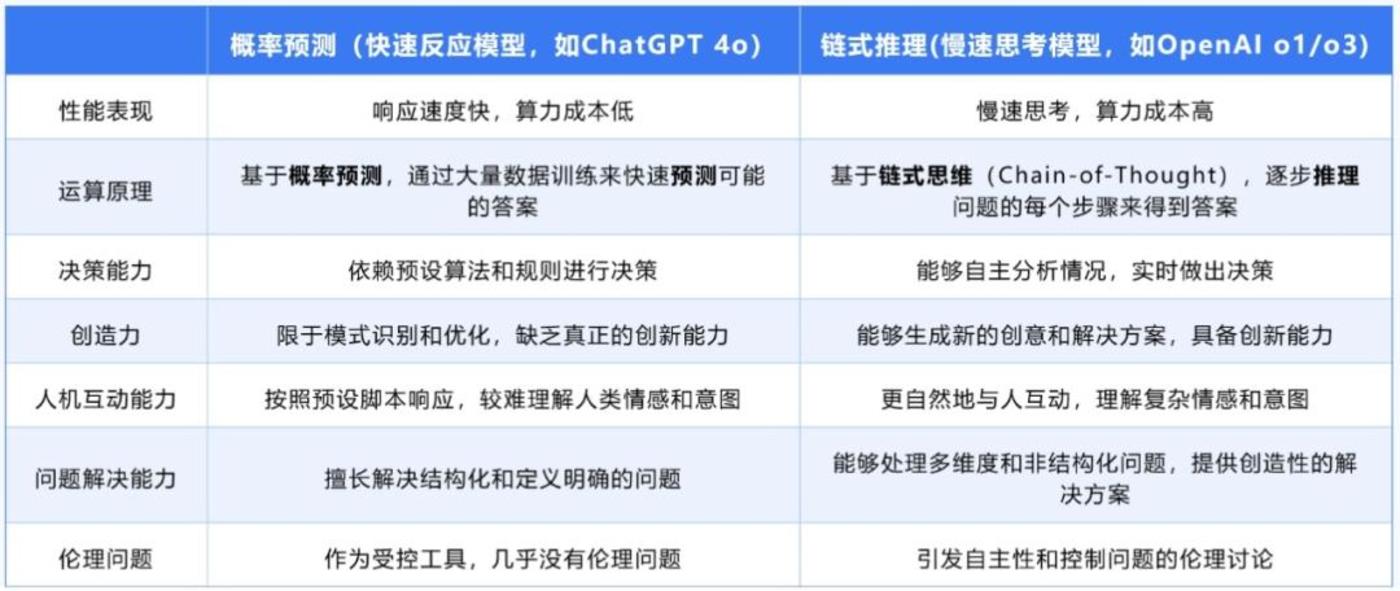
Google對齊大模型與人腦信號!語言理解生成機制高度一致,成果登Nature子刊
白交 發自 凹非寺
量子位 | 公眾號 QbitAI
Google最新發現,大模型竟意外對應人腦語言處理機制?!
他們將真實對話中的人腦活動與語音到文本 LLM 的內部嵌入進行了比較,結果兩者之間呈現線性相關關係。
比如語言理解順序,首先是語音,然後是詞義;又或者生成順序:先計劃,再發音,然後聽到自己的聲音。還有像在上下文預測單詞,也表現出了驚人的一致性。
其論文發表在了Nature子刊。

網民表示:這個問題比大多數人意識到的要重要得多。

Google對齊大模型與人腦信號
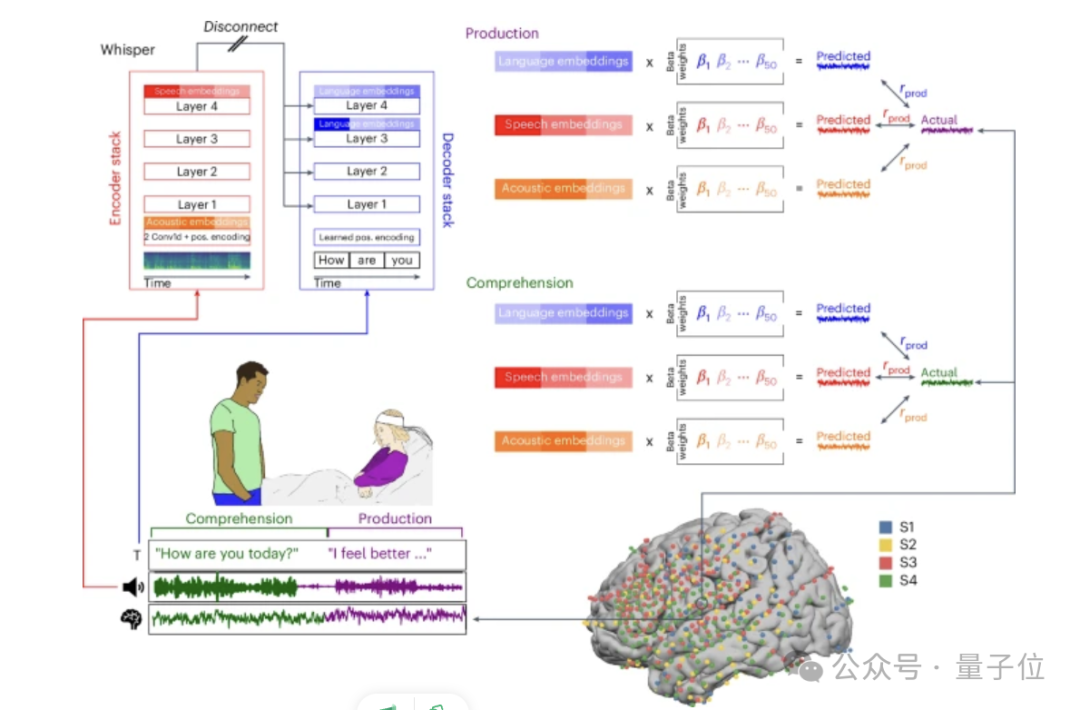
他們引入了一個統一的計算框架,將聲學、語音和單詞級語言結構聯繫起來,以研究人腦中日常對話的神經基礎。
他們一邊使用皮層電圖記錄了參與者在進行開放式真實對話時語音生成和理解過程中的神經信號,累計100小時。另一邊,Whisper中提取了低級聲學、中級語音和上下文單詞嵌入。
