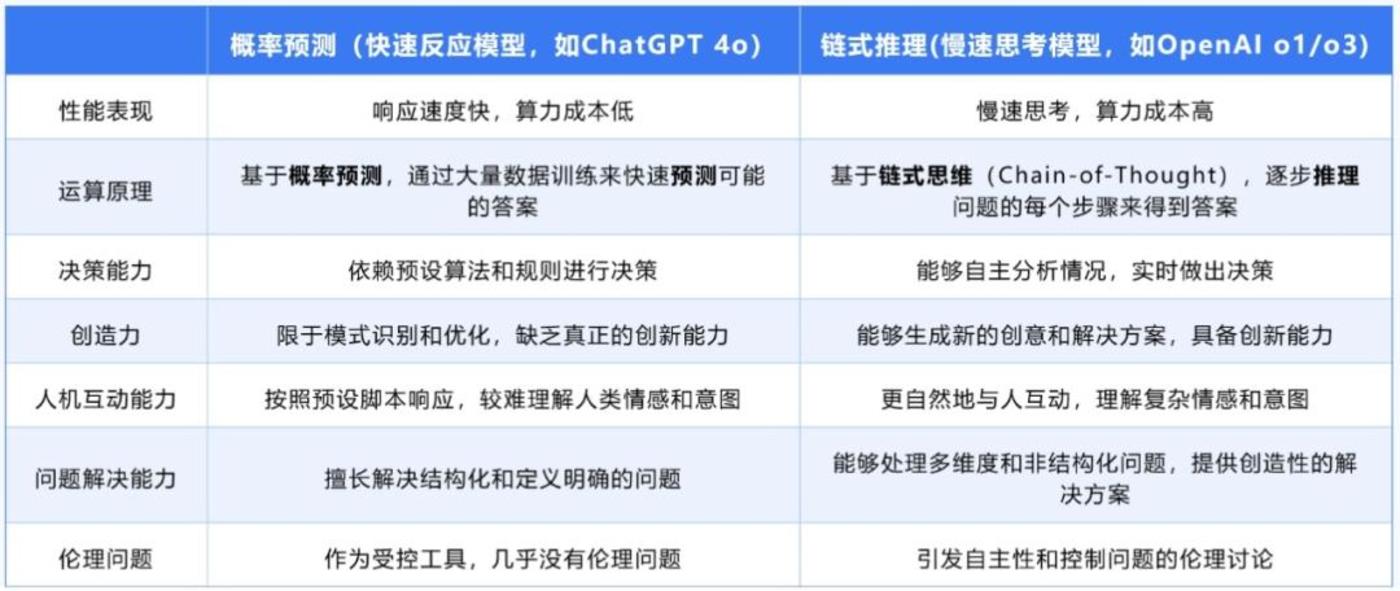
為什麼明明很準,獎勵模型就是不work?新研究:準確度 is not all you need
機器之心報導
編輯:張倩、Panda
訓練狗時不僅要讓它知對錯,還要給予差異較大的、不同的獎勵誘導,設計 RLHF 的獎勵模型時也是一樣。
我們知道,一個 RLHF 算法是否成功的一大關鍵在於其獎勵模型(RM)的質量。但是,我們應該如何衡量 RM 的質量呢?近日,普林斯頓大學一個研究團隊發現,如果僅用準確度來衡量 RM 的質量,可能無法完全體現一個獎勵模型作為有效教師的特性。為此,他們選擇了從優化角度來研究這個問題。

-
論文標題:What Makes a Reward Model a Good Teacher? An Optimization Perspective
-
論文鏈接:https://arxiv.org/pdf/2503.15477
在這篇論文中,他們證明:無論獎勵模型有多準確,如果它會導致獎勵方差較低,那麼 RLHF 目標優化起來就會比較緩慢。即使是完全準確的獎勵模型也會導致優化速度極其緩慢,性能表現趕不上會導致獎勵方差較高但準確度較低的模型。
他們還表明,對一種語言模型有效的獎勵模型可能會讓另一種語言模型的獎勵方差較低,從而導致優化過程變得緩慢。
這些結果說明:如果在設計獎勵模型時僅基於準確度或不考慮具體的語言模型,那麼就會遭遇一些根本性的限制。總體而言,除了準確度之外,獎勵模型還需要誘導出足夠的方差才能實現有效優化。
考慮到強化學習與生物大腦學習機制具有一定的共通性,於是我們求助了 Claude,讓它通過「人訓練狗」的類比給我們提供了更為直觀易懂的解釋:

看起來這個解釋還不錯?
