剛剛,GPT-4o原生圖像生成上線,P圖、生圖也就一嘴的事
機器之心報導
機器之心編輯部
就在 DeepSeek V3「小版本更新」,阿裡通義千問團隊開源了新模型後,OpenAI 深夜也悄悄搞事情。
毫無預告地,OpenAI 推出 GPT-4o 原生圖像生成。效果讓人驚歎不已。更妙的是,即使免費用戶也可使用。
先來體驗一下:

在生成結果中可以看到,GPT-4o 在執行任務時首先會對我們的原始提示詞進行優化,編寫一個更加詳細的英文版提示詞:

在 OpenAI 看來,圖像生成應該是語言模型的核心能力之一。因此他們將最先進的圖像生成器 4o 集成到了 GPT-4o 中。
2024 年 5 月,OpenAI 發佈其首個全能多模態模型 GPT-4o,與 ChatGPT 之前採用的生成式 AI 圖像模型(OpenAI 的 DALL-E 3)不同 —— 這個經典的 diffusion transformer 通過去除像素噪聲來根據文本提示重建圖像 —— 新的圖像生成器被整合到了同一個多模態模型中。OpenAI 對整個模型進行了統一訓練,使其能夠同時理解文本、代碼和圖像等多種形式。
GPT-4o 的圖像生成能力具有以下突出優勢:它能精準呈現文字內容,嚴格遵循指令要求,並充分調用 4o 內置知識庫和對話上下文 —— 包括對上傳圖像進行轉化處理或將其作為視覺靈感來源。這些特性讓用戶能更輕鬆地創造出與構想完全一致的圖像,通過視覺表達實現更高效的溝通,從而將圖像生成技術升級為兼具精確性與實用性的強大工具。
效果如何,我們接著往下看。
有用且美麗的圖像生成
OpenAI 基於在線圖像和文本對模型進行了訓練,這不僅讓模型學習了圖像與語言之間的關係,還學習了圖像之間的相互關係。結合後訓練,最終的模型具有令人驚訝的視覺流暢性,能夠生成有用、一致且具有上下文感知能力的圖像。
文本渲染
一圖勝千言,但有時在恰當位置生成幾個字就能昇華圖像意境。4o 將精準符號與視覺元素完美融合的能力,使圖像生成進階為真正的視覺傳達工具。
提示:「創建一張逼真的照片,內容是兩名 20 多歲的女巫(一名是灰白色挑染髮型,另一名是長卷的紅褐色頭髮)正在閱讀一個街標。
