阿里深夜開源Qwen2.5-VL新版本,視覺推理通殺,32B比72B更聰明
機器之心報導
機器之心編輯部
就在 DeepSeek V3「小版本更新」後的幾個小時,阿裡通義千問團隊也開源了新模型。
擇日不如撞日,Qwen2.5-VL-32B-Instruct 就這麼來了。
相比此前的 Qwen2.5-VL 系列模型,32B 模型有如下改進:
-
回覆更符合人類主觀偏好:調整了輸出風格,使回答更加詳細、格式更規範,並更符合人類偏好。
-
數學推理能力:複雜數學問題求解的準確性顯著提升。
-
圖像細粒度理解與推理:在圖像解析、內容識別以及視覺邏輯推導等任務中表現出更強的準確性和細粒度分析能力。
對於所有用戶來說,在 Qwen Chat 上直接選中 Qwen2.5-VL-32B,即可體驗:https://chat.qwen.ai/
32B 版本的出現,解決了「72B 對 VLM 來說太大」和「7B 不夠強大」的問題。如這位網民所說,32B 可能是多模態 AI Agent 部署實踐中的最佳選擇:

不過團隊也介紹了,Qwen2.5-VL-32B 在強化學習框架下優化了主觀體驗和數學推理能力,但主要還是基於「快速思考」模式。
下一步,通義千問團隊將聚焦於長且有效的推理過程,以突破視覺模型在處理高度複雜、多步驟視覺推理任務中的邊界。
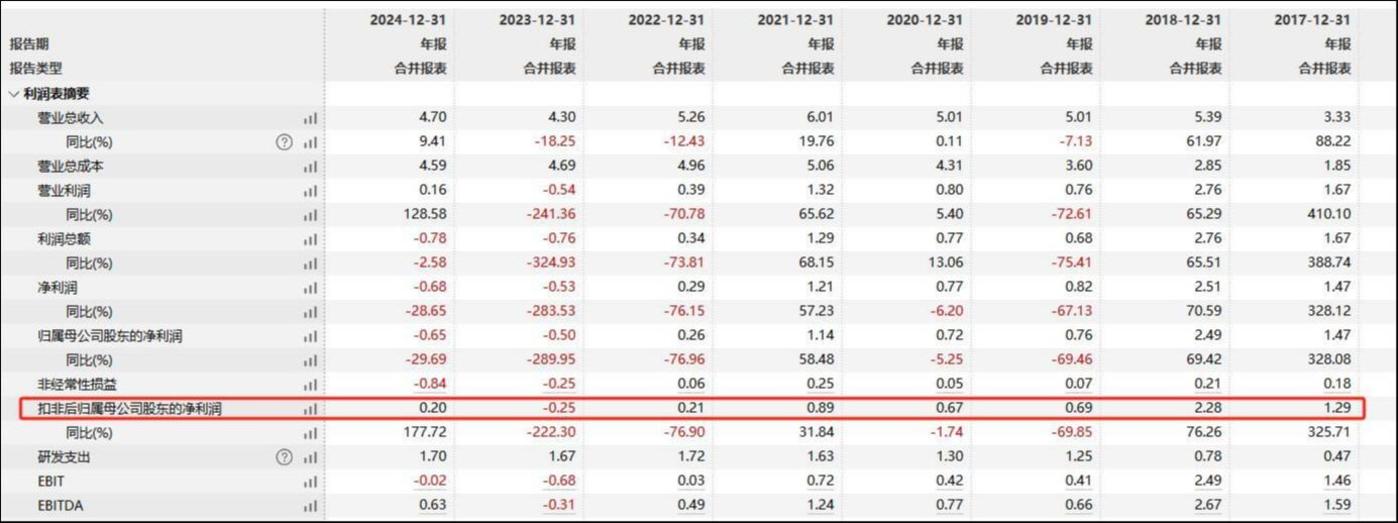
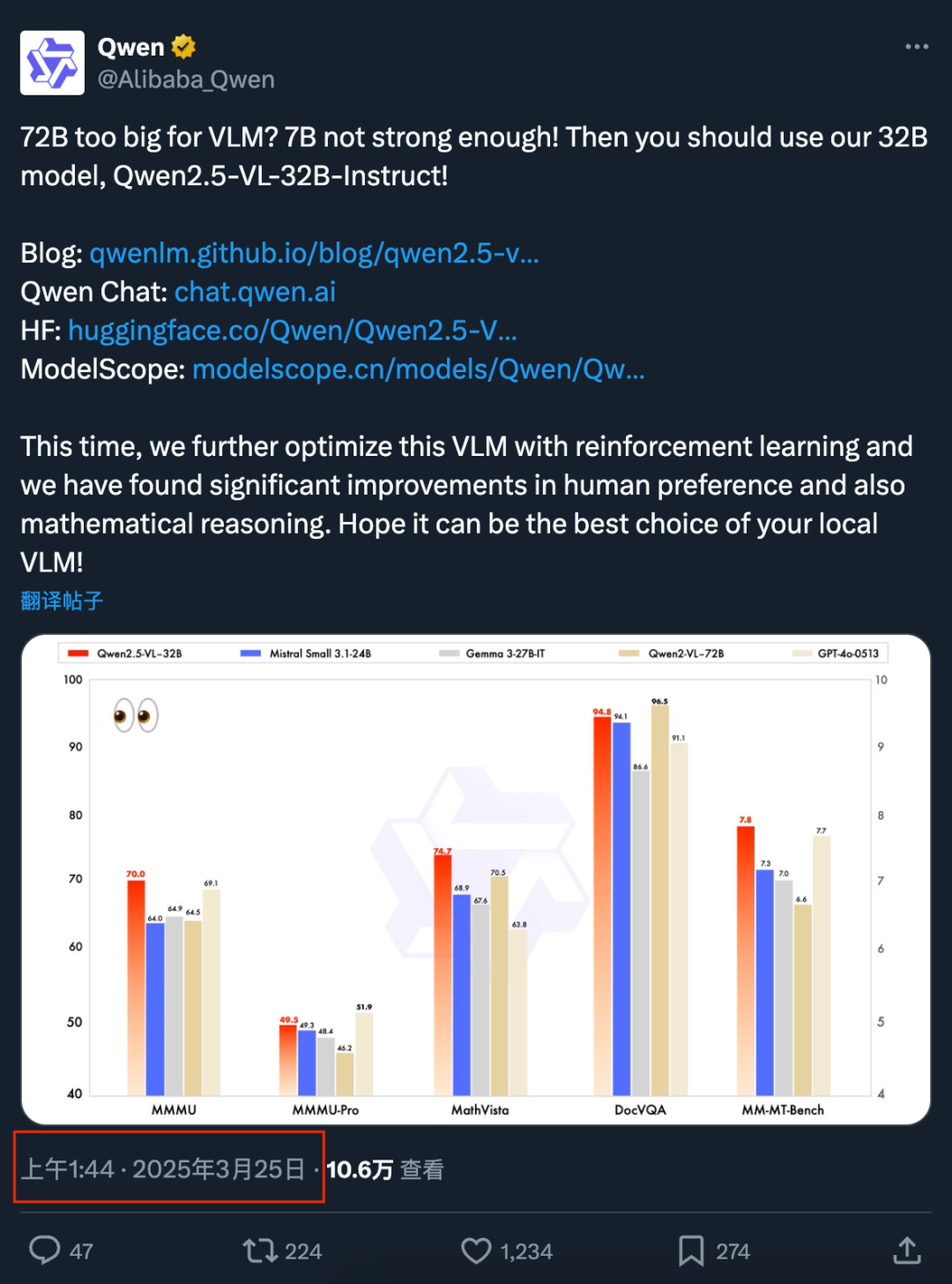
32B 可以比 72B 更聰明
先來看看性能測試結果。
與近期的 Mistral-Small-3.1-24B、Gemma-3-27B-IT 等模型相比,Qwen2.5-VL-32B-Instruct 展現出了明顯的優勢,甚至超越了更大規模的 72B 模型。