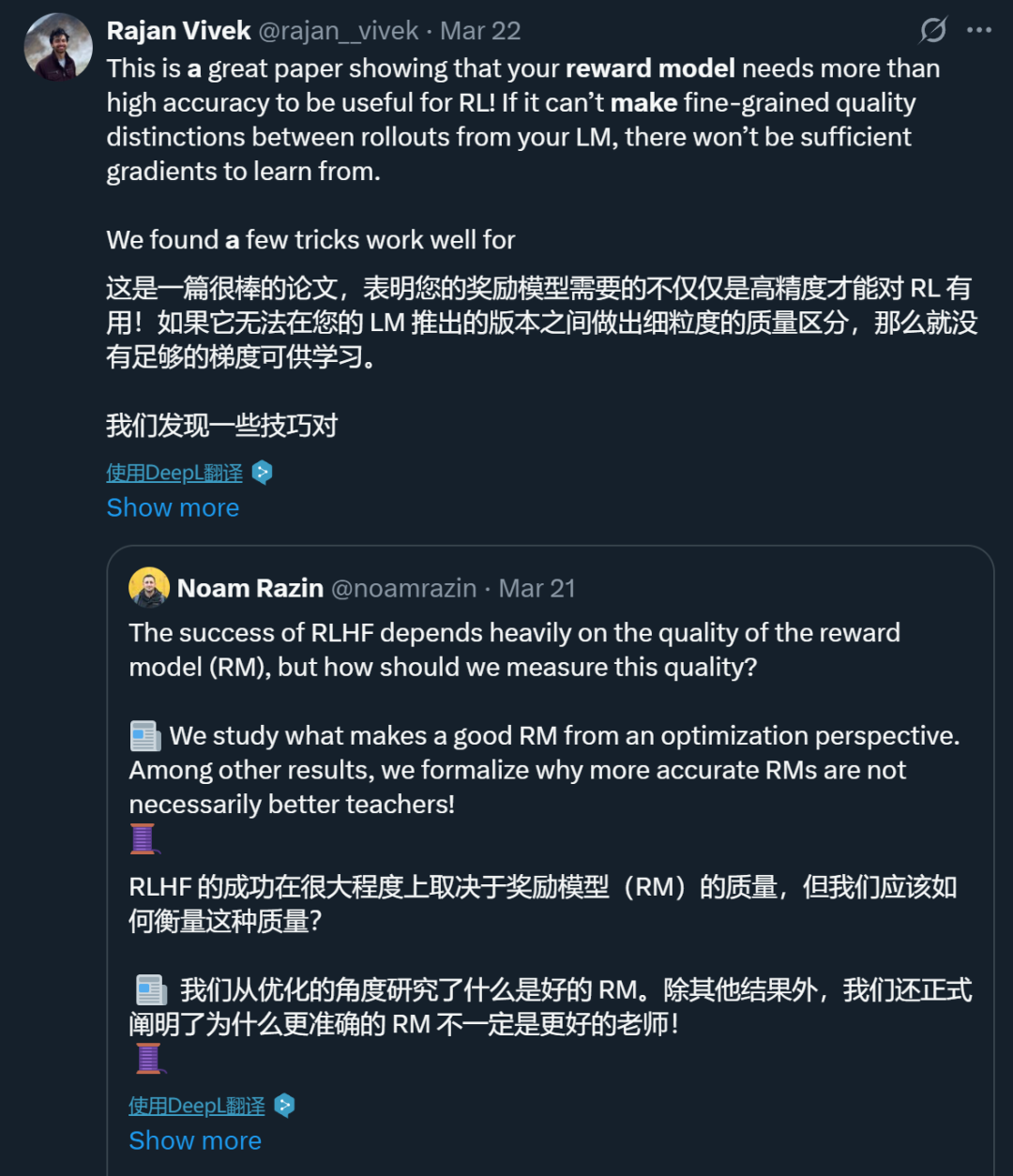
這項工作吸引了不少研究者的注意。其中,來自史丹福大學的 AI 研究者Rajan Vivek 不止肯定了該工作的價值,還給出了一些讓獎勵更加細粒度(誘導獎勵方差)的技巧,包括:
在最小對比對上進行訓練:可以人工合成這些對比對,要求獎勵模型能夠可靠地為其中一個輸出賦予略高的分數。
從生成式獎勵模型中計算連續獎勵:通過取 token 概率和分數的加權和來實現。
結合監督微調(SFT)、均方誤差(MSE)和偏好損失:這些方法使模型能夠生成推理依據,優化其連續獎勵,並有效地從最小對比對中學習!
下面繼續來看原論文給出的更為技術化的描述。
從優化視角看如何設計優良的獎勵模型
該團隊研究的是通過策略梯度最大化 RLHF 目標(如下 (1) 式)時預期的真實獎勵 r_G 增加到所需量所需的時間。這個時間越短越好。
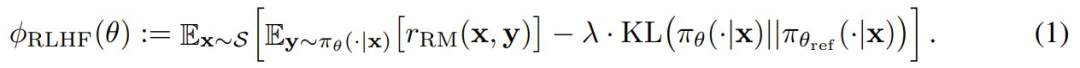
他們證明,如果獎勵模型 r_RM 會為初始策略引入較低的獎勵方差,則由於目標圖景平坦,r_RM 和 r_G 都會以較慢的速度增加。因此,為了實現高效優化,r_RM 需要確保獎勵方差不會太低。
