AMD跑DeepSeek性能超H200!128併發Token間延遲不超50ms,吞吐量達H200五倍
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
DeepSeek-R1掀起新一輪購卡潮的同時,AMD的重要性也上升了。
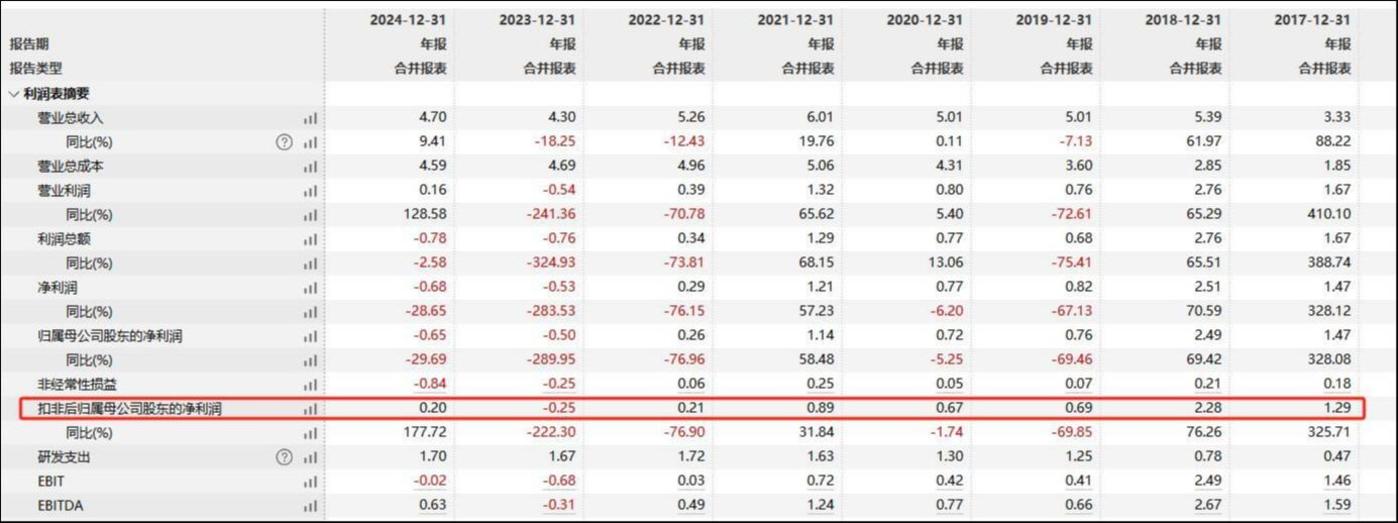
在AMD的MI300X上跑FP8滿血R1,性能全面超越了英偉達H200——
相同延遲下吞吐量最高可達H200的5倍,相同併發下則比H200高出75%。

這個結果,一方面歸功於SGLang框架,另一方面則是得益於AMD新優化的AI內核庫AITER。
