三位數學家改寫經典牛頓法!300年前算法一夜更新,收斂速度更快函數範圍更廣
白交 一水 發自 凹非寺
量子位 | 公眾號 QbitAI
300年經典牛頓法,迎來重磅升級!
三位普林斯頓數學家找到更快更強的解法,其中還有一位是華人。
牛頓法是什麼?學過高數的同學想必並不陌生,它通過不斷求導來尋找複雜函數f(x)接近零點的最優解。
就是這麼一個非常簡單的「近似求解」算法,因為收斂速度非常快,時至今日它仍被廣泛應用在計算機視覺、物流、金融甚至純數學問題等各個領域,比如開發能夠區分交通信號燈和停車標誌的自動駕駛汽車。
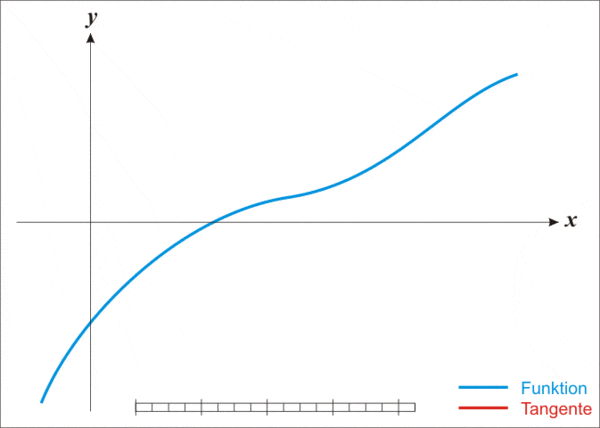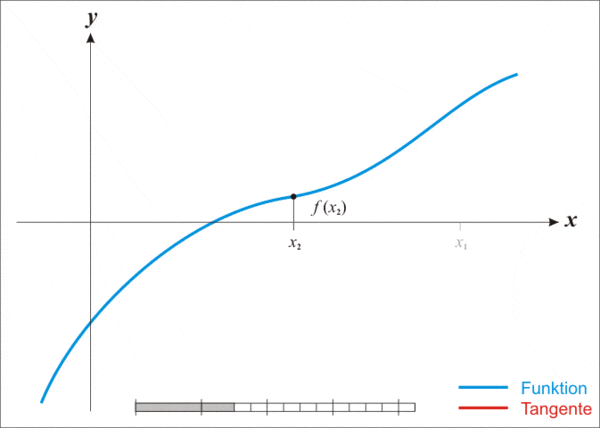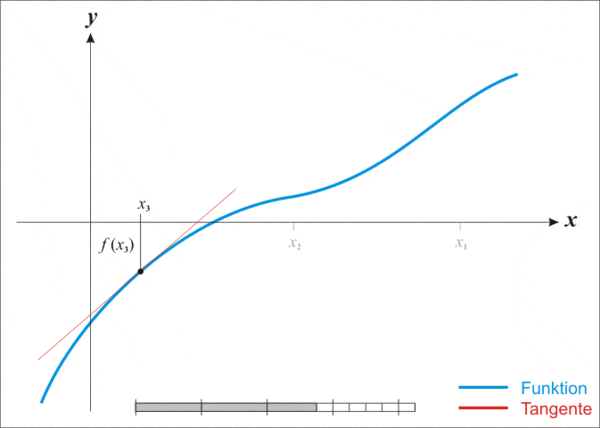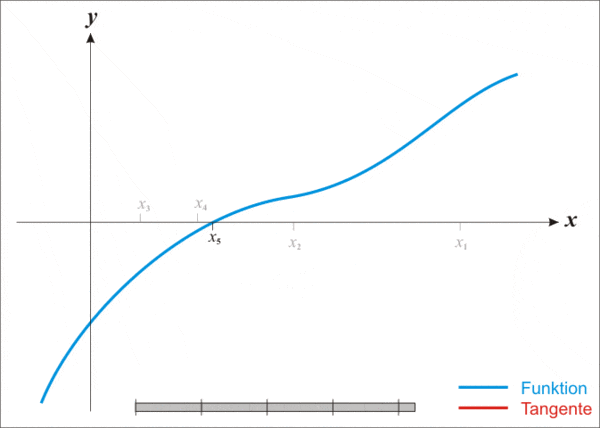
但即便這麼強大,牛頓法也存在一個缺點,那就是不適用於所有函數。
於是乎,過去幾個世紀諸多數學家前赴後繼企圖在此基礎之上進行優化。現在這三位數學家成功將可適用的函數範圍一擴再擴。
比如像這個複雜的二元函數。

與傳統牛頓法相比,新方法展現出來的更連貫,覆蓋也很大。
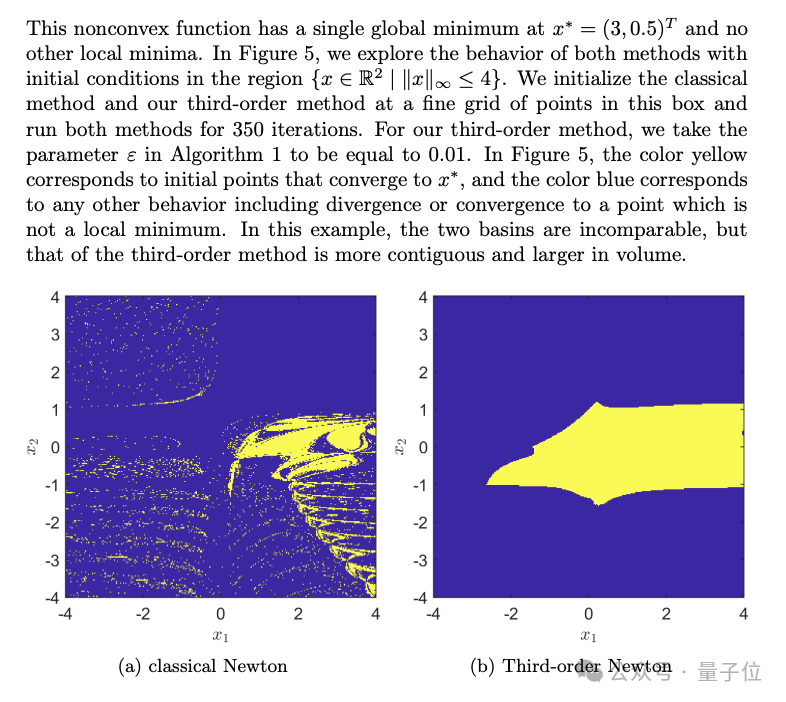
一合著者表示,牛頓法在優化中有1000種不同的應用,而他們的算法有可能取代它。
來看看究竟是咋回事情。