背景:紐約威廉斯堡一條普通的城市街道,一根電線杆上完全被許多詳細的街標覆蓋(例如,街道清掃時間、需要停車許可證、車輛分類、拖車規則),包括中間的幾個荒謬的標誌:Broom Parking for Witches Not Permitted in Zone C,Magic Carpet Loading and Unloading Only (15-Minute Limit) 等等。
人物:一名女巫拿著一把掃帚,另一名女巫拿著一個捲起的魔法地毯。她們在前景中,身體微微背向相機,頭部微微傾斜,仔細查看標誌。
從背景到前景的構圖:街道 + 停放的汽車 + 建築物 → 街標 → 女巫。人物必須是離拍攝相機最近的。」
這就是生成一張圖片的部分提示詞,提示詞描述的可謂非常詳細。GPT-4o 不但嚴格遵循指令,還將提示語中的文本字符也準確的表達出來了。

GPT-4o 生成的菜單,不知道的還以為這是一張真實菜單。
提示:「我在 Marin 開設了一家名為 Haein 的傳統概念餐廳,主打採用有機農場新鮮食材烹製的韓式料理,並根據時令供應輪換菜單。請您設計一份菜單圖片,需包含以下菜品 —— 整體風格要兼顧傳統 / 鄉村韻味與高端精緻感。請為每道菜品配上優雅的彼得兔風格的插畫,確保所有文字正確呈現,並使用白色背景。