AITER可以用來加速GPU訓練和推理,AMD副總裁Emad Barsoum直接喊出了AITER is all you need。

還有網民表示,英偉達CUDA的護城河要終結了。

之前著名黑客George Hotz也曾表示自己非常看好AMD,認為只要有好的軟件MI300X表現就能超越H100。
結果MI300X超額實現了George的期待,直接把H200給超了。

吞吐翻倍、延遲更低
AMD的測試結果顯示,MI300X在延遲相似的情況下實現了H200五倍的吞吐量,超過了每秒7k Tokens。
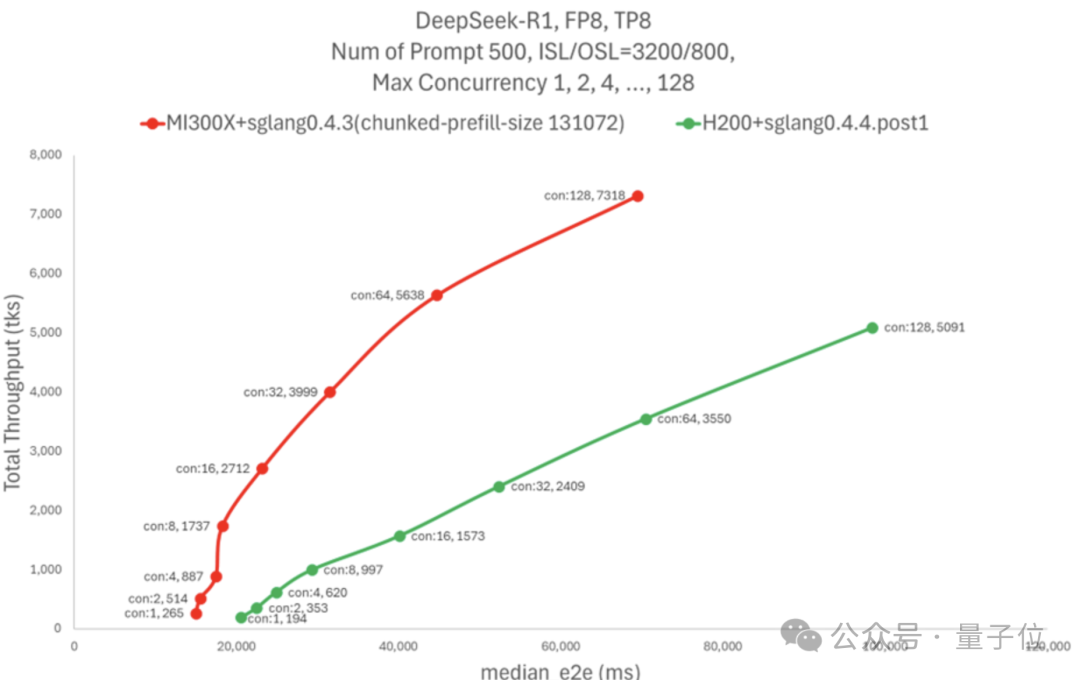
如果固定併發數量,MI300X相同併發下的吞吐量比H200高75%,延遲降低 60%。
