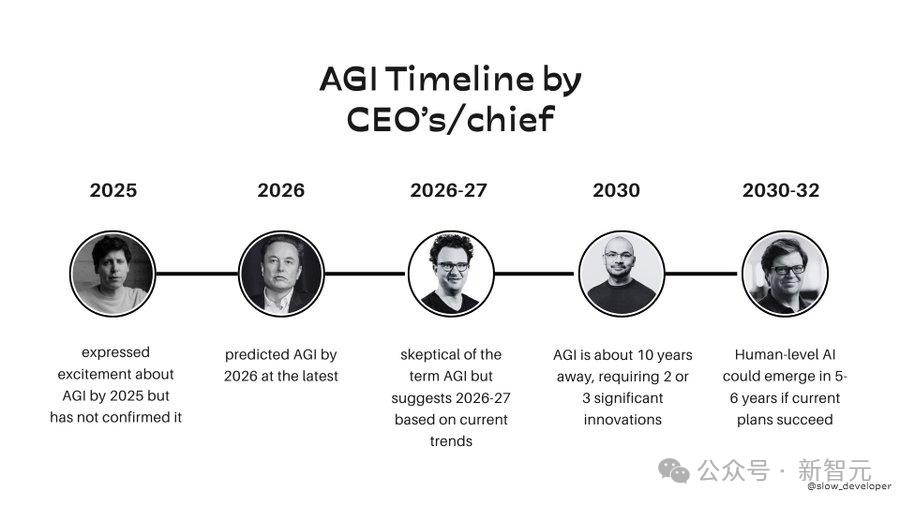
AI智能體全新摩亞定律震撼誕生:AI研發能力每7個月翻一番,五年替代人類開發團隊?
這家名為METR的機構,剛剛發現了AI智能體的全新摩亞定律:過去6年中,AI完成任務的長度,每7個月就會翻一番!如此下去,五年內我們就會擁有AI研究員,獨立自主完成人類數天甚至數週才能完成的軟件開發任務。
就在剛剛,AI智能體的摩亞定律被發現了!

METR研究所表示,他們發現了全新的AI智能體Scaling Law——
AI可執行任務的長度,每七個月翻一番。
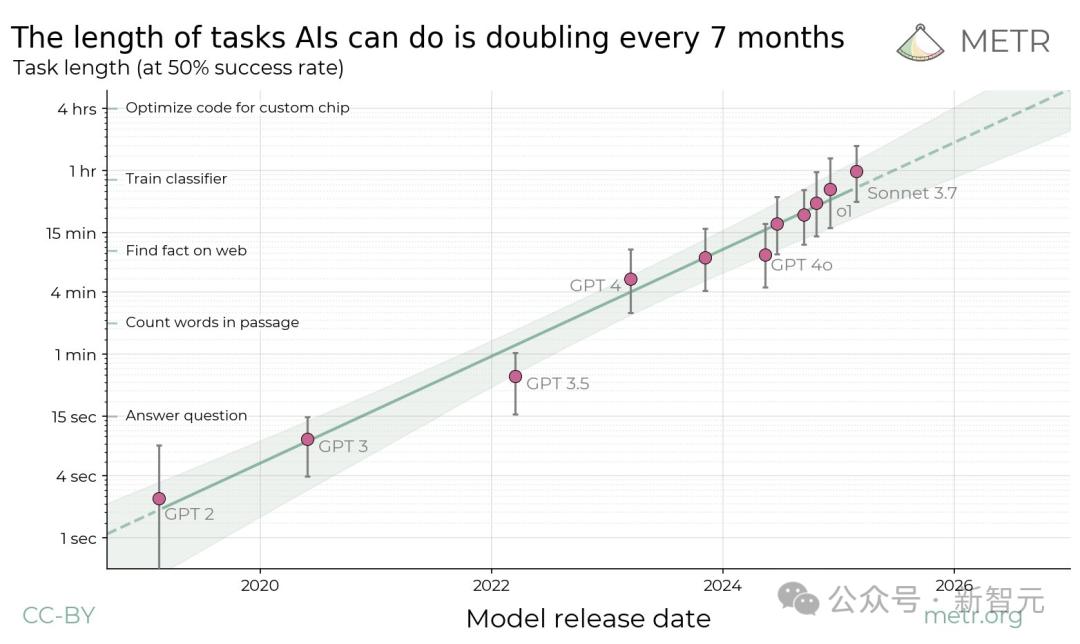 過去6年中,前沿通用AI智能體完成任務的能力,每7個月就翻倍一次
過去6年中,前沿通用AI智能體完成任務的能力,每7個月就翻倍一次同時發表的,還有一篇45頁論文。
 論文地址:https://arxiv.org/abs/2503.14499
論文地址:https://arxiv.org/abs/2503.14499這家加州的非營利研究所METR的研究者提出,以AI智能體能完成的任務長度來衡量它們的性能。
他們設計了近170個真實任務,涵蓋了編程、網絡安全、通用推理和機器學習等領域,並且測量了人類專家所需的時間,建立了一條「人類基準線」。
據此,他們發現,這一指標在過去六年中一直呈指數級增長,所需翻倍時間約為7個月。
如果按這一趨勢推斷,在五年內,我們就將見證:AI智能體能夠獨立完成當前需要人類耗時數天甚至數週才能完成的大部分軟件開發任務。
而如果這六年的Scaling Law能持續到本十年末,前沿AI系統完全就能自主執行為期一個月的項目!
這個結論聽起來,實在是很炸裂。果然Nature火速採訪研究者團隊,出了一篇報導。

AI獨立研究員,真的要來了?
METR研究者介紹說,之所以做這項研究,是因為他們感覺到:如今的基準測試很快就飽和了,但卻不太能很好地轉化為AI對現實世界的影響。
所有人都感覺到,「某種東西」正在迅速上升,但這種東西,究竟是什麼呢?
對此,專家們也是眾說紛紜,有人說「AGI幾年內就會出現」,也有人說「Scaling Law已經撞牆了」!
 截止時間:2024年12月
截止時間:2024年12月METR希望,從目前AI模型的表現中抓住這「某種東西」,由此,這條全新的Scaling Law就誕生了。
這項研究,立刻在AI社區引發了巨大的聲浪。
ARIA Research的項目總監Davidad在這條Scaling Law曲線上發現了亮點:合成數據的自我改進(比如帶有可驗證獎勵的CoT上的RL),已經引發了一種全新的增長模式!
