Uni-3DAR用自回歸統一微觀與宏觀的3D世界,性能超擴散模型256%,推理快21.8倍
機器之心發佈
機器之心編輯部
從微觀世界的分子與材料結構、到宏觀世界的幾何與空間智能,創建和理解 3D 結構是推進科學研究的重要基石。3D 結構不僅承載著豐富的物理與化學信息,也可為科學家提供解構複雜系統、進行模擬預測和跨學科創新的重要工具。如何準確且高效地構建 3D 模型、理解和生成 3D 世界正在成為 AGI、AI for Science、具身智能三大 AI 熱門領域共同關注的焦點。而隨著 AI 技術的發展,大型語言模型(LLM)與大型多模態模型(LMM)那強大的自回歸下一 token 預測能力也已經在開始被用於創建和理解 3D 結構。基於此,我們看到了 AI for Science 的新可能。
近日,一個開創性的此類大模型誕生了!
它名為 Uni-3DAR,來自深勢科技、北京科學智能研究院及北京大學,是一個通過自回歸下一 token 預測任務將 3D 結構的生成與理解統一起來的框架。據瞭解,Uni-3DAR 是世界首個此類科學大模型。並且其作者陣容非常強大,包括了深勢科技 AI 算法負責人柯國霖、中國科學院院士鄂維南、深勢科技創始人兼首席科學家和北京科學智能研究院院長張林峰等。
柯國霖在 𝕏 上分享表示:Uni-3DAR 的核心是一種通用的粗到細 token 化方法(coarse-to-fine tokenization),它能將 3D 結構轉化為一維的 token 序列。


-