如果需要Token間延遲不超過50毫秒,一個H200節點可以處理16個併發請求,MI300X節點則可以處理128個。
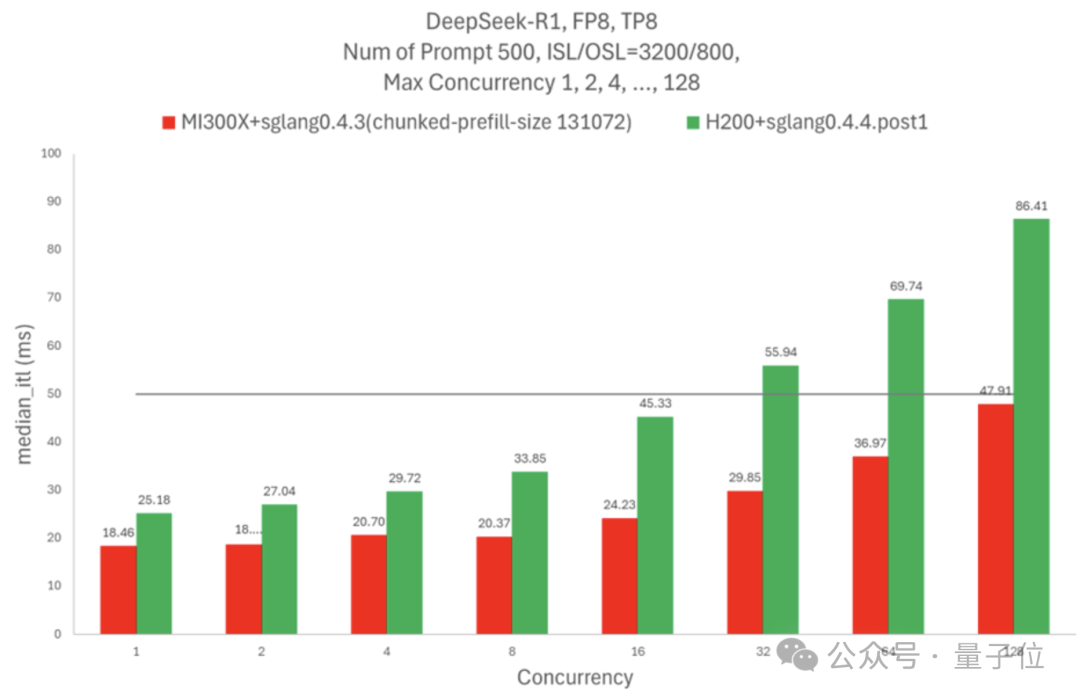
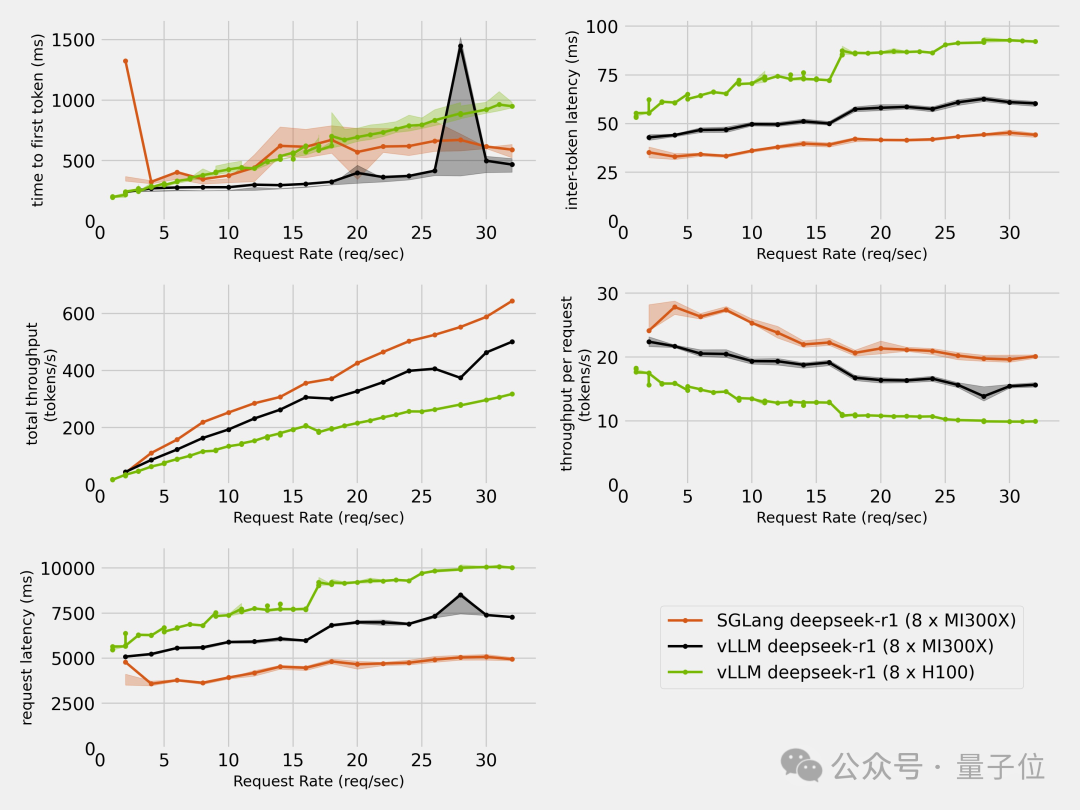
除了AMD自己,也有第三方對H100和MI300X進行了對比測試。
結果除了首個Token延遲出現了一些不穩定之外,其餘的速度和延遲指標都是MI300X全面超過了H100。
看到MI300X的表現,有人拿出了老黃經典的那句「買的越多省的越多」,表示現在這句話該讓AMD來說了。
那麼,在這些成績的背後,AMD都用了那些技術呢?