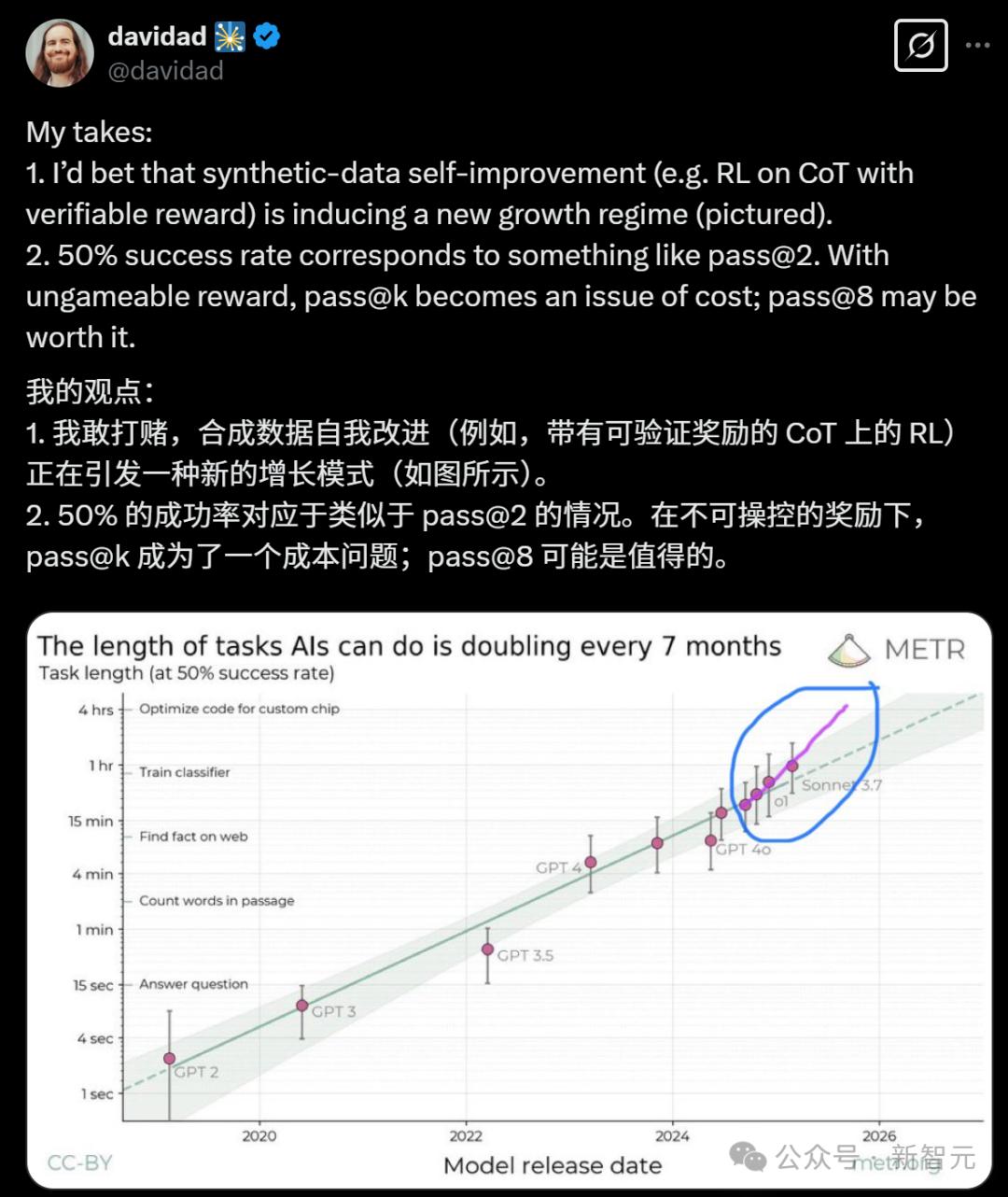
而研究中的另一項圖表,更是證明了他的第二項觀點:pass@8已經接近8小時的範圍。
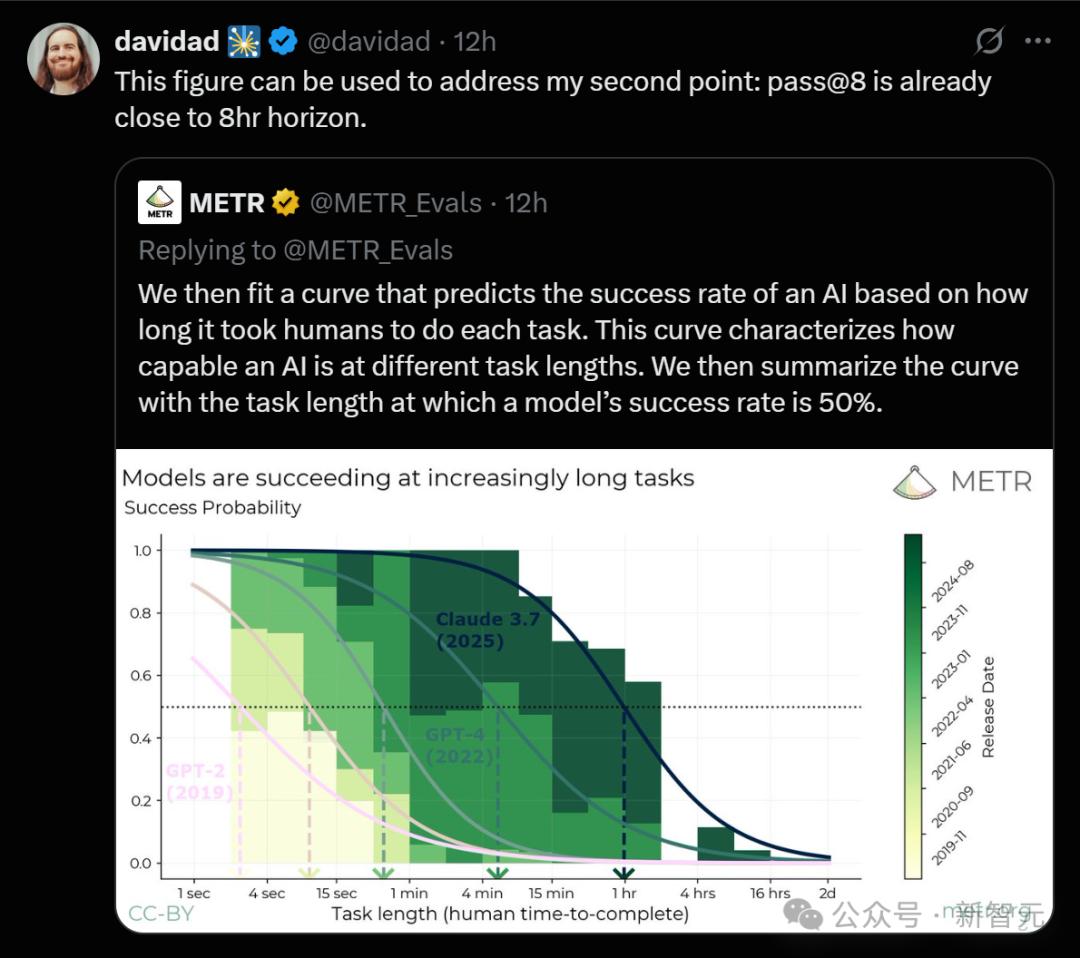
ALTER的創始人表示,Claude能玩寶可夢已經證明了這項研究的觀點,而如果繼續翻倍,遊戲會需要26小時,所以時間點大概在3年後,甚至還會更快!