論文標題:Uni-3DAR: Unified 3D Generation and Understanding via Autoregression on Compressed Spatial Tokens
-
論文地址:https://arxiv.org/abs/2503.16278
-
項目主頁:https://uni-3dar.github.io
-
代碼倉庫:https://github.com/dptech-corp/Uni-3DAR
基於這套通用的 token 化方法,Uni-3DAR 使用自回歸的方式,統一了 3D 結構的生成和理解任務。大量實驗表明,Uni-3DAR 在分子生成、晶體結構生成與預測、蛋白結合位點預測、分子對接和分子預訓練等多個任務中均取得了領先性能。尤其在生成任務中,相較於現有的擴散模型,其性能實現了高達 256% 的相對提升,推理速度提升達 21.8 倍,充分驗證了該框架的有效性與高效性。此外,此模型不僅可以用在微觀的 3D 分子,也可以用到宏觀的 3D 任務上,具備跨尺度的能力。
具體來說,Uni-3DAR 解決了 3D 結構建模里的兩個痛點:
第一,數據表示不統一。當前的 3D 結構存在多種表示方式,尤其在不同尺度下差異顯著。宏觀結構常用點雲、網格(Mesh)等表示方式,而微觀結構則多採用原子坐標或圖結構。這些表示方式的差異導致建模思路截然不同。即使在同一尺度,由於數據特性的差異,不同類型的結構(如晶體、蛋白質、分子)也往往採用各自專用的表示與模型,難以兼容。這種表示上的割裂嚴重限制了模型的通用性,也阻礙了構建可借助大規模數據訓練的通用基礎模型的可能性。
