DeepSeek-V3深夜驚爆上新,代碼數學飆升劍指GPT-5,一台Mac可跑
685B的DeepSeek-V3新版本,就在昨夜悄悄上線了。參數量685B的V3,代碼數學推理再次顯著提升,甚至代碼追平Claude 3.7,網民們實測後大呼強到離譜!有人預測說,按照此前的節奏,DeepSeek-R2大概率幾週內就將上線。
昨晚,DeepSeek-V3悄然升級!
新模型版本為DeepSeek-V3-0324,參數量為6850億,相較上個版本參數增幅不大(6710億)。

從發佈時間和技術特點來看,DeepSeek-V3-0324,很可能是DeepSeek-R2的基礎架構。
所以按照DeepSeek一貫的產品發佈節奏(先推出基礎模型,幾週後再發佈專門的推理增強版)來看,DeepSeek-R2很可能在幾週後就將上線!
升級後的V3在代碼、數學推理能力上,得到顯著提升。尤其是代碼領域,不少網民直呼「眼前一亮」。
相較於上一版,從一球在超立方體彈跳的Python腳本,即可看出V3代碼性能的改善。
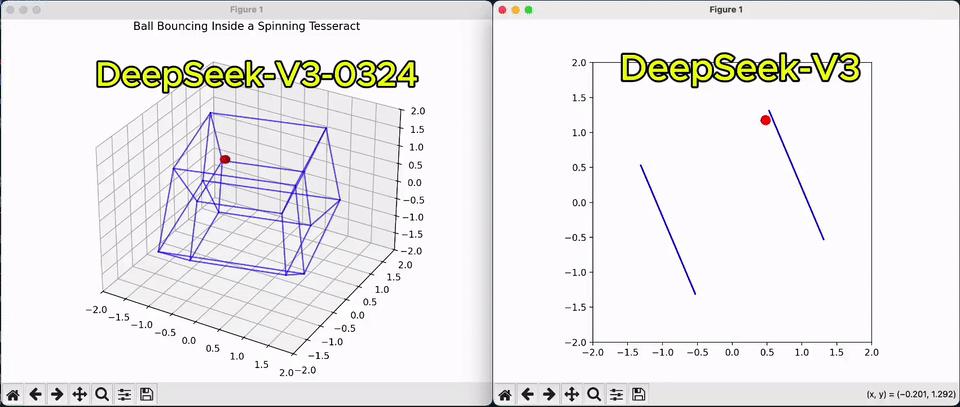
甚至,它還能解鎖Claude 3.7 Sonnet很多玩法,代碼可以與之正面較量。
值得一提的是,DeepSeek V3另一大亮點在於採用MIT開源協議,上個版本還是自定義許可證。
這不僅可以自由修改、分發模型,還支持模型蒸餾、商業化應用。
 模型文件總計641GB,主要以model-00035-of-000163.safetensors形式存在
模型文件總計641GB,主要以model-00035-of-000163.safetensors形式存在685B雖大,但也能在消費級設備上跑起來。
這不,蘋果機器學習工程師Awni Hannun就基於MLX框架和4-bit量化,在512GB M3 Ultra實現了超過20 token/s的運行速度。