SGLang框架+AMD張量引擎
軟件框架層面,R1在MI300X上取得優異表現的關鍵,是SGLang框架。
SGLang是一個開源大模型推理框架,是開源社區協作的一項成果,發起者是LMSYS,也就是搞大模型競技場的那個組織。
SGLang在GitHub上擁有超過1.2萬星標,並且不論AMD還是隔壁英偉達,以及馬斯克的xAI,都非常青睞這個框架,此外AMD還是SGLang的主要貢獻者之一。
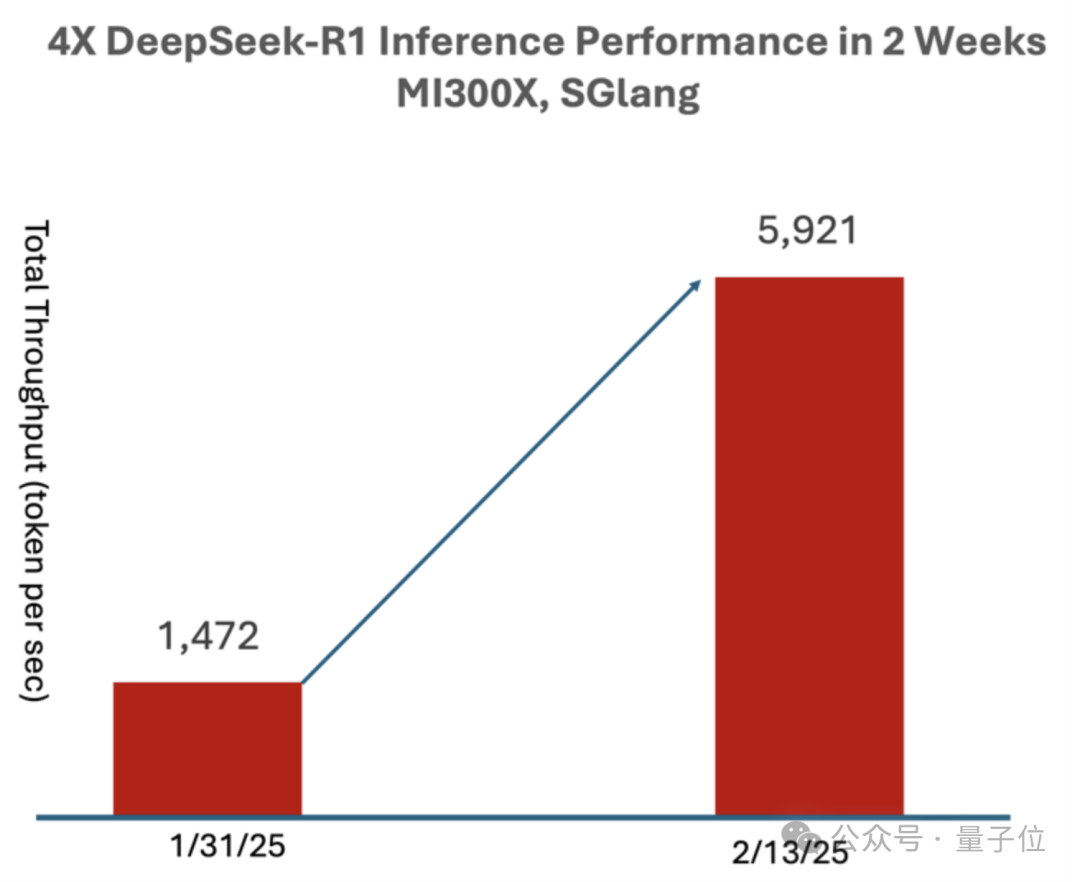
在稍早一些的測試當中,使用SGLang在MI300X上運行DeepSeek-R1,僅過了兩週就相比於day 0時性能提升到了4倍,吞吐量達到了每秒5921 Tokens。
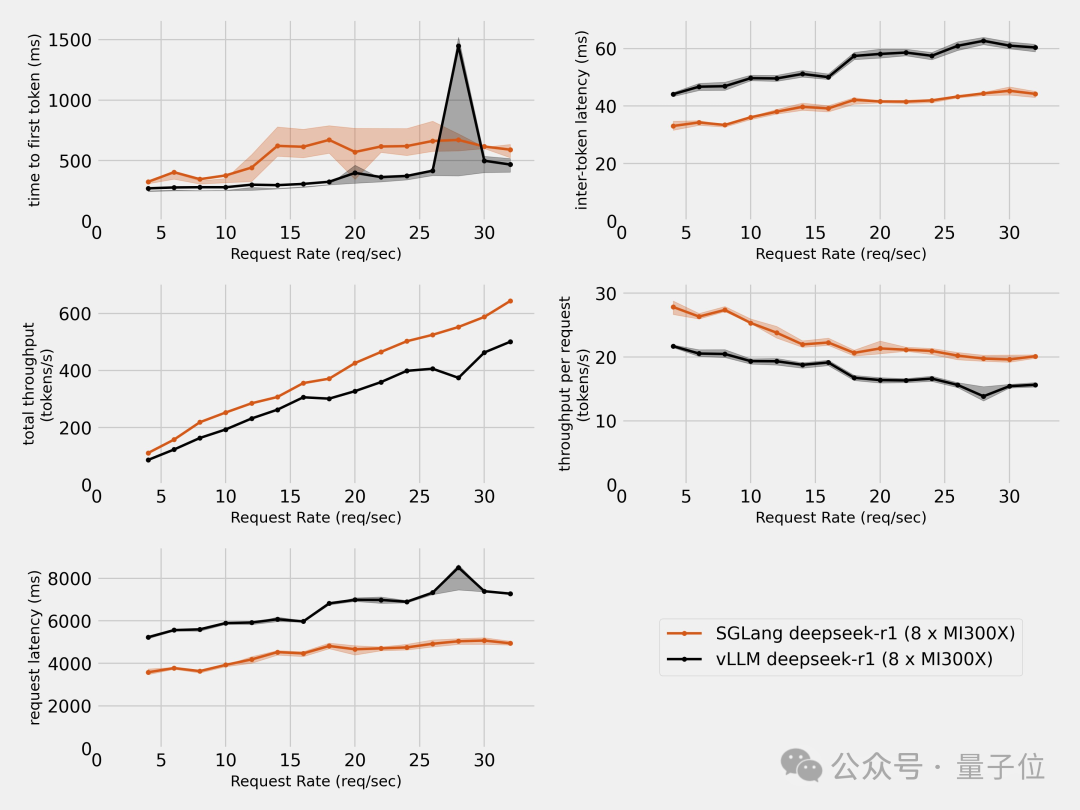