之後,他們確立了獎勵方差和優化率之間關係的兩個主要含義。
1、由於獎勵方差與準確度沒有綁定,因此更準確的獎勵模型不一定是更好的教師。
2、由於相同的獎勵模型可能會給一種策略引入較高的獎勵方差,但為另一種策略引入較低的獎勵方差,因此對於不同的初始策略,使用不同的獎勵模型會有更好的效果。
圖 1 展示了準確度與獎勵方差對 RLHF 目標圖景的影響。

具體來說,準確度和獎勵方差體現了獎勵模型的不同方面:前者控制著與 ground truth 獎勵的對齊,而後者決定了目標圖景的平坦度。
準確度越低,獎勵模型越容易受到獎勵 hacking 攻擊 —— 獎勵模型認為有益的方向可能並不會提升 ground truth 獎勵。另一方面,即使獎勵模型完全準確,低獎勵方差也意味著平坦的圖景有礙策略梯度方法的效率。
低獎勵方差意味著最大化獎勵的速度緩慢
這裏將預期獎勵所需的時間下限設為一個加法常數。定理 1 表明,這個時間的增長與
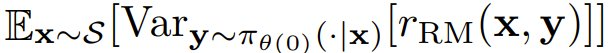
成反比,這是 r_RM 針對初始策略與訓練集 S 中的提示詞得到的平均獎勵方差。這樣一來,如果提示詞 x ∈ S 的
