OpenAI語音智能體誕生,懟臉實拍語氣狂到飛起,API降到每分鐘0.3美分
就在今天淩晨,OpenAI的全新音頻模型上線了!語音智能體的時代正式開啟了!現在可以利用新的語音模型,指導GPT-4o的說話語氣:想溫柔就溫柔,讓瘋狂就瘋狂!而且,定價也很親民,比上一代語音模型更便宜。
就在今天淩晨,OpenAI的全新音頻模型上線了!
這次,一共發佈了三款全新語音識別模型gpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-mini-tts,正式開啟了語音智能體的時代。
三款模型的語音轉文本和文本轉語音的功能,讓開發者能輕鬆構建智能體。
gpt-4o-transcribe (語音轉文本):比原來的Whisper模型更準確,更理解人類說話,錯誤更少
gpt-4o-mini-transcribe (語音轉文本):gpt-4o-transcribe 的精簡版本,速度更快、效率更高
gpt-4o-mini-tts (文本轉語音):可控性強,用戶可以直接對它發號施令,不僅指定說什麼,還能教它怎麼說
在價格上,也有大驚喜:API價格,最低達到了每分鐘0.3美分!
跟昨天的o1-pro API的天價token相比,語音模型的API真可謂是良心價了。
要知道,昨天的OpenAI史上最貴API,輸入價格150美元/每百萬token,輸出價格600美元/每百萬token,比DeepSeek-R1要貴上千倍。
這也就意味著,以後像客服中心記錄電話或者記錄會議內容這樣的工作,都會變得更可靠,更方便,甚至更便宜!
語音轉文本的兩個全新模型,比起之前又來了一波大升級,比OpenAI原來的Whisper模型更準確,能更好地理解人類語音。
在多種語言上,有更低的詞錯誤率(WER)。