然後開發編碼模型,將這些嵌入詞線性映射到語音生成和理解過程中的大腦活動上,這一模型能準確預測未用於訓練模型的數小時新對話中語言處理層次結構各層次的神經活動。
結果他們就有了一些有意思的發現。
對於聽到的(語音理解過程中)或說出的(語音生成過程中)每個單詞,都會從語音到文本模型中提取兩種類型的嵌入:
來自模型語音編碼器的語音嵌入和來自模型解碼器的基於單詞的語言嵌入。
通過估計線性變換,可以根據語音到文本的嵌入來預測每次對話中每個單詞的大腦神經信號。
比如聽到「How are you doing?」,大腦對語言理解的神經反應序列be like:
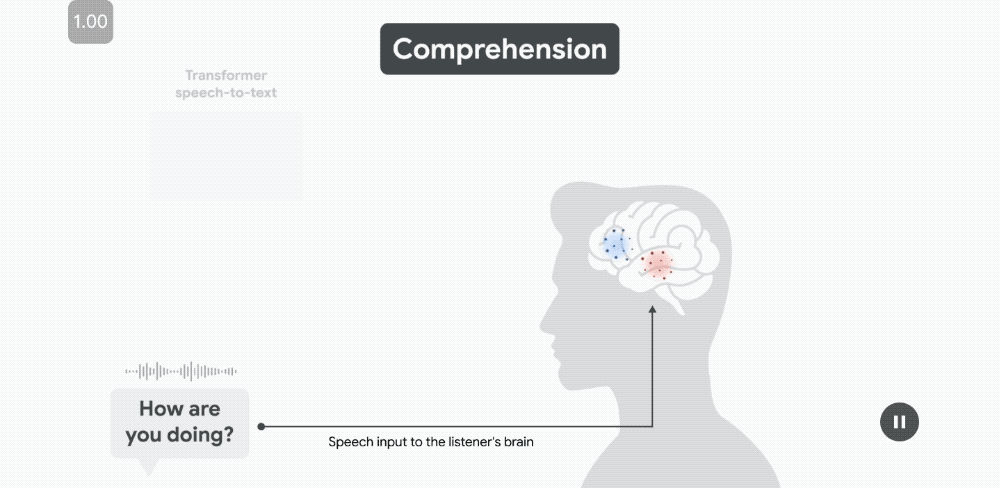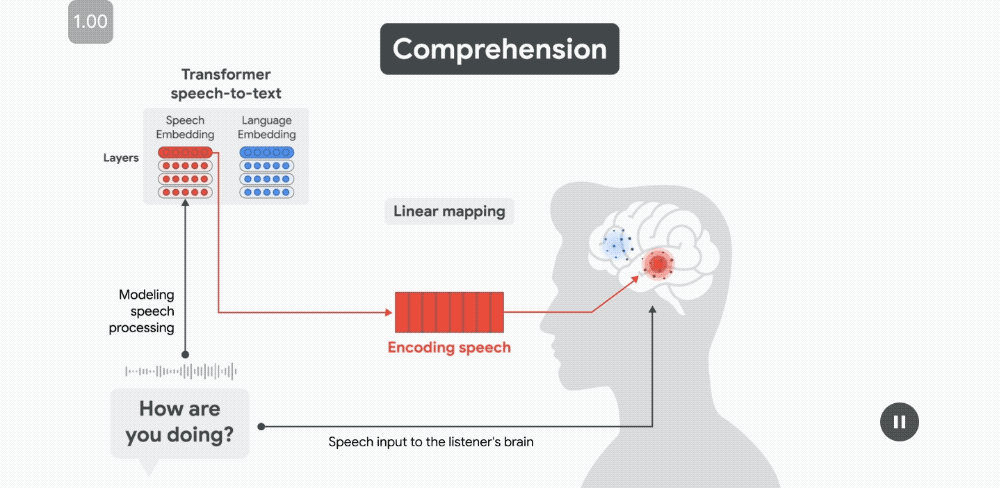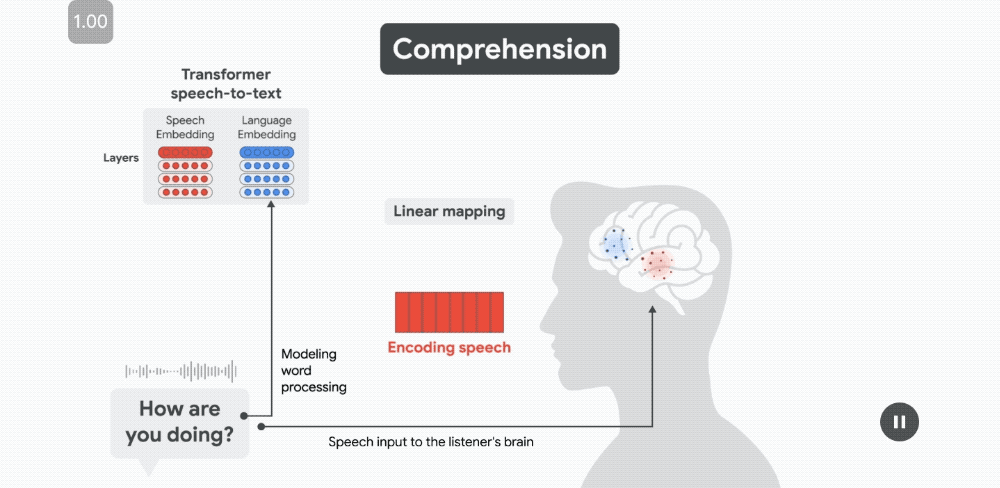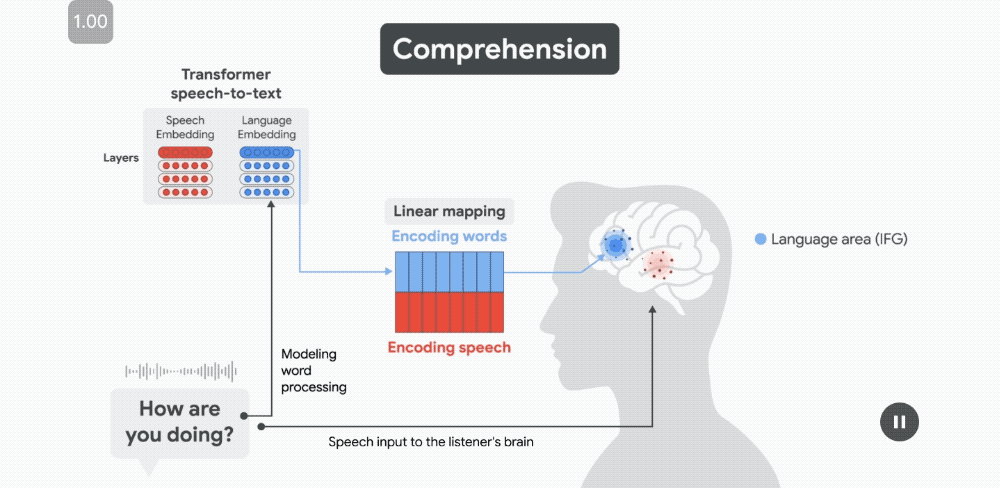 當每個單詞發音時,語音嵌入能夠預測沿顳上回(STG)的語音區域的皮層活動。
