火了!高中生用Minecraft做AI基準,用戶看圖投票決定大模型排名
機器之心報導
編輯:蛋醬
偶然發現了一個很有趣的 AI 基準測試,點開鏈接,竟然是一個 MineCraft 作品投票頁面?
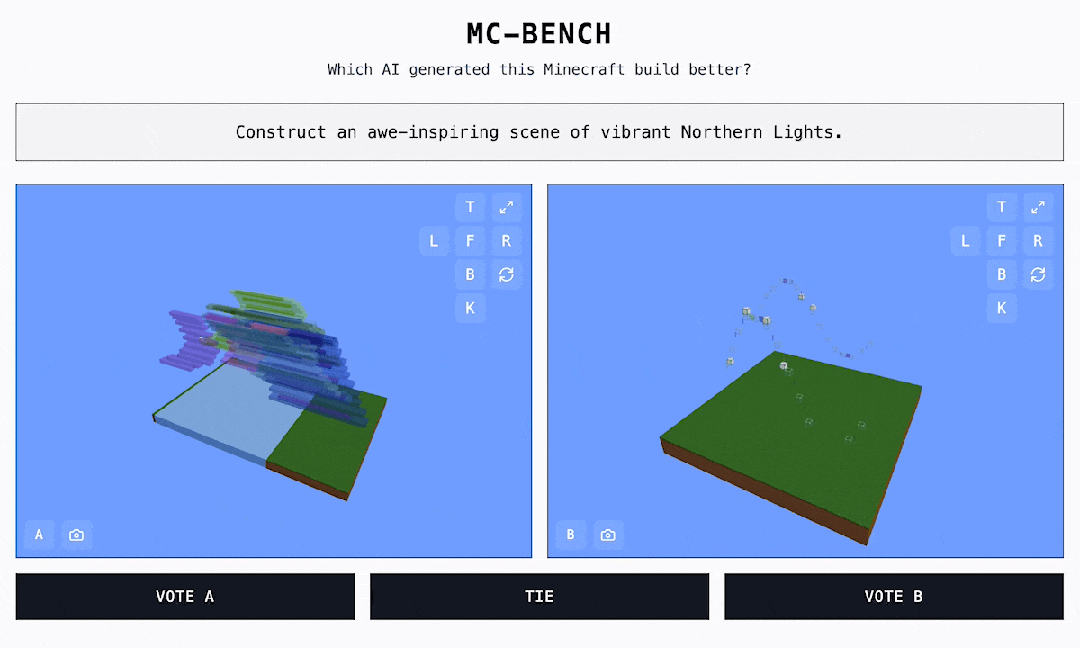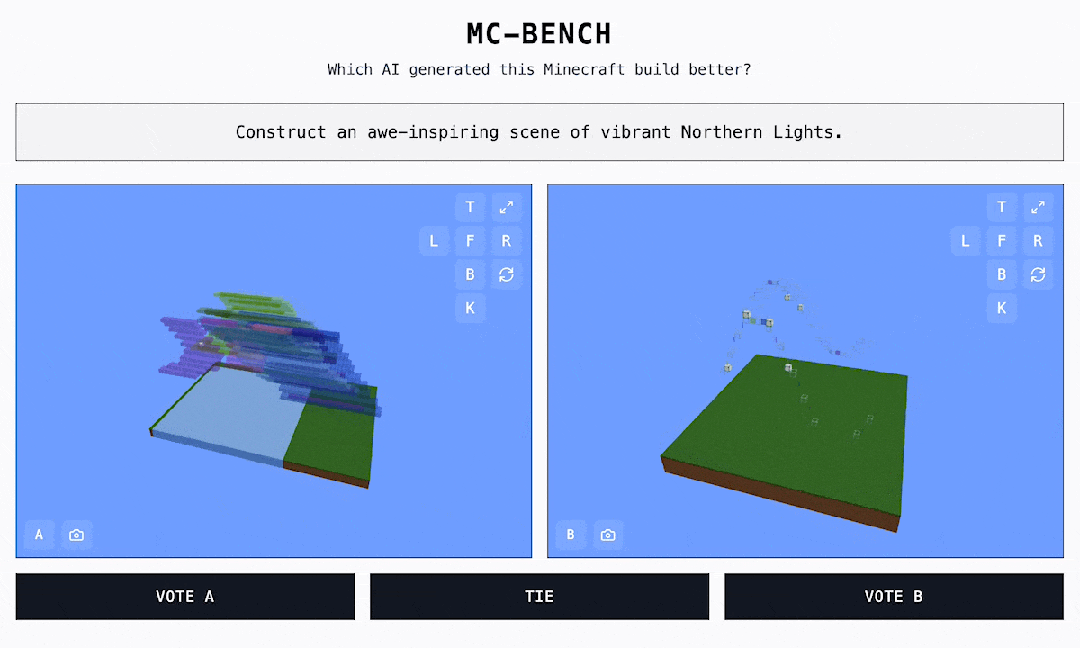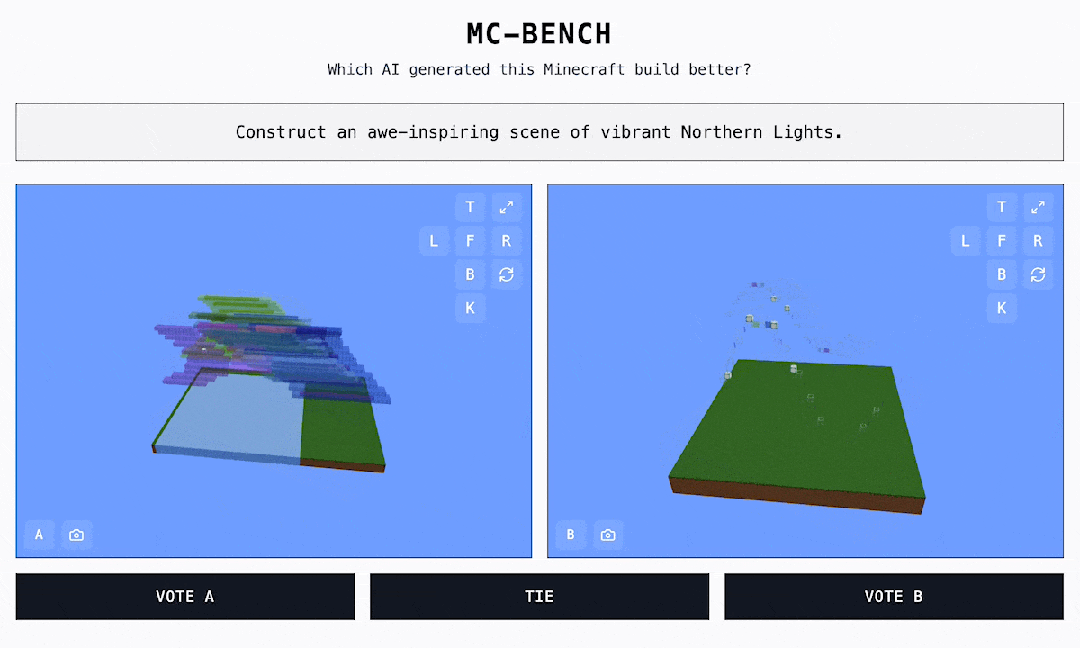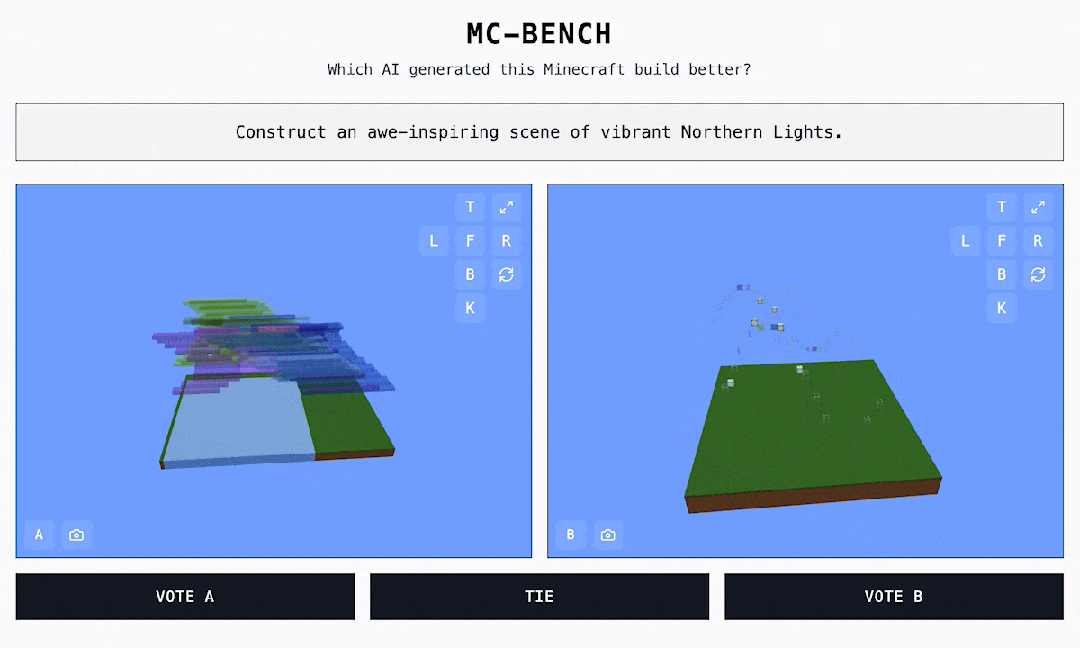
如圖所示,這些作品都是 AI 完成的,灰色框中的文字對應的是提示詞。黑框是可點擊的選項 ——A、B 或者持平。
網站地址:https://mcbench.ai/