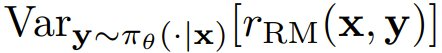
較低(即當 r_RM 無法充分地分離在初始策略下可能的輸出時),則策略梯度就會出現優化速度慢的問題。

定理 1 是原論文中定理 4 的精簡版,對其的證明請訪問原論文附錄部分。
眾所周知,低獎勵方差意味著通過 softmax 產生下一 token 分佈的策略出現了梯度消失現象。
具體而言,對於任何提示詞 x 和策略 π_θ,
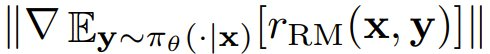
都會隨著
衰減。然而,僅憑這一點並不能得到令人滿意的獎勵最大化率下限,因為如果沒有進一步的知識,梯度範數可能會在訓練過程中迅速增加。
但研究表明情況並非如此:當獎勵方差較低時,RLHF 目標的高階導數會與梯度一起消失,從而阻止梯度範數的快速增加。這會限制策略參數 θ(t) 的移動,從而導致獎勵增長率的下限。
更準確的獎勵模型不一定是更好的教師
上一小節表明:低獎勵方差會阻礙策略梯度的效率。值得注意的是,獎勵方差與通常用於評估獎勵模型的指標(準確度)無關。準確度僅取決於獎勵模型如何排序不同的輸出,而不考慮其獎勵之間的分離程度,而獎勵方差則由這種分離程度決定。定理 2 確定的一個關鍵含義是:準確的獎勵模型 r_RM 也可能有較低的獎勵方差。
