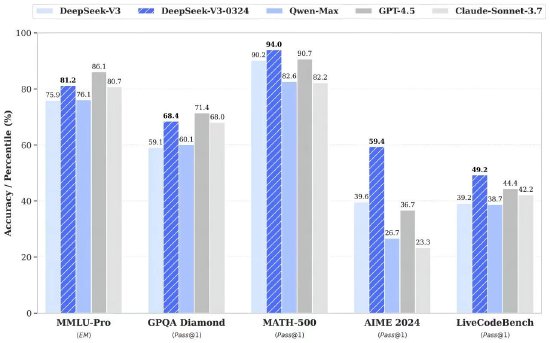
田淵棟和Sergey Levine參與開發新型RL算法,能通過多輪訓練讓智能體學會協作推理
機器之心報導
編輯:Panda
強化學習提升了 LLM 各方面的能力,而強化學習本身也在進化。
現實世界中,很多任務很複雜,需要執行一系列的決策。而要讓智能體在這些任務上實現最佳性能,通常需要直接在多輪相關目標(比如成功率)上執行優化。不過,相比於模仿每一輪中最可能的動作,這種方法的難度要大得多。
在直接優化多輪目標方面,一類自然的方法是應用單輪 RLHF 算法,例如 RAFT、DPO 和 PPO ,不過這些方法不會在不同輪次間執行顯式的 credit 分配。因此,由於複雜順序決策任務的長期性,它們可能會出現高方差和較差的樣本複雜性等問題。
另一種選擇是應用價值函數學習方法,例如 TD 學習。然而,這需要在 LLM 表徵的基礎上訓練一個新的特定於任務的價值頭,這可能無法在有限的微調數據下很好地泛化。因此,目前尚不清楚哪種多輪 RL 算法最有效,能夠充分利用 LLM 的推理能力來訓練通用、有能力和目標導向的智能體。
近日,Meta FAIR 和加利福尼亞大學伯克利分校一個研究團隊在這個研究課題上取得了新的突破。首先,他們為該問題構建了一個新的基準:ColBench(Collaborative Agent Benchmark)。在此基礎上,他們還提出了一種易於實現但非常有效的 RL 算法:SWEET-RL(RL with Step-WisE Evaluation from Training-Time Information)。

-
論文標題:SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
-
論文地址:https://arxiv.org/pdf/2503.15478
-
代碼地址:https://github.com/facebookresearch/sweet_rl
這篇論文的一作為伯克利 AI 研究所(BAIR)二年級博士生周逸飛(Yifei Zhou)。並有多位著名 AI 研究者參與其中,包括田淵棟、Jason Weston 和 Sergey Levine。
下面我們就來簡單解讀一下這項研究,更多詳情請參閱原論文。
ColBench
先來看看他們提出的新基準。首先,為瞭解決為 LLM 智能體開發多輪 RL 算法的挑戰,該團隊構建了一些基本設計原則,包括:
-
應具有足夠的任務複雜性,可以挑戰智能體的推理和泛化能力。
-
