OpenAI研究負責人諾姆·布朗:基準測試比數字大小毫無意義,未來靠token成本衡量模型智能|GTC 2025
責編 | 王啟隆
今年英偉達大會(GTC 2025)邀請到了 OpenAI 的人工智能推理研究負責人、OpenAI o1 作者諾姆·布朗(Noam Brown)參與圓桌對話。
他先是帶著大家回顧了自己早期發明「德撲 AI」的工作,當時很多實驗室都在研究玩遊戲的 AI,但大家都覺得摩亞定律或者擴展法則(Scaling Law)這些算力條件才是突破關鍵。諾姆則在最後才頓悟發現,範式的更改才是真正的答案:「如果人們當時就找到了正確的方法和算法,那多人撲克 AI 會提前 20 年實現。」
究其根本原因,其實還是很多研究方向曾經被忽視了。「在項目開始前,沒有人意識到推理計算會帶來這麼大的差異。」
畢竟,試錯的代價是非常慘痛的,諾姆·布朗用一句很富有哲思的話總結了直到現在都適用的一大問題:「探索全新的研究範式,通常不需要大量的計算資源。但是,要大規模地驗證這些新範式,肯定需要大量的計算投入。」
 左為英偉達專家白賴仁·卡坦紮羅,中為諾姆·布朗,右為主持人瓦爾蒂卡
左為英偉達專家白賴仁·卡坦紮羅,中為諾姆·布朗,右為主持人瓦爾蒂卡在和英偉達專家的對話過程中,諾姆還對自己加入 OpenAI 之前、成為「德撲 AI 之父」的故事做了回顧,因此這部分便不再贅述,讓我們先快速回顧一遍 o1 曾經造成的轟動。
眾所周知,OpenAI 是 AI 圈的熱搜之王。
圍繞它這幾年的炒作,用一篇文章可能都放不下:先是首席科學家 Ilya Sutskever 宣佈「AI 已具備意識」、然後高層地震、首席執行官 Sam Altman 被短暫罷免、Ilya 不久之後離職、聯合創始人 Greg Brockman 休長假、第二輪高層動盪、「矽谷美女 CTO」 Mira Murati 離職……
這些驚天大瓜的背後,是曾經流傳在傳說中的「Q*」項目。從 GPT-4 發佈後的一年里,國外各大媒體一次又一次地暗示爆料 Q* 的進展,OpenAI 自己從未正面回應它,但許多從 OpenAI 離職的科學家都暗示過他們在開發一個能「威脅人類」的 AI。
Q* 後來更改代號為「Strawberry」,最終孵化為世界上的第一個推理模型——OpenAI o1-preview。

於是在 2024 年 9 月之後,OpenAI 開始了新的炒作,並開啟了 AI 領域新一輪的賽跑,目標是:誰能先把 o1 複現出來?
當時許多公司其實基本找到了追趕 GPT-4 和 GPT-4o 兩款模型的路徑,但面對 o1 這見鬼一樣的推理能力,皆是一籌莫展。上至 Anthropic、Google 和 Meta,下至國內外各種初創公司和學術機構,都倒在「CloseAI」的閉源高牆面前。
最後的結局反倒是大家都知道的:2025 年 1 月,DeepSeek-R1 發佈,英雄登場,開源了研究成果,漫長的賽跑告一段落。
 Noam Brown 在最上一排從左往右數第九位
Noam Brown 在最上一排從左往右數第九位難倒全天下 AI 公司的 OpenAI o1,由一百多名研究人員在多年之間研發完成,上圖的 18 個人是核心貢獻者,他們的項目領導就是諾姆·布朗。
在項目開始前,他就給 o1 定下了方向:「我們需要開發出一種推理方法,它應該像深度學習在快思考(System 1)思維方面所展現出的那樣,具有廣泛的適用性和高度的靈活性。」
最終的目標,就是為 OpenAI 開發一個能夠進行慢思考(System 2)思維的推理模型。

諾姆在對話中也分享了不少自己試錯中得到的感悟,比如:「預訓練仍然至關重要。預訓練和推理是相輔相成的,它們是攜手並進的,我認為我們會在這兩個方面都看到持續的進步。」
當前 AI 圈人人都面臨算力緊迫的問題,所以諾姆建議我們先從對算力要求不那麼高的地方開始改善:「人工智能基準測試的現狀非常糟糕,這種單一數字的比較,其實已經毫無意義了。你必須從「單位成本智能」的角度來思考,比如每個 token 能買到的智能。」
鋪墊到此為止,讓我們進入正題吧。
主持人:我是英偉達戰略技術合作夥伴關係負責人,瓦爾蒂卡·辛格(Vartika Singh),很榮幸主持這場專題討論會,主題是「高級人工智能推理:從遊戲到複雜推理」(Advanced AI reasoning from games to complex reasoning)。我想先為討論設定一下背景。
現在的人工智能正處在一個關鍵時刻。算法的重大突破不斷湧現,並得益於日益強大的計算能力。今天的對話,我們請到了兩位領軍人物,他們的工作正是這種融合的體現。
一位是來自 OpenAI 的諾姆·布朗(Noam Brown),他的工作促成了我們對人工智能如何在戰略性複雜推理和遊戲中取得卓越成就的理解。
另一位是英偉達應用深度學習研究副總裁白賴仁·卡坦紮羅(Bryan Catanzaro),他一直站在前沿,構建工業級、可擴展的訓練和部署系統。
介紹完背景,我們不妨先請兩位談談,如何將你們的工作放到人工智能推理的大背景下進行理解。諾姆,你先開始怎麼樣?