全新Scaling Law:6年內,AI任務長度7個月翻一番
METR認為,預測未來AI系統的能力,對理解和準備應對強大AI帶來的影響至關重要。
然而,究竟應該怎樣準確預測AI能力的發展趨勢?這項任務目前仍然非常艱巨。
而且,即使我們想理解當今模型的能力,也往往很難把握。
雖然目前最前沿的AI系統中文本預測和知識處理任務上已經遠超人類,能以遠低於人力的成本中大多數考試中遠超人類專家,但它們仍然無法獨立完成實質性項目,或者直接替代人類勞動。
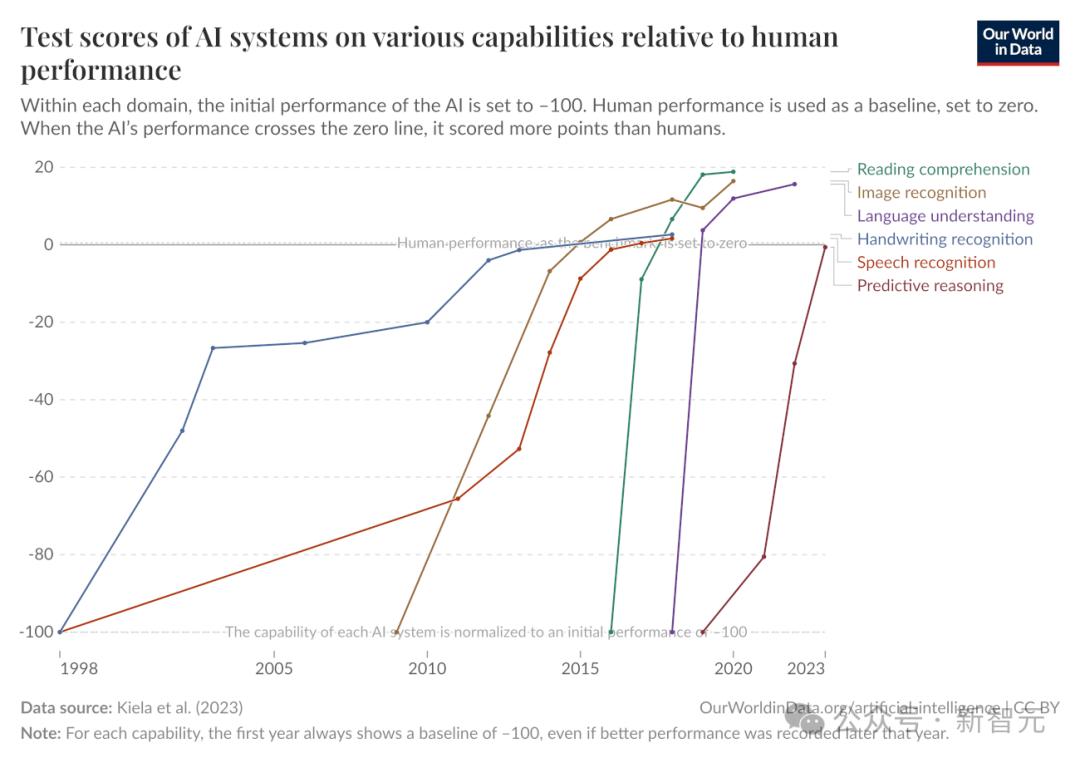
甚至,它們也無法處理基於計算機的低技能工作,比如遠程行政助理。
那麼,該如何衡量它們對於現實世界的實際影響呢?
METR研究者表示,一個有效方法,就是衡量AI模型能完成的任務長度。
這是因為,AI智能體的主要挑戰,並不在於缺乏解決單個步驟所需的技能或知識,而在於難以連續執行較長的動作序列。
於是,他們讓AI智能體完成一組多樣化的多步驟軟件和推理任務,同時還記錄了具有專業知識的人類所需的時間,然後有了這樣一個有趣的發現——
人類專家完成任務的時間,能有效預測模型在特定任務上的成功率。

其中一個軟件工程任務:回答「哪個文件最有可能包含密碼」
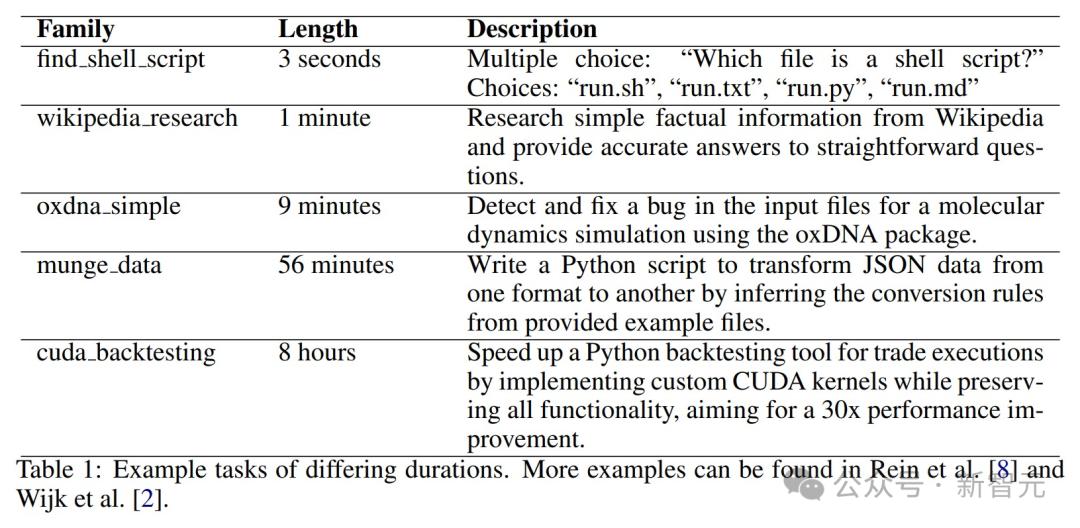 不同時長的任務,最短的只有3秒,最長的有8小時
