OpenAI最新音頻模型一手實測,可癲可禦可定製,中文有點翻車
智東西3月21日報導,今天,OpenAI在其API中推出全新一代音頻模型,分別為語音轉文字模型gpt-4o-transcribe、gpt-4o-mini-transcribe,以及文字轉語音模型gpt-4o-mini-tts。據OpenAI介紹,這些模型大幅降低了單詞識別錯誤率、語言識別能力與準確性,尤其是在涉及口音、嘈雜環境和不同語音速度等具有挑戰性的場景。

開發者還可以讓文本轉語音模型以特定的方式說話,如「像富有同情心的客戶服務人員一樣說話」,或是「機器人腔調」、「瘋狂科學家風格」。這一功能提升了語音智能體的定製化程度,讓智能體與用戶的交互更為逼真、豐富。
為展示本次發佈的模型,OpenAI還專門創建了一個獨立網站,用戶可在網站內免費體驗模型文字轉語音的能力,而語音轉文字能力需要通過API訪問才可使用。
發佈後,智東西也第一時間上手體驗了新模型的文字轉語音能力。它不僅能流利、富有情感地說英文,還能用意大利語報菜名,用粵語打推銷電話,不過,在大部分中文場景中,這款文字轉語音模型還有較大的提升空間。
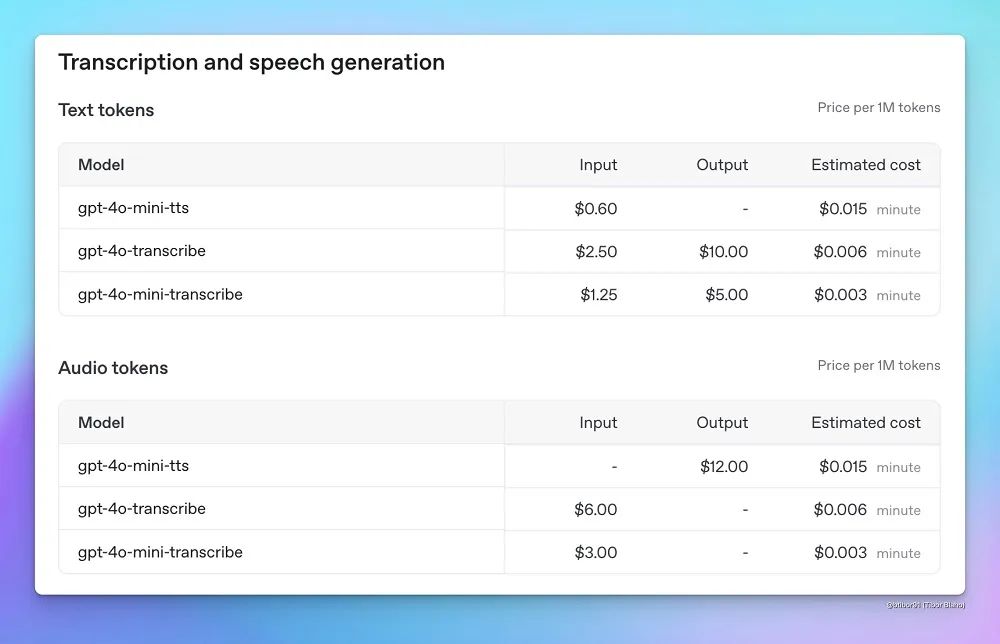
價格方面,gpt-4o-transcribe的定價為每分鐘0.006美元(約合人民幣0.04元);gpt-4o-mini-transcribe的定價為每分鐘$0.003美元(約合人民幣0.02元);gpt-4o-mini-tts的定價為每分鐘0.015美元(約合人民幣0.11元)。
01 定製化程度大幅提高,中文語音效果略顯生硬