諾姆·布朗:我大概在 2012 年進入人工智能領域,開始在卡內基梅隆大學攻讀博士學位。我研究的是遊戲人工智能,最初是撲克 AI。當時,國際象棋這類完美信息博弈已經取得了很大進展,圍棋也在不斷進步,但沒人真正知道如何將這些技術擴展到撲克這種非完美信息博弈。如何才能開發出超越人類水平的撲克 AI——更廣泛地說,如何在非完美信息博弈中實現超越人類水平的 AI?這大概是我博士期間六年時間的研究方向。
2017 年,我們開發出了第一個超越人類水平的撲克 AI(Libratus),但它專攻的是兩人撲克。
2018 年,我去了 Meta,並開始研究多人撲克。2019 年,我們在 Meta 開發出了首個超越人類水平的多人撲克 AI(Pluribus)。
然後,我把重心轉向了其他方面,包括嘗試將這些技術擴展到自然語言領域,應用到自然語言博弈,也就是經典桌遊《強權外交》(Diplomacy)當中。
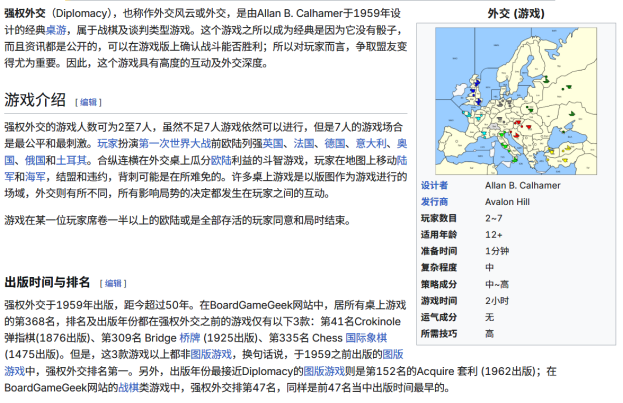
隨後在 Meta 工作期間,我和同事們一起開發了 CICERO,首個在《強權外交》這款遊戲達到人類玩家水平的 AI。
期間我注意到,所有這些技術都在運用推理能力。所以,一個重點就是,如何讓人工智能在做決策時進行更長時間的思考,從而得出更好的結果。
我從這些研究中發現,我們在撲克中使用的技術,與國際象棋中使用的技術非常不同,我們在《強權外交》遊戲中使用的技術,又與國際象棋和撲克中使用的技術大相逕庭。
那麼,我們能不能開發出一種非常通用的推理方法呢?最好是能應用於像語言這樣廣泛的領域。正是這個想法促使我來到 OpenAI,在那裡,我和許多傑出的同事一起開發了 OpenAI o1 系統。
 諾姆當年的豪言壯語
諾姆當年的豪言壯語白賴仁·卡坦紮羅:你的工作經歷真是令人印象深刻。我大概是從研究生時期開始研究 AI 系統的,我在 2008 年的 ICML 會議上發表了我的第一篇論文。
當時我展示了如何在 GPU 上訓練一些模型,結果人們問我:「你來這裏幹什麼?」這說明十七年前,計算能力對於人工智能發展的重要性,可能還不是那麼顯而易見。
但我堅信,推動計算系統,是推動人工智能向前發展的巨大機遇。因此,我在 2011 年全職加入了英偉達。我的工作,促成了 QDNN 的誕生,這是英偉達首個用於 GPU 上 AI 的庫。從那時起,我有幸參與了很多其他項目,包括 DLSS,它利用機器學習來加速圖形渲染過程。如今,由於 AI 的實時應用,我們的圖形渲染效率提高了大約 8 到 10 倍,我對此感到非常興奮。尤其現在 AI 正在進入虛擬世界,並以全新的方式進行互動,我認為這非常重要。
還有,這些年來,我們一直在致力於語言相關的系統研發。我們構建了一個名為 Megatron 的系統,我認為它推動了行業進步,幫助擴展了大型語言模型的訓練。我對未來充滿期待,希望能夠將所有在 AI 系統方面的工作提升到一個新的水平,以支持更強大的推理能力。
主持人:兩位的工作都非常出色。那麼,我們先從遊戲部分開始聊起。諾姆剛剛提到了 Libratus 和 Pluribus,然後是 CICERO,我看到這三個項目之間存在著明顯的區分,或者說某種程度上的界限。
你提到,這三者之間存在某種內在聯繫,最終促成了 OpenAI o1 的誕生,以及 OpenAI o1 中的推理能力。能否詳細描述一下,你在這些工作中主要考慮了哪些技術?