這種量化方式直接將模型的磁盤佔用空間減少到352GB。
有M3 Ultra的童鞋們,可以按照下面的方式使用llm-mlx跑起來:
- llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
- llm chat -m mlx-community/DeepSeek-V3-0324-4bit
若是本地跑不了的朋友,除了官網之外,還可以在OpenRouter上體驗。
體驗地址:openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free
相比起某些會在發佈前數月就開始大肆宣傳造勢的O和A開頭的AI公司,DeepSeek這種低調辦大事的風格可謂是天壤之別。
沒有白皮書,沒有博客文章,只有一個空白的README文件和模型權重本身——上線即可直接可以下載使用。
新版V3代碼能力飆升,追平Claude 3.7
遺憾的是,DeepSeek尚未公佈新版模型的系統卡,暫時無法窺探更多技術細節。
 官方小助手的更新提示
官方小助手的更新提示不過,這並未阻擋全網對新模型的熱情,已有機構、網民紛紛對V3展開通用能力、代碼、數學等多維度的測評。
根據網民Xeophon的自測,DeepSeek-V3-0324所有指標性能暴漲,擊敗了Claude 3.5 Sonnet,成為目前最強的非推理模型。

就代碼能力來看,DeepSeek-V3-0324同樣能夠與Claude 3.5 Sonnet一決高下。
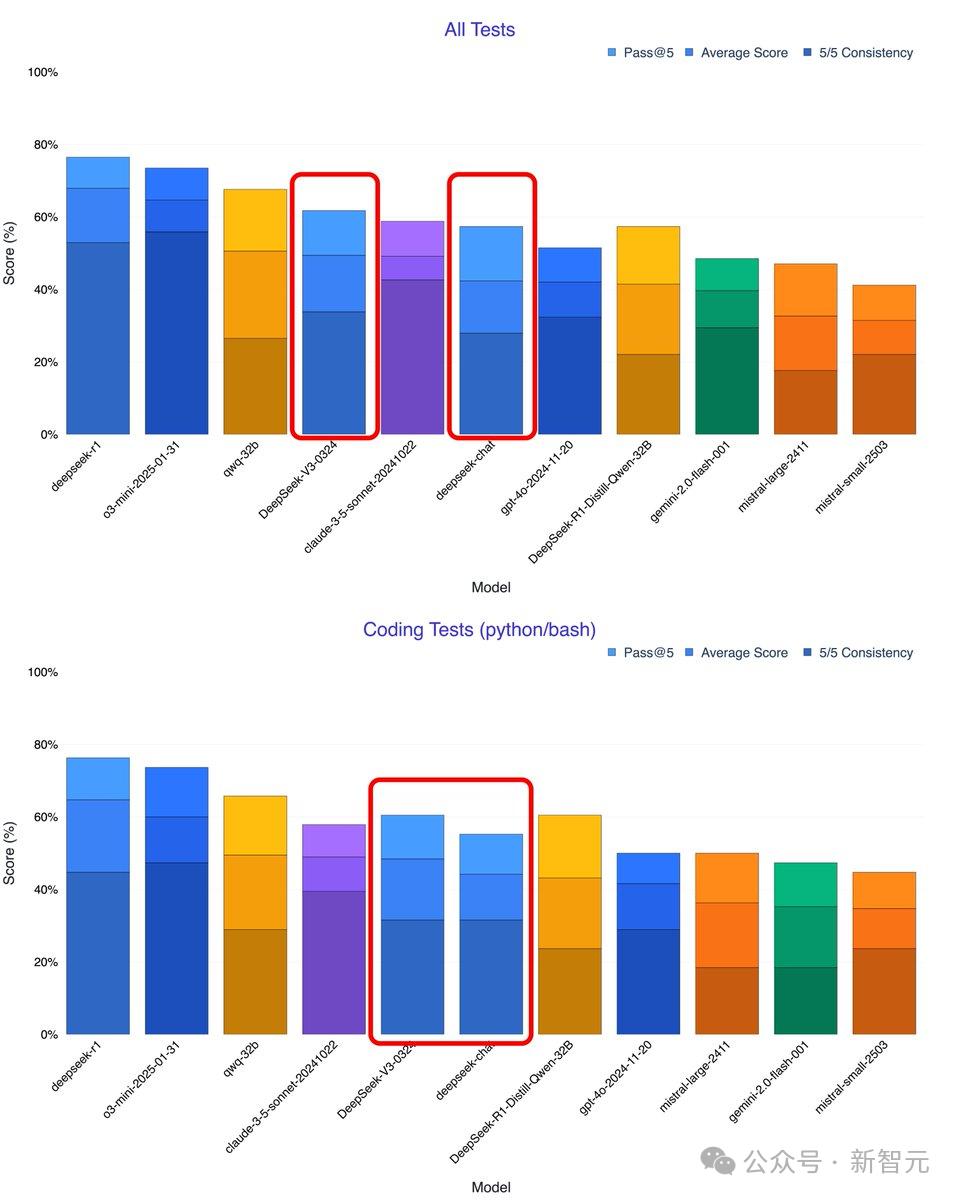
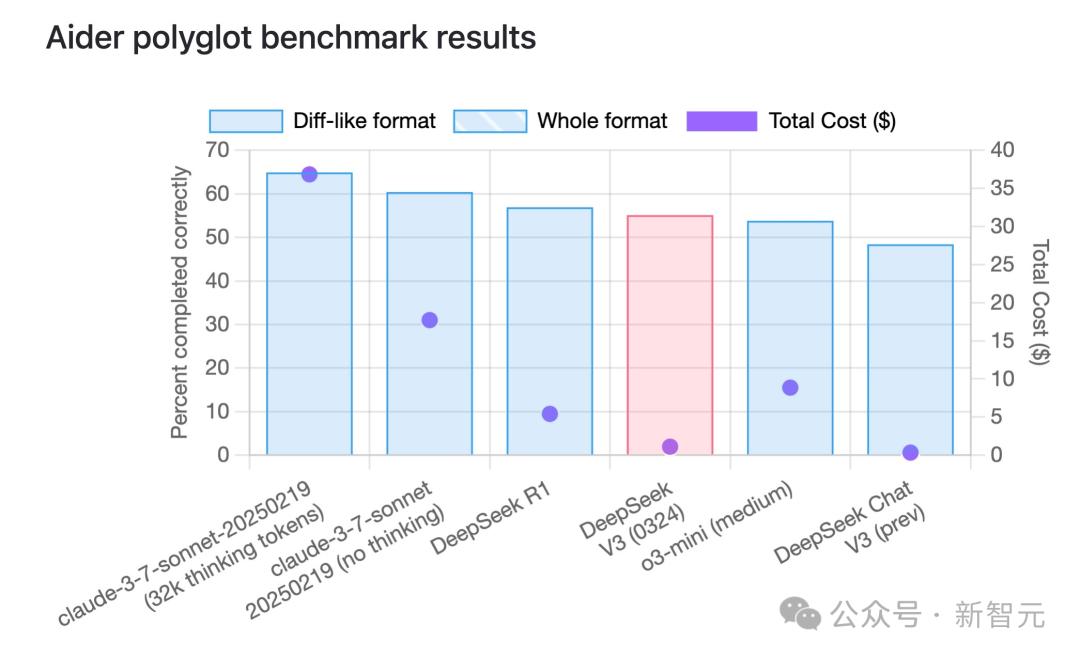
另外,在Aider的多語言基準測試中,DeepSeek-V3-0324拿下55%成績,較前代版本顯著提升,成為僅次於Sonnet 3.7的非推理類模型第二名。
其表現已可媲美R1和o3-mini等具備推理能力的模型。
