清華&哈佛4D語言場建模新方法,動態場景精準識別|CVPR2025
周韌平 投稿
量子位 | 公眾號 QbitAI
構建支持開放詞彙查詢的語言場在機器人導航、3D場景編輯和交互式虛擬環境等眾多應用領域展現出巨大的潛力。儘管現有方法在靜態語義場重建方面已取得顯著成果,但如何建模4D語言場(4D language fields)以實現動態場景中時間敏感且開放式的語言查詢,仍面臨諸多挑戰。而動態世界的語義建模對於推動許多實際應用的落地至關重要。
來自清華大學、哈佛大學等機構的研究團隊提出了一種創新方法——4D LangSplat。該方法基於動態三維高斯潑濺技術,成功重建了動態語義場,能夠高效且精準地完成動態場景下的開放文本查詢任務。這一突破為相關領域的研究與應用提供了新的可能性, 該工作目前已經被CVPR2025接收。

將現有靜態語義場重建方法直接遷移到動態場景中,一種直觀的思路是沿用CLIP提取靜態的、物體級語義特徵,並借鑒4D-GS等工作的思路,通過訓練變形高斯場來建模隨時間變化的語義。然而,這種簡單的遷移存在兩個關鍵問題:首先,CLIP最初是為圖-文對齊任務設計的,其在動態語義場中的感知和理解能力存在局限性;其次,基於輸入時間信息預測特徵變化量的方法缺乏對特徵變化的有效約束,導致動態語義場建模的學習成本顯著增加。
針對上述問題,本文提出了4D LangSplat框架。該框架的核心創新在於:利用影片分割模型和多模態大模型生成物體級的語言描述,並通過大語言模型提取高質量的句子特徵(sentence feature),以替代傳統靜態語義場重建方法(如LERF、LangSplat)中直接使用CLIP提取的語義特徵。在動態語義特徵建模方面,4D LangSplat引入了狀態變化網絡(Status Deformable Network),通過先驗壓縮語義特徵的學習空間,實現了更加穩定和準確的語義特徵建模,同時確保了特徵隨時間的平滑變化。