進入體驗網址首頁,可以看到目前OpenAI提供了11種預置的聲音選項。不過,他們給聲音起的名字不太直觀,用戶需要逐一試聽才能瞭解背後的聲音到底有什麼特點。
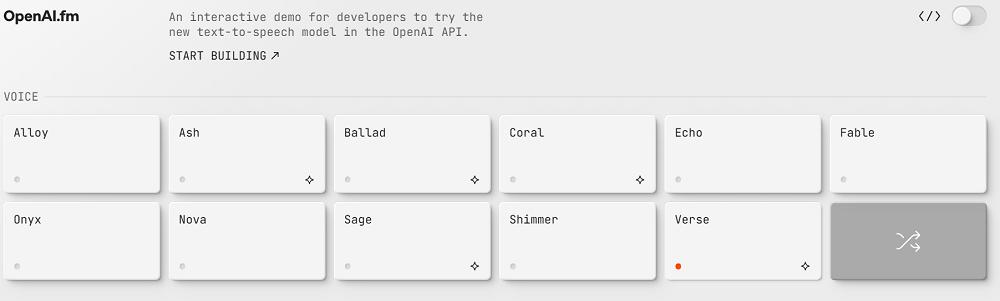
在未經提示詞調整前,這些語音的聽感大多較為普通,不帶過多情感,保留了一定的「機器感」。
用戶可以在選擇聲音後,指定特定的風格或人設,如「冷靜」、「耐性老師」、「友好」、「美食主廚」等等。
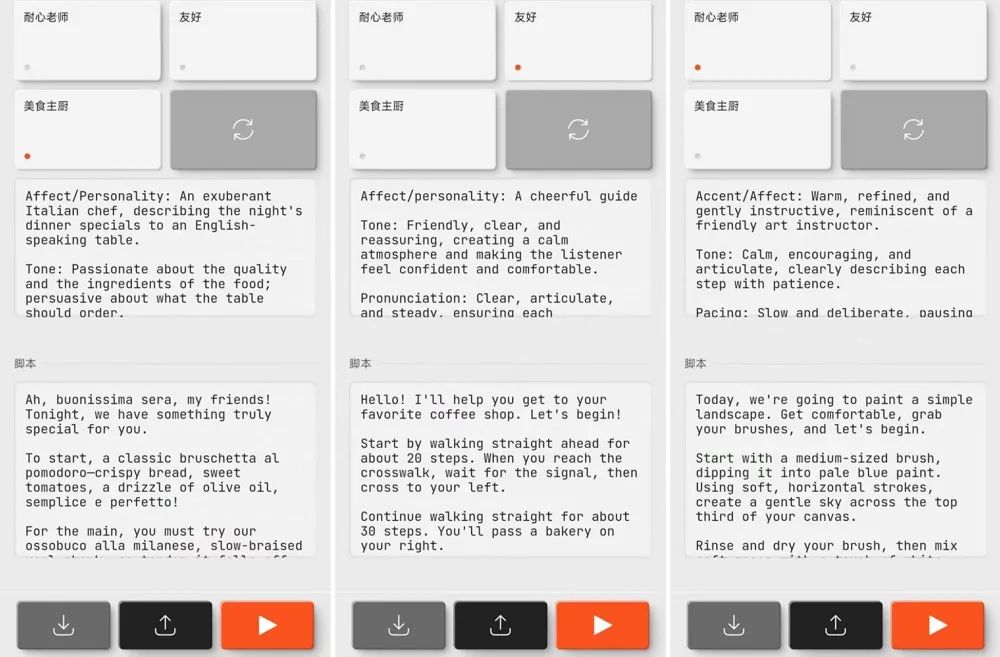
智東西嘗試了OpenAI提供的「美食主廚」選項,這位「主廚」的人設是一位意大利人,需要以充滿激情的腔調講述當晚的菜單。
提交內容後,模型在數秒內返回了結果。不得不承認,這一語音的感染力很強,也符合對意大利人語音語調的刻板印象。這位「主廚」不僅能用意大利語報菜名,還能自如地切換回英文進行講解,細聽之後,我們可以發現他所說的英文並非完全標準,帶有一定意大利口音,可謂是細節拉滿了。
模型還能模仿特定歷史時期的說話方式,這是通過定製化的提示詞實現的。選擇「中世紀騎士」選項後,模型在情感、語氣、情緒、發音、停頓等方面都收到了極為詳細的指引。可以看到,實現這一效果的提示詞長達100多個單詞,涉及多個方面的定義,如果用戶自行撰寫,應該需要具備一定提示詞工程基礎。

正如提示詞所要求的那樣,這段語音具有較強的戲劇性,發音清晰、從容,略帶正式感,在涉及特定古英語內容時也做了應有的處理。不過,平心而論,這一效果並非完全單靠模型本身所實現,還需要與恰如其分的文本內容配合,才能完美實現。
智東西也測試了模型在中文場景的能力。為提高效率,我們使用大模型仿照OpenAI提供的提示詞範本,撰寫了中文提示詞和文本。這一聲音的人設是一位語文老師,文本內容是一堂古詩課。

