一名高中生創建AI測試網站,讓用戶能和模型在《我的世界》中進行建造比賽
隨著傳統的 AI 基準測試被證明存在不足之處,AI 開發者們正在轉向更具創意的方法來評估生成式 AI 模型的能力。對於 12 年級的阿迪·辛格(Adi Singh)來說,這個方法是《我的世界》(Minecraft),一款微軟旗下的沙盒建造遊戲。
 (來源:MINECRAFT)
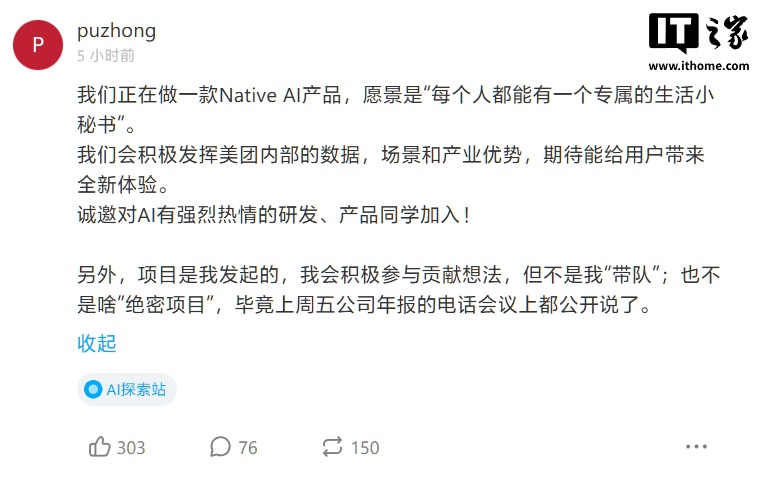
(來源:MINECRAFT)Minecraft Benchmark(下稱「MC-Bench」)網站是辛格和他人合作開發的,目的是讓 AI 模型在挑戰中相互競爭,應對提示的方式則是直接用《我的世界》完成創作。用戶可以投票選出哪個模型做得更好,只有在投票後才能看到每個《我的世界》作品都是由哪個 AI 完成的。
《我的世界》的價值並不在於遊戲本身,而在於人們對它的熟悉程度。畢竟,它是有史以來最暢銷的電子遊戲之一。
辛格表示,《我的世界》讓人們能更輕鬆地看到 AI 發展的進展。人們熟悉《我的世界》,也習慣了它的畫面風格和整體氛圍。
 (來源:https://mcbench.ai/about)
(來源:https://mcbench.ai/about)MC-Bench 網站上目前列出了幾位貢獻者。根據 MC-Bench 網站的信息,Anthropic、Google、OpenAI 和阿里巴巴已資助該項目使用它們的產品來運行基準測試提示,但這些公司並未以其他方式參與該項目。
辛格表示,目前他只是在進行一些簡單的構建,以反思 AI 領域從 GPT-3 時代以來所取得的進步,但他未來可能會考慮擴展到更長期的項目,以及其他以目標為導向的任務。其表示,遊戲可能只是一種測試代理推理的媒介,它比現實生活更安全,也更容易控制以用於測試目的。
其他遊戲比如《Pokemon紅》《街頭霸王》和《你畫我猜》也被用作 AI 的實驗基準,這在一定程度上是因為對 AI 進行基準測試這門「藝術」向來極為棘手。