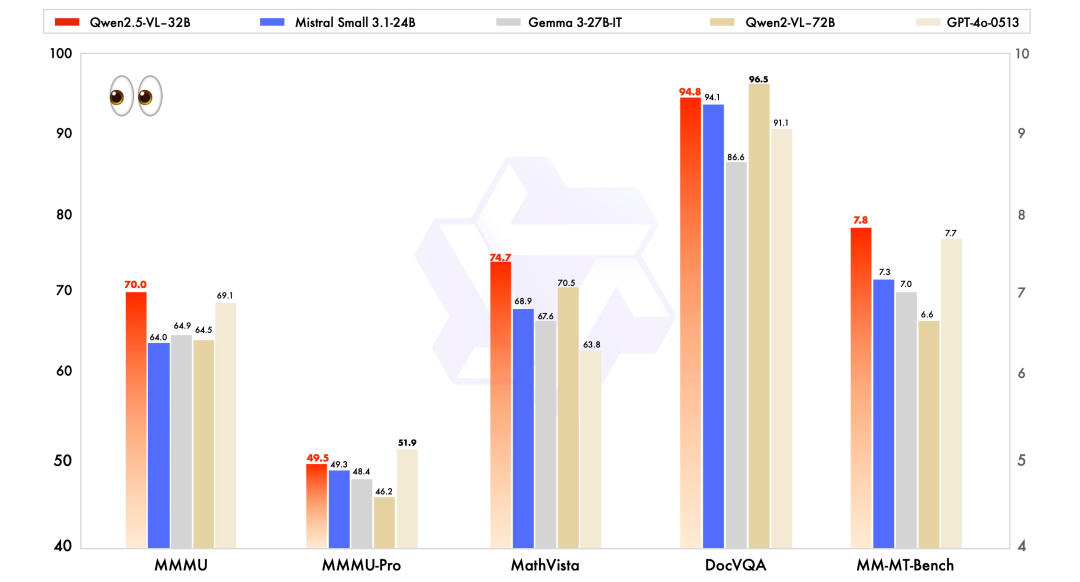
如上圖所示,在 MMMU、MMMU-Pro 和 MathVista 等多模態任務中,Qwen2.5-VL-32B-Instruct 均表現突出。
特別是在注重主觀用戶體驗評估的 MM-MT-Bench 基準測試中,32B 模型相較於前代 Qwen2-VL-72B-Instruct 實現了顯著進步。
視覺能力的進步,已經讓用戶們感受到了震撼:

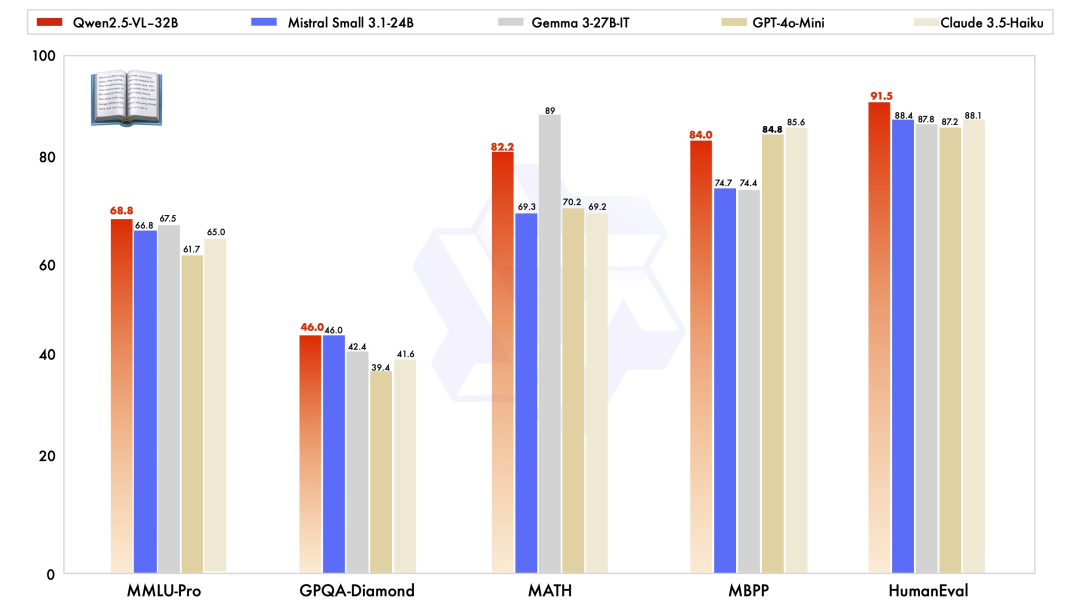
除了在視覺能力上優秀,Qwen2.5-VL-32B-Instruct 在純文本能力上也達到了同規模的最優表現。
實例展示
或許很多人還好奇,32B 版本的升級怎麼體現呢?