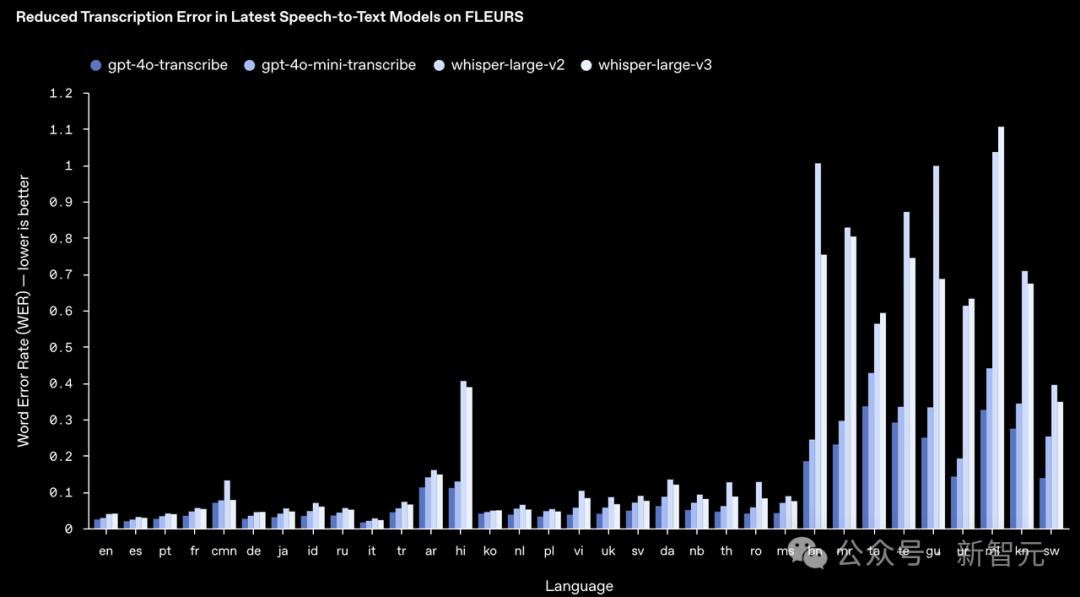 最新語音轉文本S湯臣模型,減少了在FLEURS上的轉錄錯誤率WER
最新語音轉文本S湯臣模型,減少了在FLEURS上的轉錄錯誤率WER 其中,語音轉文本GPT-4o-Transcribe在API中可用,每分鐘僅0.6美分,與Whisper價格相同,而GPT-4o-Mini-Transcribe是0.3美分,是滿血版的半價。
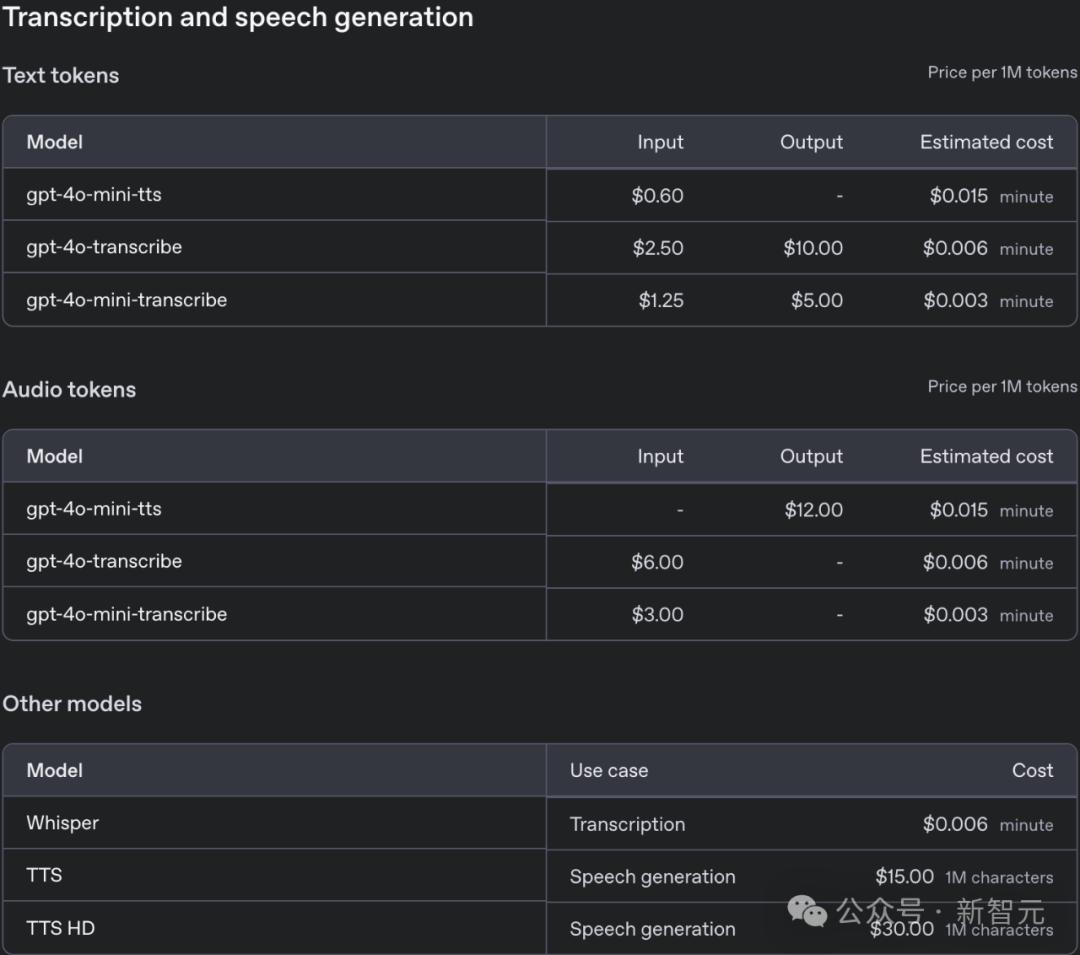 其他模型為OpenAI上一代語音模型
其他模型為OpenAI上一代語音模型 這些新模型可以通過API來使用,讓開發者能創建更智能、更個性化的語音助手。
從而更好地理解各種口音和快速說話,甚至在嘈雜的環境中也表現良好。
另外,OpenAI還推出了一個新的湯臣S(文本轉語音)模型:gpt-4o-mini-tts。
現在,OpenAI已經開放了免費體驗地址,只要輸入文字,就可以生成語音,還能選不同的語氣。
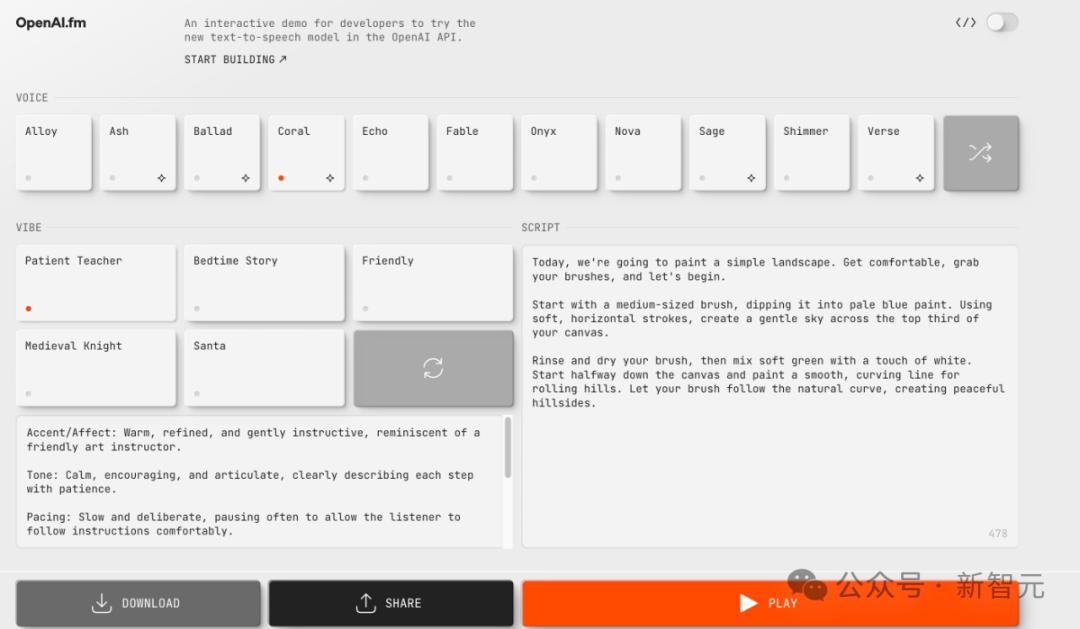 API體驗地址:https://www.openai.fm/
API體驗地址:https://www.openai.fm/ 現場實測
昨天淩晨的直播中,OpenAI給我們現場懟臉實測,展示了一番新的湯臣S模型實際表現到底怎麼樣。
首先,他們的VOICE(音色)選擇了Ash,然後在VIBE(大概是情感的意思)中隨機出了Mad Scientist(瘋狂科學家)。
之後輸入了需要合成音頻的腳本:
Ah-ha-ha! The stars tremble before my genius! The rift is open, theenergy surging-unstable? Perhaps. Dangerous? Most certainly!