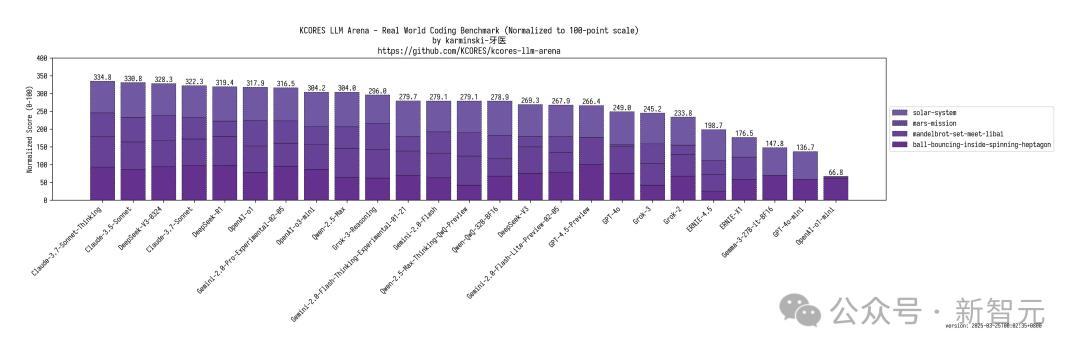
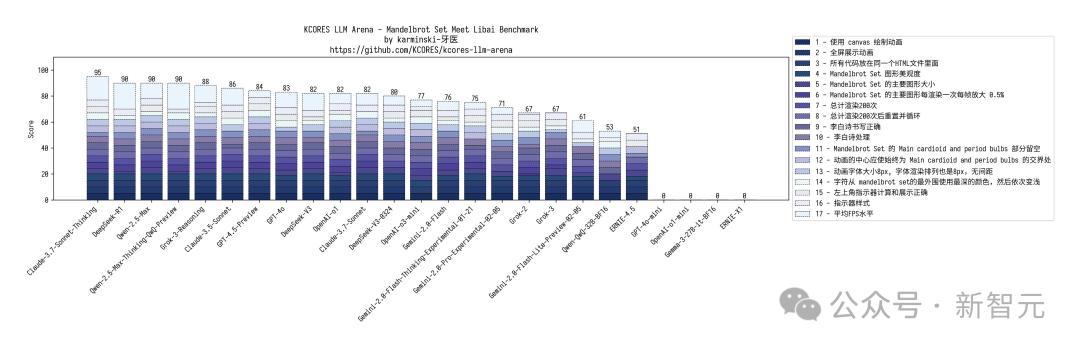
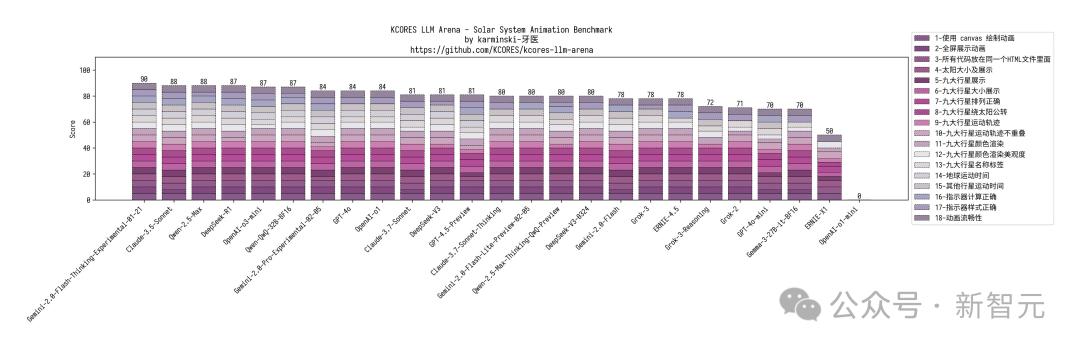
網民「karminski-牙醫」還帶來了全網最速的代碼實測,新模型直接干翻了DeepSeek R1,與Claude 3.7相匹敵。

在 KCORES大模型競技場中,Claude-3.7-Sonnet-Thinking無疑是LLM當之無愧的王者,DeepSeek-V3-0324以328.3分拿下第三名,僅次於Claude 3.5 Sonnet。
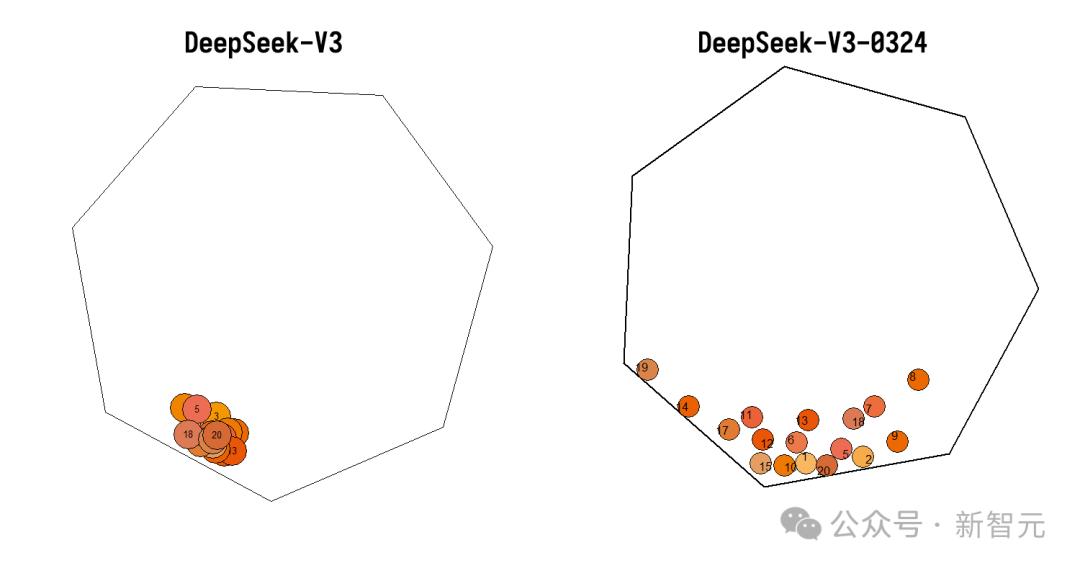
他還展開了四項評測,20個小球碰撞測試,上個版本結果擠成一團,DeepSeek-V3-0324在物理模擬上表現更好。