第二,建模任務不統一。 3D 結構相關任務可分為生成和理解兩大類,但它們各自獨立發展。生成任務多依賴擴散模型,從隨機噪聲逐步合成穩定結構,而理解任務則主要基於無監督預訓練方法。相比之下,大型語言模型(LLM)已通過自回歸方式成功實現了生成與理解任務的統一,但這種統一範式在 3D 結構建模領域仍然鮮有嘗試。若能借助自回歸方法統一 3D 任務建模,不僅有望打通理解與生成的界限,更可能將 3D 結構納入多模態大語言模型的處理範式,繼圖像和影片之後成為 LLM 可理解的新模態,為構建面向物理世界的通用多模態科學模型奠定基礎。
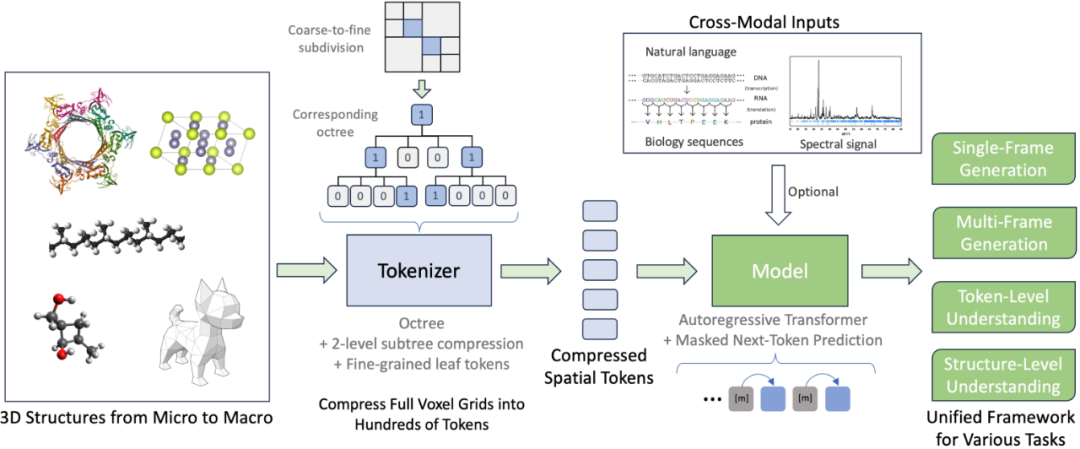 Uni-3DAR 整體架構
Uni-3DAR 整體架構下面我們具體解讀下這篇論文的兩個核心技術。
Compressed Spatial Tokens統一微觀與宏觀 3D 結構
3D 結構在微觀(如原子、分子、蛋白質)和宏觀(如物體整體、力學結構)層面均表現出顯著稀疏性:大部分空間為空白,只有局部區域含有重要信息。傳統的全體素網格表示計算資源消耗巨大,無法利用這種稀疏性。
為此,Uni-3DAR 提出了一種層次化、由粗到細的 token 化方法,實現了數據的高效壓縮和統一表示,既適用於微觀也適用於宏觀 3D 結構建模,為後續的自回歸生成與理解任務提供了堅實基礎。
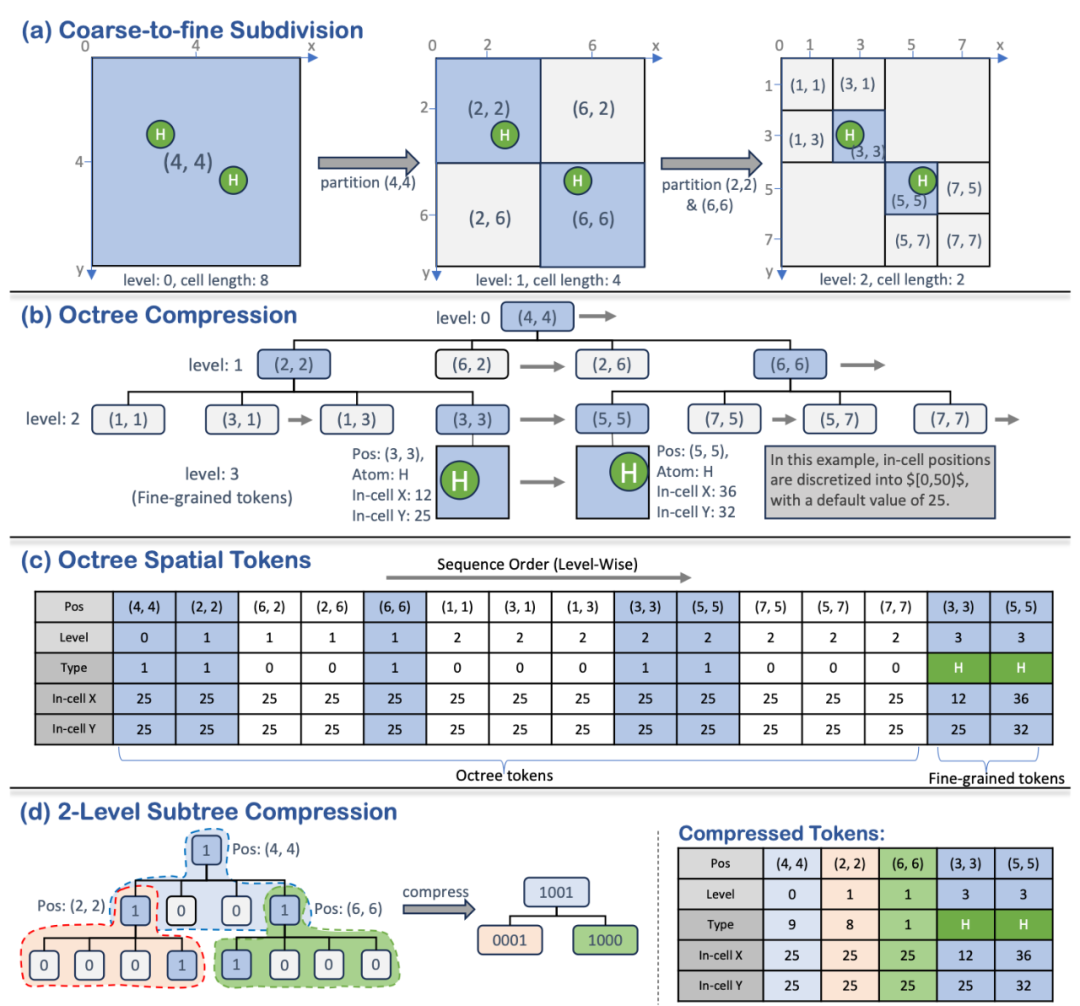