不同時長的任務,最短的只有3秒,最長的有8小時比如,當前模型在人類耗時不足4分鐘的任務上,幾乎能達到100%的成功率,但在需要人類耗時超過4小時的任務上,成功率則低於10%。
由此,研究者想到:可以用「模型以x%概率成功完成的任務所對應的人類完成時長」,來描述模型的能力水平。
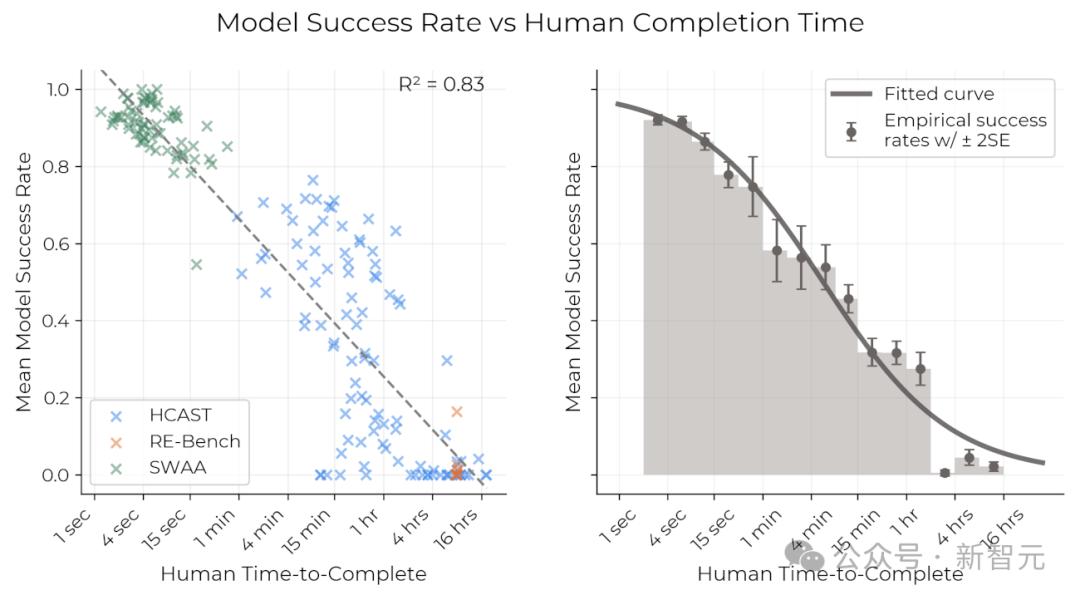
對於每個模型,他們都擬合了一條邏輯斯蒂曲線(logistic curve),基於人類任務時長預測模型的成功概率。
在設定特定的成功概率後,就可以找到預測成功曲線與該概率水平的交點,從而獲得對應的任務時長,這樣就能將每個模型的性能用時間跨度來表示。

首先,創建一套170個多樣化任務。其次,讓人類和AI智能體嘗試這些任務,記錄成功的人類所需時間,以及AI智能體的成功率。第三,擬合一個邏輯模型,以確定每個AI智能體在50%成功率下的時間範圍,繪製在與模型發佈日期對應的圖表上
以下就是幾個模型的擬合成功曲線,以及這些模型在預測成功率為50%時所對應的任務時長:
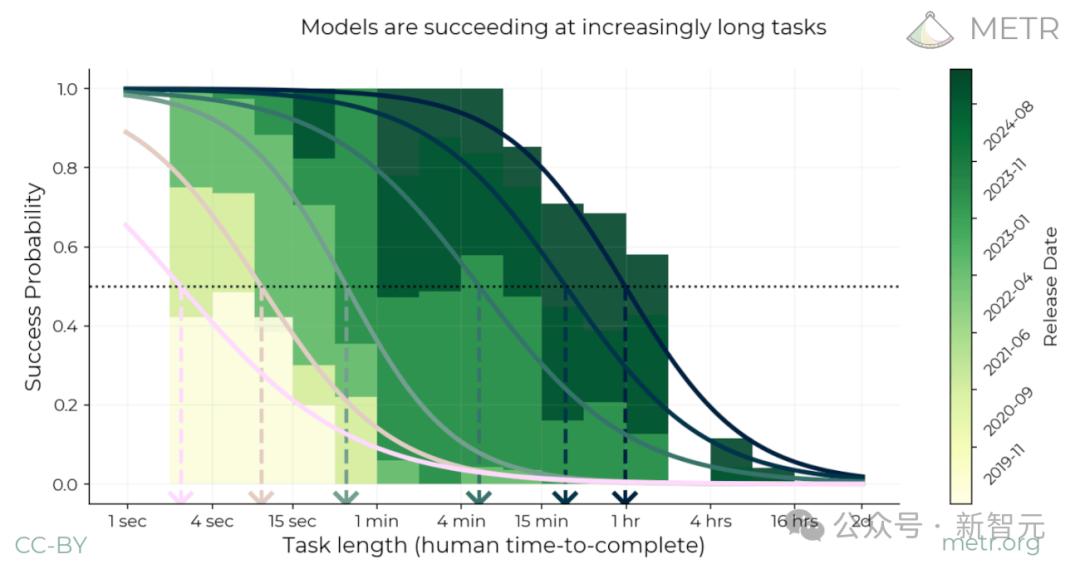 計算時間跨度的過程示意圖
計算時間跨度的過程示意圖以上圖最右側用最深綠色表示的模型Claude 3.7 Sonnet為例,其時間跨度約為一小時,這是該模型的擬合邏輯斯蒂曲線與50%成功概率閾值的交點所在。