前面提到的第三方,也在MI300X上分別用SGLang和vLLM進行了測試,結果SGLang完勝。
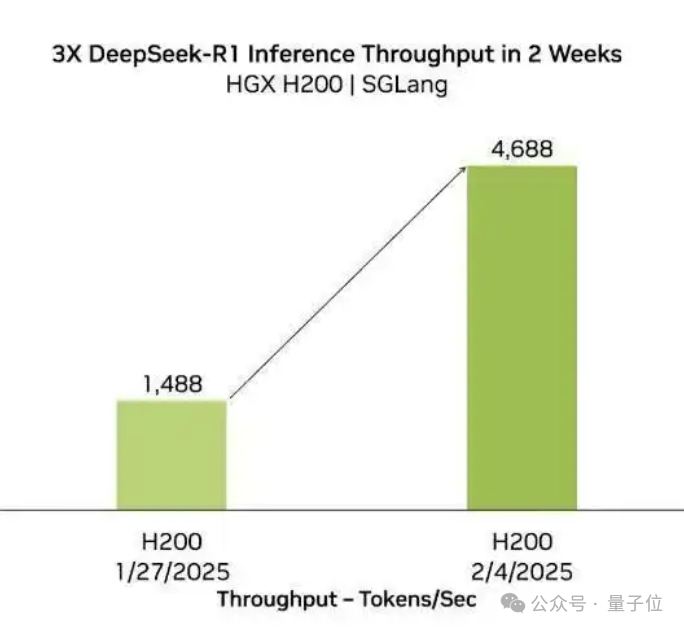
實際上,SGLang一直是DeepSeek模型的一個最佳拍檔,不僅對於AMD,在英偉達H200上,也能帶來類似的性能提升。
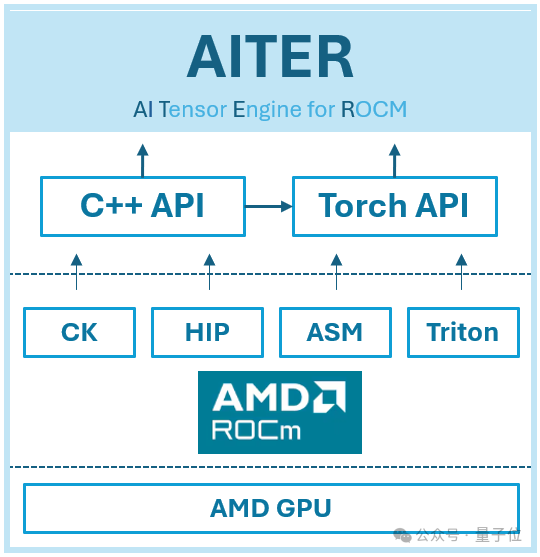
而在硬件層面,MI300X高效運行R1的關鍵,是AMD為ROCm(可以理解為AMD版CUDA)打造的AI張量引擎AITER。
AITER是一個包含大量高性能AI算子的集中式存儲庫,也是一個統一平台,可以輕鬆找到優化的算子並將其集成到現有框架中。