4D LangSplat的提出顯著拓展了語義高斯場建模的應用場景,為動態語義場的實際落地提供了一種極具前景的解決方案。目前,該工作已在X(Twitter)平台上引發廣泛關注,論文的代碼和數據已全面開源。
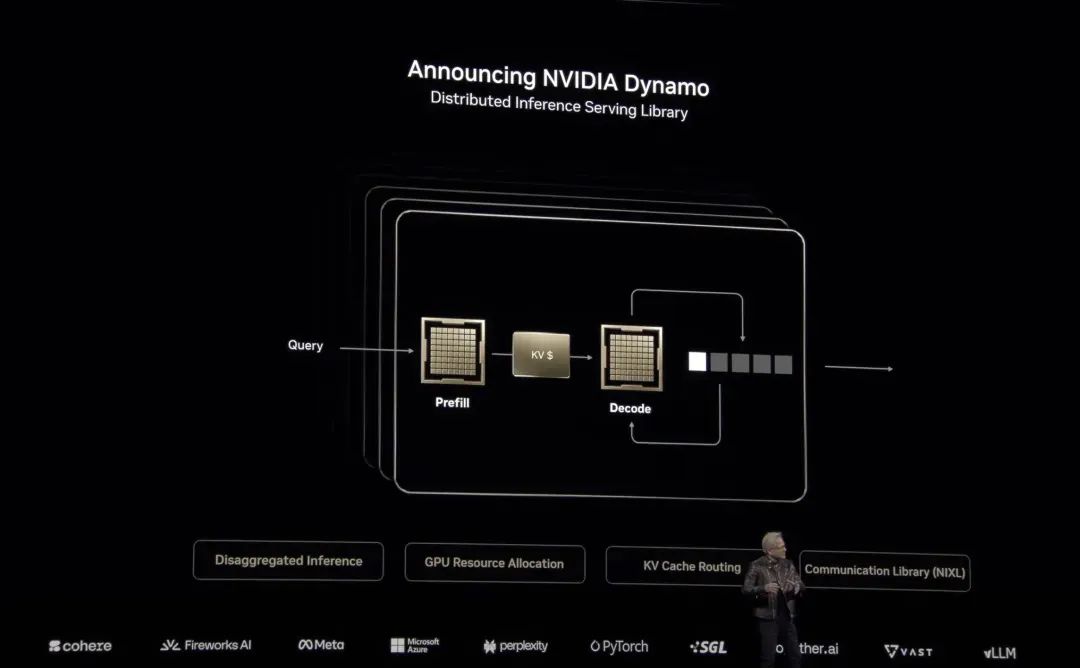
方法論
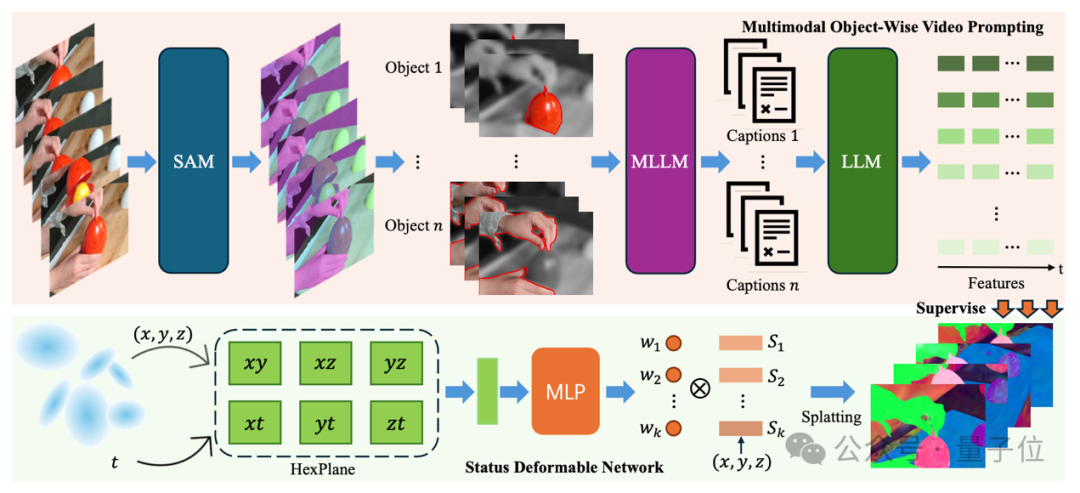
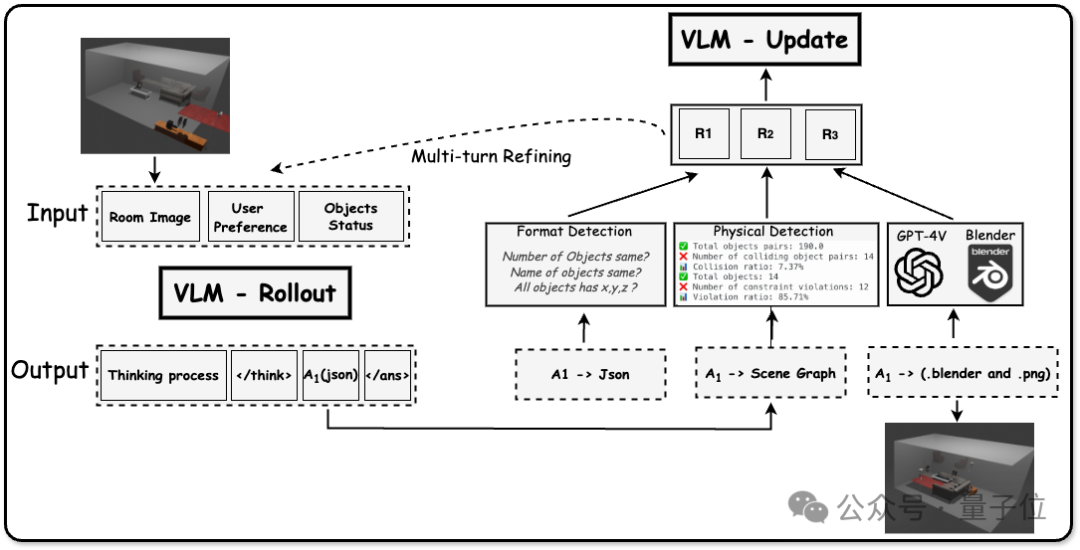
多模態對象級影片提示技術(流程圖中上半部分的紅色區域)
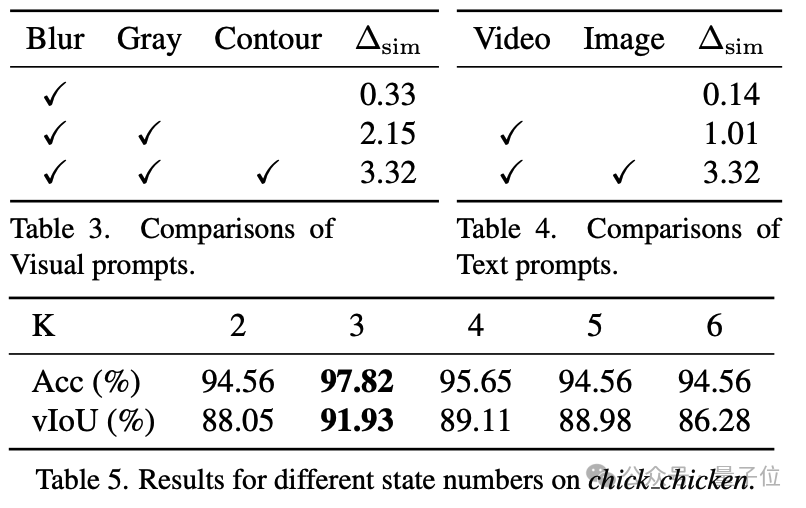
本文結合了SAM(Segment Anything Model)和DEVA tracking技術,對物體進行分割,並在時間維度上保持物體身份的一致性。為了使多模態大模型能夠更專注於已有物體的描述,首先為目標物體生成視覺提示。具體而言,視覺提示包括輪廓線(Contour)、背景虛化(Blur)和單色調整(Gray)。這一過程可以形式化地定義為:
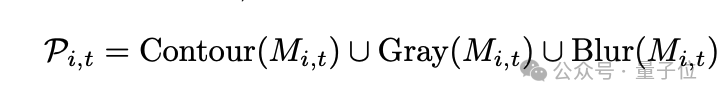
在加入視覺提示後,首先利用多模態大模型(Qwen-Instrution-7B)生成影片級的語言描述,隨後逐幀將圖片和影片描述再次輸入到大模型中,提示其生成特定時間步驟下的物體狀態變化的自然語言描述。生成影片-物體級語言描述和圖片-物體級語言描述的過程可以形式化地定義為:
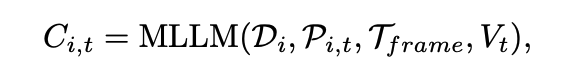
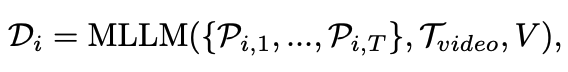
對於每一條生成的圖片-物體級描述,使用在sentence-embedding任務上經過微調的LLM模型(e5-mistral-7b)將其轉化為語義特徵,並通過分割掩碼生成最終的語義特徵圖。此外,參考LangSplat的做法,訓練了一個自動編碼器,將高維特徵壓縮到低維空間,從而降低高斯場訓練的複雜度和計算成本。
狀態變化場(流程圖中下半部分的綠區域)
