Nature發文「智能體摩亞定律」,Agent能力每7個月翻倍,5年後能頂人類苦幹一個月的工作
一水 發自 凹非寺
量子位 | 公眾號 QbitAI
AI Agents(智能體)也有自己的「摩亞定律」了?!
就在最近,Nature報導了一項來自非營利研究機構METR的最新發現:
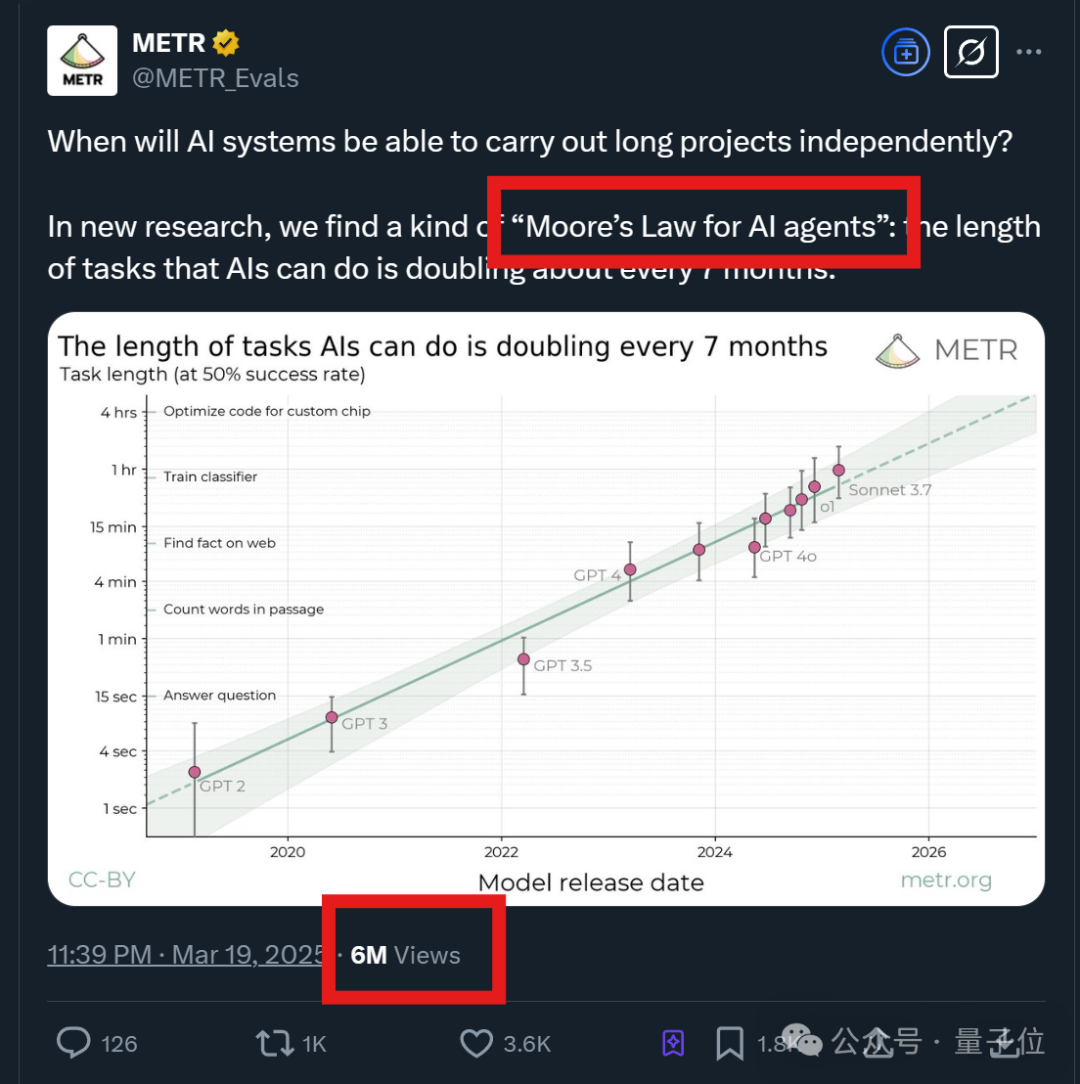
AI在完成長期任務方面的進步速度驚人,其時間跨度大約每七個月翻一番。
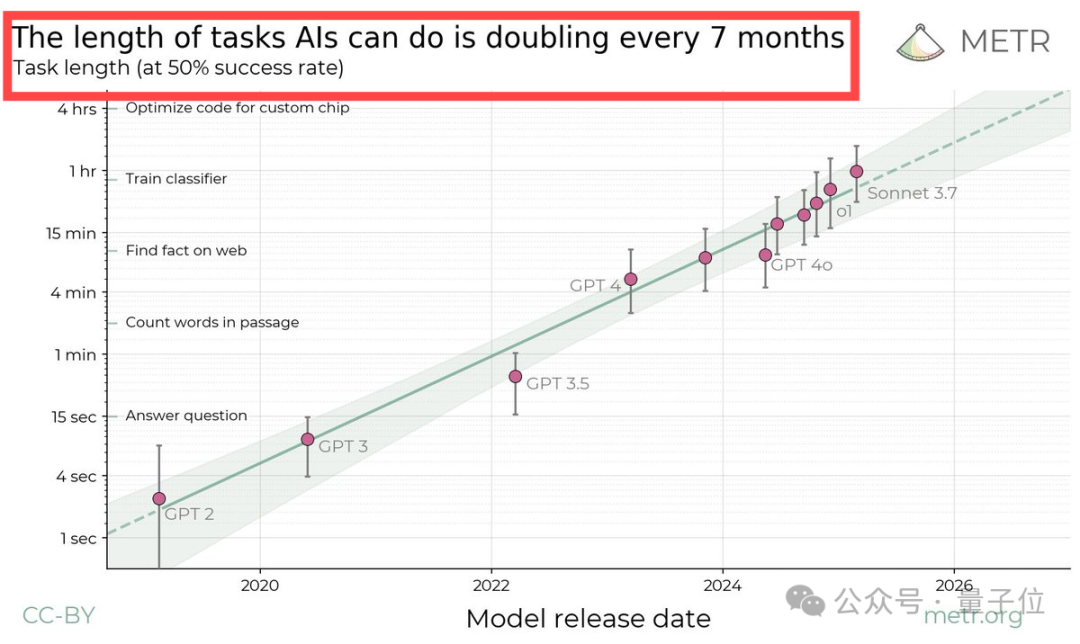
為了衡量Agent自動完成任務的能力變化,研究人員提出了「50%-任務完成時間跨度(50%-task-completion time horizon)」這一指標。
他們以50%任務成功率為基準,假設2019年AI達到這一目標所需時間對應人類需要的時間為10分鐘,那麼7個月後,其對應的人類完成任務時間則變成了20分鐘。
換句話說,AI能夠勝任越來越多人工耗時久的任務,能力逐漸更強。

2024年這一增長速度變得更快了,一些最新模型大約每三個月翻一番。
按照預測,大約五年後,AI就能自動完成很多人類現在要花一個月才能完成的任務。
網民們紛紛表示,這下終於對AI進步神速有實感了!