模型在生成中文語音時的速度也較為理想,基本實現了秒出結果,但與英文語音豐富的情緒和語音語調變化相比,中文的語音效果略顯生硬,聲音缺乏起伏與變化,也沒有親和力。
智東西還嘗試了多個不同角色的中文表現,依舊出現了類似的問題。下方案例是一個常見的推銷場景,相信大部分人在接到這樣的電話時,都能第一時間判斷出這是由AI生成的。
在方言上,智東西嘗試了閩南語、粵語、山東話、河南話等指令,最終只有粵語成功返回了結果,其他的指令返回的結果與普通話沒有太大差別。
02 超越whisper,轉寫準確度提升
本次OpenAI還帶來了2款新的語音轉文字模型。OpenAI上一代語音轉文字模型whisper最早於2022年發佈,後陸續更新至whisper-large-v3版本。
本次發佈的gpt-4o-transcribe和gpt-4o-mini-transcribe在多個基準測試上超過了原有的whisper模型,在單詞識別錯誤率上有明顯進步。
從語言上來看,gpt-4o-transcribe和gpt-4o-mini-transcribe在「高資源語言」,即使用人數較多、訓練數據充足的語言上表現出色,如英語、西語、葡萄牙語、法語、中文等。眾多高資源語言中,模型在中文上的表現相對較差。
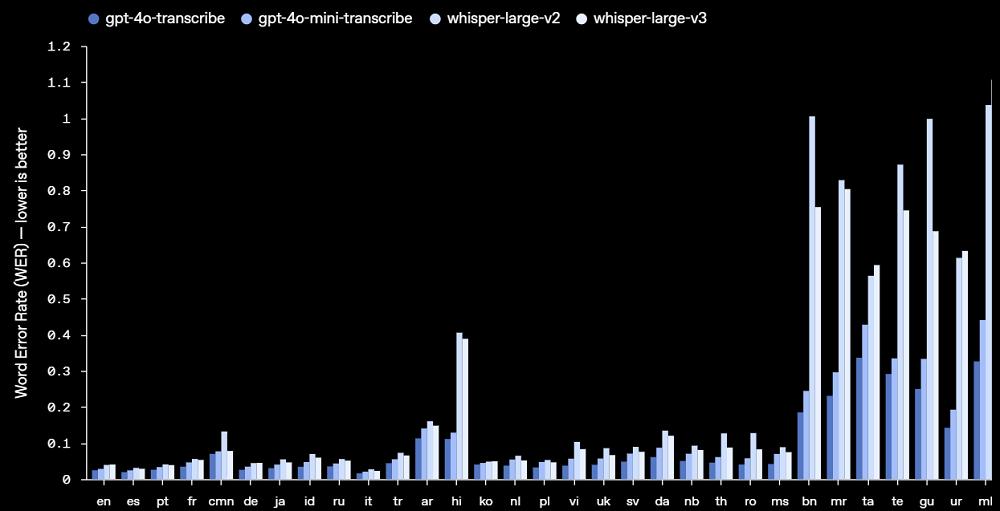
而在低資源語言上,gpt-4o-transcribe和gpt-4o-mini-transcribe實現了較大的改進,如孟加拉語(bn)的錯誤率就從whisper的1%左右下降至0.3%左右,而在印度地方語言古吉拉特語(gu)的錯誤率也下降至0.4%。
