whisper 系列。
這兩個模型支持超 100 種語言,主要通過強化學習和多樣化高質量音頻數據集訓練,能捕捉細微語音特徵,減少誤識別,尤其在嘈雜環境、口音及不同語速下表現更穩定。
在文本轉語音上,OpenAI 最新推出了 gpt-4o-mini-tts 模型,開發者通過「模擬耐性客服」或「生動故事敘述」等指令,控制語音風格,可以應用於客服(合成更具同理心的語音,提升用戶體驗)和創意內容(為有聲書或遊戲角色設計個性化聲音)方面。
IT之家援引博文介紹,附上三款模型費用如下:
-
gpt-4o-transcribe:音頻輸入每 100 萬 tokens 費用 6 美元、文本輸入每 100 萬 tokens 費用 2.5 美元,輸出每 100 萬 tokens 費用 10 美元,每分鐘成本 0.6 美分。
-
gpt-4o-mini-transcribe:音頻輸入每 100 萬 tokens 費用 3 美元、文本輸入每 100 萬 tokens 費用 1.25 美元,輸出每 100 萬 tokens 費用 5 美元,每分鐘成本 0.3 美分。
-
gpt-4o-mini-tts:每 100 萬 tokens 輸入費用為 0.60 美元,每 100 萬 tokens 輸出費用為 12 美元,每分鐘成本 1.5 美分。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。