諾姆·布朗:我認為我早期關於撲克 AI 的大量研究,實際上並沒有過多地關注推理。很多研究更像是「預訓練」。你會花大量時間來訓練這些模型,可能要在大型系統上訓練兩到三個月。此外,我們那時還沒用 GPU,實際上用的是 CPU。但是,當真正開始玩牌時,AI 的反應速度非常快,可能只需要 10 到 100 毫秒。它的工作原理就像一個查找表。
之前也有一些研究,探討如何為這些系統增加推理計算能力,但這並不是研究的重點。原因有很多,其中一個是讓 AI 具有推理能力本身就非常困難。現在大家都知道,AI 玩國際象棋運用了 Alpha-Beta 剪枝技術,AI 玩圍棋則是通過蒙地卡羅樹搜索。但這兩種技術在撲克中都行不通。所以,撲克推理一直是一道難題。
此外,撲克是一種方差非常高的遊戲。玩牌的人都知道,就算你牌技很差,也有機會靠運氣贏錢。即使是職業撲克玩家,也可能因為年景不好,打了一整年牌最後還是虧錢。但如果突然之間,你對每一張手牌的思考時間從 10 毫秒變成了 20 秒,問題就來了——因為這中間可能要過掉上百萬張牌,才能從結果中判斷一個 AI 是否比另一個 AI 更厲害——你肯定不想花那麼多時間。所以,有很多原因導致這個研究方向被忽視了,而最大的原因,是人們沒有意識到推理計算會帶來這麼大的差異。
我在研究過程中,總覺得好像缺了點什麼。人類在遇到棘手情況時,在行動之前會花很多時間思考。也許,這種思考能力會非常有用。當我深入研究這個問題,並看到它帶來的巨大改變時,我立刻意識到,這方面需要大力發展。所以我們最終在 AI 撲克使用的技術,與國際象棋、圍棋等遊戲中使用的技術非常不同。所以對我來說,真正的啟示是並不存在一種通用的系統可以解決所有問題。
主持人:這裡面有一個從快思考(System 1)到慢思考(System 2)的轉變。
諾姆·布朗:沒錯。2017 年我們開發的撲克 AI 叫 Libratus,我認為那是一個重大突破。然後在 2019 年,我們推出了 Pluribus,我認為它的性能更進一步。兩者之間具體細節的差異,其實沒那麼重要,重點在於 Pluribus 成本更低。我們開發出了一種更好的、擴展推理計算的方法,讓成本進一步降低。2019 年的 Pluribus,在雲端計算上訓練的成本不到 150 美元。
我認為這個結果真正表明,這不僅僅是摩亞定律或者 Scaling Law 在起作用,而是我們實際上採用了一種不同的範式,它在推理階段利用了更多的計算資源。正因為如此,我們才能夠實現這樣的突破。如果人們當時知道要採取這種方法,並且知道要使用哪些算法,那麼 20 年前就能做到這一點。
主持人:你說訓練它只花了 150 美元。那在實際玩牌的時候,它的計算量大概是 10 萬美元對 5 萬美元的水平嗎?