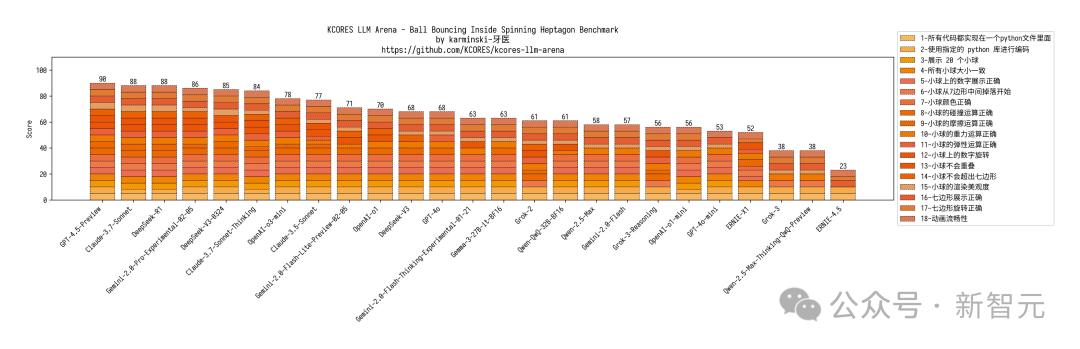
在mandelbrot-set-meet-libai測試中,DeepSeek-V3-0324沒有過多變化,較初版僅僅低了2分,完成度提升很高。
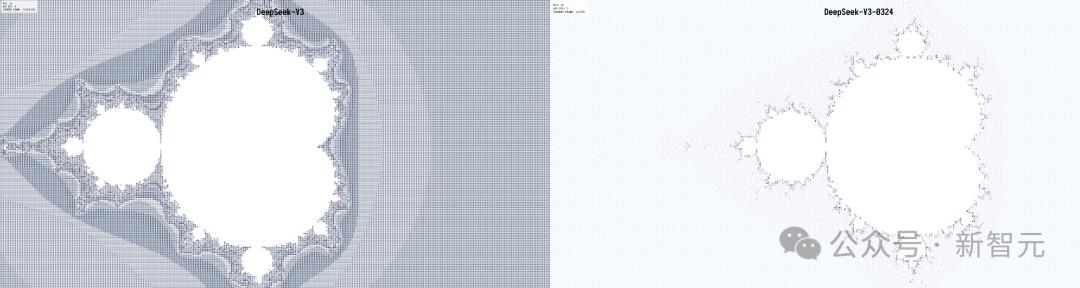
還有火星任務測試中,DeepSeek-V3-0324星球渲染正確,所有模型中位列第三。
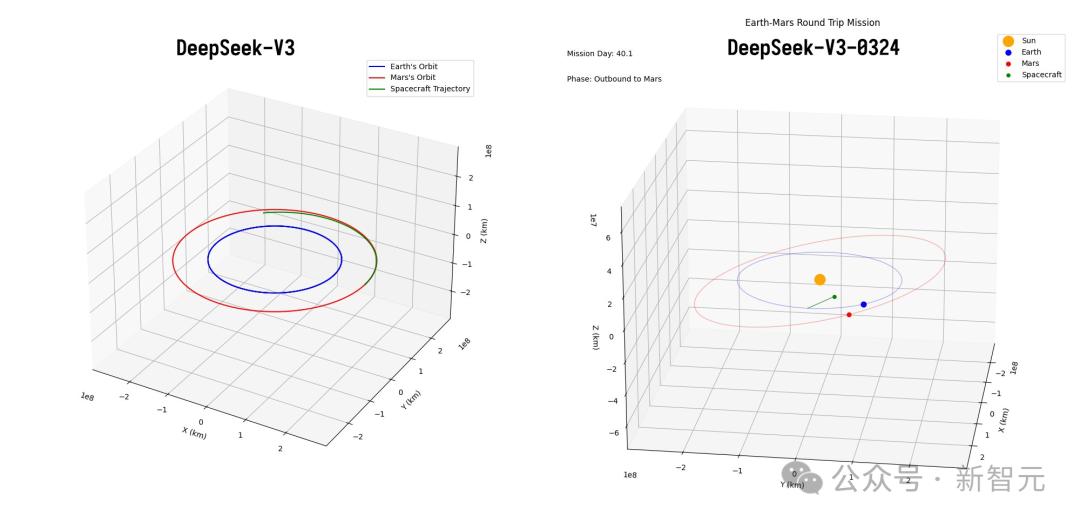
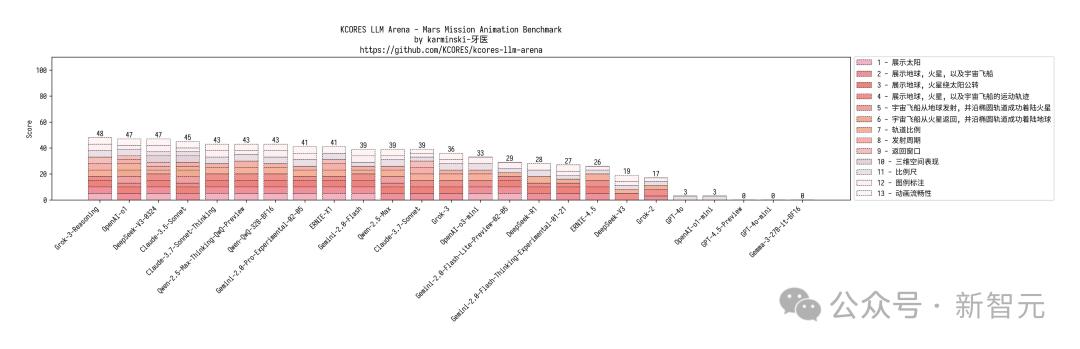
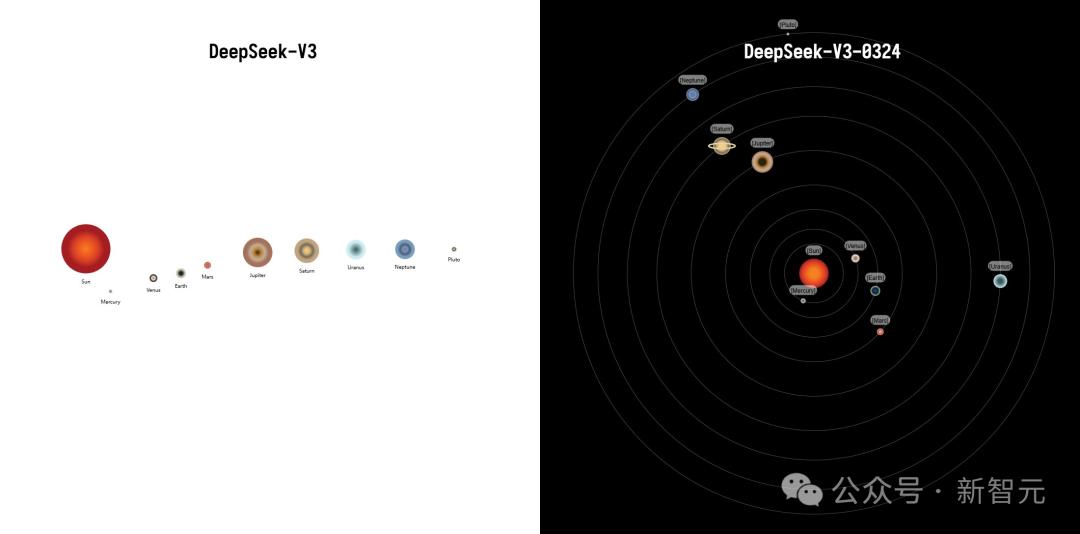
九大行星測試,DeepSeek-V3-0324真正繪製出了太陽系的完整圖。
此外,DeepSeek-V3-0324在Misguided Attention基準上,躍居非推理類模型榜首,甚至超越了Claude Sonnet 3.7(非推理模型)。