1. 層次化八叉樹壓縮
該方法首先利用八叉樹對整個 3D 空間進行無損壓縮。具體做法是從包含整個結構的一個大格子開始,針對非空格子(即包含原子或其他結構信息的區域),遞歸地將其均分為 8 個等大小的子單元。經過多層細分後,形成一個由粗到細的層次結構,其每一層的 token 不僅記錄了區域是否為空,還保留了該區域的空間位置信息(由所在層次及格子中心坐標確定),為後續的自回歸生成提供了明確的空間先驗。
2. 精細結構 token 化
雖然八叉樹可以有效壓縮空白區域,但它僅提供了粗粒度的空間劃分,無法捕捉到諸如原子類型、精確坐標(在微觀結構中)或物體表面細節(在宏觀結構中)等重要信息。
為此,該團隊在最後層非空區域內進一步引入了「3D patch」的概念 —— 類似於圖像領域中的 2D patch 的處理。通過將局部結構細節進行離散化(例如採用向量量化技術),將連續的空間信息轉化為離散的 token。
這樣一來,無論是描述微觀尺度下單個原子的信息,還是刻畫宏觀尺度下物體表面的細節,都能以同一形式進行表示。
3. 二級子樹壓縮
由於即使在八叉樹結構下,token 數量仍可能較多,該方法進一步提出了二級子樹壓縮策略。具體來說,將一個父節點及其 8 個子節點的信息合併為一個單一的 token(利用父節點固定狀態以及子節點的二值特徵,共可組合成 256 種狀態),從而將 token 總數約降低 8 倍。這不僅大幅提高了計算效率,也為大規模 3D 結構的高效建模提供了可能。