頂部:大醬湯(發酵大豆燉菜) – 18 美元
大醬湯是用當地的蘑菇、豆腐和時令蔬菜做成的,配上米飯……
底部:時令米酒 —— 每杯 12 美元」

持續生成
由於圖像生成功能現已深度集成於 GPT-4o 系統,用戶可通過自然對話實現圖像優化。GPT-4o 能基於聊天上下文中的圖文內容持續創作,確保輸出結果的一致性。例如在設計遊戲角色時,當你反復調整和測試方案,該角色的外觀特徵將在多次迭代中保持高度協調。
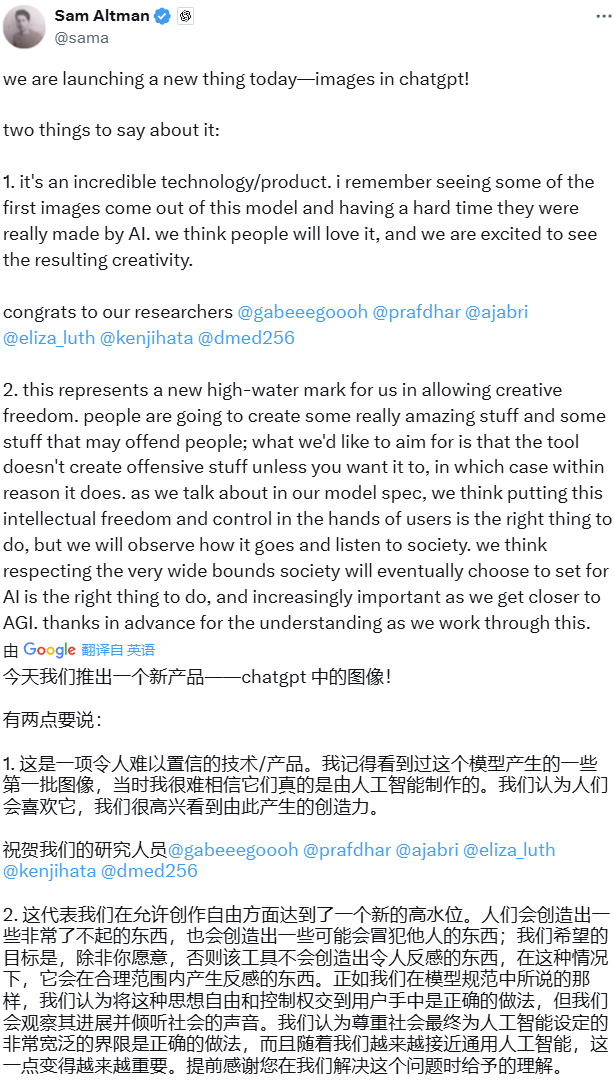
舉例來說,當你輸入一張貓咪的圖片,然後給出提示「給這隻貓一頂偵探帽和一副單片眼鏡」,GPT-4o 就能在保持原始圖片的情況下,遵循指令重新生成一張。
你還可以繼續修改圖片,只要給點提示就可以了,例如給定提示「將這個場景製作成一款 AAA 級的 4K 遊戲引擎打造的影片遊戲,並添加一個神秘角色扮演遊戲的用戶界面作為覆蓋層。在遊戲中,我們可以在頂部看到生命值條和小地圖,底部則顯示法術圖標,整體界面風格保持一致且具有標誌性。」對話過程一張精美的圖片就生成了。