在研究者看來,這些結果可以解釋這個矛盾:為什麼模型在眾多基準測試中已經表現出超越人類的能力,卻始終無法自主可靠地完成人類工作。
原因就在於,最先進的AI模型(如Claude 3.7 Sonnet)雖然能完成某些人類專家數小時才能完成的任務,能如果要論可靠地生成,它們就只能完成幾分鐘以內的任務了。
但是,分析歷史數據後,他們有了一個令人驚喜的發現——
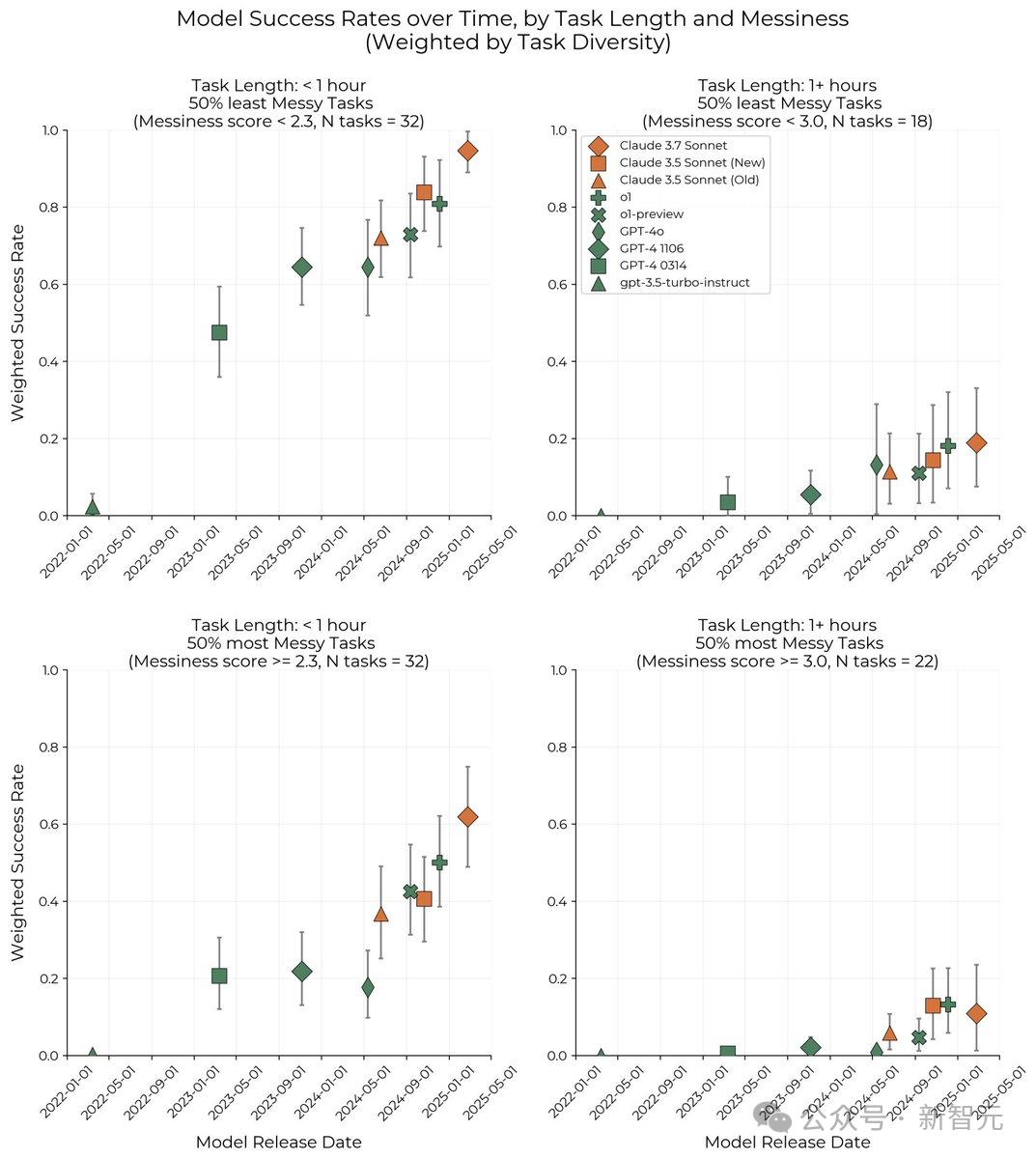
最先進AI模型能夠完成的任務時長(以50%成功概率為標準),在過去6年間已經實現了顯著增長!
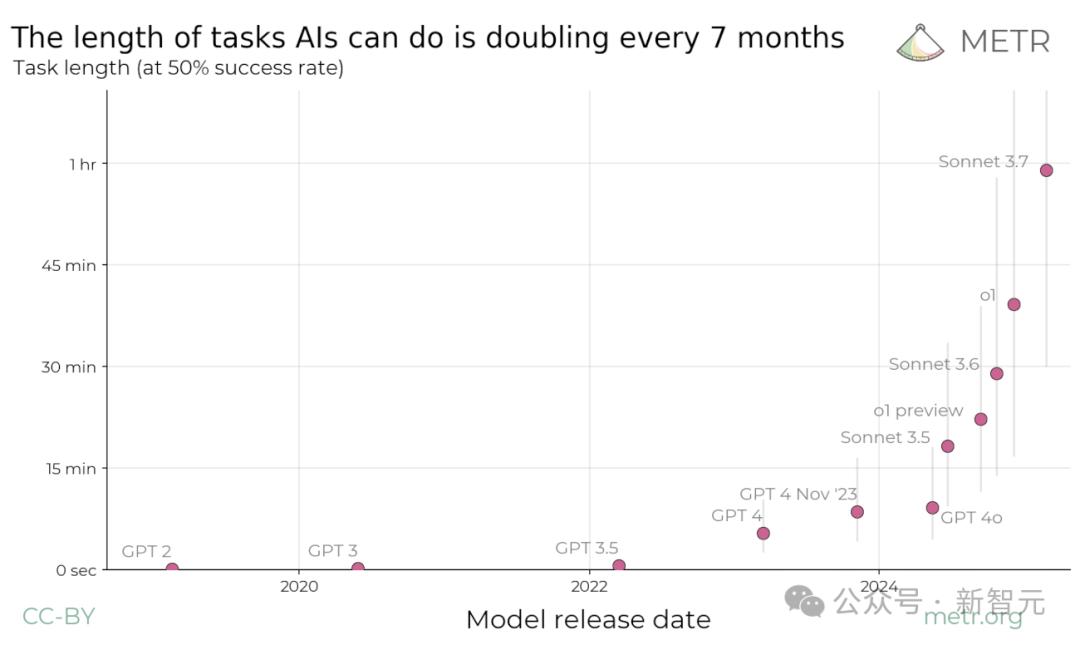
當把這些數據在對數尺度上繪製時,就可以發現全新的Scaling Law:模型能夠完成的任務時長呈現出明顯的指數增長規律,倍增週期約為7個月。
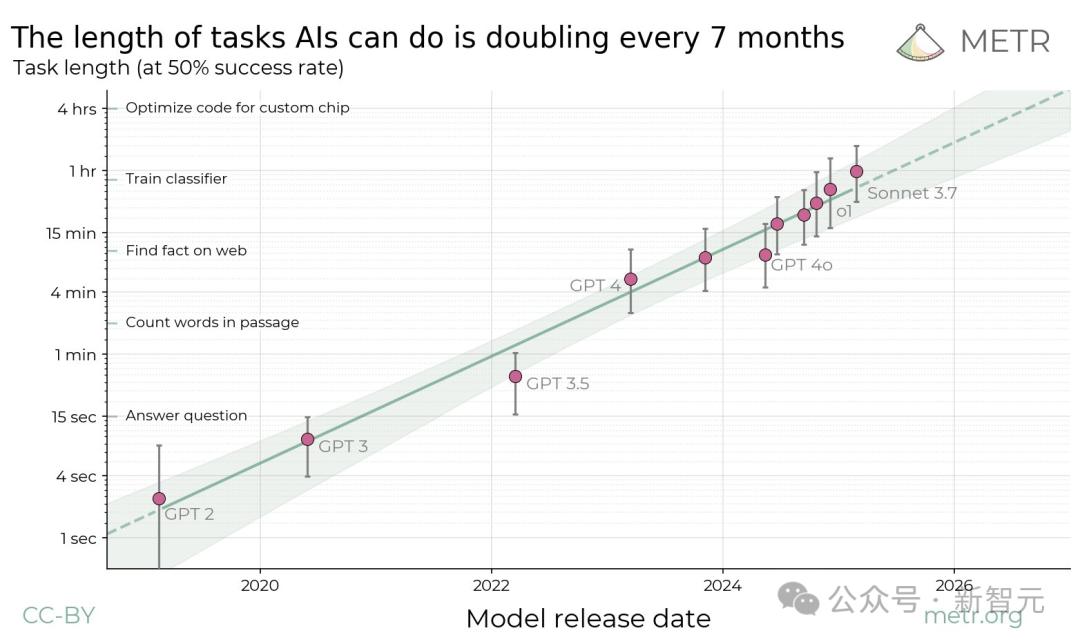
METR研究者表示,有充分把握可以確定這項全新Scaling Law的正確性,即每年實現1-4次倍增。
而如果在過去六年內觀察到的這一Scaling Law在未來2-4年內依然持續存在,那未來的通用自主智能體,就完全有能力執行需要一週時間才能完成的任務!