綜上,該方法充分利用了 3D 結構固有的稀疏性,通過八叉樹分解、精細 token 化與二級子樹壓縮,不僅大幅降低了數據表示的複雜度,而且實現了從微觀到宏觀 3D 結構的統一表示,為後續自回歸生成與理解任務提供了高效、通用的數據基礎。
Masked Next-Token Preiction統一生成和理解的自回歸框架
在傳統自回歸模型中,token 的位置是固定的 —— 例如在文本生成中,第 i 個 token 後總是緊接著第 i+1 個 token,因此下一個 token 的位置可以直接推斷,無需顯式建模。
然而,在該論文提出的粗到細 3Dtoken 化方法中,token 是動態展開的,其位置在不同樣本間存在較大變化;如果不顯式提供位置信息,自回歸預測的難度將大大增加。為此,該論文提出了 Masked Next-Token Prediction 策略。
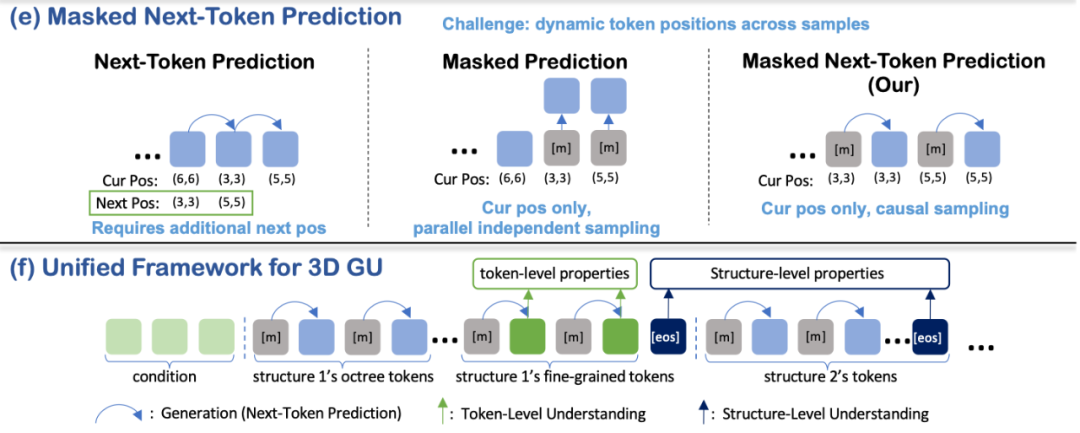
具體而言,該方法對每個 token 複製一份,確保兩個副本具有相同的位置信息,然後將其中一個副本替換為 [MASK] token。在自回歸預測過程中,由於被掩碼 token 與目標 token 的位置信息完全一致,模型能夠直接利用這一明確的位置信息來預測下一個 token 的內容,從而更精確地捕捉下一個 token 的位置特徵,提高預測效果。儘管複製 token 使序列長度翻倍,但實驗結果表明,該策略顯著提升了性能,而推理速度僅下降 15% 至 30%。