提出「50%-任務完成時間跨度」指標
在METR的介紹中,他們將這一發現命名為「Moore’s Law for AI agents」,也就是「智能體摩亞定律」。
下面我們詳細展開其研究方法。
整體而言,他們主要是讓AI和一些專業人員在相似條件下嘗試完成任務,然後測量人類所需要的時間,最終來比較AI成功率如何隨著人類完成時間的長短而變化。
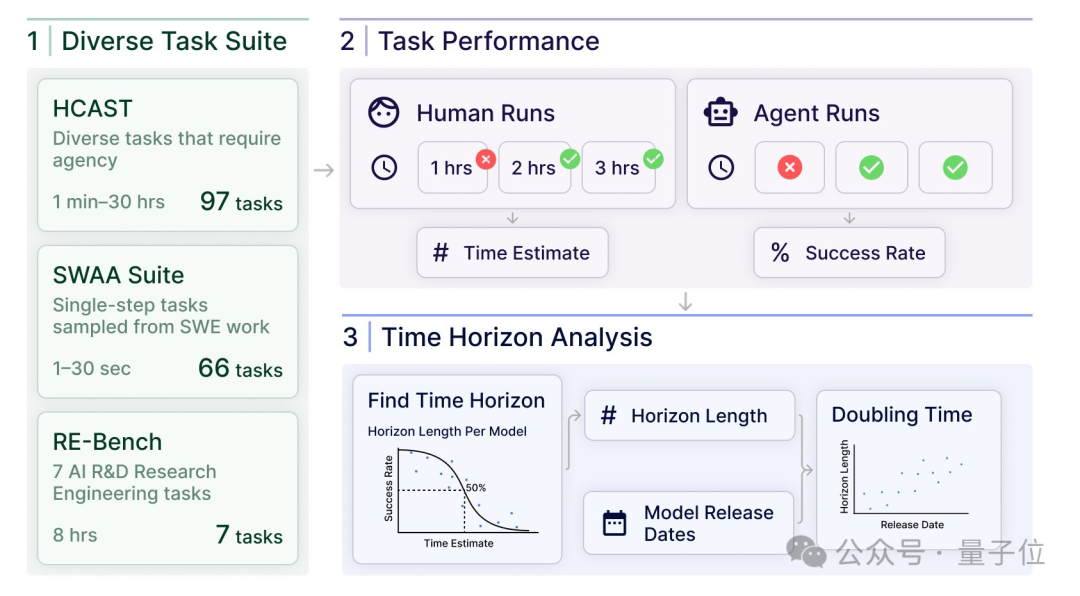
這第一步,研究團隊選擇了三個不同的任務套件來評估AI模型的能力:
-
97個HCAST任務,涵蓋軟件工程、機器學習、網絡安全和一般推理挑戰的多樣化任務集合,難度從幾分鐘到30小時;
-
7個RE-Bench任務,由七個開放式的機器學習研究工程環境組成,每個需人類專家約8小時完成;
-
66個SWAA任務,代表軟件開發過程中的單個步驟操作,時長1秒到30秒。
接下來,為了量化評估AI模型的表現,團隊招募了800多名軟件工程、機器學習和網絡安全領域的專業人員執行任務,並記錄他們完成任務所需的時間。