來都來了,先投個票吧。投票之前,作品都是「匿名」的。只有在投票後,我們才能看到每個 Minecraft 作品是由哪個模型完成的。

在這個基準里,主要看三個維度:指令遵循、代碼完成度和創造力。
AI 技術飛速演進的時代,傳統的人工智能基準測試顯然不夠用了。總有人能想出一些新穎的測試方法,比如的沙盒建造遊戲 Minecraft。
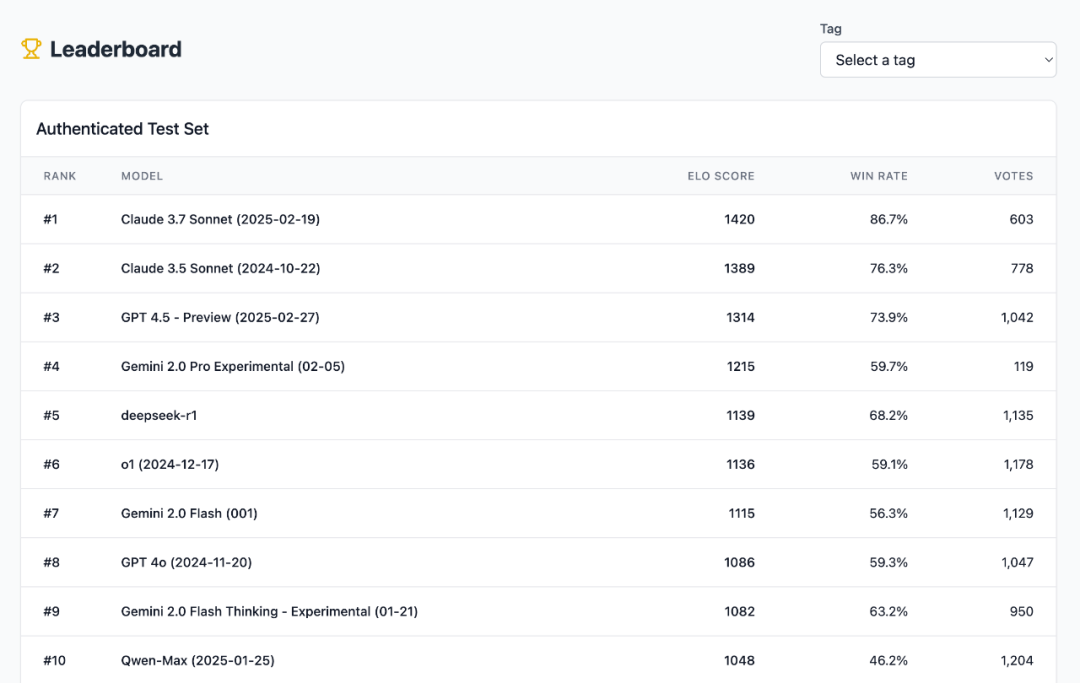
這就是我們剛剛看到的 Minecraft Benchmark(MC-Bench)。作為用戶,我們能夠參與的部分就是:投票。累計票數中的 ELO 分數決定了每個模型的排名。
有趣的是,無論採用哪種指標,排行榜的收斂程度都很高:Claude 3.7 & 3.5 和 GPT-4.5 都是斷層領先。
