Idea撞車何愷明「分形生成模型」,速度領先10倍,性能更強
澳州國立大學團隊提出了ARINAR模型,與何凱明團隊此前提出的分形生成模型類似,採用雙層自回歸結構逐特徵生成圖像,顯著提升了生成質量和速度,性能超越了FractalMAR模型,論文和代碼已公開。
前不久,大神何愷明剛剛放出新作「分形生成模型」,遞歸調用原子生成模塊,構建了新型的生成模型,形成了自相似的分形架構,將GenAI模型的模塊化層次提升到全新的高度。

論文地址: https://arxiv.org/pdf/2502.17437v1
GitHub 地址:https://github.com/LTH14/fractalgen
最近,澳州國立大學的研究人員提出了一個全新的圖像生成模型ARINAR,在思想上與分形生成模型不謀而合,但是在性能和速度上都顯著提升,base模型的FID從11.8提升到2.75,生成時間從2分鐘降低到12秒!ARINAR不僅超越了之前的擴散模型,與目前表現最好的自回歸模型MAR相比,ARINAR生成質量相當,速度是MAR的5倍。

論文鏈接: https://arxiv.org/abs/2503.02883
GitHub地址:https://github.com/Qinyu-Allen-Zhao/Arinar
ARINAR全稱是雙層自回歸逐特徵生成模型(Bi-Level Autoregressive Feature-by-Feature Generative Models),核心思想在於:通過逐特徵生成的方式生成tokens,從而提高整體圖像生成的質量和速度。
設計動機
現有的自回歸(AR)圖像生成模型通常採用逐token生成的方式。具體來說,模型會首先預測第一個token的分佈,根據這個分佈采樣出第一個token,然後基於這個token生成下一個token的分佈,再采樣出第二個token,依此類推,直到生成完整的圖像。
這裏的token可以理解為圖像的某種表示形式,通常是使用自編碼器(如VAE)實現圖像與一系列tokens之間的轉換。每個token可以看作圖像的一個局部區域或特徵的編碼。
研究人員指出,逐token生成的核心挑戰在於如何建模高維token的複雜分佈。每個token通常是一個高維向量(例如16維)。當模型需要預測下一個token的分佈時,如何準確地表達和預測該token的分佈一直是一個難題。
現有的方法主要有兩種思路:
- 離散token生成:一些方法使用特殊的自編碼器(如VQVAE)將圖像轉換為離散的token,然後使用多項式分佈來建模token的分佈。這種方法的問題在於,離散化會引入量化誤差,導致生成圖像的質量下降。
- 連續token生成:另一些模型嘗試直接建模連續token的分佈。
例如,GIVT模型使用高斯混合模型(GMM)來預測token的分佈,並從GMM中采樣生成token。然而,實踐中GMM難以準確擬合複雜的高維token分佈;
另一種方法是MAR模型,使用輕量級的擴散模型來生成token。雖然擴散模型能夠更好地擬合分佈,但擴散過程通常需要上百次迭代,導致整個模型生成速度較慢。
這些方法的局限性在於,要麼過於簡單,無法很好地擬合複雜的token分佈,要麼生成速度較慢。
因此,研究人員提出了一個新的思路:逐特徵生成。
具體來說,模型每次不再一次性生成整個token,而是逐特徵生成。每個token由多個特徵組成(例如16維),模型會先生成第一個特徵的分佈並采樣出第一個特徵,然後基於這個特徵生成第二個特徵的分佈,再采樣出第二個特徵,依此類推,直到生成整個token。
方法設計
ARINAR模型的設計分為兩層自回歸結構:
外層自回歸層:這一層負責生成token的條件向量。具體來說,它基於已經生成的token,預測下一個token的條件向量。這裡外層可以是任意之前的自回歸模型,例如使用MAR。
內層自回歸層:這一層基於外層生成的條件向量,逐特徵生成下一個token。具體來說,內層會先生成第一個特徵,然後基於這個特徵生成第二個特徵,依此類推,直到生成整個token。
假如一個圖像被轉換成256個16維的tokens,那麼外層自回歸模型就會運行256次,每次預測下一個token的條件向量。每次外層自回歸模型生成條件向量後,內層自回歸模型就會運行16次來逐特徵生成相應的token。
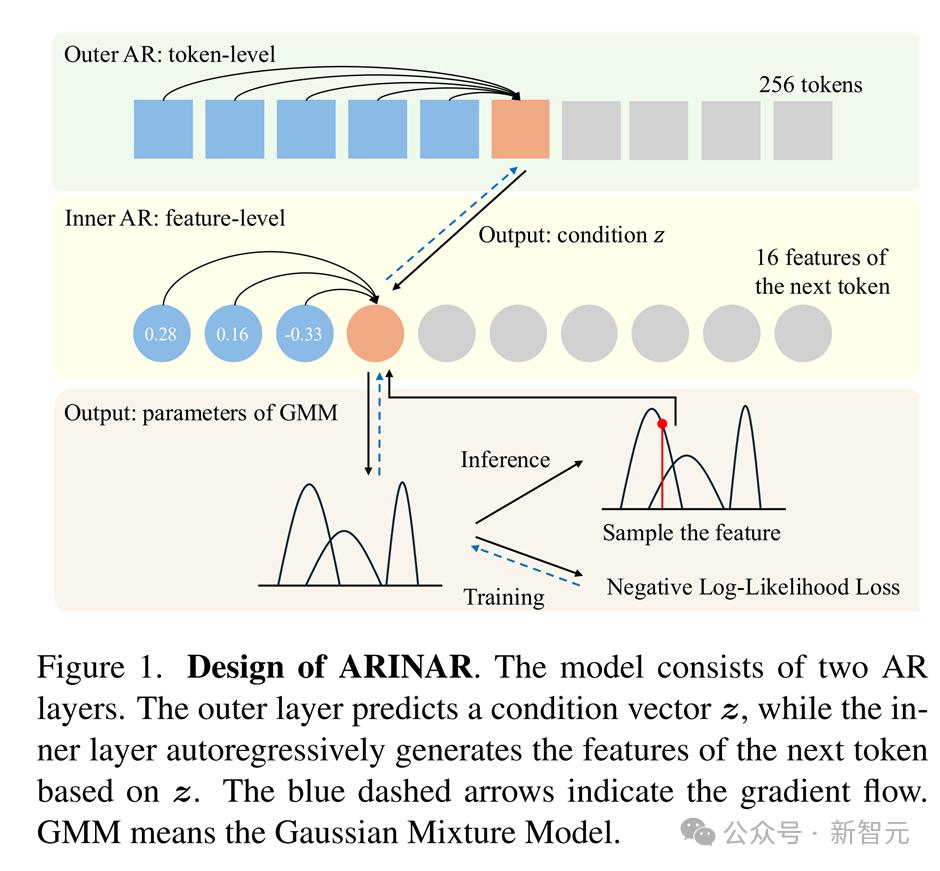
這種雙層結構的好處是,內層自回歸只需專注於單個特徵的生成,而不需要一次性建模整個token的分佈。因此,內層可以使用簡單的高斯混合模型(GMM)來建模單個特徵的分佈,從而大大簡化了預測token分佈的難度。
與FractalMAR的關係
在論文中,研究人員提到了一個與之類似的工作FractalMAR,也是一個多層自回歸模型,但它是在像素空間中逐像素生成圖像的。
也就是說,FractalMAR的每一層都負責生成圖像的不同部分,從大塊區域到單個像素。例如使用一個四層自回歸模型:
- 最外層生成整個圖像的大塊區域;
- 第二層生成每個大塊區域中的小塊區域;