通過對語義特徵的觀察,發現現實中的大部分變形和運動都可以分解為一系列狀態及其之間的過渡。例如,人的運動可以分解為站立、行走、跑步等狀態的組合。在特定時間點,物體要麼處於某種狀態,要麼處於從一個狀態到另一個狀態的過渡中。
基於這一觀察,本文提出了狀態變化網絡(Status Deformable Network)。該建模框架將特定時間步下的變化狀態分解為若干狀態的線性組合,網絡以Hexplane提取的時空特徵作為輸入,專注於預測指定時間步下的線性組合係數。數學上,其建模方式如下:
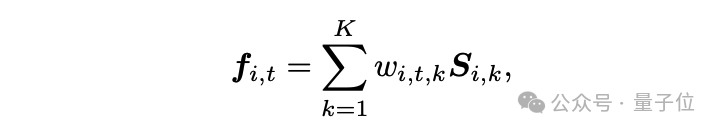
其中,w代表模型預測的係數,S 代表狀態特徵。在訓練過程中,狀態特徵和預測係數的狀態變化網絡聯合優化,以確保對變化語義特徵的準確和平滑建模。
4D 開放詞彙查詢
4D開放詞彙查詢任務定義為兩個子任務:時間無關的查詢和時間敏感的查詢。
時間無關的查詢主要考驗語義場的靜態語義建模能力,目標是根據指定的查詢詞,給出物體在每一幀的查詢結果掩碼,類似於物體追蹤檢測任務。而時間敏感查詢則更注重動態語義建模能力,不僅需要給出查詢物體的掩碼,還需要精確到具體的時間步(例如動作發生的幀範圍)。
為了完成這兩個子任務,同時渲染了時間無關的語義場和時間敏感的語義場。前者基於CLIP提取語義特徵,且不對語義特徵的變化進行建模;後者則採用本文的方法提取時間敏感語義,並利用狀態變化網絡對語義特徵進行建模。在進行時間敏感查詢時,首先通過時間無關場生成對應物體的查詢掩碼,然後計算掩碼內時間敏感場的平均相關係數,並給出預測幀的結果。通過結合這兩個場,能夠同時勝任時間敏感查詢和時間無關查詢任務。
實驗
實驗設置:
由於目前缺乏針對4D語義查詢的標註數據,團隊在HyperNeRF和Neu3D這兩個數據集上進行了手工標註,構建了一個專門用於4D語義查詢的數據集。在評估指標方面針對不同的查詢任務設計了相應的衡量標準:
時間無關查詢:使用平均準確率(mACC)和平均交並比(mIoU)作為查詢結果的評估指標。