三位數學家改寫經典牛頓法
牛頓法(Newton’s Method)誕生於17世紀,由大名鼎鼎的英國數學家牛頓首次提出。
其核心思想是,通過不斷逼近函數的根或極小值點,以尋找函數的最優解。
通俗來說,這有點像在陌生環境里蒙眼尋找最低點。在行走過程中,我們唯一需要的信息在於兩點:1)自己是否在上坡或者下坡,即斜率(函數的一階導數);2)以及坡度是增加還是減少,即斜率本身的變化率(函數的二階導數)。
利用上述信息,我們可以相對快速地得到一個近似值。
若將這一過程用數學方法來表示,則具體如下:
-
Make a guess(做一個猜測):選擇一個接近你認為可能是最小值的起始點,作為尋找函數最小值的起點;
-
Model the curve(模擬曲線):在該點附近構造一個拋物線,以近似原函數的形狀;
-
Find the next point(找到下一個點):計算拋物線的最低點,以此作為新的迭代點;
-
Repeat(重覆):使用新的迭代點重覆上述步驟,逐步逼近函數的最小值;
-
Keep going(繼續進行):持續迭代,直至找到函數的最小值。
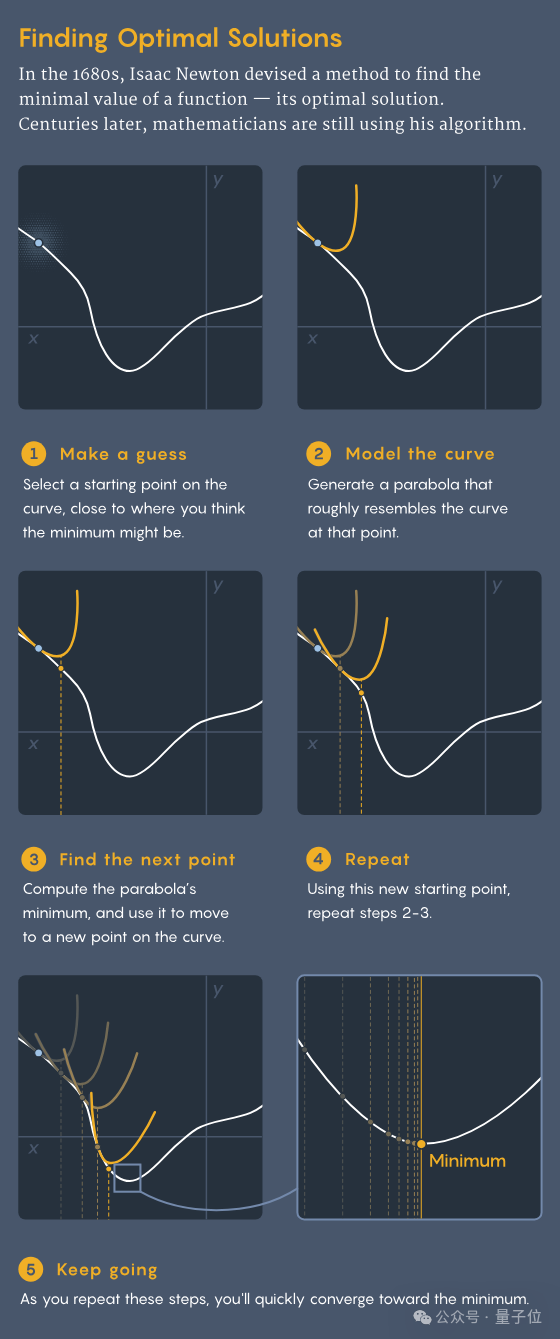
牛頓證明了,只要不斷重覆上述過程,最終就會逼近原始複雜函數的最小值。
而且和類似迭代方法(如梯度下降)相比,牛頓法雖然每次迭代的計算成本高於梯度下降,但在效率方面優勢明顯。
簡單來說,牛頓法收斂速度相比梯度下降法更快,即在更少的迭代次數內找到最小值,因此也適用於多種情況。