當每個單詞發音時,語音嵌入能夠預測沿顳上回(STG)的語音區域的皮層活動。幾百毫秒後,當聽者開始解碼單詞的含義時,語言嵌入會預測布羅卡區(位於額下回;IFG)的皮層活動。
不過對於回答者,則是完全相反的神經反應序列。
在準備發音「Feeling Fantastic」之前,在發音前約 500 毫秒(受試者準備發音下一個單詞時),語言嵌入(藍色)預測布羅卡區的皮層活動。
幾百毫秒後(仍在單詞發音之前),當說話者計劃發音時,語音嵌入(紅色)預測運動皮層(MC)的神經活動。
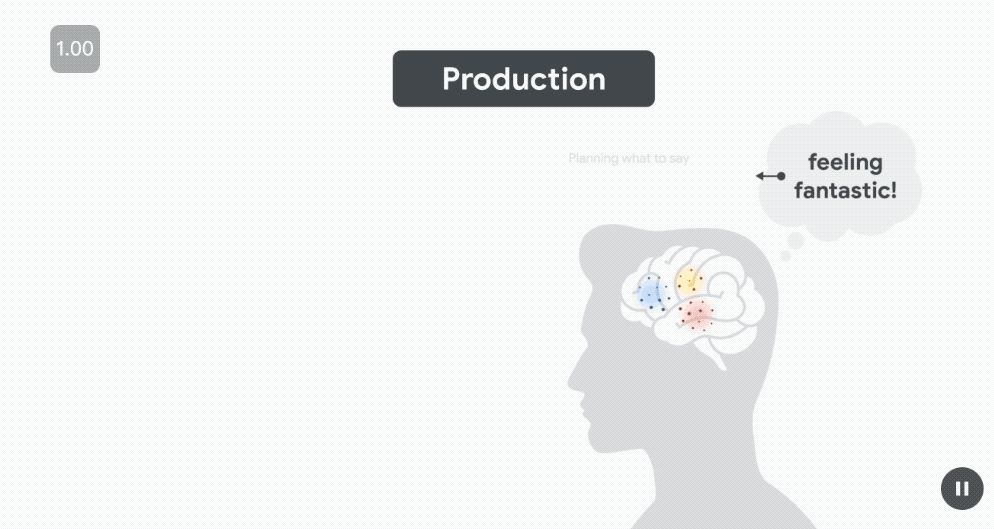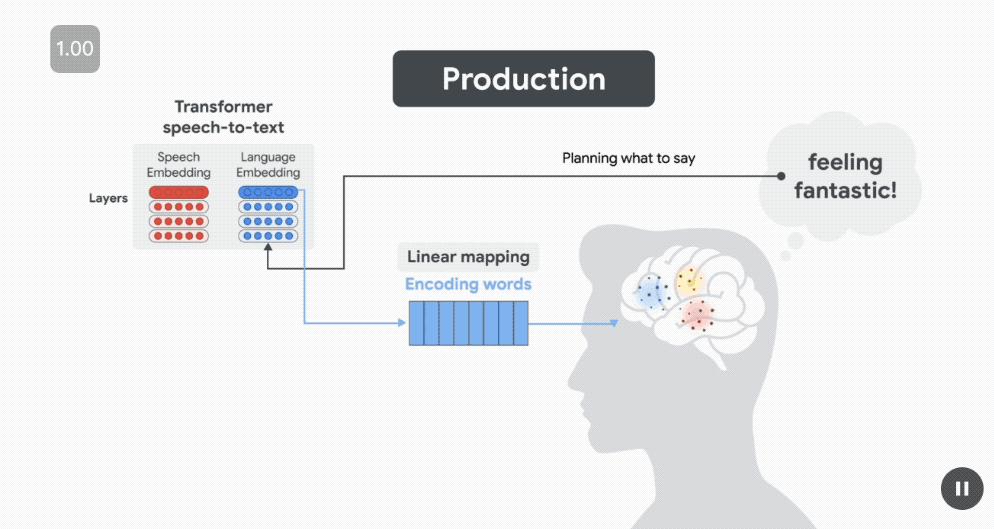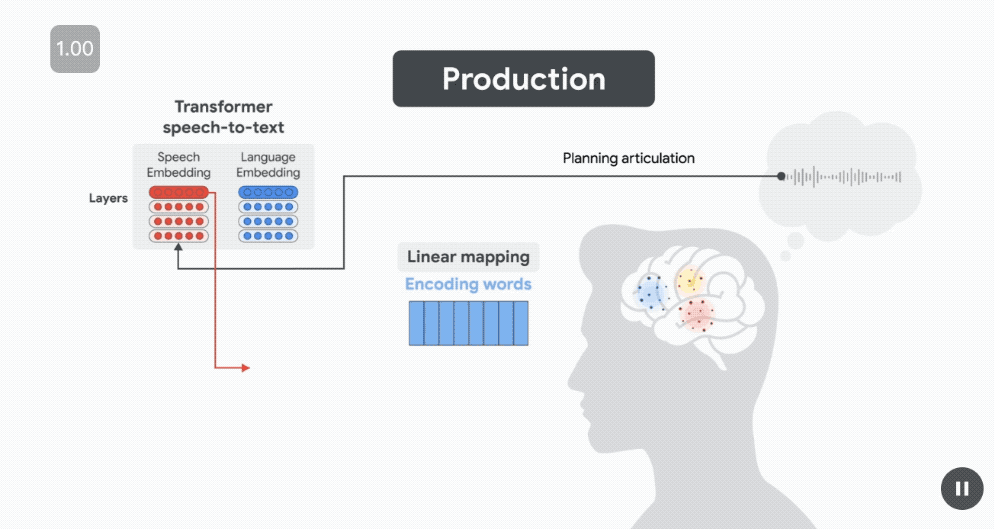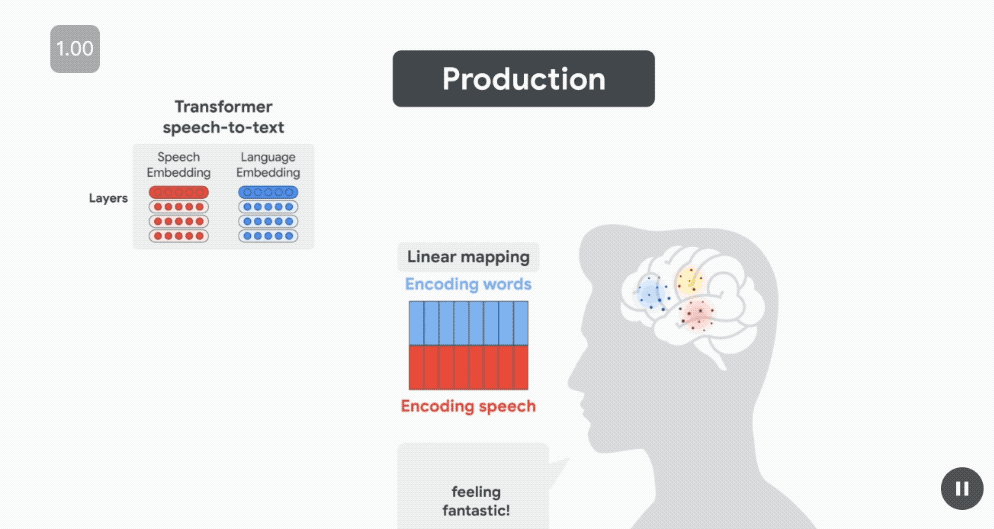