基於 Masked Next-Token Prediction,該論文構建了一個統一的自回歸框架,使得 3D 結構的生成與理解任務能夠在單一模型內同時進行。
具體來說,生成任務(包括單幀與多幀生成)在被掩碼的 token 上執行,利用自回歸機制逐步構建結構;token 級理解任務(如原子級屬性預測)則依託精細結構 token 進行;而結構級理解任務則引入了一個特殊的 [EoS](End of Structure) token,用於捕捉整體結構的全局信息。
此設計使不同任務對應的 token 在模型內部彼此獨立、互不幹擾,從而支持聯合訓練。同時,自回歸特性也便於將其他模態數據(例如自然語言文本、蛋白質序列、儀器信號等)統一到單個模型,進一步提升模型的泛化能力和實用性。
實驗結果
該論文在微觀 3D 結構領域設計了一系列任務,包括分子生成、晶體結構生成與預測、蛋白結合位點預測、蛋白小分子對接以及基於預訓練的分子性質預測。
實驗結果顯示,在生成任務中,Uni-3DAR 的性能大幅超過了擴散模型方法;而在無監督預訓練的理解任務上,其表現與基於雙向注意力的模型基本持平。這些成果充分證明,Uni-3DAR 不僅能統一不同類型的 3D 結構數據及任務,而且在效果和速度上均實現了顯著提升。
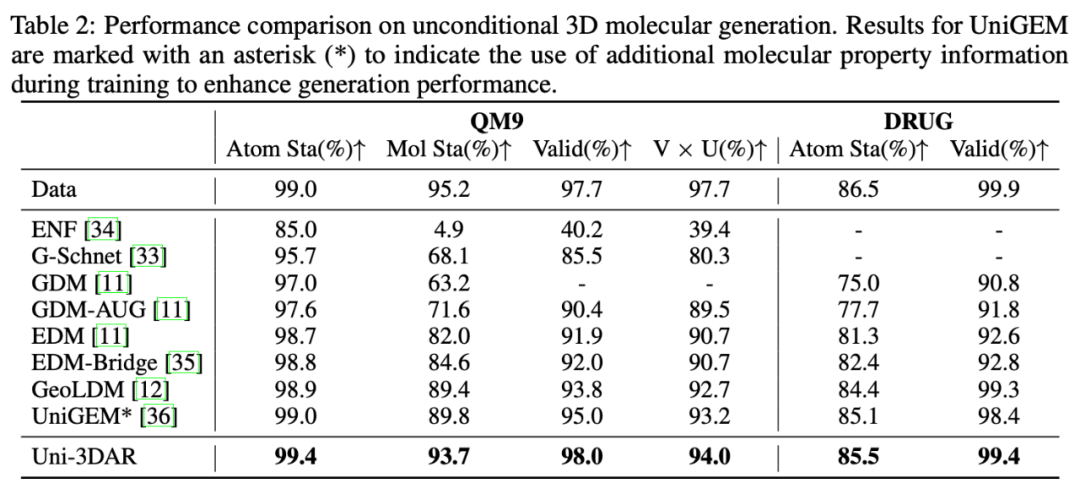
3D 小分子生成任務性能
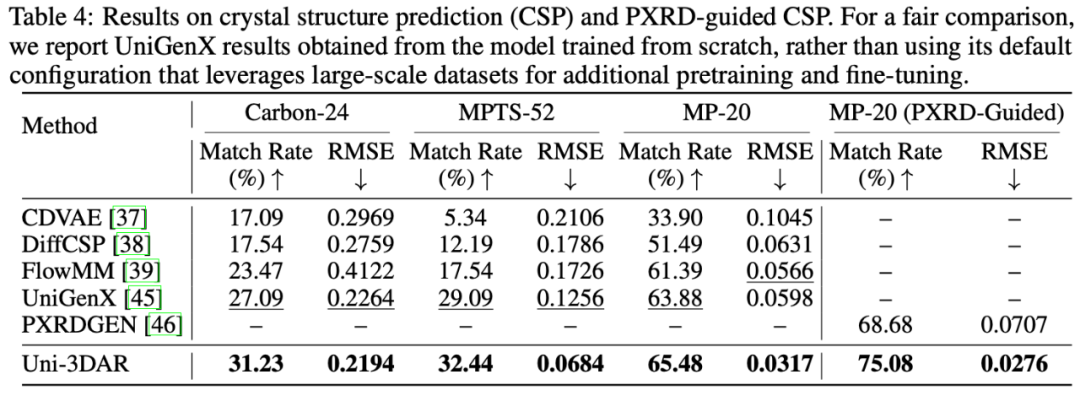
晶體結構預測,以及基於多模態信息(粉末 X 射線衍射譜)的晶體結構解析性能