諾姆·布朗:Pluribus 在推理時,使用了 28 個 CPU 核心。每張手牌大約需要 20 秒的推理時間。這其實已經很便宜了,但如果和以前的技術相比,以前只用一個 CPU,每張手牌大約只能推理 10 毫秒甚至更短的時間,所以在推理計算方面,這絕對是一個巨大的提升。
主持人:這真是令人印象深刻。我們接下來聊聊你的另一項工作,CICERO。你在其中融入了語言組件,用於 AI 的對話、談判和溝通。
白賴仁·卡坦紮羅:諾姆,我想請你先解釋一下《強權外交》這款遊戲,可能有些人還沒玩過。
諾姆·布朗:《強權外交》是一個七人遊戲。它涉及到自然語言交流。實際上,這款桌遊的真正複雜之處,在於與其他玩家進行談判。遊戲實際的機制非常簡單,複雜性主要來自於與人互動。
在我們的撲克 AI 取得成功之後,與此同時,DeepMind 在《星際爭霸》和 OpenAI 在《Dota 2》等遊戲上也取得了成功。我們當時就在思考,接下來應該關注什麼方向?差不多在那個時候,我們也看到了語言模型方面的圖片,因為 GPT-2 就在 2019 年發佈。
總之,一直以來,我和我的同事們都在討論《強權外交》這款遊戲。實際上,我以前覺得研究這種桌遊簡直是天方夜譚。我當時想,這太難了。但是,我的同事 Adam Lerer 說服了我,他說,為什麼不試試呢?不妨把目標定得更高一點。
 Adam Lerer
Adam Lerer我們已經在撲克 AI 上取得了巨大的成功。所以我們當時就在想,我們怎樣才能超越之前的成就呢?不如就瞄準一個高風險、高回報的目標,如果成功了,那肯定會非常酷。
白賴仁·卡坦紮羅:我認為要玩好《強權外交》這款遊戲,不僅要非常擅長推理和戰略思考,還要有說服力。你必須建立同盟,然後在合適的時機背叛他們。所以我認為,這比撲克或國際象棋要難得多,撲克和國際象棋的規則要嚴格得多,也更機械化。《強權外交》這款遊戲更加模糊,也更人性化。
主持人:這就是我想說的,與你之前在撲克 AI 方面的工作相比,CICERO 是在 Meta AI 做的,對吧?不是在 CMU 做的。它包含了一些超越你之前為撲克 AI 所做的工作的內容。
諾姆·布朗:《強權外交》這款遊戲的複雜性,我認為可以從三個維度來看。
首先,我們的研究從撲克這樣的雙人零和遊戲,變成了一個涉及多名玩家、涉及到真人並且需要理解真人的遊戲。這其中還有很多複雜性,我們可以專門開一個討論會來探討。
還有一個維度是,我們進入了自然語言領域,在一個如此開放、如此自由的行動空間中進行推理,又意味著什麼?在國際象棋中,任何一個時刻,都有大約 20 個合理的行動可以選擇。而在撲克中,可能就是棄牌、跟注、加註這幾個選項,
當然,還有如何平衡這些行動的問題,但總的來說,行動空間還是相對有限的。而在《強權外交》這種桌遊里,你的行動空間是你可能對另一個人說的一切。這種複雜性,直接把推理難度提升到了一個全新的水平。
主持人:在我們深入討論 CICERO 之前,我想補充一個問題。你剛剛提到計算量顯著減少了,這為後來 Libratus 和 Pluribus 之間的發展奠定了基礎。是什麼讓這種降低成為可能?主要是算法上的改進,對嗎?
諾姆·布朗:從 Libratus 到 Pluribus,雙人撲克 AI 變成了六人撲克 AI,訓練成本降到了 150 美元,這主要是算法上的改進。而真正的原因是,我們開發出了更好的推理技術,這讓我們可以在預訓練上投入更少的精力,並將更多的計算負擔轉移到了推理階段。
主持人:那麼,當你轉向 CICERO 時,計算需求發生了怎樣的變化?它是你在 CPU 上對撲克 AI 所做的工作,與 GPU 計算的結合嗎?
諾姆·布朗:不,那時候我們已經轉向了。一旦你開始處理自然語言談判,你就必須轉向神經網絡,轉向語言模型。所以,計算負擔就轉移到了 GPU 上。
主持人:我想接著 GPU 的話題來問一問白賴仁。傳統的深度學習一直都是矩陣乘法密集型的,因此 GPU 在這方面表現非常出色。自從諾姆和他的團隊和導師們最初在撲克 AI 方面開展工作以來,推理方面的工作也成倍增加。當你在英偉達內部進行設計或研究時,你是如何考慮這個問題的?
白賴仁·卡坦紮羅:我們在英偉達所做的工作,實際上是試圖理解世界上最重要的計算,然後從頭到尾優化它們。顯然,我們製造 GPU,然後製造網絡,但我們也構建編譯器、庫、框架,並且我們也研究算法和應用。我們加速計算的目的,是為了讓大家能夠做到以前做不到的事情。
黃仁勳在他的主旨演講中說,他聽到的最高讚揚,是一位科學家說:「感謝你們,我真的可以在我的有生之年完成我畢生的工作了。」 這就是我們在英偉達的目標。我們堅信,要提供真正能改變行業格局的加速,實現像諾姆提到的那種突破,唯一的辦法就是從頭到尾地思考問題,並在技術棧的每一層,尋找加速的機會。所以,這就是我們所做的事情。
現在,你剛才提到了一個很有意思的點,說這項工作實際上是矩陣乘法密集型的。這確實沒錯。我相信,人工智能算法和人工智能系統的發展是相輔相成的。人工智能系統對於人工智能的發展至關重要。算法顯然也非常重要,而且成功的算法往往是協同進化的。
有趣的是,如果大家回顧一下 2012 年,當 Alex Krizhevsky 和 Ilya Sutskever 發表 ImageNet 論文時,如果你仔細閱讀那篇論文,它完全重新定義了整個計算機視覺領域,但它本質上是一篇系統論文。它主要探討的問題是,我們如何以更有效的方式訓練更大的模型?