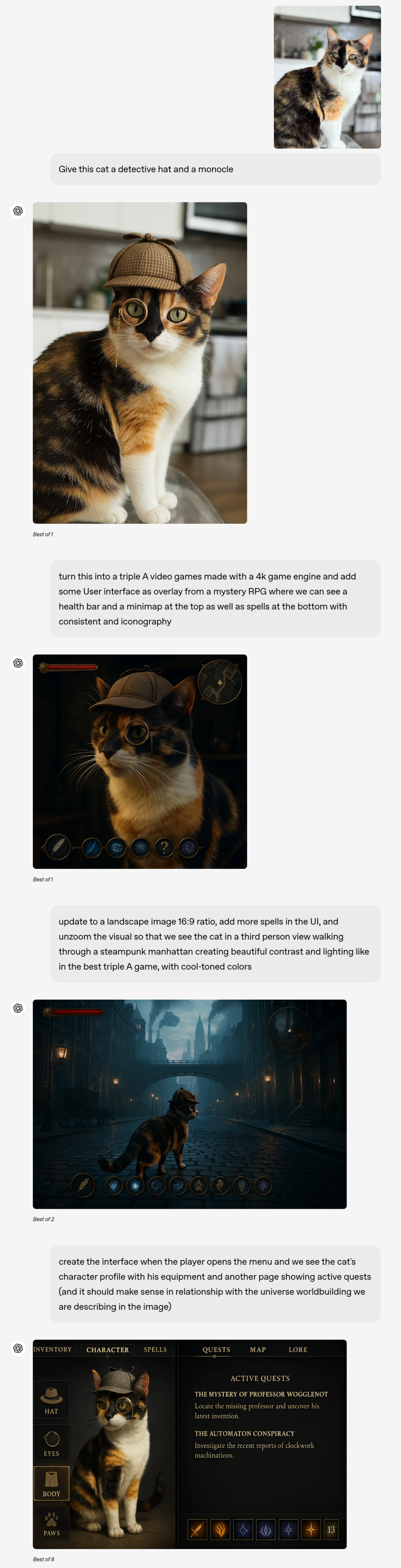
除了圖像作為輸入,你也可以從提示入手,例如要求 GPT-4o 生成一張「奢華蛋殼紋理卡片上的詩歌」,然後把詩歌內容也附加上,就能出現如下的效果圖,你也可以進一步修改,輸入提示就可以了。
指令遵循
GPT-4o 的圖像生成能夠細緻入微地遵循詳細的提示,注重細節。其他系統在處理大約 5 到 8 個對象時可能會遇到困難,而 GPT-4o 能夠處理多達 10 到 20 個不同的對象。對象與其特徵和關係的更緊密綁定,使得控制更加精準。
提示:「一張正方形圖片,包含一個 4 行 4 列的網格,共有 16 個物體,背景為白色。從左到右、從上到下依次排列如下:
一顆藍色的星星
一個紅色的三角形
一個綠色的正方形
一個粉色的圓形
一個橙色的沙漏
一個紫色的無窮大符號
一個黑白波點圖案的領結
一個紮染風格的 42 字樣
……
用草書寫成的 OpenAI 字樣
一道彩虹色的閃電」

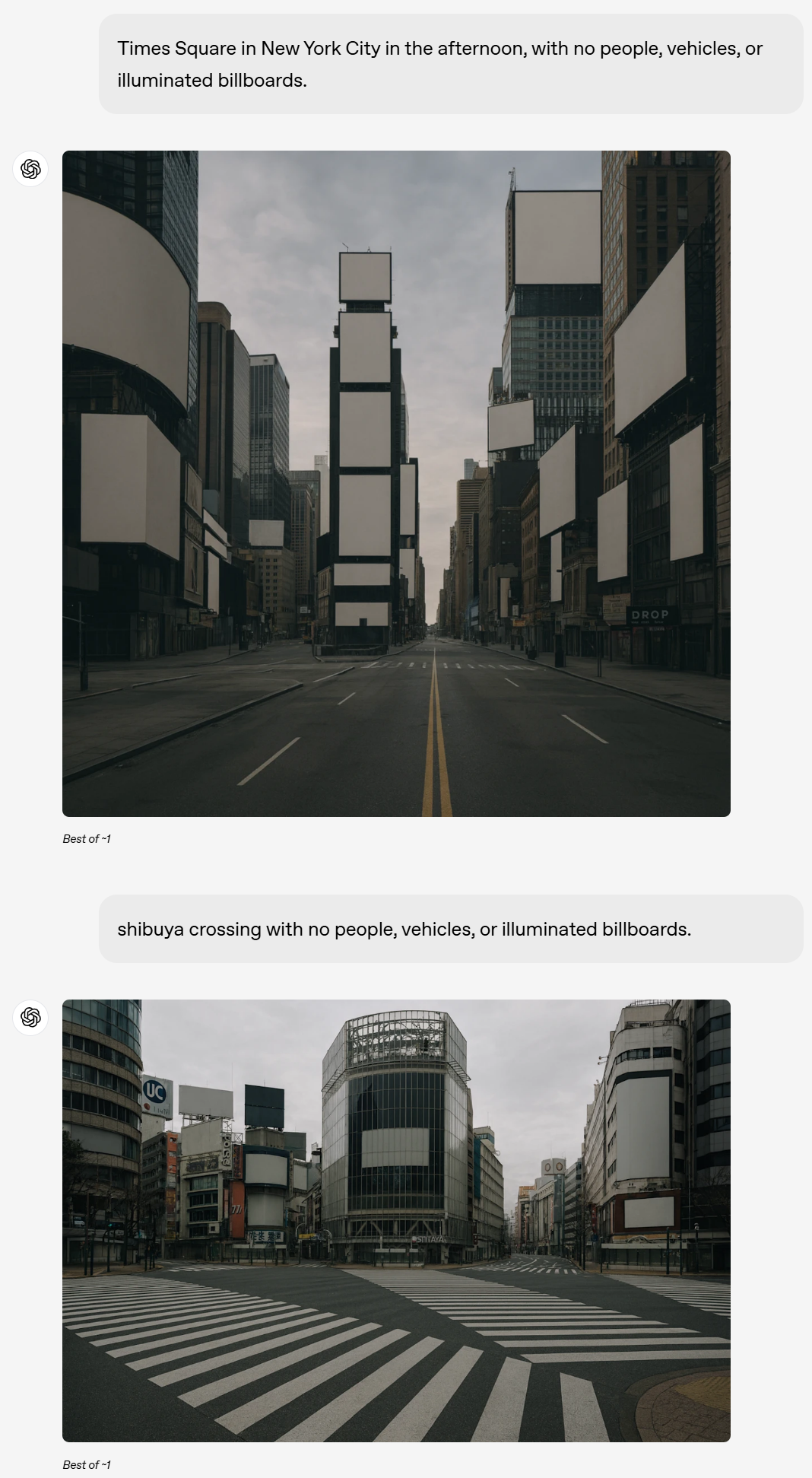