Captain Rylen’s hands twitch over the controls. Fools! They hesitate, but I-I alone see the future! 「Engage the thrusters!」 I bellow, eyes wild with possibility.
The ship lurches, metal groaning-oh, what delicious chaos! Light bends,time twists,and then-800M!
Silence. Darkness. And then. oh-ho! A new universe! Bigger! Stranger! Andmine for the taking!
Ah-ha-ha-ha!
首次嘗試的時候沒輸出,不過刷新後很快模型正常輸出音頻,大家可以通過下邊影片感受一下模型的效果。
可以聽得出,合成的語音質量還是挺高的,基本上沒有多少AI味了,甚至還有一些高級感。
語音清晰,但語氣狂得飛起,聽起來就像一本正經的吹牛。
接著,他們又換了另一種VIBE:Serene(寧靜),輸入了下面的合成腳本:
This livestream is going really well! You are doing great.
這次的語音效果就顯得十分平靜,給人一種寧靜感,就像李白《靜夜思》的意境一樣。
還可以利用全新的的語言模式,直接調用智能體!
從今以後,文本智能體轉換為語音智能體變得輕而易舉。
直播中,演示了要在電話上使用Patagonia客服智能體,需要修改已有智能體的哪些代碼。
只用9行代碼,智能體不僅聽得懂人話,而且會開口說話了!