從技術上講,MC-Bench 是一個編程基準,因為模型需要編寫代碼來創建所提示的構建,如「冰霜雪人」(Frosty the Snowman)或「原始沙灘上迷人的熱帶海濱小屋」(a charming tropical beach hut on a pristine sandy shore)。
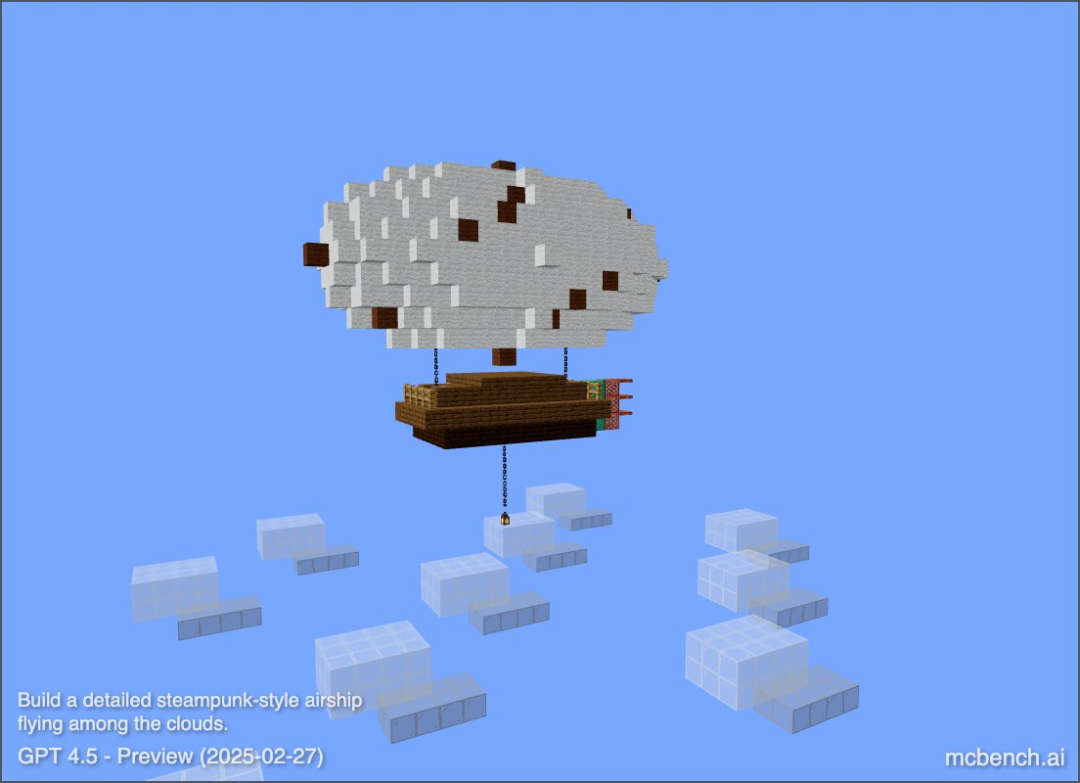
Prompt:”build a detailed steampunk-style airship flying among the clouds”(一艘在雲層中飛行的詳細蒸汽朋克風格飛艇)
創辦 MC-Bench 的 Adi Singh 是個高中生,在他看來,用 Minecraft 做測試基準的價值並不在於遊戲本身,而在於「人們對它的熟悉程度」,畢竟它是有史以來最暢銷的影片遊戲。