空曠的城市,提示:下午的紐約時代廣場,沒有人,沒有車輛,也沒有發光的廣告牌。
轉化數學公式:

上下文學習
GPT-4o 能夠分析並學習用戶上傳的圖像,將圖像的細節無縫整合到上下文中,以指導圖像生成。
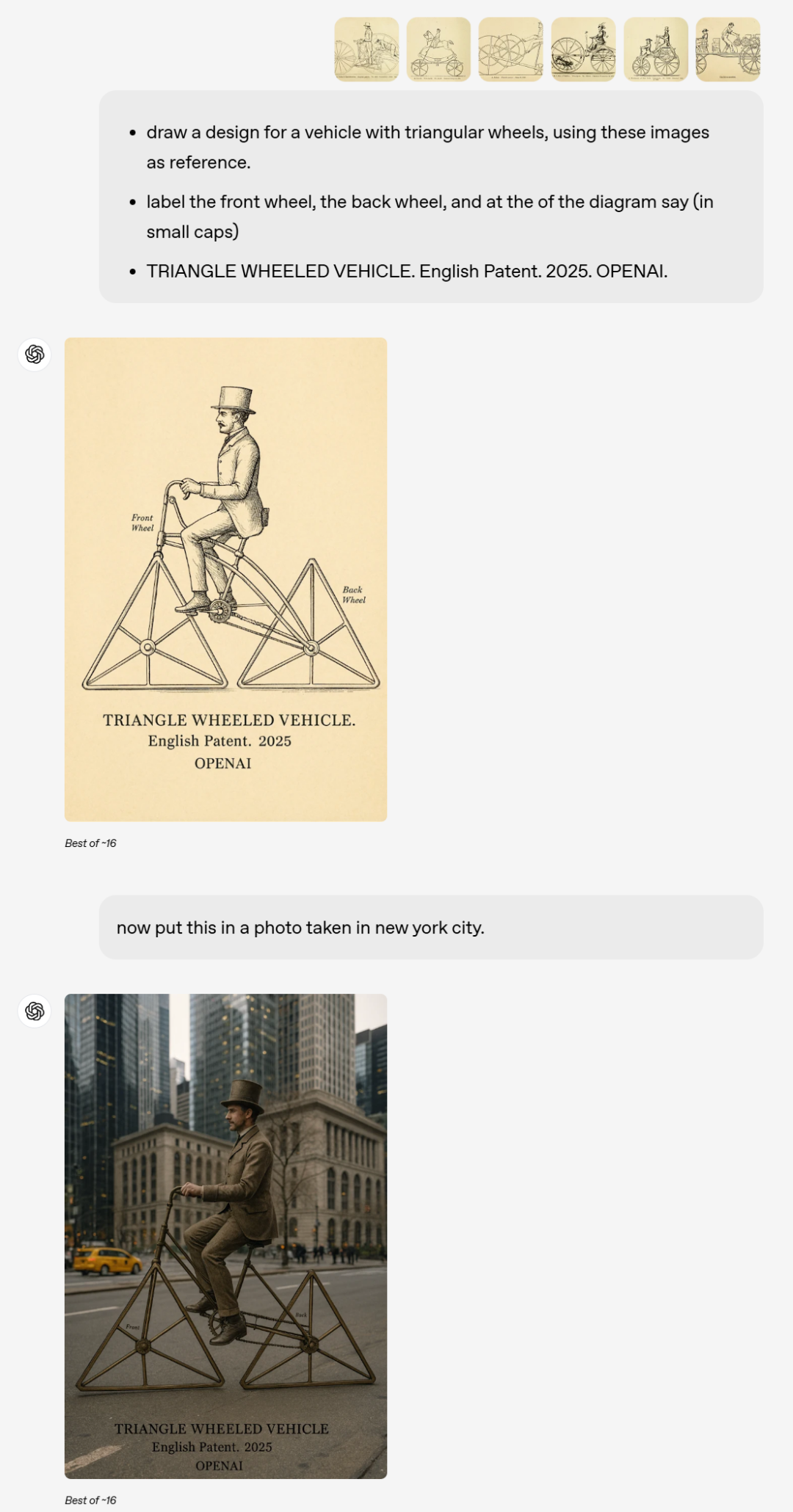
當你輸入幾張圖像,然後給出提示:用這些圖像作為參考,畫一個三角形車輪的車輛設計。
標出前輪,後輪,並在圖的下方給出文字(用小大寫)
「TRIANGLE WHEELED VEHICLE. English Patent. 2025. OPENAI」
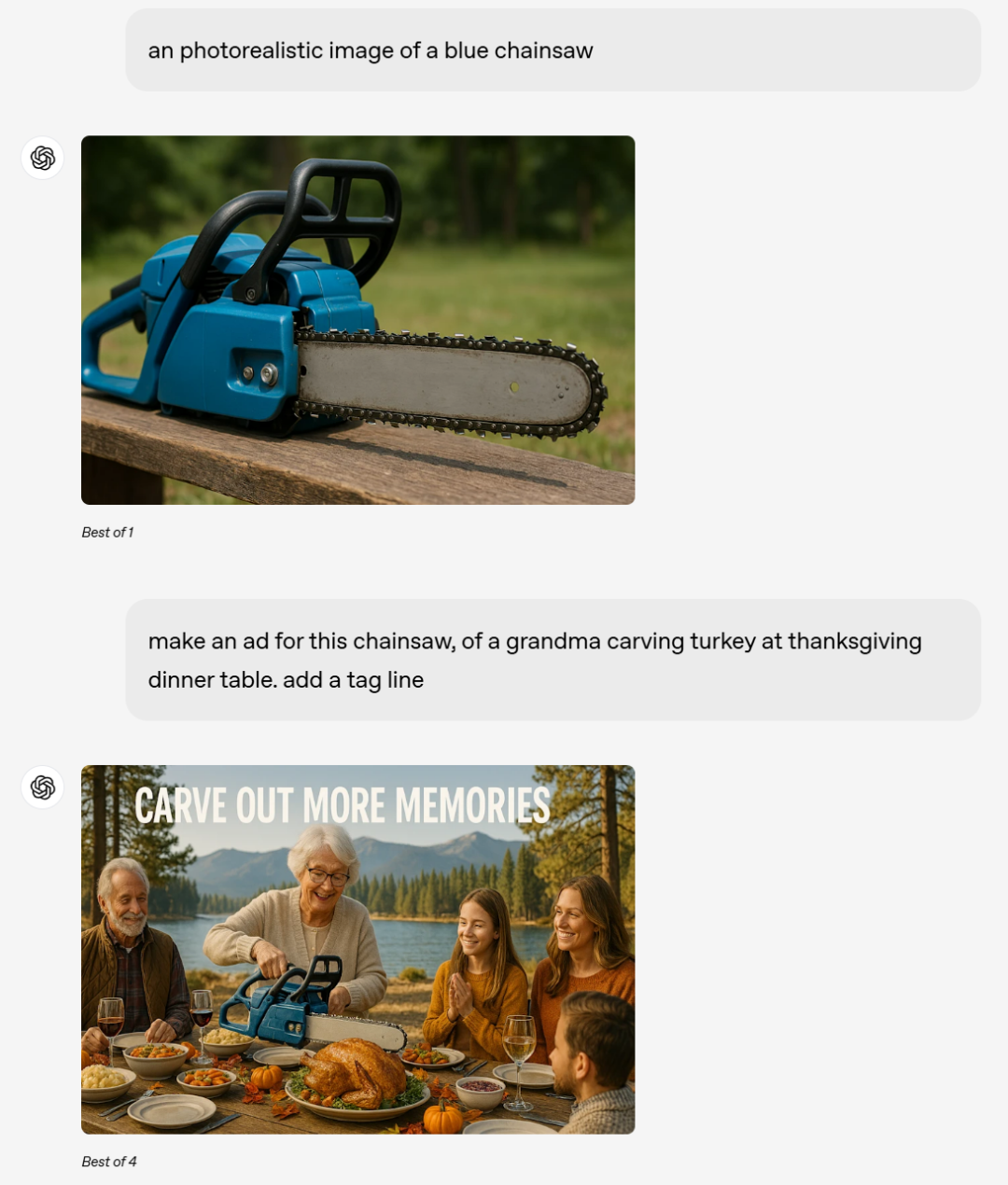
提示:藍色電鋸逼真圖像。
然後再給出提示:為這個電鋸做個廣告,一個奶奶在感恩節餐桌上切火雞。並添加標籤行。
世界知識
原生圖像生成使 4o 能夠將文本和圖像之間的知識聯繫起來,從而形成一個感覺更智能、更高效的模型。

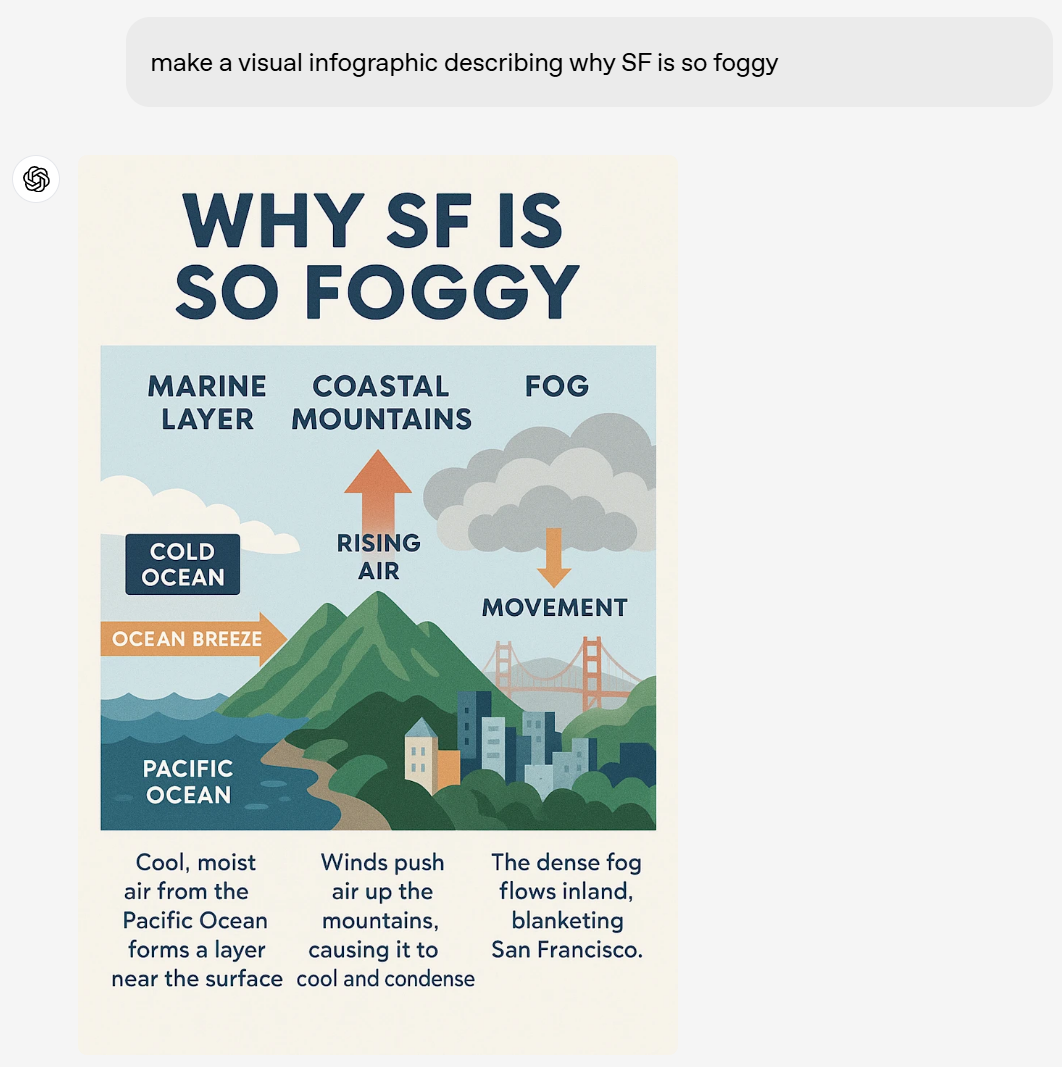
提示:製作一個視覺信息圖表,描述為什麼舊金山如此多霧。