就像AI版的Siri,可以直接詢問最近的訂單,智能體聽起來就像真的客服一樣。
Agent調用工具,獲得相關信息後,回答自然,準確,流暢。
直播的結尾,還有一個小彩蛋。
OpenAI現場宣佈舉辦有獎競賽,可獲得全球限定版收音機:
誰能想出最有創意的文本轉語音使用方式,並分享給Open AI的Twitter賬戶,就有機會獲得特別版收音機。
他們會選出3位獲獎者,可能是因為這款收音機全世界只有三台,背面有Open AI的logo。
創意爆棚的小夥伴可以去碰碰運氣。

OpenAI,意在語音Agent
OpenAI在博客中稱,新的語音模型套件旨在為語音Agent提供強大支持,並已向全球開發者開放。

在最近幾個月裡,OpenAI一直在努力讓文本智能助手變得更聰明、更強大、更有用。
OpenAI推出了很多Agent產品,比如Operator、Deep Research、Computer-Using Agents和Responses API,這些都是為了幫助AI助手更好地完成任務。
但是,為了讓智能助手真正有用,需要讓AI能和人更自然、更深入地交流,就像我們和朋友聊天一樣。
所以,OpenAI讓智能助手不僅能理解我們的話,還能用自然的聲音回答我們。
現在,開發者還可以讓智能助手的語音聽起來更人性化,比如聽起來像一位溫柔的客服人員。這樣,智能助手就能更好地為客服、講故事等不同的場合服務。
自從2022年推出第一個音頻模型以來,OpenAI一直在努力讓AI變得更聰明、更準確、更可靠。
現在,開發者可以用這些新的音頻模型來創建更準確的語音轉文本系統和聽起來更自然的文本轉語音系統。
所有這些功能都可以通過API來實現。
全球領先的語音識別模型
昨天,OpenAI推出了兩款新的語音識別模型:gpt-4o-transcribe和gpt-4o-mini-transcribe。
它們比原來的Whisper模型更準確,能更好地理解我們說的話。
在幾個重要的測試中,gpt-4o-transcribe表現比Whisper模型好,錯誤更少。
這是因為OpenAI用了更先進的學習方法和更多音頻數據。
這些新模型能更好地理解人說話的細節,減少錯誤,特別是在有口音、很吵或者說話很快的情況下。
現在,這些模型已經可以在OpenAI的語音轉文本API中使用了。
新模型在多個測試中都取得了更低的WER,包括一個包含100多種語言的測試。這表明新模型在更多的語言上都能表現得很好。
指標「詞錯誤率」(word error rate,WER)用於衡量語音識別的準確性:WER越低,表示模型越準確。
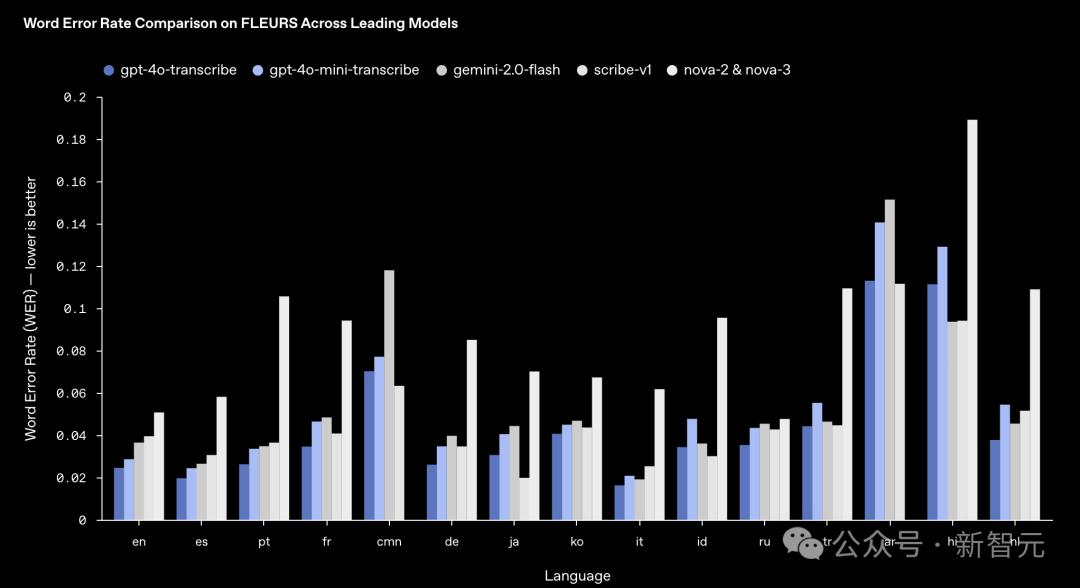
頂級模型在FLEURS上,不同語言的的WER比較
如圖所示,新模型在大多數主要語言上的表現都優於其他領先的模型。
這意味著OpenAI的語音識別技術,在全球範圍內都是領先的。
全新文本轉語音湯臣S模型
OpenAI還推出了全新的gpt-4o-mini-tts 模型,具有更好的可控性。
開發者們有福啦!現在可以對模型 「發號施令」,不僅能告訴模型該說什麼,還能教它怎麼說。
不管是搞客戶服務,還是進行創意故事創作,都能有超棒的定製體驗。
目前,已經在文本轉語音API里上線。