不過牛頓當時也提醒:
雖然這一方法在大多數情況下有效,但如果一開始從一個距離真實最小值太遠的點開始,則可能越跑越偏。

而且更麻煩的是,牛頓法還存在一個顯著缺點——不適用於所有函數。
其核心策略是將一個複雜函數轉化為一個更簡單的函數,而一旦函數過於複雜,它也同樣沒轍了。
因此後來數學家們努力的方向在於,在不犧牲效率的前提下擴大算法使用範圍。
直到去年夏天,三位研究人員發表了對牛頓法的最新改進。
將牛頓法擴展到迄今為止最廣泛的函數類別
具體而言,他們發現牛頓法在處理某些複雜函數(如高次冪函數)時效果不好,這是因為它依賴於函數的泰萊展開(一種使用求導和多項式逼近原函數的手段),而這個展開並不總是能很好地描述原函數,特別是當函數有很多「山穀」(局部最小值)時。
於是他們提出,如果一個函數滿足兩個條件,那麼它就更容易找到最小值:
-
凸形(Convex):函數的形狀像一個碗,只有一個「山穀」
-
平方和(Sum of Squares):函數可以表示為一些平方項的和
前者意味著如果從任何位置開始尋找,都不會陷入局部最小值的問題,因為只有一個最小值,而且無論從哪個方向開始,都會滑向這個唯一的最低點。
後者意味著可以很容易地識別和計算函數的最小值,因為平方和形式的函數特別容易處理,其平方數總是非負的,而且它們的最小值是0。
接下來,為了滿足上述條件,他們使用了一種叫做半定規劃(Semidefinite Programming)的技術來調整泰萊展開,具體步驟如下:
1、微調泰萊展開。不直接使用函數的泰萊展開,而是對其進行微調,使其既凸形又可以表示為平方和。
2、增加調整因子。在泰萊展開中加入一個調整因子,這個因子可以幫助他們控制展開的形狀,使其更接近原函數,同時滿足凸形和平方和的條件。
3、多導數收斂。他們的方法可以使用任意多個導數來進行泰萊展開,這意味著他們可以更快地找到函數的最小值。使用更多的導數可以讓算法以更高的速度(比如立方速度)收斂到最小值。
最終他們創造了這種更強版本的牛頓法,能夠以更少的迭代次數找到最小值。
他們的算法如下:

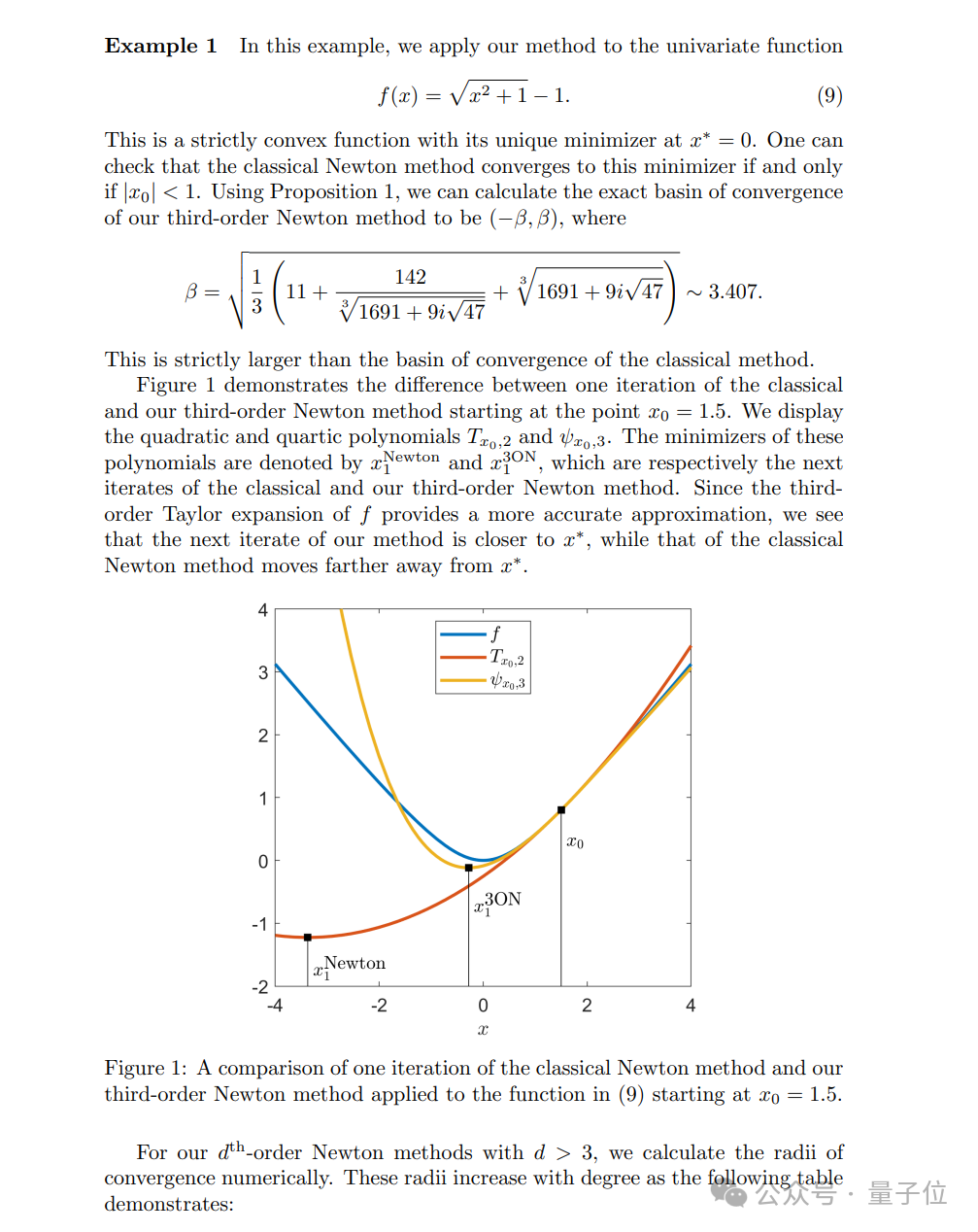
在下面這個函數中,與傳統牛頓法相比,其改進版本(第三階牛頓法)在理論上提供了更快的收斂速度,並且在實踐中可能比經典牛頓法更有效,尤其是在初始點離最小值點較遠的情況下。
一位華人參與
這項工作是三位數學家在普林斯頓大學期間合作完成的。

其中華人Jeffrey Zhang,目前是耶魯大學生物醫學信息學與數據科學博士後研究員,研究方向包括大型語言模型、數據科學和統計學、計算複雜性、多項式優化、博弈論和機制設計。

此前在普林斯頓大學獲得運籌學和金融工程博士學位,導師正是同為該論文作者的Amir Ali Ahmadi教授。
更早之前,他在2014年獲得耶魯大學計算機科學和經濟學與數學學士學位。
另一位作者Abraar Chaudhry也是Amir Ali Ahmadi教授的學生,現佐治亞理工學院博士後研究員。在普林斯頓攻讀博士之前,他在布朗大學讀本科。