需要明確一下,定理 2 考慮了兩點:(i) 存在 r_RM 完全準確而 r′_RM 幾乎完全不準確的極端情況;(ii) 對於提示詞 x 和獎勵模型 r_RM,關於無序輸出對的均勻分佈的準確度用 accx (rRM) 表示。關於該定理的詳細版本(定理 5)的證明請訪問原論文附錄。

該團隊指出,定理 2 並不意味著高準確度的獎勵模型就一定是糟糕的教師。事實上,在幾乎任何準確度水平上,一些獎勵模型都會導致優化低效,而其他獎勵模型則表現良好。定理 2 只是形式化了準確度本身不足以評估 RLHF 中的獎勵模型的原因。
儘管如此,準確度仍是一個需要努力追求的屬性,因為更準確的模型通常不太容易受到獎勵 hacking 攻擊。也就是說,當使用不完美的獎勵模型進行訓練時,由於兩個獎勵不匹配,最終 ground truth 獎勵可能會開始減少。因此,通常的做法是只運行幾個 epoch 的策略梯度。定理 2 體現到了這種情況,其中準確度較低的獎勵模型可以通過推動 ground truth 獎勵的更快增加而勝過更準確的獎勵模型。
準確度的作用取決於對齊方法。雖然準確度本身並不能保證 RLHF 的有效性,但其重要性因對齊方法而異。例如,在 Best-of-N 采樣中,很容易證明完全準確的獎勵模型始終是最佳的。