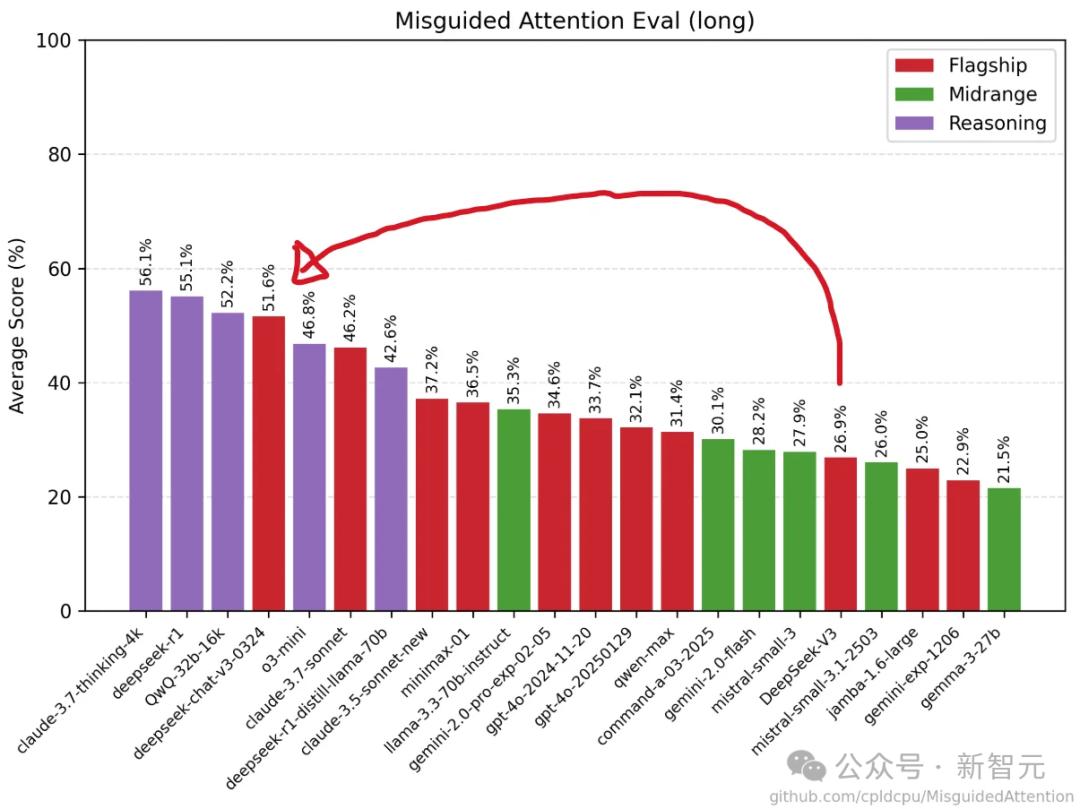
令人驚訝的是,它現在能解決一些此前只有推理模型才能處理的提示,比如「4升水壺問題」。
V3-0324似乎學會了識別推理循環,並跳出循環——這種能力甚至是許多專業推理模型都不具備的。
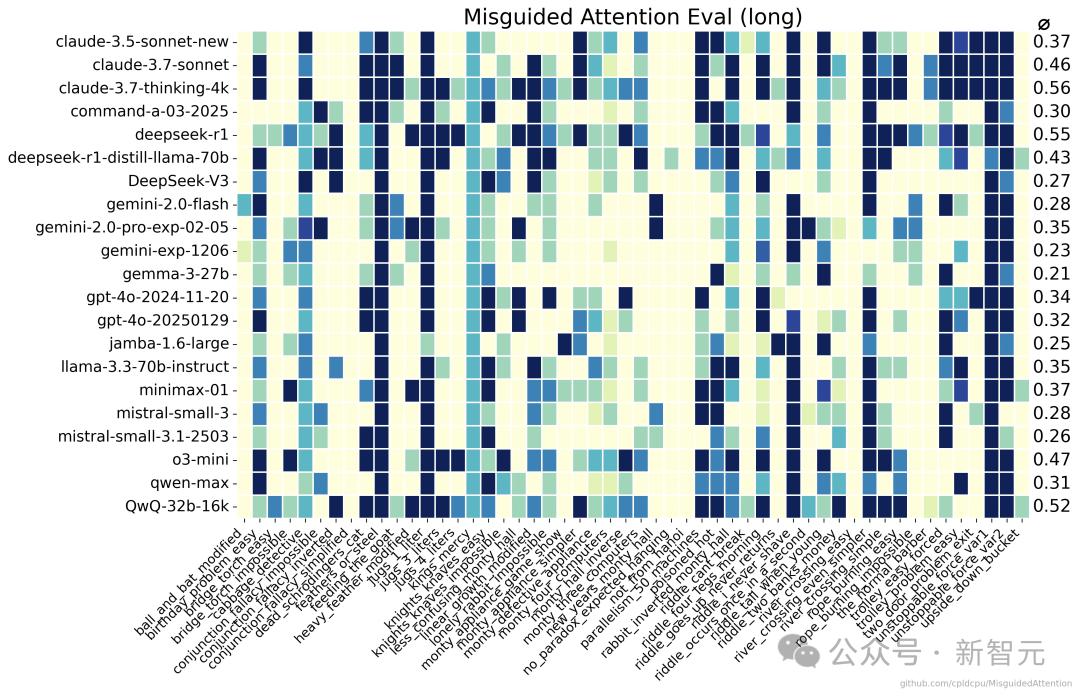 顏色越深代表特定提示的正確響應次數越多
顏色越深代表特定提示的正確響應次數越多接下來,看看DeepSeek-V3-0324在多項實測中的具體表現如何。
網民實測,一個提示即出網頁
網民「Deepanshu Sharma」表示,更新後的DeepSeek-V3-0324簡直「強的過分了」。
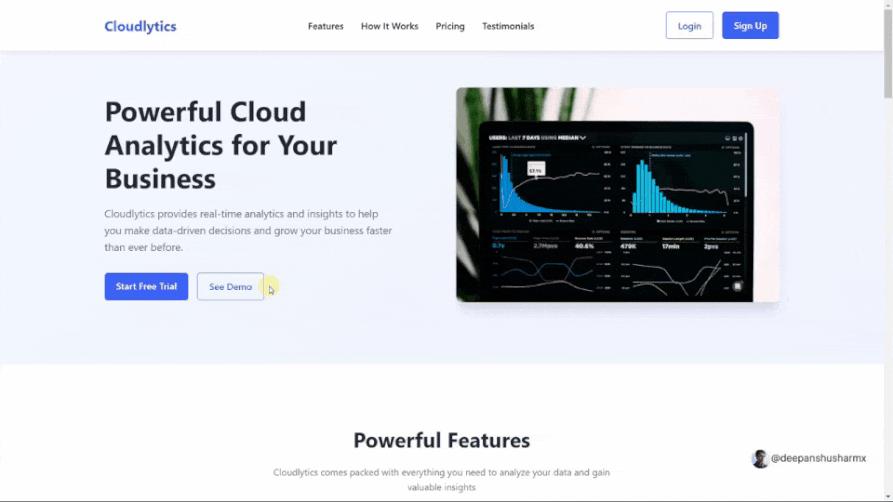
他用這個新模型一氣嗬成創建了一個新網站,編寫了800多行代碼,一次都沒有出錯!