事實上,在這三位數學家出現之前,有很多數學家都進行了嘗試。
最早19世紀,被稱為「俄羅斯數學之父」的Pafnuty Chebyshev提出了一種牛頓法,用三次方程(指數為3)近似函數。
不過當原始函數涉及多個變量時,他的算法就會不起作用。
更近的一次,2021年俄羅斯數學家Yurii Nesterov展示了如何使用三次方程有效地逼近任何數量的變量的函數。
但他的方法無法擴展到使用四次方程、五次方程等近似函數,否則會降低其效率。

現在,3位數學家將內斯特羅夫的結果又推進了一步。
與牛頓法的原始版本一樣,這種新算法的每次迭代在計算上仍然比梯度下降等方法成本更高。
因此,目前這項新工作不會改變自動駕駛汽車、機器學習算法或空中交通管製系統的運作方式。在這些情況下,最好的選擇仍然是梯度下降。
賓夕法尼亞大學Jason Altschuler表示:許多優化理念需要花費數年時間才能完全付諸實踐。不過這似乎是個全新的視角。
如果隨著時間的推移,運行牛頓法所需的底層計算技術變得更加高效,使得每次迭代的計算成本更低,那麼Ahmadi、Chaudhry和Zhang開發的算法最終可以在包括機器學習在內的各種應用中超越梯度下降。
合著者表示,從理論上講,他們目前的算法確實更快。
論文:
https://arxiv.org/pdf/2311.06374
參考鏈接:
Three Hundred Years Later, a Tool from Isaac Newton Gets an Update