不過要注意,現在文本轉語音模型只有人工預設的聲音。
OpenAI會緊緊盯著,保證出來的聲音和預設的合成聲音一模一樣。
模型背後的技術創新
在真實音頻數據上預訓練
在GPT-4o和GPT-4o-mini架構之上,新的音頻模型在專門的以音頻為中心的數據集上進行了大量預訓練。
這些數據集對於優化模型性能至關重要。
這種有針對性的方法使得模型能更好地理解語音中的細微差別,從而在音頻相關任務中表現出色。
先進的蒸餾方法
OpenAI還改進了蒸餾技術,使得大型音頻模型能夠將知識有效地轉移到更小、更高效的模型中。
通過採用先進的自我博弈方法,蒸餾數據集成功捕捉了真實的對話動態,模擬了真實的用戶與助手的互動。
這幫助小型模型在對話質量和響應性上表現優秀。
強化學習範式
對於語音轉文本S湯臣模型,OpenAI引入了強化學習(RL)範式,讓轉錄準確度達到了最先進的水平。
這種方法顯著提高了精準度,並減少了幻覺,在複雜語音識別場景中具備了極強的競爭力。
這些技術進展代表了音頻建模領域的突破,結合創新的方法和實際的增強,提升了語音應用的性能。
API全球開放
這些新音頻模型現已向所有開發者開放。
更多關於如何使用音頻的內容,參閱OpenAI的相關文檔。
 API文檔:https://platform.openai.com/docs/guides/audio
API文檔:https://platform.openai.com/docs/guides/audio 添加語音轉文本和文本轉語音模型,最簡便方式的構建語音代理。
OpenAI還發佈了與Agents SDK的集成,開發過程更加簡單。
如果開發者希望構建低延遲的語音轉語音體驗,OpenAI建議使用語音轉語音模型來構建實時API。
OpenAI還提供了簡單的Demo,點擊下展示頁面Play按鈕,即可體驗人性化的機器語音。
 如需體驗,在https://www.openai.fm/上,點擊右上角切換按鈕即可
如需體驗,在https://www.openai.fm/上,點擊右上角切換按鈕即可 未來計劃:多模態AI
展望未來,OpenAI計劃繼續投資於提升音頻模型的智能性和準確性,並探索允許開發者引入自定義聲音的方式,從而打造更個性化的體驗,同時遵循安全標準。
此外,將繼續與政策製定者、研究人員、開發者和創作者進行對話,共同探討合成語音所帶來的挑戰與機遇。
OpenAI期待看到開發者利用這些增強的音頻能力,打造出創新和創意應用。
同時,也會投資於其他媒體形式——包括影片——以便開發者能夠構建多模態的智能體驗。
參考資料:
https://platform.openai.com/docs/pricing#transcription-and-speech-generation
https://www.youtube.com/live/lXb0L16ISAc
https://www.openai.fm/
https://openai.com/index/introducing-our-next-generation-audio-models/
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。