據METR介紹,在這些任務中,人類完成時間從1秒到16小時不等。
這些時間被當作衡量任務難度的標準。

然後他們又評估了從2019年到2025年發佈的13個前沿AI模型,包括GPT系列和o1、Sonnet 3.7等,通過在構建的任務套件上運行這些模型,並記錄它們完成任務的成功率。
關鍵來了,隨後他們引入了一個新的指標——50%任務完成時間跨度(50%-task-completion time horizon),即AI模型在50%的成功率下能夠完成的任務的平均時間長度。
之所以選擇50%這一成功率,主要是它對於數據分佈的微小變化最為穩健。
簡單說,當數據的分佈(即數據的特徵、比例或趨勢等)發生一些小的變化時,這個指標不會受到太大的影響,仍然能夠保持相對穩定的表現。
論文作者之一Lawrence Chan表示:
如果你選擇非常低或非常高的閾值,那麼分別移除或增加一個成功或失敗的任務,就會對你的估計值產生很大的影響。
利用這一指標,團隊通過對AI模型在各個任務上的成功與失敗數據進行邏輯回歸分析,計算出每個模型的時間跨度,也就是模型完成任務成功率達到50%之時,對應的人類完成任務的時間。
(每個模型在每個任務上運行8次,記錄成功率)
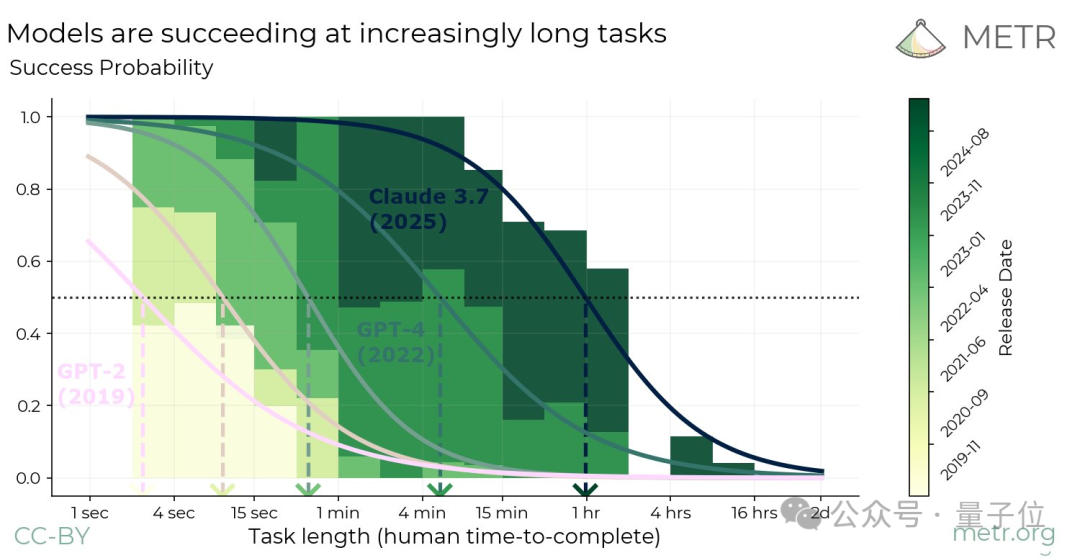
有了這些數據,團隊最終繪製了模型自主性隨時間呈指數變化的圖表。
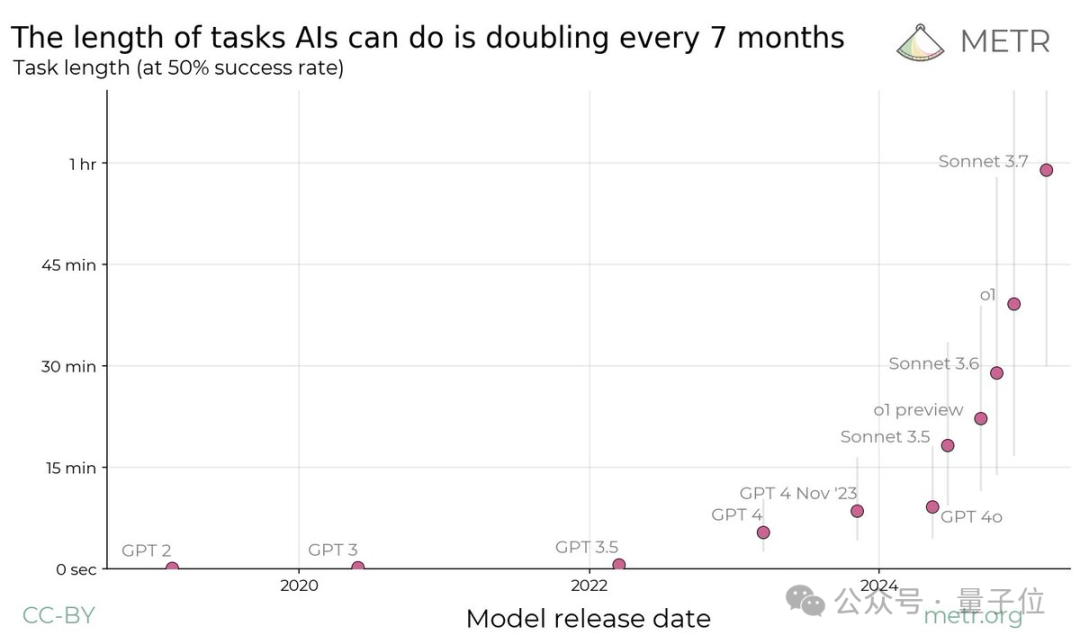
發現「AI智能體摩亞定律」
如上圖所示,研究的主要發現是:
自2019年以來,AI模型的時間跨度呈現出指數級增長,每七個月左右翻一番。
為了驗證研究結果的外部有效性,他們又進行了以下四個實驗:
1、用2023-2025年數據回溯預測,驗證趨勢一致性;
2、對HCAST和RE-Bench任務基於16個 「混亂」 因素評級,分析任務混亂程度對模型性能的影響;
3、在其他SWE-bench Verified數據集上應用相同方法,對比結果;