最後,在說話者發音後,當聽者聆聽自己的聲音時,語音嵌入會預測 STG 聽覺區域的神經活動。
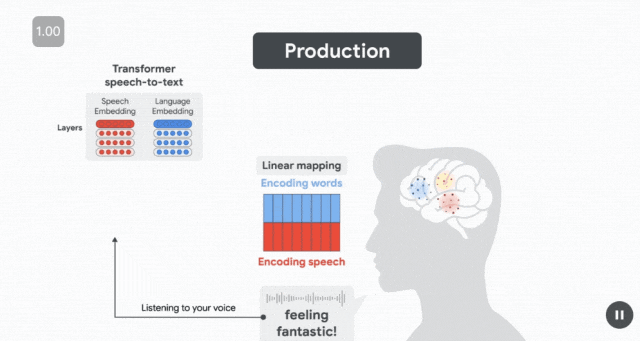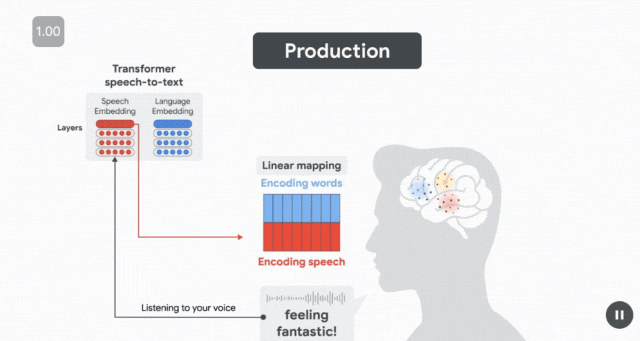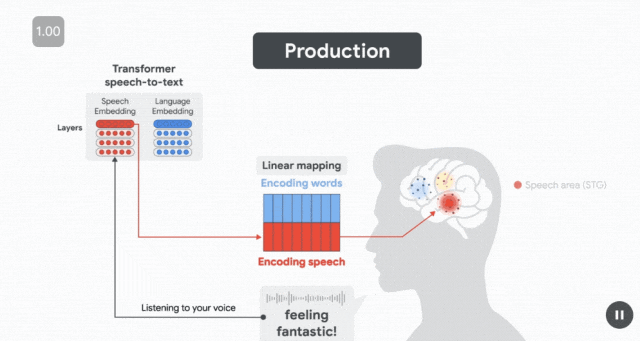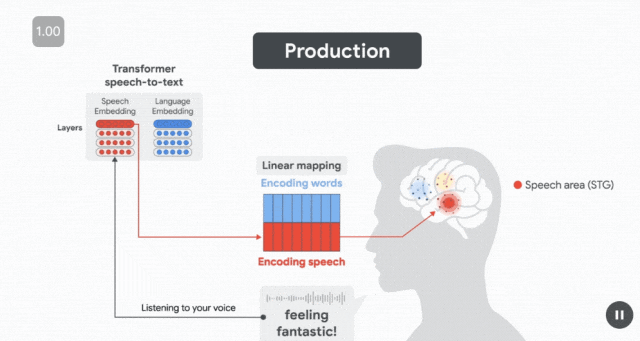
這種動態變化反映了神經處理的順序——
首先是在語言區計劃說什麼,然後是在運動區如何發音,最後是在感知語音區監測說了什麼。
全腦分析的定量結果顯示,對於每個單詞,根據其語音嵌入(紅色)和語言嵌入(藍色),團隊預測了每個電極在單詞出現前 -2 秒到出現後 +2 秒(圖中 x 軸值為 0)的時滯範圍內的神經反應。這是在語音生成(左圖)和語音理解(右圖)時進行的。相關圖表說明了他們對所有單詞的神經活動(相關性)的預測準確度與不同腦區電極滯後的函數關係。
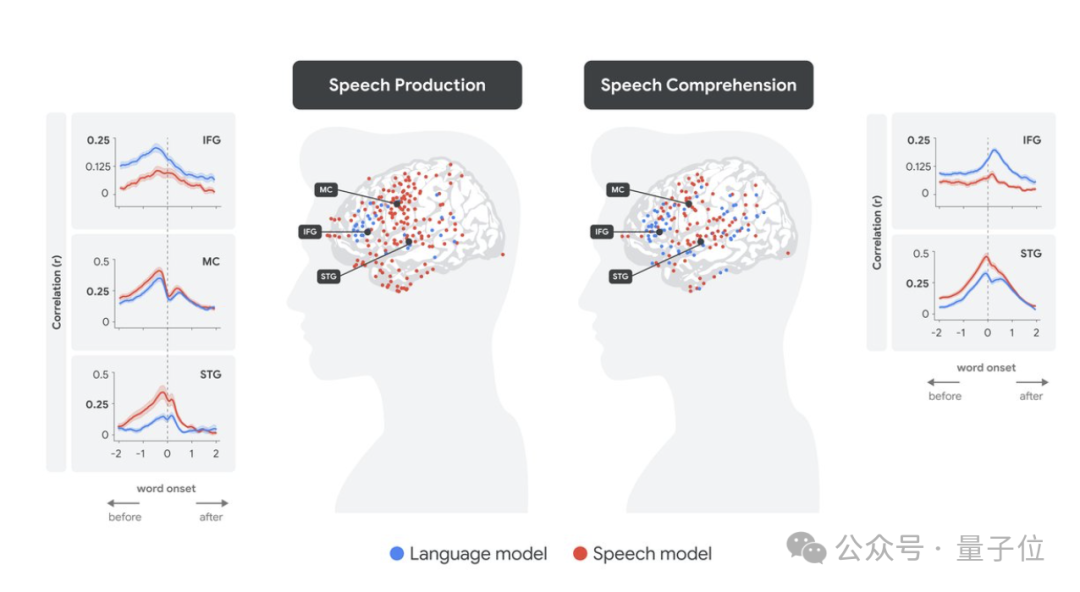