- 第三層生成每個小塊區域中的像素;
- 最內層生成每個像素的RGB值。
相比之下,ARINAR是在特徵空間中逐特徵生成圖像的。ARINAR使用了自編碼器將圖像轉換為連續的特徵表示,然後在這些特徵上依賴GMM進行逐特徵生成。
研究人員強調,雖然ARINAR和FractalMAR的設計思路相似,但ARINAR在性能和速度上都優於FractalMAR。ARINAR可以看作是FractalMAR在潛在空間中的版本。
實驗結果
研究人員在ImageNet 256×256圖像生成任務上對ARINAR進行了測試,使用了213M參數的模型(ARINAR-B)。實驗結果顯示:
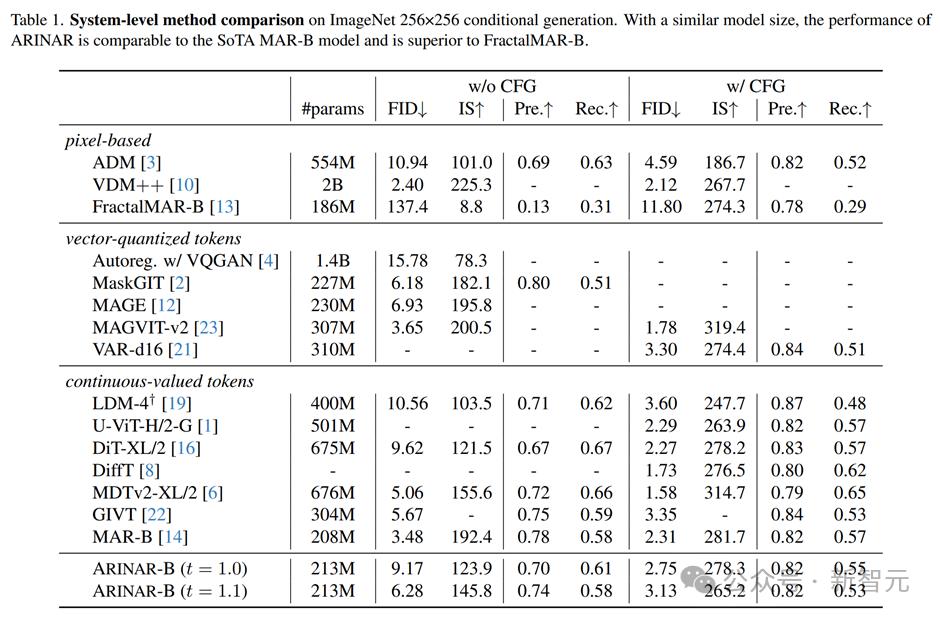
生成質量上,ARINAR-B在沒有使用CFG(classifier-free guidance)的情況下,FID(Frechet Inception Distance)得分為9.17,使用CFG後,FID得分提升到2.75,這個結果與當前最先進的MAR-B模型(FID=2.31)相當,且顯著超過了FractalMAR。
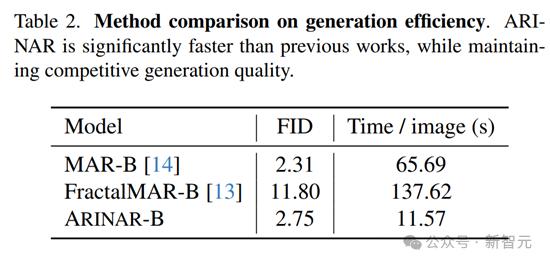
生成速度上,ARINAR-B生成一張圖像的平均時間僅需11.57秒,而MAR-B需要65.69秒,FractalMAR-B則需要137.62秒。ARINAR在保持高質量生成的同時,顯著提升了生成速度。
總結與不足
ARINAR通過逐特徵生成的方式,簡化了自回歸模型的複雜度,同時提高了生成速度和生成質量。
與FractalMAR相比,ARINAR在潛在空間中生成圖像,避免了像素空間的複雜性,從而在性能和速度上都取得了更好的結果。
這篇論文展示了自回歸模型在圖像生成任務中的巨大潛力,尤其是在生成速度和生成質量之間的平衡上,ARINAR提供了一個非常有前景的解決方案。
然而,由於計算資源的限制(使用4張A100 GPU),研究人員在這篇論文中只訓練了一個基礎模型(ARINAR-B),並且訓練時間長達8天。這確實限制了模型的進一步擴展和更大規模實驗的進行。
論文中也提到,研究人員正在尋求更多的計算資源,以便進行更多的實驗和訓練更大的模型。這意味著未來可能會有更多的研究成果發佈,進一步驗證ARINAR的潛力和可擴展性。
參考資料:
https://arxiv.org/abs/2503.02883
本文來自微信公眾號「新智元」,作者:LRST,36氪經授權發佈。