AITER的基礎架構建立在多種底層技術之上,包括 Triton、CK(計算內核)、ASM(彙編)和 HIP(異構可移植性接口)。
它支持各種計算任務,例如推理工作負載、訓練內核、GEMM(通用矩陣乘法)運算和通信內核。
它可以讓GEMM的性能提升2倍、MoE性能提升3倍、MLA解碼性能提升17倍、MHA預填充性能提升14倍。
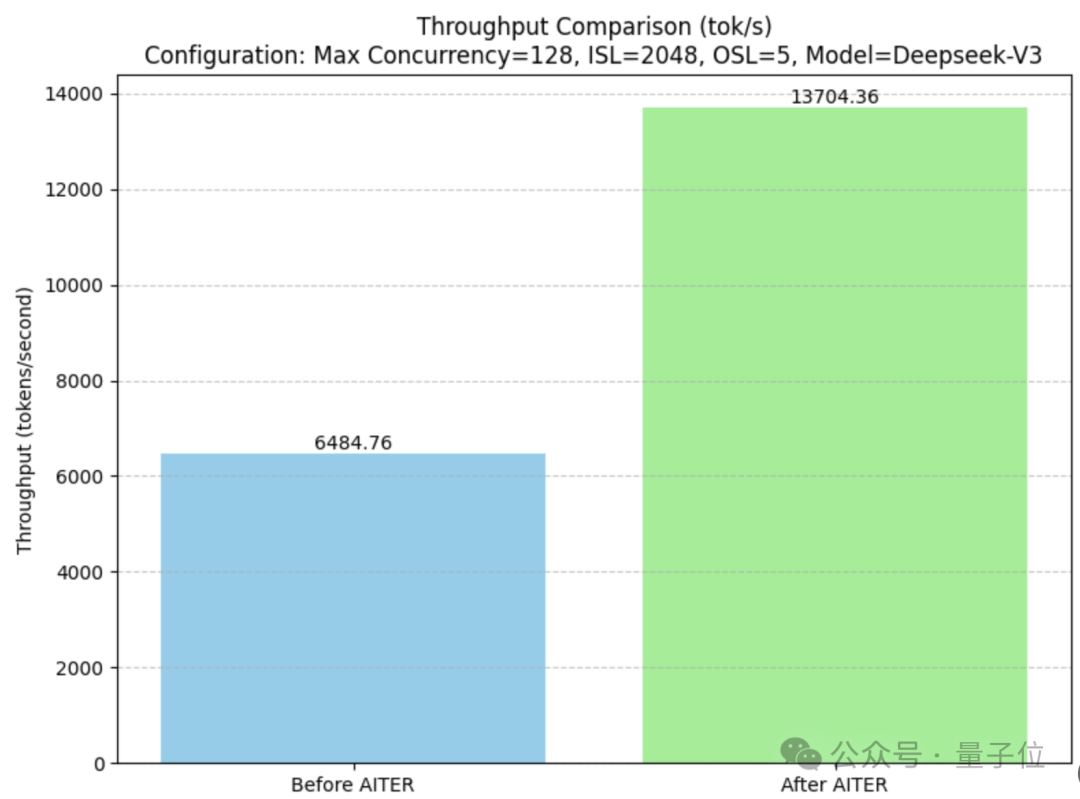
開啟AITER後,MI300X上DeepSeek-V3的吞吐量是開啟前的兩倍多。
除了框架和硬件的適配,AMD還進行了超參數調整。
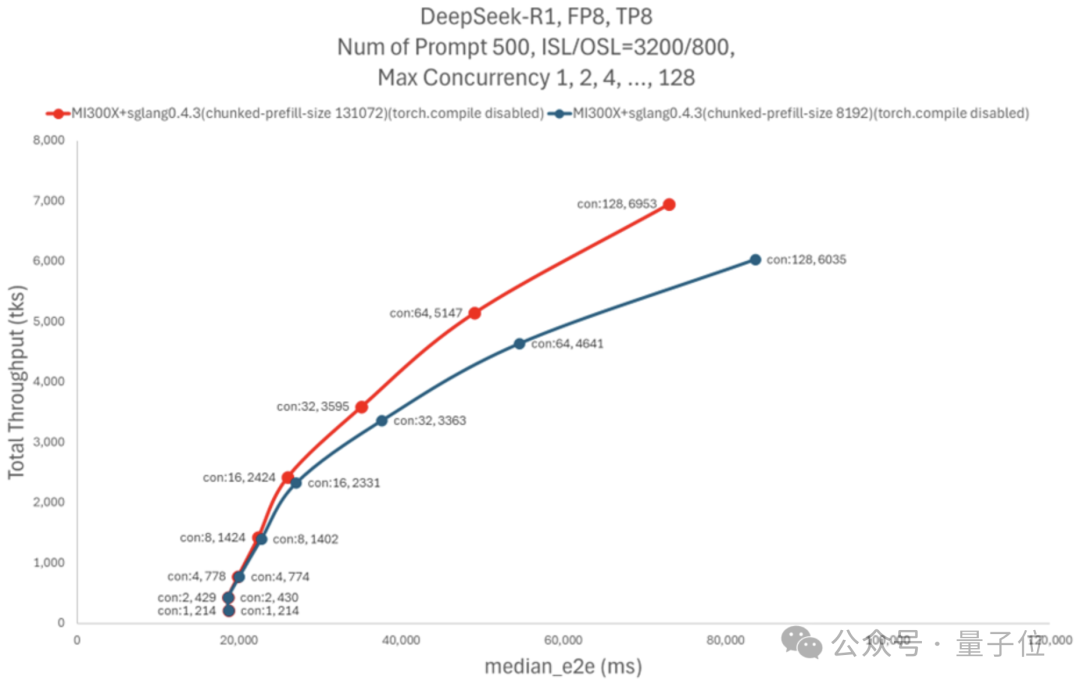
AMD發現,當運行具有大量線程(例如128個或更多)的程序時, 由於預填充吞吐量緩慢,帶來了系統的性能瓶頸。
於是AMD提高了chunked_prefill_size參數的大小,用更高的內存佔用換取了預填充過程的加速。
不過考慮到內存容量大班就是MI300X的一大特色,這種選擇也不失為一種更優的結果。
那麼,你覺得這次AMD是不是又Yes了呢?
參考鏈接:
[1]https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1-Part2/README.html
[2]https://x.com/tngtech/status/1901779226602115076
[3]https://geohot.github.io//blog/jekyll/update/2025/03/08/AMD-YOLO.html