這種系統層面的投入,帶來了許多算法上的突破,這些突破徹底重塑了整個計算機視覺領域。然後,隨著不斷迭代,就會形成一個良性循環。我相信,人工智能領域之所以如此受矩陣乘法主導,原因之一在於,這是構建能夠完成大量計算工作的計算機,最有效的方式。
矩陣乘法的特性,非常適合我們現有的技術,比如構建系統、在數據中心之間分配計算任務,以及構建可以投入大量計算資源的模型。我認為這非常重要。當然,將矩陣乘法轉化為智能,絕非易事。我們整個社區花費了數十年的時間,才弄清楚如何達到今天的水平。但我認為,重要的是要認識到,這些要素——系統和算法——它們是相互關聯和協同發展的。在我的職業生涯中,我一直看到它們彼此需要。我們投入到人工智能中的計算資源越多,效果就越好,算法也會變得更智能,這反過來又會推動下一輪的創新。
諾姆·布朗:我認為白賴仁說得 完全正確。算法和計算之間確實存在著緊密的聯繫,設計優秀算法的關鍵,在於開發出一種能夠最有效地利用計算資源,並最大程度地擴展計算能力的技術。當我們思考算法時,我們總是會考慮它的可擴展性。比如,如果我們將計算規模擴大一千倍,會發生什麼?它會遇到什麼瓶頸?這實際上是我很多工作,當然也是很多其他研究工作的出發點。
主持人:你們早期的很多工作都是在學術界完成的。現在我看到很多論文,也和很多研究人員交流過,感覺現在發表的大部分論文,都離真正令人興奮的成果還差一口氣,這主要是因為缺乏足夠的計算資源。
但即便如此,當你們最初開展研究工作時,也已經能夠使用相當強大的超級計算機了,這在多大程度上是一個關鍵因素呢?因為從你們從學術界過渡到 Meta,再到 OpenAI,發展軌跡一直非常順暢和連貫。
諾姆·布朗:確實,如果以研究生的標準來看,我當時能使用的計算資源已經非常多了。我們當時用的是數千個 CPU——現在看來這不算什麼,但對於當時的研究生來說,已經非常了不起了。我確實認為,在某種程度上,這最終成為了一個非常重要的因素。我認為,如果沒有那些計算資源,我們不可能在撲克 AI 方面達到超越人類的水平。
我之前說過,在 2019 年,我們開發的那個機器人,訓練成本不到 150 美元,並且可以在 28 個 CPU 核心上運行。當你達到那個階段,最後的訓練成本非常低,推理成本也相對較低,但是,所有前期為了找到正確的研究範式所做的探索,成本是非常高昂的。為了能夠比較不同的推理技術,並得出結論,像是「這種技術的性能,和將推理規模擴大一千倍,並在 2000 個 CPU 核心上運行三個月的效果相當」——為了能夠進行這樣的比較,就需要大量的計算資源。
因此,我認為現在這確實是一個挑戰。我經常和很多研究生交流,他們會問我,在計算規模變得如此巨大的時代,我們如何才能做出有影響力的研究?這是一個很難回答的問題。當然,在像 OpenAI 這樣的前沿實驗室,進行這種前沿能力的研究,肯定要容易得多。在學術界,仍然可以做出有影響力的研究。
我認為,探索全新的研究範式,通常不需要大量的計算資源。但是,要大規模地驗證這些新範式,肯定需要大量的計算投入。不過,前沿實驗室和學術界之間,還是存在合作機會的。前沿實驗室肯定會關注學術界發表的論文,並認真思考,這些論文是否提出了令人信服的論點,證明如果將論文中提出的方法進一步擴展,將會非常有效。如果論文中確實有這種有說服力的論點,我們就會在實驗室里進行深入研究。
此外,像評估、基準測試之類的工作,也存在機會。人工智能基準測試的現狀非常糟糕,而改進基準測試,並不需要大量的計算資源。
主持人:但這需要一些投入,比如在設計和整合方面。
諾姆·布朗:這確實需要大量的工作和努力,但對於計算的負擔相對較低。