在語音生成過程中,IFG 中的語言嵌入(藍色)明顯先於感覺運動區的語音嵌入(紅色)達到峰值,隨後 STG 中的語音編碼達到峰值。相反,在語音理解過程中,編碼峰值轉移到了單詞開始之後,STG 中的語音嵌入(紅色)峰值明顯早於 IFG 中的語言編碼(藍色)峰值。
總之研究結果表明,語音到文本模型嵌入為理解自然對話過程中語言處理的神經基礎提供了一個連貫的框架。
令人驚訝的是,雖然 Whisper 完全是為語音識別而開發的,並沒有考慮大腦是如何處理語言的,但他們發現它的內部表徵與自然對話過程中的神經活動是一致的。
儘管大模型在並行層中處理單詞,但人類大腦以串行方式處理它們,但反映了類似的統計規律。
大模型與人類大腦之間的吻合揭示了神經處理中的 「軟層次 」這一概念,大腦中較低級別的聲學處理和較高級別的語義處理部分重疊。
大模型與人腦之間的異同
日常生活中,人類大腦如何處理自然語言?從理論上講,大語言模型和人類的符號心理語言學模型是兩種完全不同的計算框架。
但受到大模型成功的啟發,Google研究院與普林斯頓大學、紐約大學等合作,試圖探索人腦和大模型處理字眼語言的異同。
經過過去五年一系列研究,他們探索了特定特定深度學習模型的內部表徵(嵌入)與自然自由對話過程中人腦神經活動之間的相似性,證明了深度語言模型的嵌入,可以作為「理解人腦如何處理語言」的框架。
在此之前,他們就完成了多項研究。
比如2022年發表在Nature Neuroscience上論文顯示,他們發現與大模型相似,聽者大腦的語言區域也會嘗試在下一個單詞說出之前對其進行預測;而在單詞發音前對預測的信心會改變他們在單詞發音後的驚訝程度(預測誤差)。
這些發現證明了自回歸語言模型與人腦共有的起始前預測、起始後驚訝和基於嵌入的上下文表徵等基本計算原理。

還有發表在Nature Communications另一篇論文中還發現,大模型的嵌入空間幾何圖形所捕捉到的自然語言中單詞之間的關係,與大腦在語言區誘導的表徵(即大腦嵌入)的幾何圖形一致。

不過即便計算原理類似,但他們底層神經回路架構卻明顯不同。
在一項後續研究中,他們調查了與人腦相比,基於Transformer的大模型是如何跨層處理信息的。
結果發現,雖然跨層非線性變換在 LLMs 和人腦語言區中相似,但實現方式卻大相逕庭。Transformer架構可同時處理成百上千個單詞,而人腦語言區似乎是按順序、逐字、循環和時間來分析語言的。

基於這些積累的研究成果,他們的目標是創建創新的、受生物啟發的人工神經網絡,提高其在現實世界中處理信息和發揮作用的能力。
參考鏈接:
[1]https://research.google/blog/deciphering-language-processing-in-the-human-brain-through-llm-representations/
[2]https://www.nature.com/articles/s41562-025-02105-9
[3]https://x.com/GoogleAI/status/1903149951166902316
[4]https://x.com/rohanpaul_ai/status/1903373048260284868