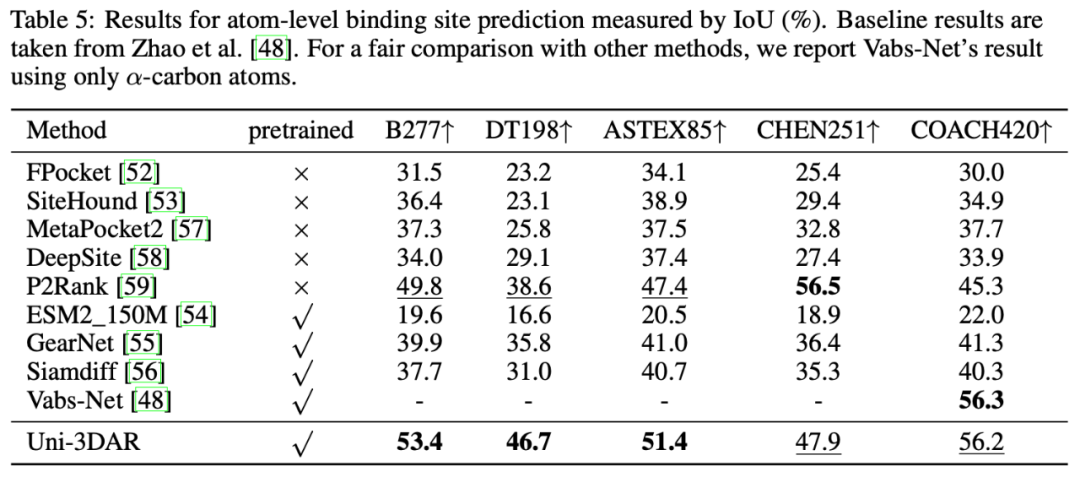
蛋白結合位點預測效果
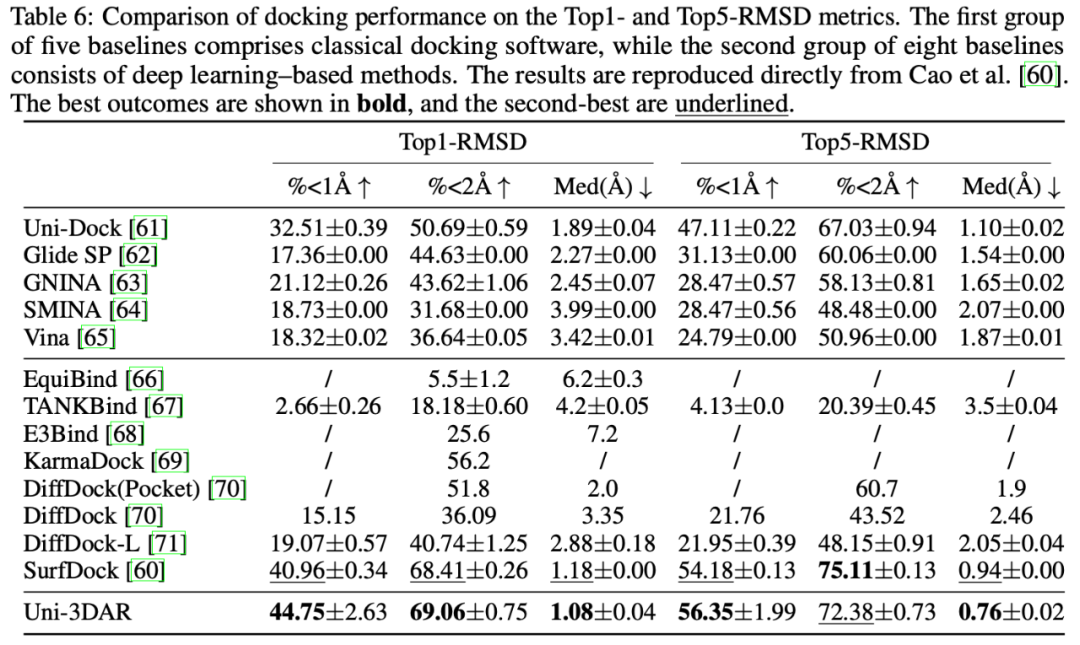
蛋白小分子對接效果
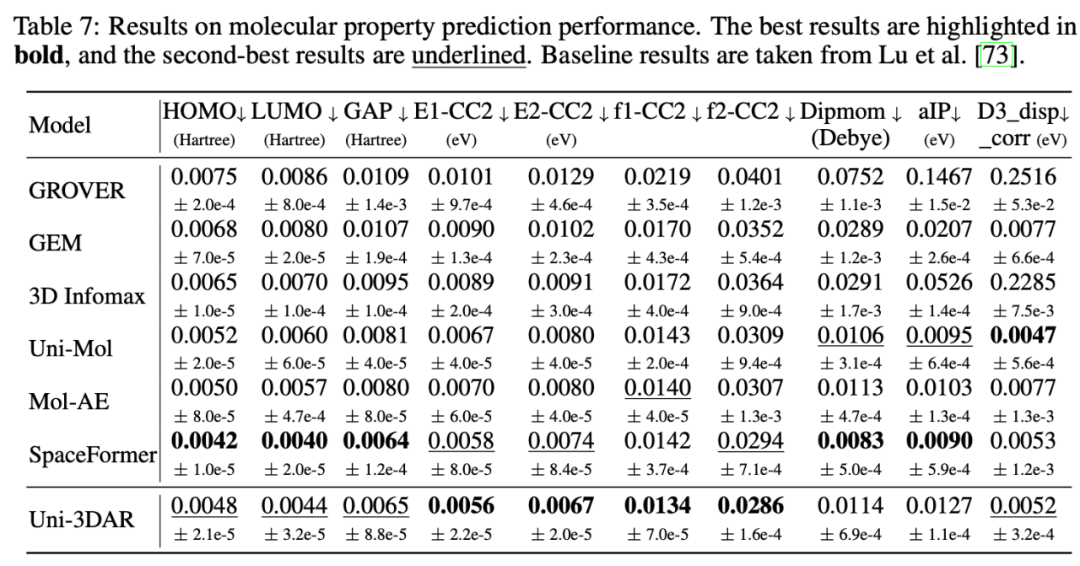
基於預訓練的小分子屬性預測效果,其中 Uni-Mol 和 SpaceFormer 也為深勢科技提出的專用模型,Uni-3DAR 超過了 Uni-Mol,與 SpaceFormer 基本持平
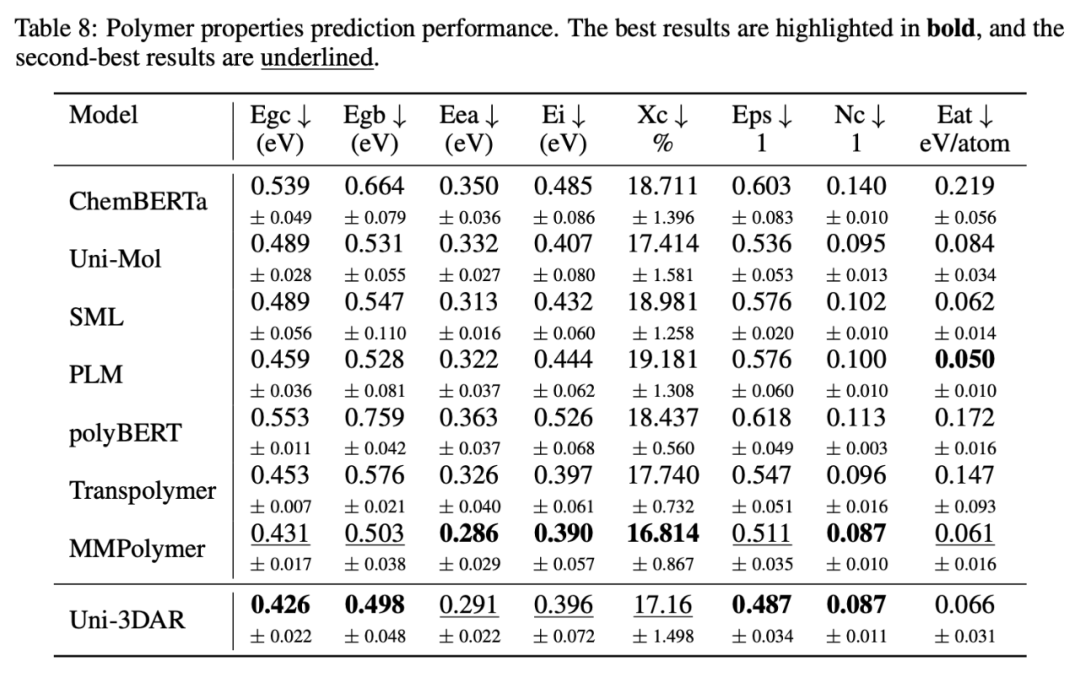
基於預訓練的高分子聚合物性質預測,其中 Uni-Mol 和 MMPolymer 也為深勢科技提出的專用模型,Uni-3DAR 超過了 Uni-Mol,與 MMPolymer 基本持平
未來展望
目前,Uni-3DAR 的實驗主要集中在微觀結構領域,因此亟需在宏觀 3D 結構任務中進一步驗證其通用性和擴展性。
此外,為保證與以往工作的公平對比,當前 Uni-3DAR 在每個任務上均採用獨立訓練。未來的一個重要方向是融合多種數據類型與任務,構建並聯合訓練一個更大規模的 Uni-3DAR 基座模型,以進一步提升性能與泛化能力。
同時,Uni-3DAR 還具備天然的多模態擴展潛力。後續可以引入更多模態的信息,例如蛋白質序列、氨基酸組成,甚至結合大語言模型與科學文獻知識,共同訓練一個具備物理世界理解能力的多模態科學語言模型,從而為構建通用科學智能體打下基礎。