OpenAI還將這兩款模型與Google、Anthropic等廠商的模型進行對比,在大部分語言上,OpenAI新模型的表現要優於其他模型。
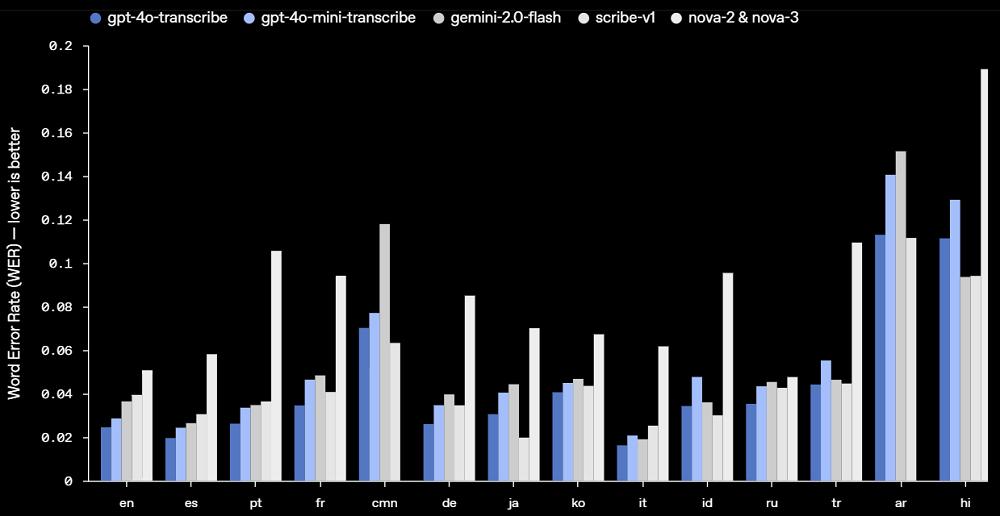
OpenAI稱,這些新的語音轉文本模型能更好地捕捉語音的細微差別,減少誤識別,並提高轉錄的可靠性。
在博客文章中,OpenAI分享了語音模型能力提升背後的技術細節。gpt-4o-transcribe和gpt-4o-mini-transcribe分別基於GPT-4o和GPT-4o-mini架構,並在專門的音頻數據集上進行了大規模預訓練。
此外,OpenAI使用改進模型蒸餾技術,將大型音頻模型的知識遷移到更小、更高效的模型。這一過程中採用了自博弈技術,蒸餾數據集有效地捕捉了真實的對話模式,有助於小型模型提供出色的對話質量和響應速度。
OpenAI的語音轉文字模型使用了以強化學習為主導的範式,這一方法顯著提高了精確度並減少了幻覺。
03 結語:音頻生成和轉錄技術前景值得期待
根據實測結果來看,OpenAI本次發佈的語音轉文本模型在whisper的基礎上並未實現明顯提升,有不少網民稱這種程度的提升不值得專門付費。而在文本轉語音方面,這款模型確實帶來了一些驚喜,不過更多的是在英語與其他西方語言上,中文場景的真實性和可用性還有待改進。
OpenAI稱,他們未來會進一步提升音頻模型的智能性和準確性,並允許開發者引入自定義聲音,從而構建更個性化的體驗。作為一個能極大提升交互體驗的模態,OpenAI在音頻生成和轉錄方面的探索值得期待。
本文來自微信公眾號 「智東西」(ID:zhidxcom),作者:陳駿達,36氪經授權發佈。