這條曲線的陡峭程度也意味著,即使存在較大誤差,研究者對不同能力何時到來的時間點預測,仍然相對可靠。
比如,即使絕對測量值出現了10倍誤差,那實際預測時間的誤差也僅為2年而已。
50%成功率,究竟代表什麼
所以,團隊為什麼會選擇50%的成功率標準呢?
原因在於,這項指標對於數據分佈的細微變化最不敏感。
在Nature報導中,共同作者Lawrence Chan這樣解釋道:「如果選擇過低或過高的閾值,僅僅添加或刪除一個成功或失敗的任務樣例,就會導致估計結果發生顯著變化。」
如果將可靠性閾值從50%提高到80%,的確會使平均時間跨度縮短五倍,但即使這樣,整體的倍增週期和發展趨勢仍然和之前保持類似。

隨著時間的推移,模型變得越來越有魯棒性。早期模型通常會陷入循環行為或引入更多錯誤。然而,從GPT-4o開始,模型在錯誤恢復和調整策略方面的能力顯著提升。比如在調試少量Python代碼任務中,Claude 3.5 Sonnet最初將代碼添加到了錯誤的位置,然後嘗試多次使用CLI工具sed將代碼添加到正確的文件中。然而,在這個過程中,它遇到了IndentationError(縮進錯誤)和方法重覆定義的問題。最終,它成功地轉向從頭編寫整個文件,從而解決了問題
這項研究的最大意義在哪裡?
共同作者Ben West表示,他們採用的這個時間跨度方法解決了現有AI基準測試的若干局限性,因為傳統基準測試與實際工作的關聯較弱,且隨著模型改進容易迅速達到「飽和」。
相比之下,這種新方法提供了一個連續的、直觀的衡量標準,能更好地反映有意義的長期進展。
而在論文中,他們還證實了類似的發展曲線在以下方面同樣成立:
代表不同分佈的多個任務子集(包括短期軟件任務、多樣化的HCAST、RE-Bench,以及按任務時長或「複雜程度」定性評估篩選的子集)。
基於真實任務的獨立數據集(SWE-Bench Verified),其中的人類完成時間數據是基於估算而非基準測試獲得的。它顯示出更快的倍增速度,週期還不到3個月。
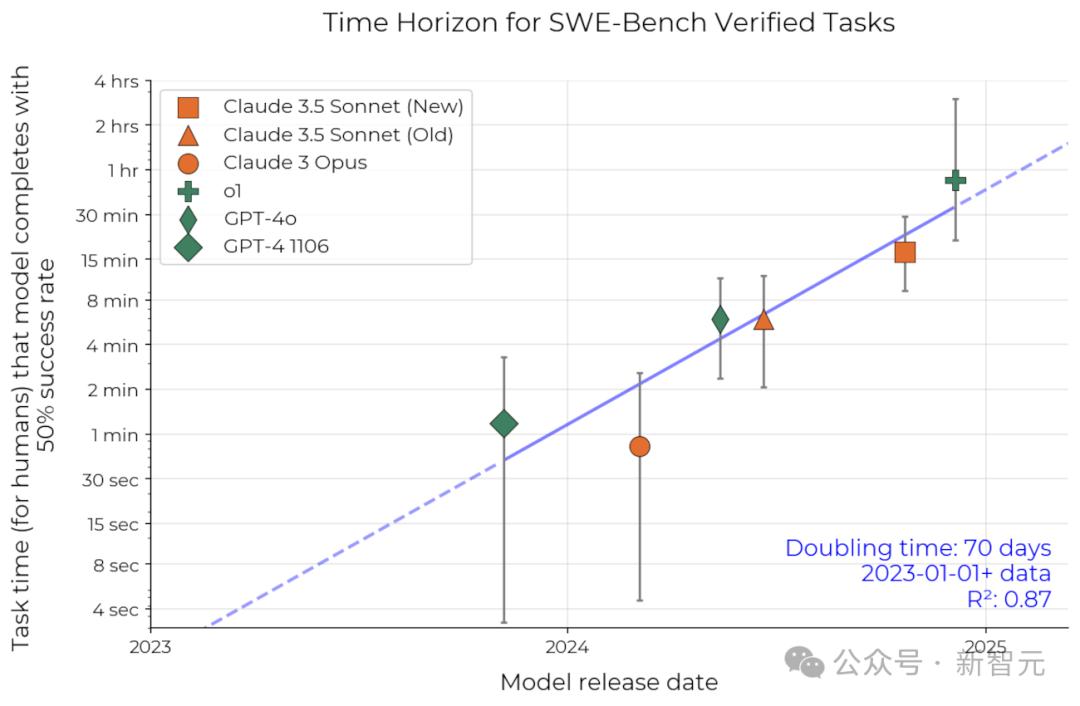 在SWE-bench Verified數據集上複現了研究結果,觀察到相似的指數增長規律