4、在內部Pull Requests(PR)任務上測試模型性能,與人類基線對比。
最終,這一趨勢得到了以上外部驗證。
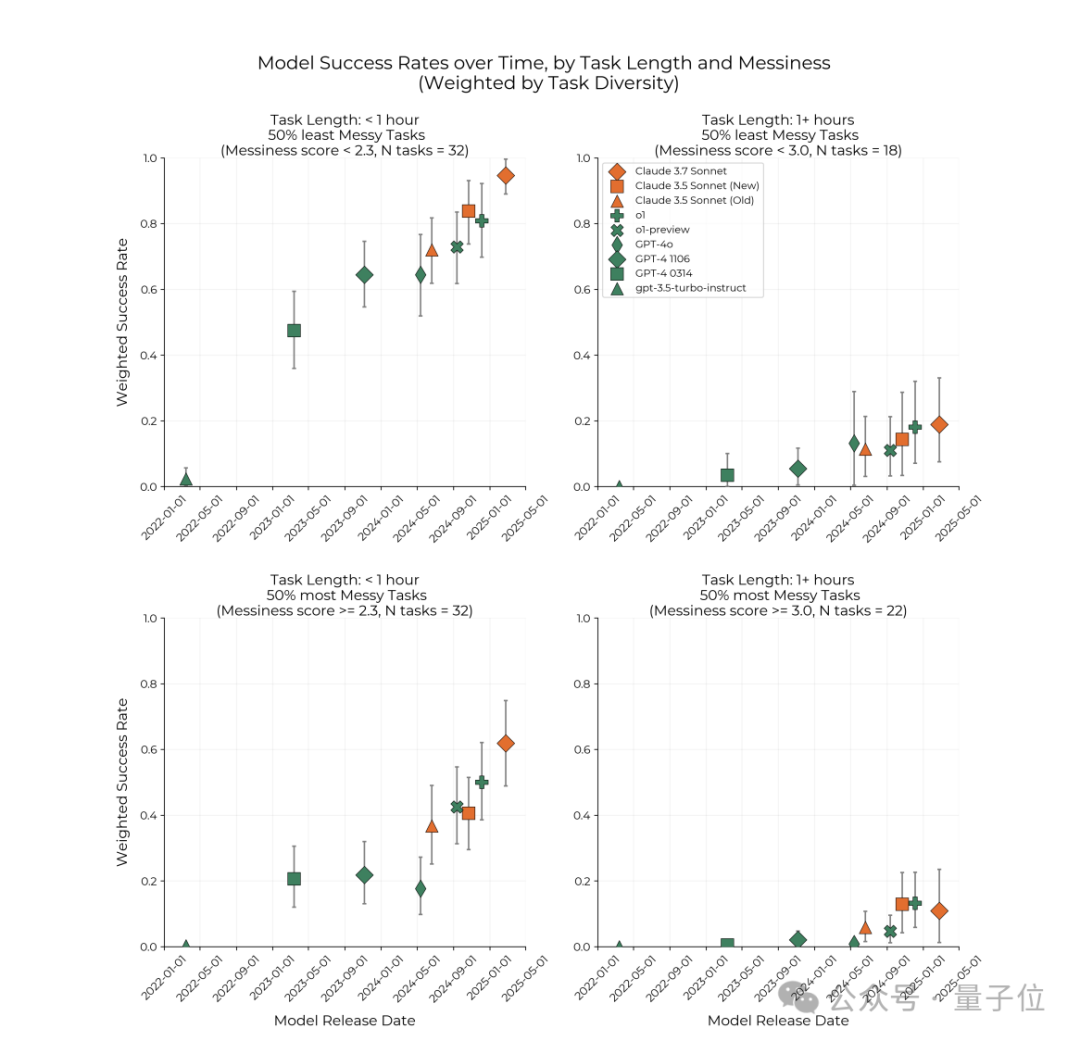
比如在第2個實驗中,所謂的16個 「混亂(messy)」 因素是指現實任務比研究任務更難的方面,包括任務是否受到有限資源的限制、是否涉及實時協調或是否源自現實世界的環境。
每個任務都根據這些因素得到了一個 「混亂度(messiness score)」 分數。
研究人員發現,儘管AI模型在更加混亂的任務上(比如缺乏明確提示和反饋、需要AI主動去獲取信息、任務條件和要求比較模糊等情況)的絕對性能較低,但另一方面其性能在穩步提升。
更有意思的是,不管任務的「混亂」程度如何,AI都是以相似的速度在提升。
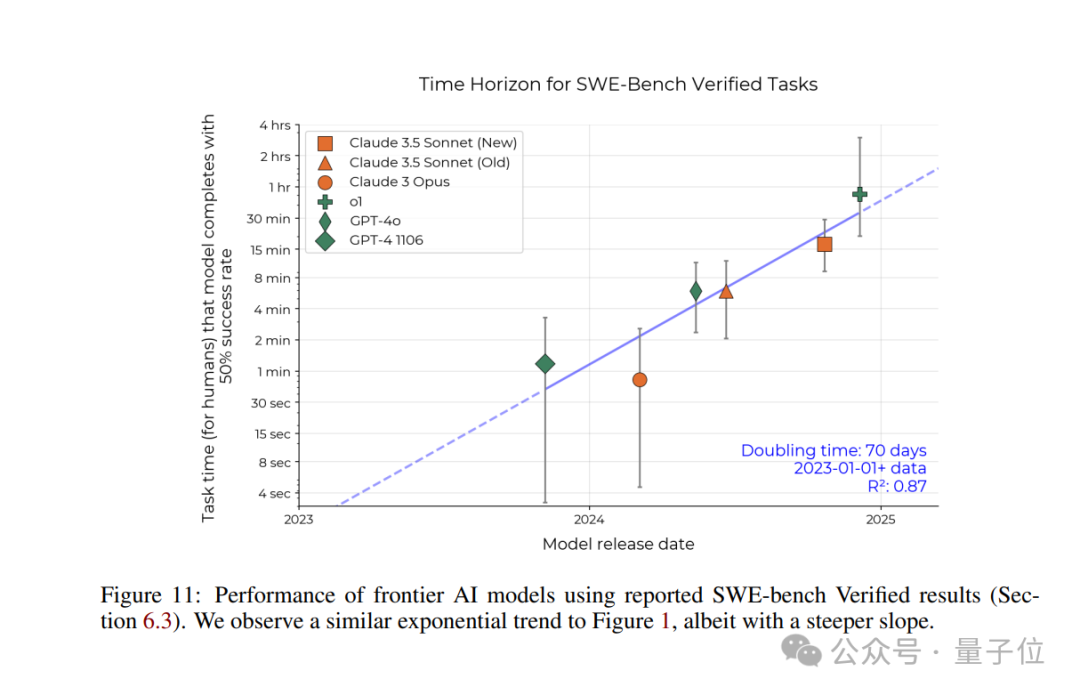
再比如在SWE-bench Verified基準上的驗證,他們也觀察到了一個類似的指數級增長趨勢。