對於大多數 MC-Bench 用戶來說,評價雪人是否更好看要比研究代碼更容易,這使得該項目具有更廣泛的吸引力,從而有可能收集更多數據,以瞭解哪些模型的得分始終更高。
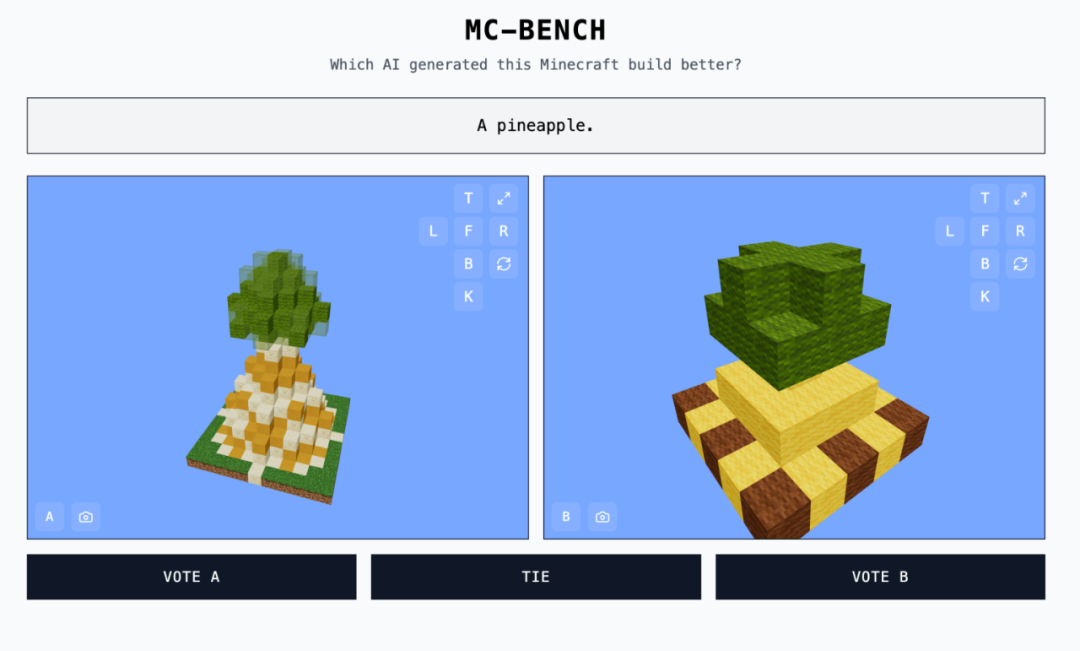
退一萬步說,即使是沒有玩過這款遊戲的人,也可以評估出哪個菠蘿的塊狀表現形式更好,請參考下面這個例子:
「目前,我們只是在進行簡單的構建,以思考我們自 GPT-3 時代以來已經走了多遠,但(我們)可以看到自己正在擴展到這些較長形式的計劃和目標導向型任務。遊戲可能只是一種測試智能體推理的媒介,它比現實生活中更安全,測試目的也更可控,因此在我看來更理想。」
研究人員經常在標準化評估中對人工智能模型進行測試,其中很多測試都會給人工智能帶來主場優勢。由於人工智能模型的訓練方式,它們天生就擅長解決某些具體的問題,尤其是需要死記硬背或基礎推理的問題。
簡單地說,OpenAI 的 GPT-4 可以在 LSAT 考試中取得第 88 百分位數的成績,但卻無法辨別「Strawberry」一詞中有多少個 「R」。Anthropic 的 Claude 3.7 Sonnet 在一項標準化軟件工程基準測試中取得了 62.3% 的準確率,但在玩《Pokemon》時卻比大多數的五歲孩子還差。
所以一些開放式的遊戲反而能「另闢蹊徑」,提供檢驗 AI 性能的新穎視角。在此之前,已經有很多知名遊戲被加入 AI 基準測試的名單,比如《Pokemon》(Pokémon Red)、《街頭霸王》(Street Fighter)和《猜字遊戲》(Pictionary)。