 (來源:MINECRAFT BENCHMARK)
(來源:MINECRAFT BENCHMARK)研究人員經常在標準化評估中對 AI 模型進行測試,但許多此類測試會讓 AI 具有天然優勢。由於訓練方式的原因,這些模型天生擅長解決某些特定領域的難題,尤其是那些需要死記硬背或簡單推理的問題。
簡而言之,我們看到 OpenAI 的 GPT-4 可以在法學院入學考試中取得 88% 的成績,但卻無法準確說出「strawberry」這個詞中有多少個「r」。Anthropic 的 Claude 3.7 Sonnet 在標準化軟件工程基準測試中的分數為 62.3%,但它在玩《寶可夢》遊戲時的表現卻比大多數五歲兒童還要差。
 (來源:MINECRAFT BENCHMARK)
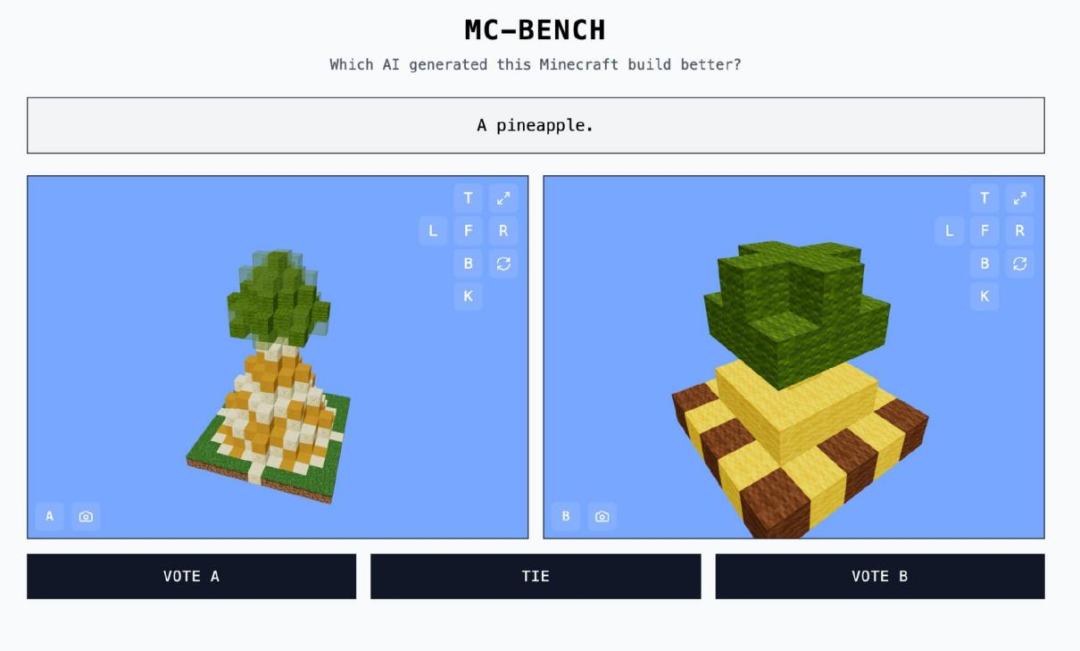
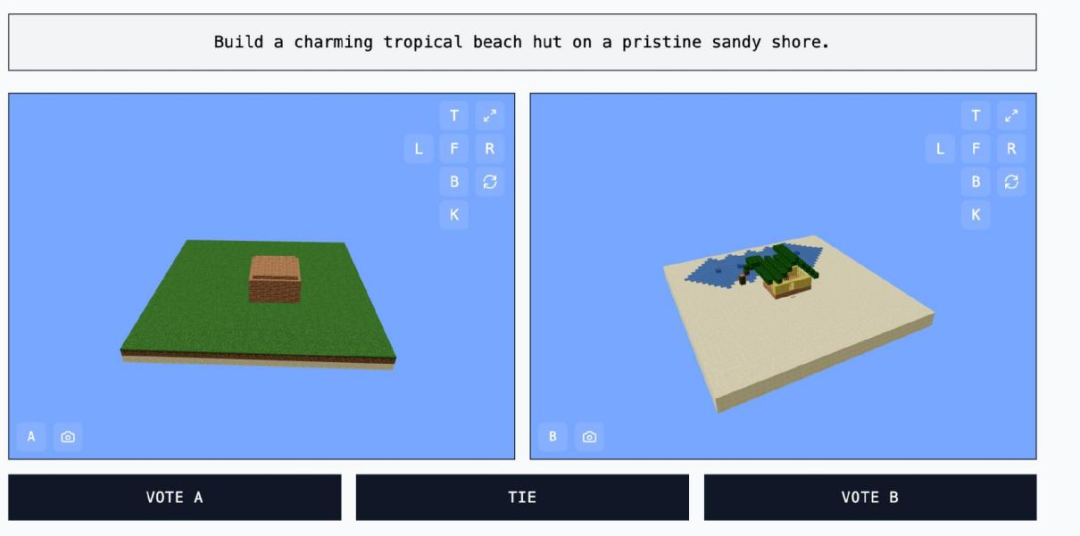
(來源:MINECRAFT BENCHMARK)從技術上講,MC-Bench 是一個編程基準測試,因為模型被要求編寫代碼(完成構建)來回應提示,例如創造「雪人 Frosty」或「原始沙灘上迷人的熱帶海灘小屋」。
但對於大多數 MC-Bench 評判者來說,評估一個雪人看起來是否更好,比深入研究代碼要容易得多,這使得該項目具有更廣泛的吸引力,並因此有可能獲得更多關於哪些模型持續得分更高的數據。
當然,這些分數是否對 AI 的實用性有重大影響還有待商榷。不過,辛格堅信這是一個強烈的信號。
其告訴媒體,目前 MC-Bench 的測試結果排行榜非常接近於他自己使用這些模型的經驗,這與許多純文本基準測試是不同的,因此也許 MC Bench 對於相關公司是有用的,可以幫助這些公司瞭解自己是否正在朝著正確的方向前進。
參考資料:
https://mcbench.ai/
https://x.com/_mcbench
https://github.com/mc-bench
運營/排版:何晨龍