儘可能地降低開銷,以支持快速研究原型設計。
-
應該有足夠的任務多樣性,以便在 RL 訓練時不會過擬合。
接下來,具體看看該基準中的兩個任務:後端編程和前端設計。
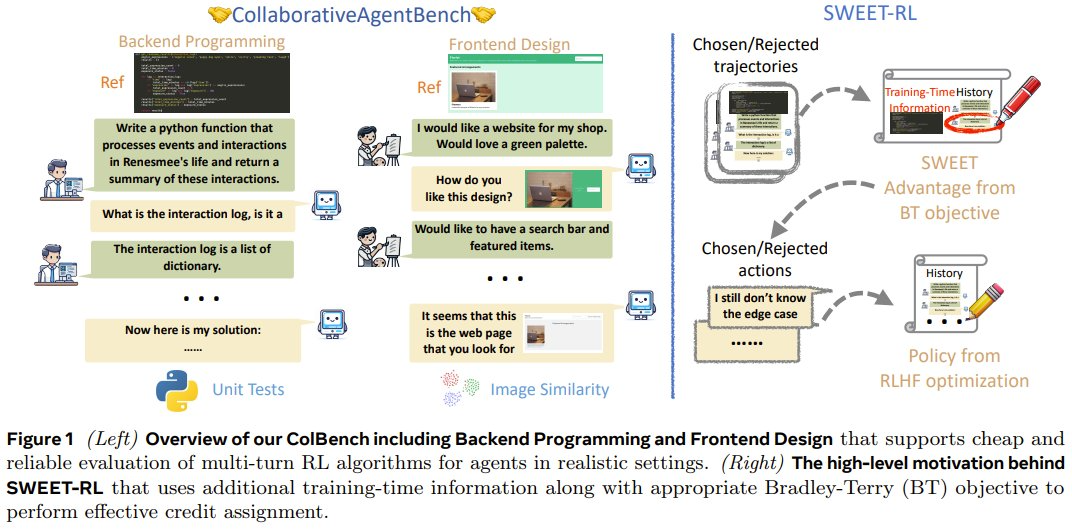
後端編程協作
在此任務中,智能體需要與人類模擬器協作編寫自定義 Python 函數(最多 50 行)。
在協作開始時,智能體會先獲得高級描述和函數簽名。但並不會提供很多具體的細節,例如應考慮哪些條件以及在邊緣情況下該怎麼做。智能體必須推理並決定需要人類模擬器提供哪些具體說明。人類模擬器需要根據只有它們自己可見的參考代碼,用自然語言對每個需要說明的問題提供簡要解釋,但不會編寫代碼。
智能體和人類模擬器之間的交互僅限於 10 輪來回。當智能體決定給出最終解決方案或達到最大輪數時,交互結束。
在評估智能體是否成功時,需要對每個函數進行 10 次隱藏單元測試,並對每次協作給出 0 或 1 的獎勵。
前端設計協作
在此任務中,智能體需要與人類模擬器協作,通過編寫 HTML 代碼片段(約 100 行)來設計網頁。
在協作開始時,智能體會獲得網頁的高級描述。同樣,許多具體細節(例如網頁的佈局和調色板)都缺失,只有人類模擬器才能看到。在每一輪中,智能體都有機會編寫 HTML 結果並通過 Web 瀏覽器呈現出來。人類模擬器可以對比來自智能體的網頁和參考網頁,然後向智能體描述它們的差異。與後端編程協作類似,當智能體決定給出最終解決方案或達到最大 10 輪交互時,交互結束。
評估指標方面,使用了智能體解答與參考網頁之間的 CLIP 嵌入的餘弦相似度。同樣,協作結束時,會發放 0 或 1 的獎勵。
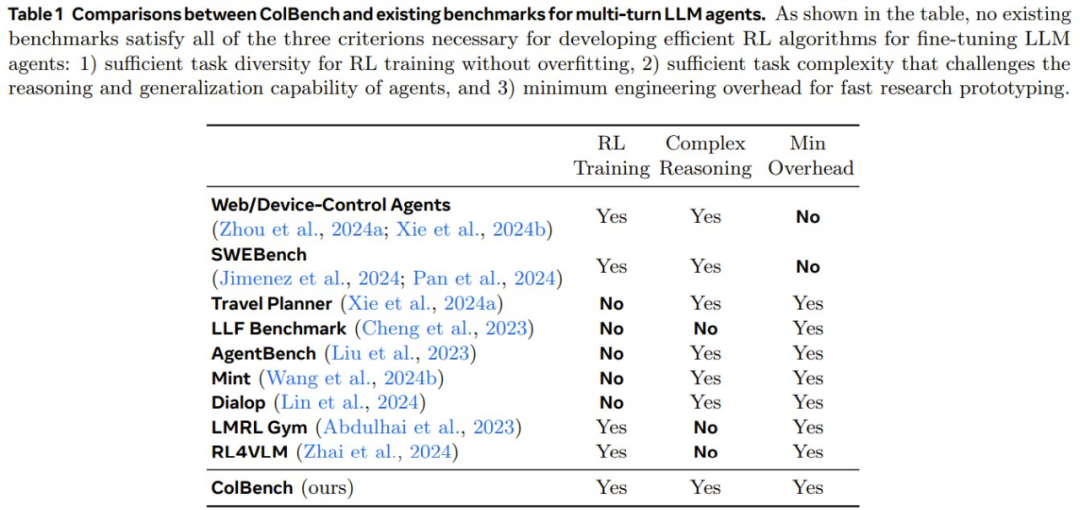
表 1 比較了 ColBench 與現有的其它基準。
SWEET-RL
SWEET-RL 是一種兩階段訓練方法,如圖 2 所示。
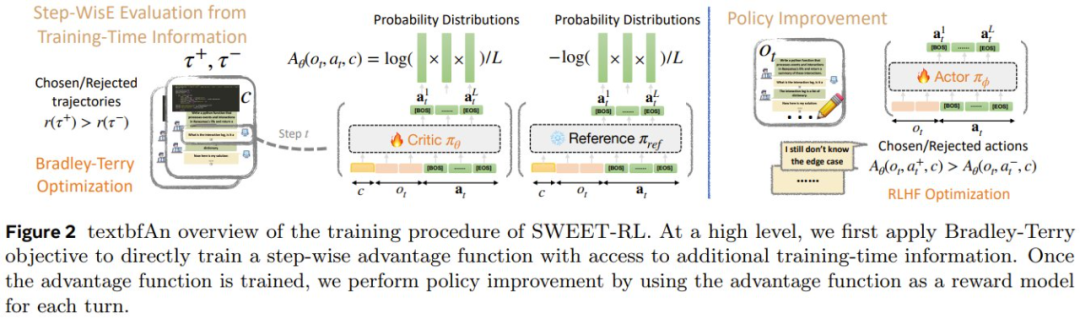
第一階段:學習各個輪次的優勢函數
為了在推理密集型任務中執行顯式 credit 分配,之前一些研究使用的方法是:先學習一個顯式的價值函數,然後從學習到的價值函數中得出每個單獨動作的優勢。
然而,該團隊的實驗發現,當微調只能使用有限數量的樣本時,這種價值函數不能很好地泛化。他們猜想這是因為在推理密集型任務中學習準確的價值函數本身就是一項艱巨的任務,並且不能有效地利用預訓練 LLM 的推理和泛化能力。