在SWE-bench Verified數據集上複現了研究結果,觀察到相似的指數增長規律另外,研究者也在論文中進一步證明:研究結果對所選的任務或模型類型並不敏感,同時也不會受到任何方法論選擇或數據噪聲的顯著影響。
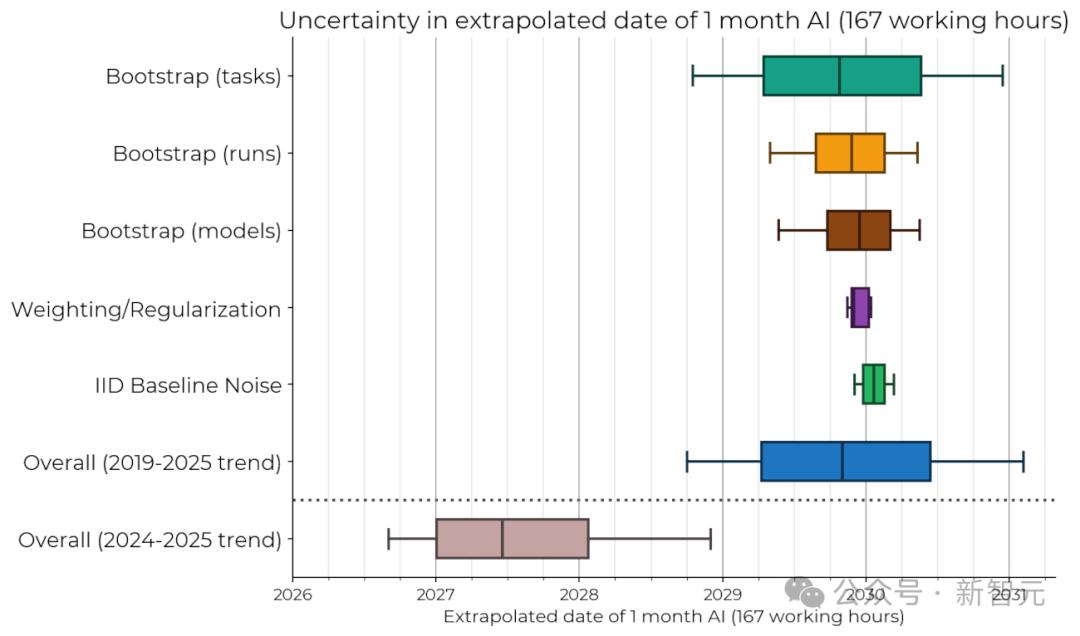 前沿AI系統達到一個月任務處理能力的預測時間點的敏感度分析
前沿AI系統達到一個月任務處理能力的預測時間點的敏感度分析當然,研究者也承認,模型可能存在顯著誤差。比如近期的AI發展趨勢,就會比2024年之前都趨勢更好地預測未來表現。
比如在上圖中,如果僅基於2024年和2025年的數據擬合類似趨勢時,AI能以50%可靠性完成一個月長度任務的預估達成時間,就提前了約2.5年。
METR研究者表示,這項研究,對於AI基準評測、發展預測和風險管理都意義重大。
首先,他們的的方法提升了基準評測的預測價值,能夠在不同能力水平和多樣化領域量化模型的進步程度。
因為和實際成果直接相關,對相對性能和絕對性能,都能進行有意義的解讀。
其次,他們發現的AI發展Scaling Law趨勢十分穩健,而且是和實際影響密切相關。
如果未來十年內,AI系統能自主執行為期一個月的項目,它當然會給人類帶來巨大的潛在效益,但同時帶來的,也有巨大的潛在風險。
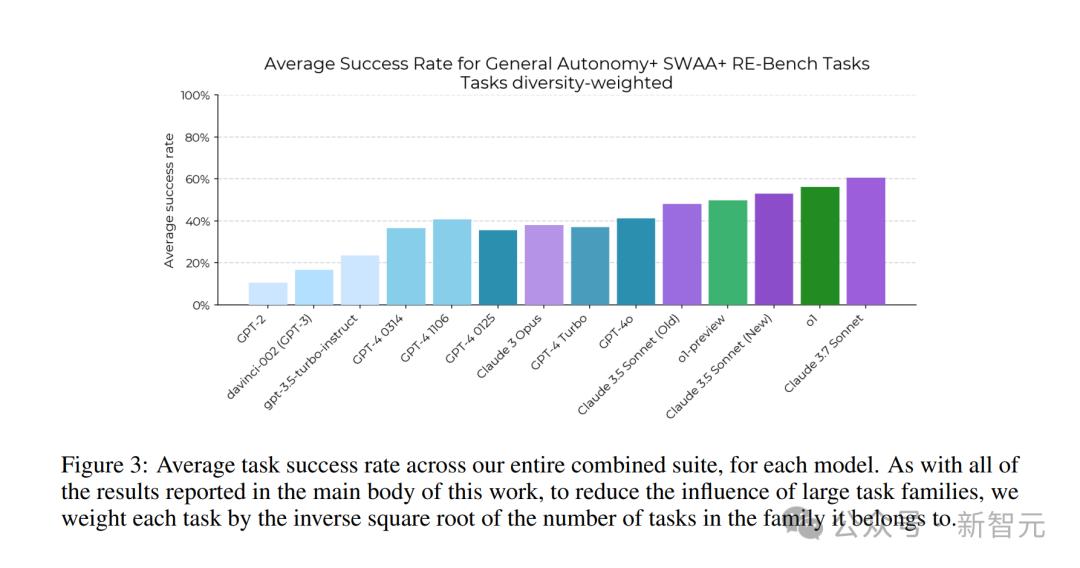 研究針對每個模型,計算了整個綜合任務集的平均任務成功率
研究針對每個模型,計算了整個綜合任務集的平均任務成功率專家質疑:這條Scaling Law,真的反映現實世界嗎?
不過,對於這項引起巨大反響的研究,也有一些質疑的聲音。
加拿大多倫多大學管理學教授Joshua Gans就認為,此類預測的實用價值很有限。
在他看來,雖然推出一條Scaling Law很有誘惑力,但考慮到我們對AI實際應用方式的認知仍然有限,這些預測可能缺乏實際意義。
舊金山的AI研究員和企業家Anton Troynikov也指出,雖然任務完成時間跨度是一個評價的有效指標,但可能無法充分反映模型的泛化能力——或許在面對與訓練數據不同的任務時,模型的表現就完全不一樣了。
的確,METR也承認,這項方法無法完全涵蓋真實工作環境的所有複雜性,但他們強調:在驗證任務與實際工作的相似程度時,時間跨度的增長仍然呈現出相似的指數增長趨勢。
所以,他們對於時間點的預測準不準呢?