關於「回覆更符合人類主觀偏好」、「數學推理能力」、「圖像細粒度理解與推理」這三個維度,我們通過幾個官方 Demo 來體會一番。
第一個問題,是關於「細粒度圖像理解與推理」:我開著一輛卡車在這條路上行駛,現在是 12 點,我能在 13 點之前到達 110 公裡外的地方嗎?

顯然,從人類的角度去快速判斷,在限速 100 的前提下,卡車無法在 1 小時內抵達 110 公里之外的地方。
Qwen2.5-VL-32B-Instruct 給出的答案也是「否」,但分析過程更加嚴謹,敘述方式也是娓娓道來,我們可以做個參考:

第二個問題是「數學推理」:如圖,直線 AB、CD 交於點 O,OD 平分∠AOE,∠BOC=50.0,則∠EOB=()
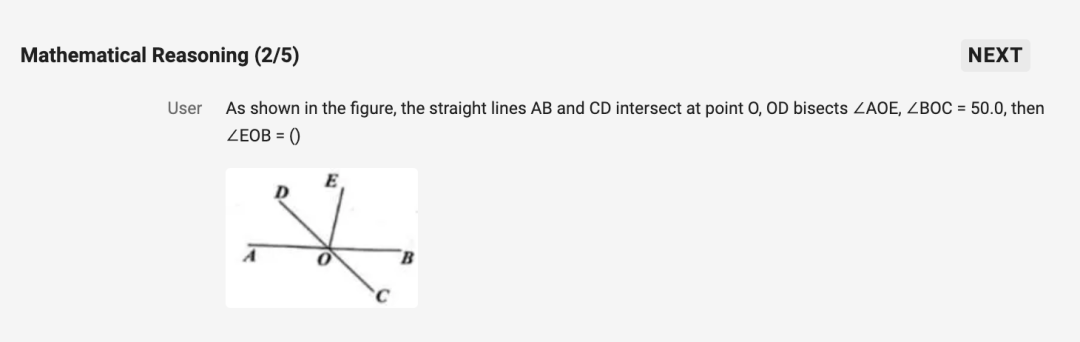
答案是「80」:


第三個題目的數學推理顯然更上難度了:
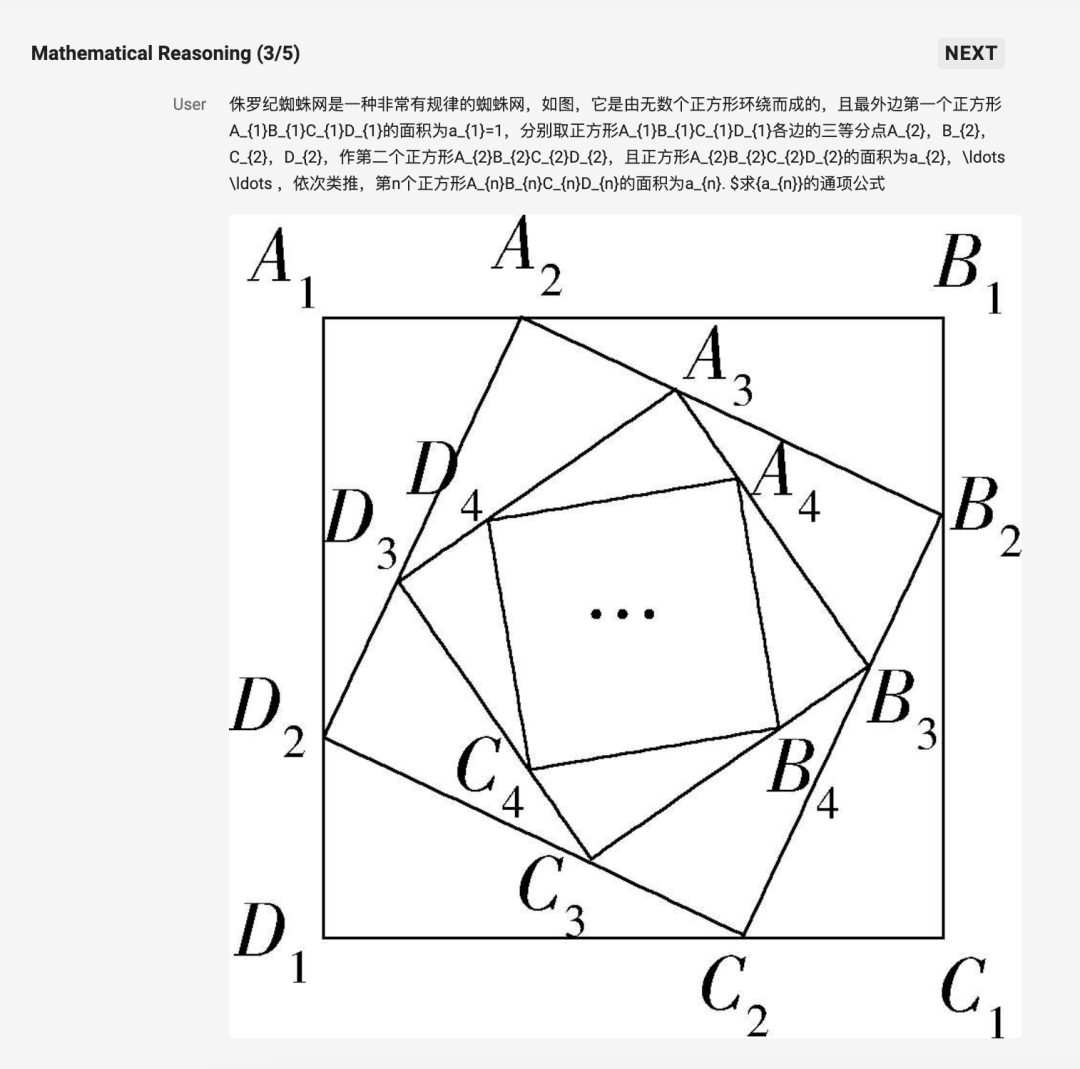
模型給出的答案特別清晰,解題思路拆解得很詳細:



在下面這個圖片內容識別任務中,模型的分析過程也非常細緻嚴謹:
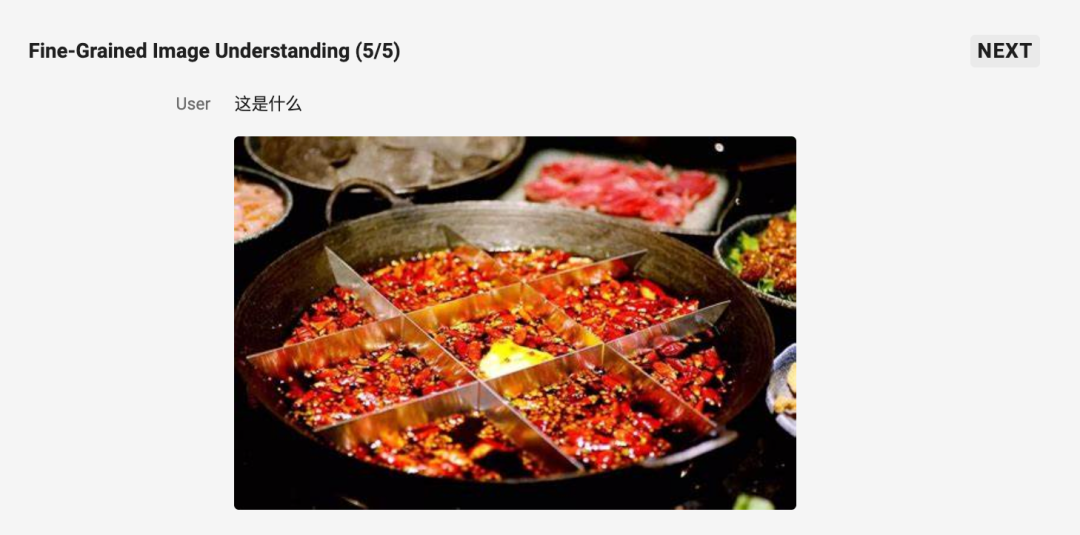


關於 Qwen2.5-VL-32B-Instruct 的更多信息,可參考官方博客。
博客鏈接:https://qwenlm.github.io/zh/blog/qwen2.5-vl-32b/