DeepSeek無顯卡本地部署70B,能跑嗎?
大家好,我是波導終結者。

在我寫這篇文章的這幾天,號稱32B能媲美DeekSeek-R1滿血671B的QwQ模型已經放出來了,我還沒有完成完整的測試。今天先把前不久折騰的llama-70B本地部署整理出來與大家分享。因為之前有小夥伴留言,說70B也是能跑的,慢點是慢點,自己本地折騰個樂嗬。我想一想也有道理,但是具體什麼樣才叫“能”跑,定義可能不一樣。最基礎的,能載入運行,不崩,能正確出結果,再慢也叫能跑。那咱們就以這個定義為基礎,來看看本地無顯卡部署DeepSeek是否可行吧?
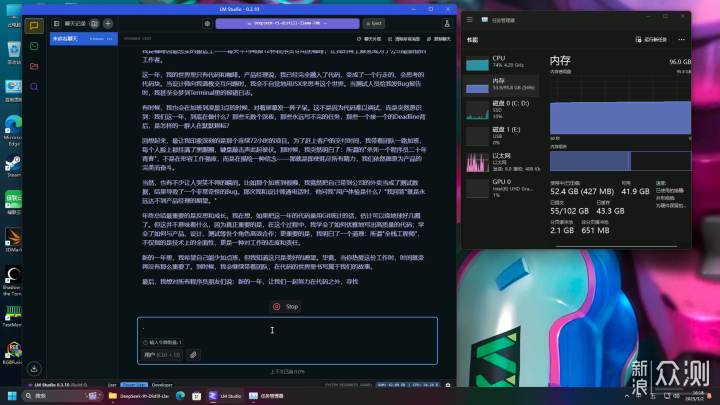
70B-Q4_K_M的模型大小為42.52GB,基本上得64G內存才有戲,出於謹慎起見,這裏我還是放到96G的機子上跑。而Q6模型有57.88G,Q8模型有74.98G,根據自己機子酌情選擇。CPU線程池拉滿,評估處理大小拉到1024,題目為“請幫我寫一篇年終總結,主角是程式員,每天工作24小時,每週工作6天”。實測CPU佔用50-70%左右,雙通道內存仍存在瓶頸但並未達到質變程度,內存佔用54GB左右。4分43秒出結果,1.64 tok/sec,1233 tokens,6.79s to first token,還算可以接受。
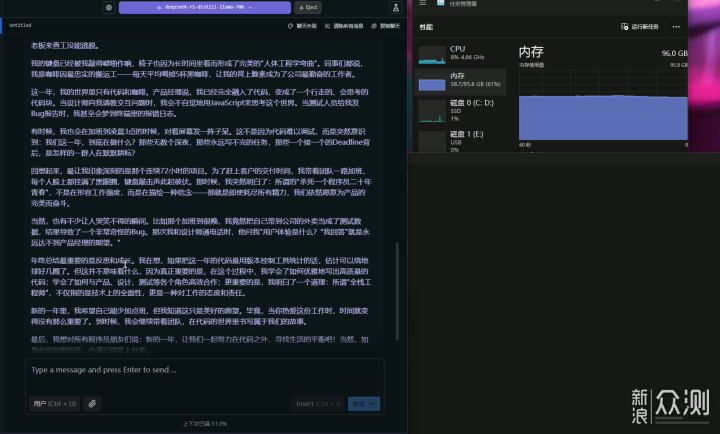
但根據小夥伴反饋,70B在連續對話時會卡住。這裏我測試了一下,要求繼續在原文基礎上修改。原文有“一天12杯黑咖啡”,“夢到Terminal里的報錯日誌”,“公司attendance系統”,“用JSX來思考這個世界”這樣不合理,或者無必要英文的使用。我跟它說,“一天喝12杯咖啡會死人的,沒必要的英文請改成中文”。此時,小夥伴所反饋的疑似卡住的現象開始出現,雖然顯示4分24秒出結果,但是1.61 tok/sec,1183 tokens,1050.18s to first token。注意這個first token,換算一下,它先思考了17.5分鐘,才開始正式工作。總的等待時間已經超過20分鐘。
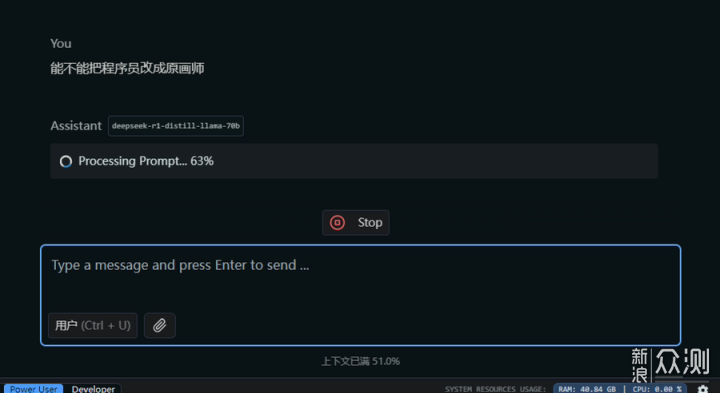
但你說它能跑嗎?確實能跑,結果也很不錯。沒有必要的英語單詞都換成了中文術語,“BUG,Deadline”等可以保留的都保留了,“JSX來思考世界”改成了“JavaScript來思考世界”。其他部分沒有叫它改的,也都沒有亂改。只是程式也好AI也好,思考方式和人類還是有區別,才會需要把之前的內容都回鍋一遍吧。這裏我叫它把程式員改成原畫師,正式計算結果之前又卡住好久。
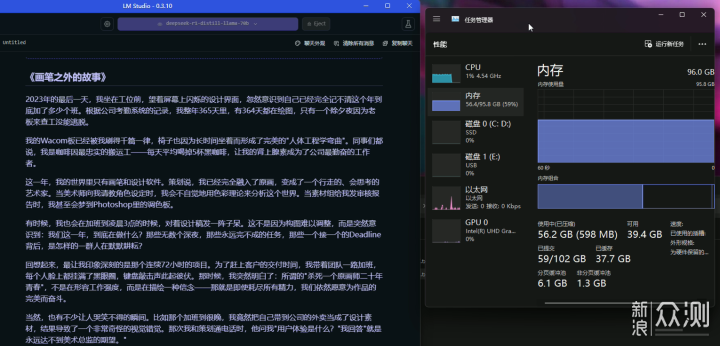
隨著負載的加重,出結果的速度繼續變慢。5分19出結果,1.58 tok/sec,1239 tokens,1162.05s to first token,還不知道之前的Processing Prompt有沒有算進去。結果倒是中規中矩,文章架構幾乎沒換,只是把一些描述和字眼,從程式員相關,換成了畫師相關。

總的來看,本地部署70B,只要內存夠,上下文不爆炸,慢是慢了點,倒也不能說不能用。至於最近冒出來的QwQ-32B,測試完再跟大家分享。
感謝大家的觀看,點讚和關注,我們下期再見。