由於執行 credit 分配的最終目標是得出每個動作的優勢,這對於 LLM 來說可能比估計預期的未來回報更容易,因此該團隊提出直接學習每個輪次動作的優勢函數。
考慮到偏好優化已經在 LLM 微調方面得到成功應用,因此該團隊提出根據軌跡的偏好對來訓練每輪次優勢函數。
給定同一任務的兩條軌跡,並附加訓練時間信息 c,根據它們的累積獎勵將它們標記為選取 τ+ 和拒絕 τ−。這樣一來,便可以採用 Bradley-Terry 目標進行微調:
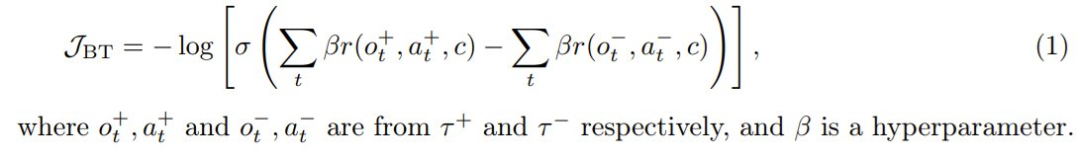
然後,可以使用優勢函數重寫這個目標函數:
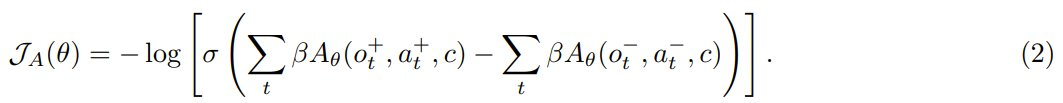
直觀地講,類似於單輪 RLHF 的目標,即學習每個選取響應的高獎勵和每個拒絕響應的低獎勵,2 式的效果是增加選取軌跡中每個動作的優勢並降低拒絕軌跡中每個動作的優勢。
為了進一步將學習目標與下一 token 預測預訓練對齊,該團隊的做法是重新利用 LLM 的現有語言模型頭來參數化優勢函數:
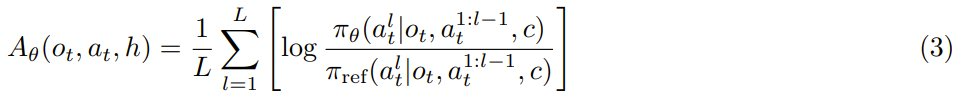
第二階段:通過每輪流的優勢優化智能體
該團隊得到的一個重要觀察是:雖然最終策略 π_φ 不能以隱藏信息 h 為條件,但此類信息在訓練期間是可用的。由於優勢 LLM π_θ 只會在訓練期間使用,因此它可以將 c 作為 3 式的輸入。
直觀地講,許多現實問題(例如協作和數學推理)都具有一些隱藏的訓練時間信息,例如參考解。如果每輪次的優勢函數可以訪問此類訓練時間信息,那麼它應該能夠更好地判斷策略採取的行動是否在正確的軌道上。
因此,他們為每輪次的優勢函數提供了額外的訓練時間信息 c,而僅向策略提供了交互歷史 o_t,從而產生了不對稱的 actor-critic 結構。原則上,RLHF 文獻中的任何成功算法都可用於優化每輪次策略 π_φ,方法是將交互歷史視為提示詞,將每輪次優勢函數 A_θ 視為獎勵模型。在訓練策略的這個階段,不需要人類合作者的互動。
為了簡單,該團隊選擇使用 DPO 進行訓練。對於每個輪次 t,首先從給定交互歷史 o_t 的當前策略中抽取候選動作,並根據學習到的每輪次優勢函數對它們進行排序,以獲得要選取和拒絕的動作。然後,使用標準 DPO 損失優化每個輪次的策略:
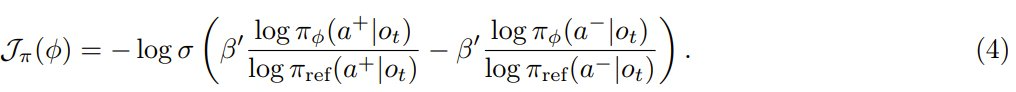
在實踐中,每個輪次都會采樣 16 個候選動作,並從前 50% 分位數中隨機選擇動作作為選取動作,從後 50% 分位數中隨機選擇動作作為拒絕動作。
實驗表現