對於不同的初始策略,不同的獎勵模型更好
獎勵方差取決於獎勵模型和策略。特別是,對一個策略產生高獎勵方差的獎勵模型可能會對另一個策略產生低獎勵方差。因此,獎勵方差和優化之間的聯繫意味著對於不同的初始策略,使用不同的獎勵模型會更好,見定理 3。這表明,為了忠實地評估 RLHF 的獎勵模型,需要考慮正在對齊的策略。

實驗結果
在實驗部分,作者驗證了從理論分析中得出的結論在實踐中是成立的。
首先,他們表明,在策略梯度期間,獎勵方差與獎勵最大化率密切相關。具體來說,在固定訓練預算下,更準確的獎勵模型如果產生較低的獎勵方差,反而可能導致性能下降。更令人意外的是,這一現像甚至適用於真實(ground truth)獎勵本身:作者發現,即使能夠直接獲取真實獎勵,在某些情況下使用代理獎勵模型反而能取得更好的效果。
如下圖 2 所示,作者使用一些獎勵模型,通過策略梯度方法(RLOO)訓練了一個 Pythia-2.8B 語言模型。這些獎勵模型的特性如表 1 所示。作為對比,作者還直接使用真實獎勵進行了策略梯度訓練。圖 2 展示了代理獎勵(左圖,即用於訓練的獎勵)和真實獎勵(右圖)隨訓練輪數增加的變化情況。