白賴仁·卡坦紮羅:是的。我認為,人們開展研究工作的方式,也存在一些必要的差異。前沿實驗室,可以負擔得起在一個項目上投入大量資源,並將其做大的成本。比如,大家可以看看 GPT-4 的論文,有多少作者參與了這篇論文,對吧?而學術界,有發表論文的需求,這樣學生才能畢業。學生需要完成博士論文,所以他們需要對某一部分工作擁有主導權。
我之所以說這些,是因為我實際上相信,人工智能正在吞噬的第一個領域,就是人工智能研究本身。因為各種力量都在推動我們進行合作,構建更宏大的項目,讓更多人參與進來,這樣我們才能真正敢於下大賭注,進行大規模投入。這使得那種研究模式,變得非常困難,即我們有很多小型項目,每個項目都試圖在某個方面達到最先進的水平。
我認為,這正在推動整個領域,走向一種新的模式,即學術界仍然會湧現出許多非常有趣和重要的研究工作,但這些工作必須以較小的規模進行。然後,將這些學術研究成果,整合到前沿模型中的過程,也就是整合到像你在 OpenAI 構建的那種,最終會被實際部署的模型中的過程,我認為這必須作為第二步來完成。這主要是因為,構建這些模型所需的投入實在太大了,我認為這確實正在改變我們進行研究的方式。
主持人:這是一個值得進一步探討的話題。讓我們回到《強權外交》和 CICERO 相關的工作上。諾姆,你前面也有提到 OpenAI o1,而在最終目標方面,它和 CICERO 之間存在一些差異。
但是,如果大家對外交這類事情非常感興趣,並且你們已經在某種遊戲環境場景中,成功地實現了用於外交的 AI。那未來是否有可能將這項技術,應用到現實世界的情境中,比如談判或多方政府對話等等?
諾姆·布朗:對於外交 AI 的研究工作,也就是關於《強權外交》遊戲的 CICERO 項目,我們從這項工作中學習了很多,我認為整個社區也從中獲益匪淺。我認為我們更深入地理解了,開發用於多智能體環境的 AI,意味著什麼?在一個非常靈活、開放的環境中進行推理,又意味著什麼?用於外交 AI 的技術,在某種程度上是特定於《強權外交》這款遊戲的。
主持人:那如果有人問,CICERO 能否直接用於現實世界的談判?
諾姆·布朗:不能。至少沒法開箱即用。這並不是我們研究的真正目的,這並不是我們最初的目標。我們的目的是,探索自然語言博弈中的「外交」這個領域。因為如果你把所有現有的技術,比如 Alpha Zero、Pluribus,都拿來嘗試應用於這款遊戲,你會發現它們根本行不通。這說明,一定有什麼東西是缺失的。然後,通過探索這個領域,弄清楚缺失的到底是什麼,你就能從這個過程中學到很多東西。
學術界也能從這個過程中學到很多。我個人從中得到的一個重要啟示是,我們之前開發的推理技術,都太過於狹隘了。深度學習最美妙的地方之一,就是它極其靈活的範式。你可以把 Transformer 模型,應用到各種不同的領域,它基本上都能開箱即用。但事實上,我們卻不得不為所有這些不同的場景,為撲克、國際象棋、圍棋和《強權外交》開發出非常特定於領域的推理技術,這大大減緩了開發進程。
我們確實開發出了一種在《強權外交》遊戲中有效的推理技術。我們也取得了非常出色的性能。但這卻花費了數年的時間才開發出來。如果我們接下來想研究,比如現實世界中的實際談判,那又需要花費數年時間,才能開發出適用於那種場景的技術。所以,我從這項工作中得到的啟示是,我們需要開發出一種推理方法,它應該像深度學習在快思考(System 1)思維方面所展現出的那樣,具有廣泛的適用性和高度的靈活性。
主持人:我想問兩位一個問題。首先,我假設我們最終肯定會達到目標,我們會構建出真正的多智能體環境,在其中可以進行複雜的談判。那在那種情況下,計算能力,計算技術的進步,以及算法的進步,都必須攜手並進。Brian,你是如何看待這種未來發展趨勢的?