不過由於標註時間的問題,該基準測試的時間跨度翻倍時間更短。
總之,按照「智能體摩亞定律」進行預測,AI可能在2028年11月達到一個月的任務時間跨度;而在較為保守的估計下,這一目標可能在2031年2月實現。
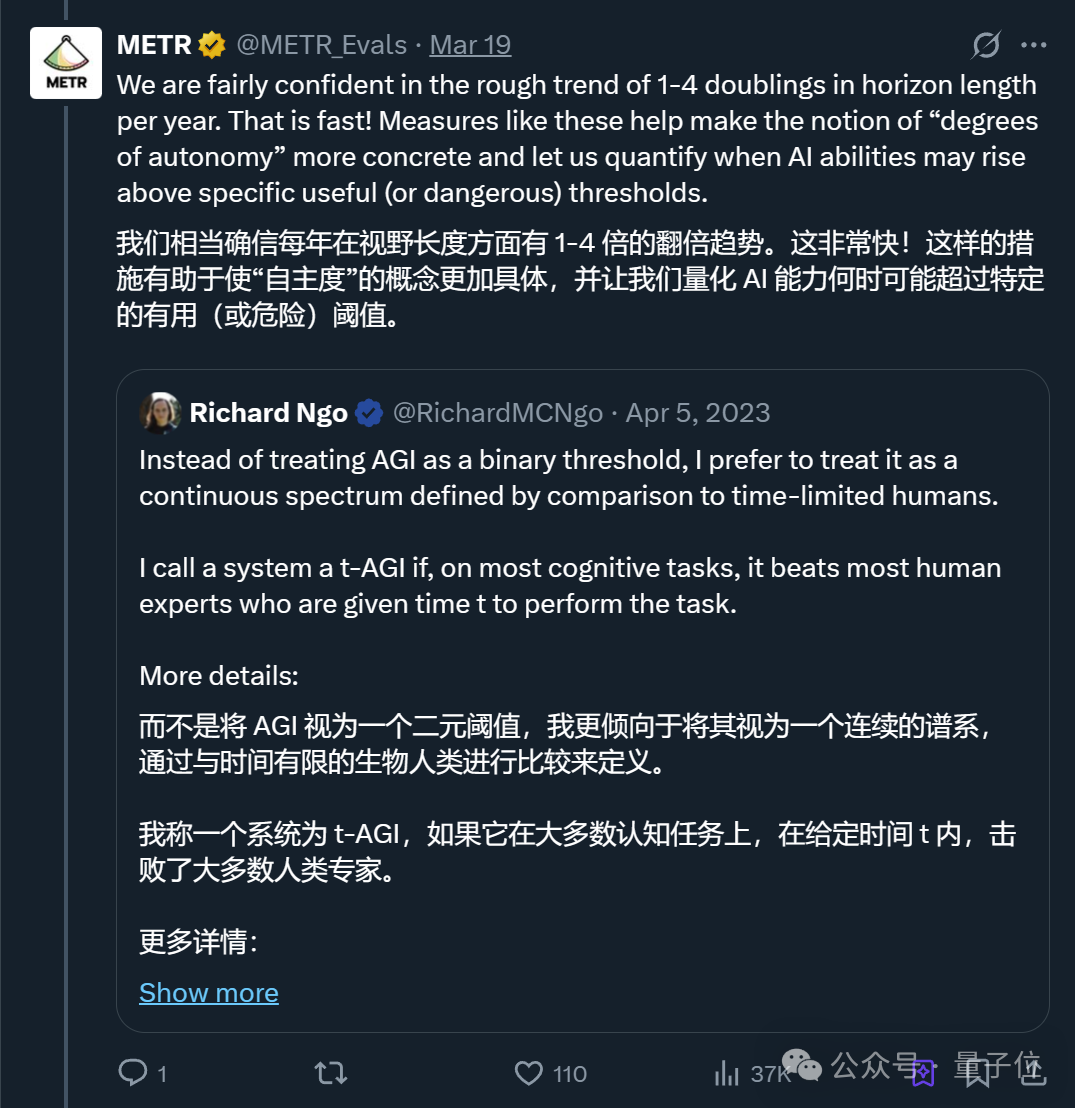
METR團隊認為,雖然研究還存在任務套件具有局限性、評估指標不完美、未來AI發展具有不確定性等需要完善的地方,但很確信這一指標每年有1~4倍的增長趨勢。
而結合現實中Manus智能體的走紅,我們已經能夠預見到智能體將迎來爆發。
論文:
https://arxiv.org/pdf/2503.14499
參考鏈接:
[1]https://www.nature.com/articles/d41586-025-00831-8
[2]https://x.com/METR_Evals/status/1902384481111322929