「看到這些厲害的開源模型不斷給大公司施加壓力,迫使他們以低成本構建更好的模型,真是太棒了!」Deepanshu寫道。
網民「Risphere」體驗完新的DeepSeek-V3-0324後表示,其在編碼方面已經與Claude 3.7 Sonnet處於同一水平上了。
要知道,Claude模型一直以來都是公認的代碼能力最強的模型。


不僅如此,Risphere甚至認為DeepSeek-V3-0324在前端開發方面超越了o1-pro和GPT-4.5!
要知道,o1-pro可是需要付費200美元每月的ChatGPT Pro會員才可以體驗的模型。
Petri Kuittinen體驗完DeepSeek-V3-0324後認為,「Anthropic和OpenAI遇上麻煩了!」。
他使用了一段非常簡短的提示詞就製作出了一個精美的響應式網頁,提示詞如下:
Create a great-looking responsive front page for AI company. Include everything in one HTML5 file.
為AI公司創建一個看起來很棒的響應式首頁。將所有內容包含在一個HTML5文件中。
Petri認為,DeepSeek-V3-0324是在前端編程上也優於DeepSeek-R1。
他完成的這個網站共有958行代碼,包括所有圖像,而且也適合手機上觀看。

不只是編程問題,數學競賽也難不倒它。
數學博士、奧賽金牌得主Jasper用AIME 2025中的題目測試了一下DeepSeek-V3-0324,它順利解決了。
Jasper表示,他現在對開源AI模型最終獲勝更有信心了!
編碼智能體Cline的速度很快,第一時間更新了DeepSeek-V3-0324。
他們還給出了使用的理由,DeepSeek-V3-0324在編碼任務上性能與Claude 3.7 Sonnet不相上下,價格卻低了53倍。

不止如此,Cline還表示,DeepSeek-V3-0324較之前的版本增加了60%的專家(從160增加到256),使用了FP8精度訓練將計算效率翻倍,不僅使前端編碼能力增強,數學與邏輯能力也有所提升。
DeepSeek註定改變全球AI格局
這次DeepSeek-V3的突然上線,節奏也與過去他們在聖誕節期間發佈V3、幾週後推出R1的模式完全吻合。
本來,業界就一直傳聞R2將在4月亮相,V3的上線基本吹響了R2的前奏。
先進開源推理模型的影響,已經不必多說了。如果它們能免費提供,那原本只有財力雄厚的大型機構才能獲得的高級AI系統,會變得人人可用。
而如果DeepSeek-R2能延續R1的發展路線,但它很可能會直接單挑OpenAI捂著的大炸彈GPT-5。這就讓OpenAI靠封閉生態和雄厚資金支持帶來的壟斷,被徹底打破。
當OpenAI和Anthropic還在為模型設置付費訪問限制時,DeepSeek已經實現了封閉模型無法達到的爆髮式創新。
而中美AI差異,已經日漸縮小,全球AI格局已被重塑。幾個月前,大部分分析師估計,中國在AI能力上落後美國1-2年,今天這一差距已經縮小至3-6個月,甚至呈現中國領先的趨勢。
而開源的方式,甚至還解決了中國公司的特殊挑戰(受限於英偉達先進芯片),因為更注重在算力有限的情況下達到有競爭力的性能,現在這已成為中國企業的潛在優勢。
就像Android系統一樣,憑著廣泛的普及性和數千開發者的集體創新,DeepSeek很可能最終超越封閉系統。
誰將通過AI擁有對世界最大的影響力?讓我們拭目以待。
參考資料:
https://x.com/TheXeophon/status/1904225899957936314
https://x.com/cline/status/1904275590678786545
https://x.com/karminski3/status/1904212084306653648
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。