白賴仁·卡坦紮羅:其實黃仁勳在他的主旨演講中,已經很好地闡述了這一點。他談到了針對不同任務的不同擴展方式。我認為我們現在可以清楚地看到,推理作為一個計算問題,其規模是非常龐大的。因為,當我們在訓練這些模型,當它們學習如何推理時,它們需要不斷練習,它們需要學習,需要不斷嘗試,獲得反饋,然後再嘗試。因此,這裏存在著一個巨大的機會,可以將計算資源,或者說模型的推理能力,轉化為智能,這是一種我們以前從未實現過的轉化方式。這就是我對這個問題的看法。
現在,這對於我們將要構建的系統類型,以及我們將要運行的軟件,都產生了巨大的影響。這與之前那種預訓練密集型的模型,截然不同。在預訓練密集型模型中,絕大部分計算資源,都投入到了訓練模型本身,也就是在越來越大的數據集上,訓練越來越大的模型。
我認為,預訓練仍然非常重要,因為我把預訓練看作是構建推理能力的基礎。基礎越牢固,推理能力就越強大。因此,我們將繼續看到進步,而且這些進步的速度,甚至超過了摩亞定律。無論是訓練模型的速度,還是在相同的計算資源下,模型所能擁有的智能水平,都在以超越摩亞定律的速度提升。這要歸功於所有投入到基礎模型本身的研究工作。
但是,我們投入到後訓練和推理計算中的計算資源,正在快速增長。我們英偉達正在思考,這對網絡技術、低精度運算、稀疏性計算以及如何設計下一代推理系統,會產生怎樣的影響,這十分令人激動。我認為這才是我們當前的首要任務。如果大家回顧一下昨天主會演講的內容,就會發現,英偉達認為這對於整個世界來說,都是一個巨大的機遇,我們非常興奮能夠幫助推動它向前發展。
諾姆·布朗:我完全同意白賴仁的看法。我認為,我們現在正處在一個非常激動人心的時刻。我們現在擁有了真正的推理模型。我認為,從 OpenAI o1 開始,這些模型就能以非常廣泛的方式進行推理,這在我看來,是一種全新的範式。就像 AlexNet 的出現,引發了對推理計算的大規模投入一樣,而不是僅僅關注訓練,而是開始大力投入 GPU 和其他硬件的研發。我認為,我們現在正處在一個關鍵節點,我們擁有了能夠進行慢思考(System 2)思維的推理模型,而不僅僅是快思考(System 1)思維。而且,這個領域還有巨大的擴展空間,也有很大的潛力去開發,專門針對推理計算的硬件。
當然,這並不是說預訓練已經過時了。我也同意白賴仁的觀點,預訓練仍然至關重要。我和一些嘗試為小規模 LLM 開發推理技術的人交流過,結果發現根本行不通。比如,你嘗試在 GPT-2 這樣的小模型上,實現像 OpenAI o1 這樣的推理能力,根本無法取得進展。所以,預訓練和推理是相輔相成的,它們是攜手並進的,我認為我們會在這兩個方面都看到持續的進步。
白賴仁·卡坦紮羅:我認為,也許目標已經發生了轉變。至少在我過去從事預訓練研究時,預訓練的目標只是嘗試獲得一個能夠收斂的模型,並且要儘可能地擴大模型規模,儘可能在最大的數據集上訓練模型。然後,模型主要還是以快思考(System 1)的方式來使用,比如,你給它一個問題,它會直接給出一個答案,對吧?因此,在那種模式下,當你考慮如何構建系統,以及如何使用系統的平衡時,你會發現,大部分的計算資源,都投入到了構建系統本身,而使用系統則相對簡單直接。
但隨著推理技術的進步,現在,我們有了一個更加複雜的訓練過程,因為推理本身,也成為了訓練過程的重要組成部分。因此,用於在推理後訓練階段,進行大規模推理的軟件和硬件,與我們用於預訓練的軟件和硬件,是完全不同的。
這裡面蘊藏著巨大的加速潛力。所以,我對此感到非常興奮。此外,當模型被部署之後,現在在我看來,推理成本與智能水平是直接相關的。因為,如果你能大幅降低模型的推理成本,那就意味著它可以進行更長時間的思考,從而更好地解決問題。
而在過去,情況並非如此,對吧?在以前的思維模式下,我們總是希望模型儘可能地龐大,因為模型越大,就越智能。但現在,我們希望模型能夠達到一個最佳平衡點,也就是,在單位推理成本下,模型所能達到的最大智能水平。這樣的模型最終才會成為最智能的模型。因此,從加速計算的角度來看,這已經是一個完全不同的問題了。
諾姆·布朗:我認為白賴仁提出了一個非常好的觀點。很多人可能沒有意識到,用基準測試的性能來衡量模型智能,這種單一數字的比較,其實已經毫無意義了。你必須從「單位成本智能」的角度來思考,比如,每美元能買到的智能,或者每 token 能產生的智能。如果一個模型可以進行非常長時間的思考,它在所有這些基準測試中的表現都會更好。因此,你真正需要考慮的,是一條智能與成本的曲線。上限可以非常高,如果你願意投入足夠的成本。我認為,這就是我們未來發展的方向。
白賴仁·卡坦紮羅:我們未來肯定會願意投入更多成本。我對此相當確信,因為即使是現在最昂貴的模型,也比人類便宜得多,令人驚訝的是。它們產生的碳排放量也比人類少。這意味著,我們將能夠找到更多方法,利用它們來解決比今天更多的問題。而且我認為,作為一個社區,我們將會找到各種方法,讓真正深度參與的推理程序,來解決真正重要的問題。我認為,這將徹底改變人工智能的應用方式。
諾姆·布朗:我認為,當人們看到這些推理模型時,他們可能會覺得,哦,這東西太貴了。但問題是,和什麼比呢?如果和 GPT-4 相比,那當然,它確實很貴。但如果和試圖完成同樣任務的人類相比,那就太便宜了。與人類進行比較,是非常有意義的,尤其是在智能水平不斷提升的情況下。一旦這些模型在某些領域超越了頂尖人類,你就可以思考一下,世界上最頂尖的人才,完成一項任務,會獲得多少報酬?他們會因為自己的專業知識,而獲得非常高的溢價。而現在,模型已經具備了這種專業知識,但成本卻只有人類成本的一小部分,這其中蘊含著巨大的價值。
主持人:那麼,回到今天討論會的主題,你們從遊戲和人類的互動中,學到了一些東西。你從 Libratus 到 Pluribus 的轉變,觀察到人類在回答問題之前,會花更多的時間思考。你們是否會重新審視這一點?因為人類本性中,還有一些方面,比如適應性等等,實際上尚未被 AI 模型所捕捉。這仍然是一個開放的研究領域嗎?還是說,已經有其他和你一樣優秀的科學家正在研究這個問題了?