作為多輪強化學習算法,SWEET-RL 究竟能不能有效地訓練 LLM 智能體來完成複雜的協作任務呢?為此,該團隊進行了實驗驗證。
在 ColBench 上的表現
表 2 展示了在 ColBench 上,不同 LLM 和多輪 RL 算法的性能情況。
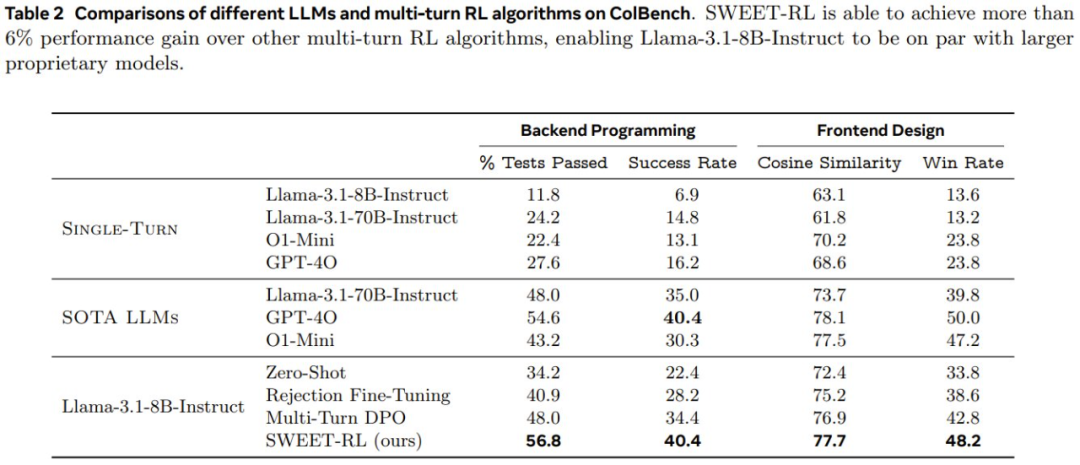
首先,比較「單輪」結果和其他協作結果,可以看到多輪協作可以通過將最終結果與人類模擬器的參考「期望」更緊密地結合起來,從而大大提高 LLM 智能體在 artifact 創建方面的性能。如果智能體必須在一個輪次內直接生產最終結果,那麼即使是表現最好的 GPT-4o 也只能達到 16.2%。相比之下,如果讓所有模型有機會與人類模擬器進行多輪交互並收集更多信息,則所有模型的成功率都能倍增(例如,Llama-3.1-8B-Instruct 的成功率從 6.9% 增加到 22.4%)。
儘管如此,即使對於 GPT-4o 和 o1-mini 等專有 LLM 來說,多輪協作仍然是一項具有挑戰性的任務,它們的成功率分別只能達到 40.4% 和 30.3%。儘管 o1-mini 在數學和編碼等符號推理任務上有所改進,但該團隊觀察到這些改進並沒有直接讓多輪協作智能體採用更好的策略,這表明為了讓 LLM 優化與人類的協作,下遊微調仍然是必要的。
SWEET-RL 與其它算法的比較
在使用下遊數據進行微調後,可以看到即使是最簡單的 RL 算法拒絕式微調(Rejection Fine-Tuning)也可以提高在這兩項任務上的性能。具體來說,後端編程成功率和前端設計成功率分別提高了 5.8% 和 4.8%。
然而,該團隊觀察到,拒絕式微調往往只是教 LLM「記住」每個訓練任務的解決方案,而沒有學習一種可泛化的策略來應對新的測試任務。
多輪次 DPO 通過為被拒絕的軌跡引入「負梯度」可以緩解這個問題,但如果沒有在長期時間上進行適當的 credit 分配,改進仍然有限。
而如果利用訓練時間信息顯式地訓練每輪次的獎勵模型來執行 credit 分配,可以觀察到相比於多輪次 DPO,SWEET-RL 在兩個任務上都有顯著提升(後端編程成功率提高 6%,前端設計勝率提高 5.4%)。
事實上,使用 Llama-3.18B-Instruct 得到的 SWEET-RL 模型不僅在參數上與 Llama-3.1-70B-Instruct 的性能相當,而且在性能上也足以與 GPT-4o 和 o1-mini 等 SOTA 專有模型比肩。
有關 SWEET-RL 的更多實驗細節和分析請參閱原論文。