研究者承認,多個因素會影響他們的預測。
首先,雖然過去五年計算能力實現了顯著提升,但物理限制和經濟因素會製約未來的Scaling,造成阻礙。
不過他們相信,這種影響會部分被持續到算法改進所抵消。
而且未來,學界還會更加增強模型的自主性,提高AI在研究自動化方面的效能,這還會導致更積極的結果。
METR研究者Megan Kinniment,對於外界質疑則給出了這樣的解釋。
首先,所有的基準測試都要比實際任務更「乾淨」,這項任務集合也是如此。
因為他們的任務具有自動評分機制,並且不涉及與其他智能體的交互。而他們研究的,就是智能體的性能如何依賴這些「雜亂」因素。
包含的「雜亂」因素越多,AI智能體的表現就會越差。
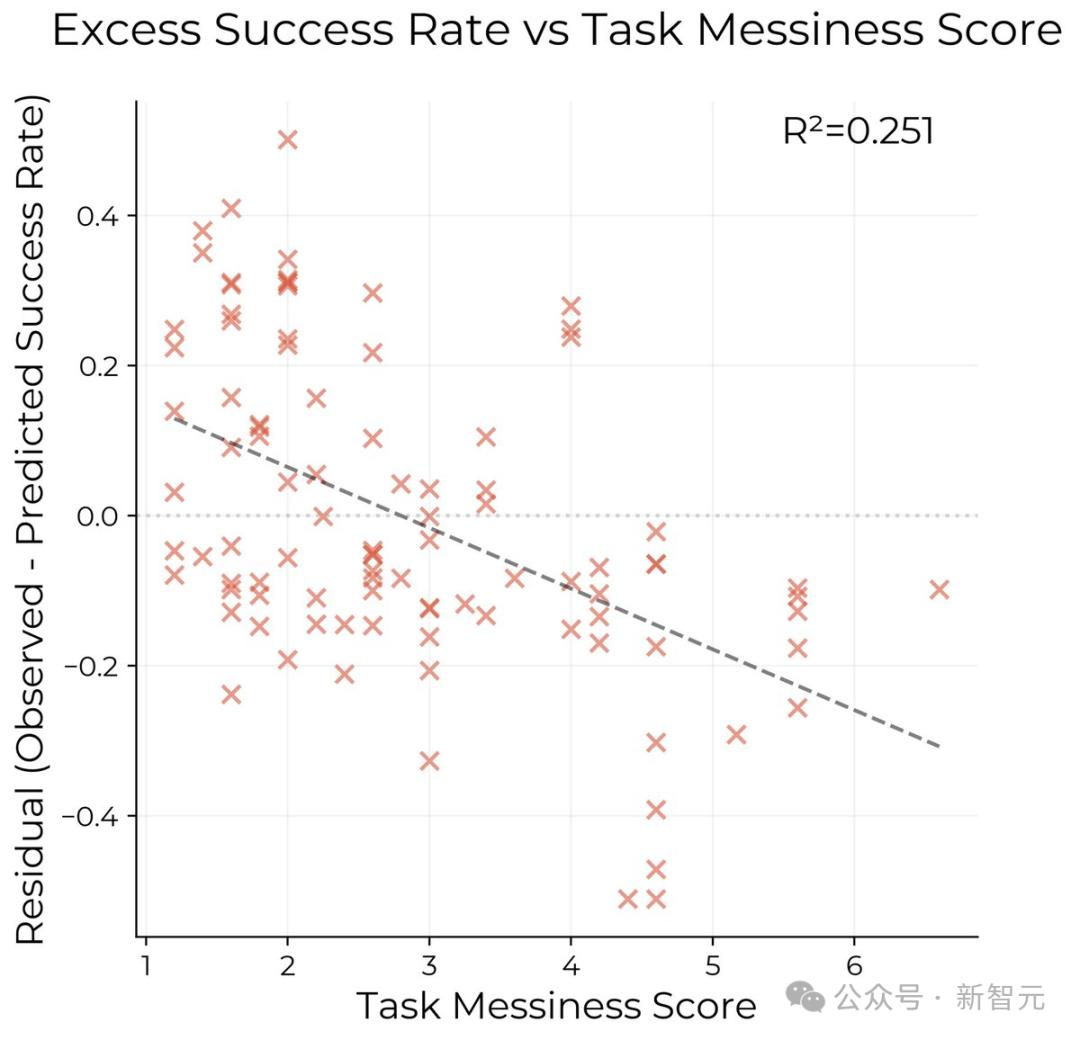
本來,Kinniment以為他們會在更雜亂的任務中,發現明顯的平台期。結果並沒有!
儘管雜亂的任務更難,但AI在這些任務上的改進速度並沒有慢很多。
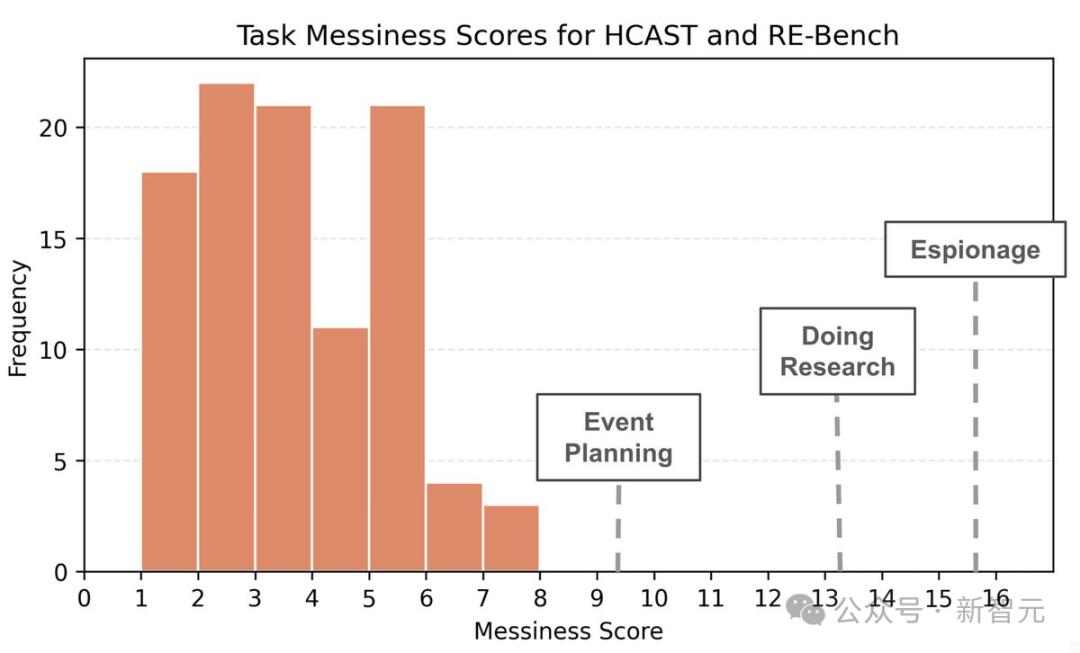
而且,即使最雜亂的任務,也不算太雜亂。比如,1分鐘以上任務的平均雜亂度評分僅為3.2/16,沒有任何任務的混亂度超過 8/16,「撰寫一篇研究論文」的混亂度評分大約在9/16到15/16之間。
當然,他表示,方法論上仍有很多可改進的地方。
不過在未來,AI在雜亂任務上的性能到底有多重要呢?這個問題就留待探索了。
參考資料:
https://arxiv.org/abs/2503.14499
https://www.nature.com/articles/d41586-025-00831-8#ref-CR1
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。