與定理 2 一致,一個完美、準確但導致低獎勵方差的獎勵模型(紅色標記)的表現不如一些準確度較低的模型。更有趣的是,在最初幾輪訓練中,使用代理獎勵模型的效果甚至優於直接優化真實獎勵。
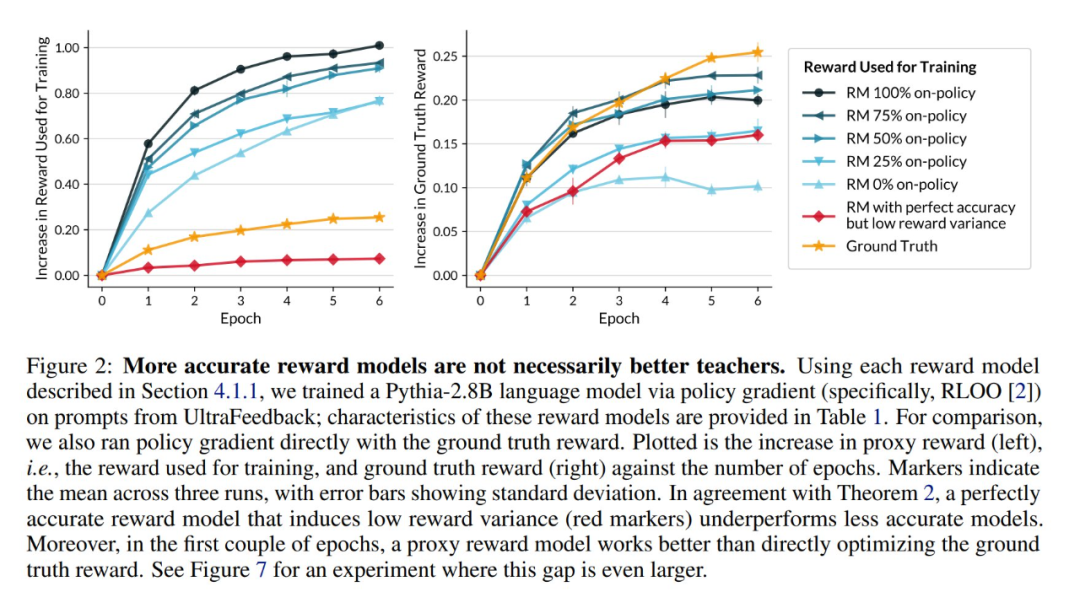
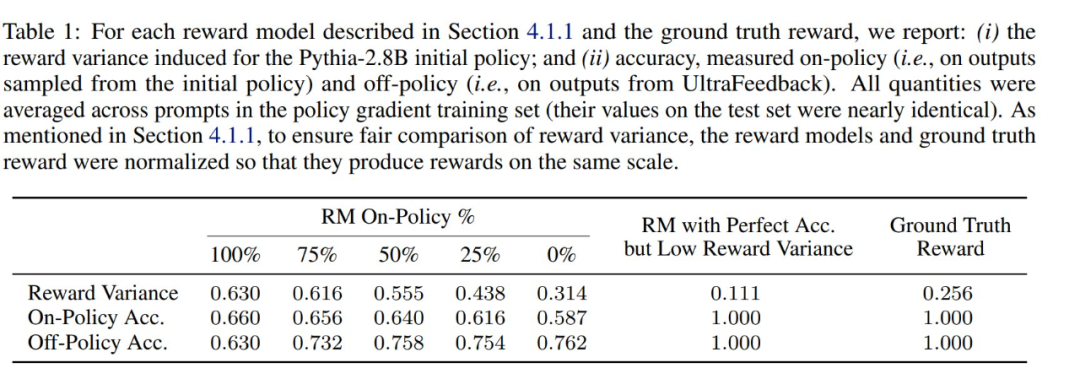 圖 7 展示了一個這種差距更為明顯的實驗。
圖 7 展示了一個這種差距更為明顯的實驗。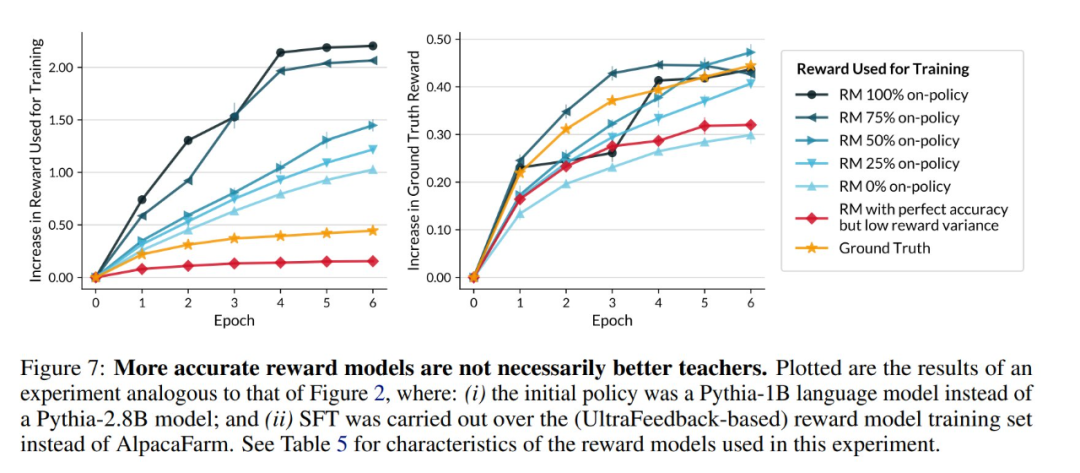
接下來,作者證明了對於不同的語言模型,不同的獎勵模型會帶來更高的真實獎勵。如下圖 3 所示,作者使用公開可用的獎勵模型,通過策略梯度方法(RLOO)在 UltraFeedback 的提示上訓練了不同的語言模型;獎勵模型的特性見表 9。圖中數據顯示,與定理 3 一致,能夠產生最高真實獎勵的獎勵模型會隨著初始策略的不同而變化。
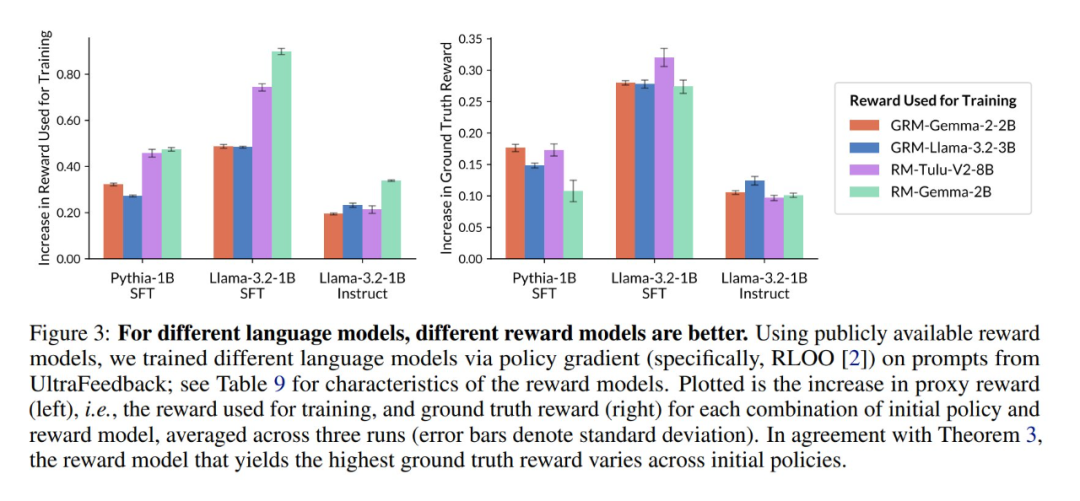
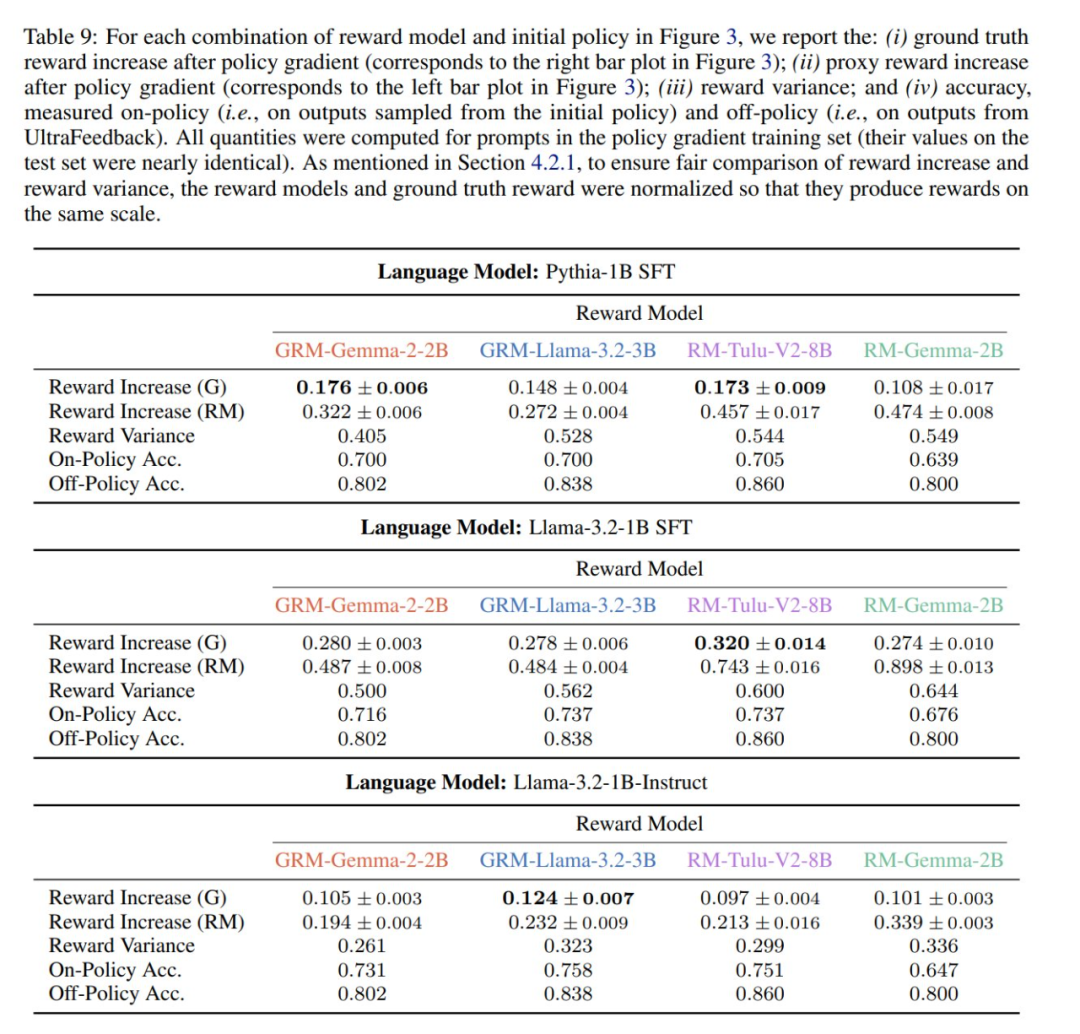
有關這些實驗的更多詳情以及定理證明請參閱原論文。