時間敏感查詢:使用幀級別的預測準確率(ACC)和像素級別的平均交並比(vIoU)作為評估指標
實驗結果:
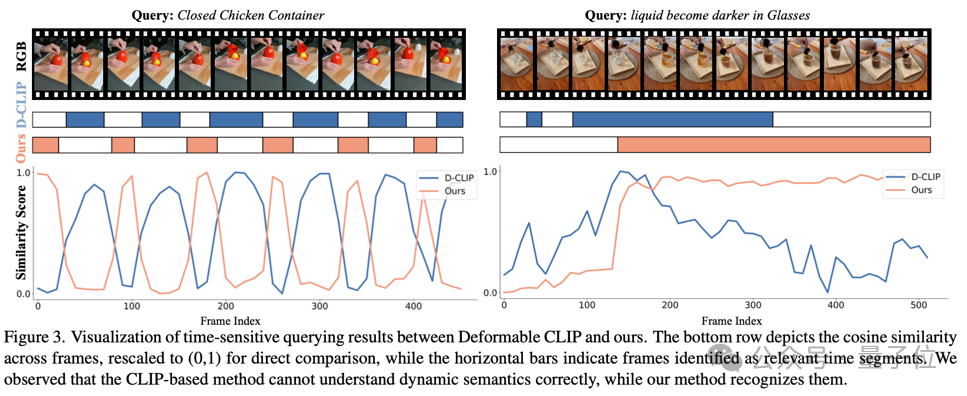
本方法在時間敏感和時間無關查詢兩個子任務上都顯著優於最先進的方法。在時間敏感查詢上,與基於CLIP特徵的方法相比,本方法在幀級別準確率(ACC)和像素級別平均交並比(vIoU)上分別提升了29.03%和27.54%。時間無關查詢方面,在HyperNeRF和Neu3D兩個場景中,本方法在平均交並比(mIoU)上分別比基線方法提升了7.56%和23.62%。

消融實驗:
為了驗證方法中各個組件的有效性,在論文中進行了詳細的消融實驗。實驗結果表明,每個組件都對最終性能的提升起到了重要作用。
貢獻總結
-
使用 MLLM 生成的對象文本描述構建 4D 語言特徵。
-
為了對 4D 場景中對象的狀態間平滑過渡進行建模,進一步提出了一個狀態可變形網絡來捕捉連續的時間變化。
-
實驗結果表明,本方法在時間無關和時間敏感的開放詞彙查詢中都達到了最先進的性能。
-
通過人工標註,構建了一個用於4D開放詞彙查詢的數據集,為未來相關方向的研究提供了定量化的指標。
Project Page: https://4d-langsplat.github.io/
Paper: https://arxiv.org/pdf/2503.10437
Video: https://www.youtube.com/watch?v=L2OzQ91eRG4
Code: https://github.com/zrporz/4DLangSplat
Data: https://drive.google.com/drive/folders/1C-ciHn38vVd47TMkx2-93EUpI0z4ZdZW?usp=sharing
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!