諾姆·布朗:我認為,如果你審視一下今天的人工智能範式,就會發現,我們還沒有完全解決所有的研究問題。仍然存在一些開放性的研究問題,需要我們去探索和解答,才能最終解鎖,我個人認為,是全面解鎖超級智能。如果你回顧過去 15 年,特別是過去 5 年的進步速度,我認為這已經超出了所有人的預期。而且現在有很多 AI 批評家,他們會指出某些方面,然後說「你看,這些模型做不到這個或那個」。人們已經這樣說了 10 年了。
白賴仁·卡坦紮羅:哦,不止 10 年了。
諾姆·布朗:是的,但真正重要的是,你必須關注技術發展的軌跡。沒錯,現在有一些事情是模型還做不到的。但是,已經有人在努力解決這些問題了。在我看來,我們有非常充分的理由,對未來的進步保持樂觀。因此,你必須從發展的眼光來看待問題,思考一年後、兩年後,人工智能會發展到什麼程度。我認為,未來的發展會非常令人印象深刻。我的意思是,即使未來沒有任何進一步的研究進展,我們今天擁有的模型,也已經足以帶來變革性的影響。
主持人:最後一個問題想問兩位。在幾年之後,擁有最先進人工智能推理能力的理想世界,在你們看來會是什麼樣的?它會是一個理想的世界嗎?
白賴仁·卡坦紮羅:假設所有這些研究都取得成功,人們也找到了應用這些技術的有效方法。
主持人:並且,我們暫且不討論它的合法性問題。
白賴仁·卡坦紮羅:我認為人工智能最終會是合法的,因為我們確實需要它。我認為世界需要人工智能。當我環顧四周,我看到這個世界對智能的需求是如此巨大。我們有太多問題不知道如何解決。我們有太多的機會,可以找到更好的方法來建設世界,讓世界變得更安全,解決我們社會長期存在的各種難題。我認為,我們需要更多的智能來應對這些挑戰。而人類的力量,與強大的推理模型相結合,意味著你將擁有一個強大的團隊,來幫助你解決最複雜的問題,幫助你理清最棘手的問題。這將使人類能夠做出一些真正重要的改變,幫助我們所有人生活得更好。所以我對未來,真的非常樂觀。
諾姆·布朗:我對未來持樂觀的願景。我認為人工智能是一項非常強大的技術,我對未來最樂觀的設想是,它將顯著提高生產力,加速科學進步。就像我們在過去一百年,甚至更長時間里,看到的令人難以置信的社會進步一樣,嬰兒死亡率大幅下降,人類文明在許多方面都取得了巨大的進步。人工智能將進一步加速這些進步。所有這些美好的事物都將繼續發展壯大。
當然,任何強大的技術,都存在風險,既有積極的一面,也有消極的一面。我希望,消極的風險也能得到妥善解決。但我個人還是比較樂觀的。我相信,這些模型最終將能夠,正如白賴仁所說,增強人類的能力,與人類形成互補,促進科學進步,實現那些原本不可能實現,或者需要花費更長時間才能實現的突破。我認為,這就是我們對未來保持樂觀的理由。
* 本文由 CSDN 精編整理。
* 今場對話源自 GTC 2025,日程為香港時間 2025 年 3 月 20 日 2:00 AM – 2:40 AM。

3. 諾姆:未來要看「單位成本智能」
【活動分享】2025 全球機器學習技術大會(ML-Summit)將於 4 月 18-19 日在上海舉辦。大會共 12 大主題、50+ 位來自學術界和一線技術實戰派的頂尖專家,聚焦下一代大模型技術和生態變革技術實踐。詳情參考官網:http://ml-summit.org/。