簡單的一句提示,4o 就把影響環境質量的原因用圖片的形式描述出來了。看來,4o 掌握的知識還是很豐富的。
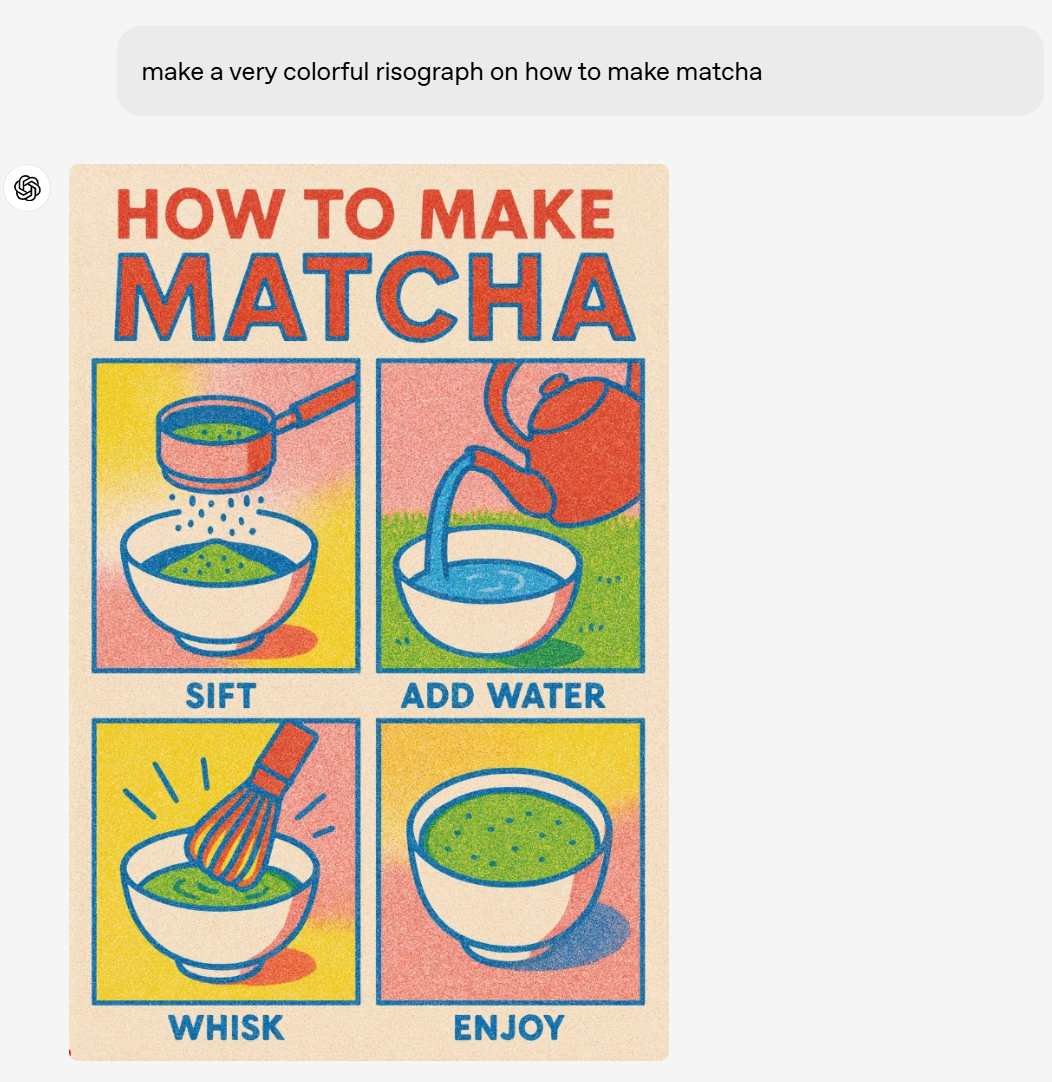
要求 4o 製作一幅關於如何製作抹茶的彩色圖解,也沒有問題。
風格
在反映豐富多樣圖像風格的圖像上進行訓練,使模型能夠令人信服地創建或轉換圖像。
提示:一隻貓望著街上的水坑,但它的倒影是一隻老虎,而且兩種倒影都被水中的漣漪真實地扭曲了。

提示:創建一張超逼真的照片,內容是這四隻動物在公園的野餐毯上玩撲克,畫面拉遠,呈現全景,照片風格逼真。一隻長毛虎斑貓正拿著一手牌……

局限性
OpenAI 沒有避諱自身模型的局限性。他們指出:「我們的模型並不完美。我們目前已經看到了其存在多種限制,我們將在首次發佈後通過模型改進來解決這些限制。」具體來說,OpenAI 羅列出的限制包括:
-
裁剪:GPT-4o 有時會錯誤地裁剪較長的圖像(如海報),尤其是靠近底部的部分。
-
幻覺:與其他文本模型一樣,圖像生成模型也可以編造信息,尤其是在上下文提示較少時。
-
高結合問題:當生成圖像需要依賴於其知識庫時,它可能難以同時準確地呈現 10-20 多個不同的概念,例如完整的元素週期表。
-
精確繪圖:模型可能在繪製涉及數據的圖表時不準確。
-
多語言文本渲染:模型有時難以渲染非拉丁語言,並且字符可能不準確或產生幻覺,尤其是在更複雜的情況下。
-
編輯精度:當要求編輯圖像生成的特定部分(例如拚寫錯誤)時,結果並不總是有效,還可能出現在沒有請求的情況下更改圖像的其他部分或引入更多錯誤的情況。另一個錯誤是模型難以保持用戶上傳的人臉在編輯中的一致性,但 OpenAI 預計將在一週內修復該錯誤。
-
小文本信息密集:眾所周知,當被要求以非常小的尺寸呈現詳細信息時,模型會遇到困難。

模型難以呈現完整的元素週期表
安全性
OpenAI 也強調了自己在模型安全方面所做的工作。
按照 OpenAI 之前發佈的 Model Spec(模型規範),他們的目標是「通過支持遊戲開發、歷史探索和教育等有價值的用例來最大限度地提高創作自由 —— 同時保持嚴格的安全標準。與此同時,阻止違反這些標準的請求仍然和以往一樣重要。」以下是對其它風險領域的評估:
通過 C2PA 和內部可逆搜索給出出處
所有生成的圖像都將自帶 C2PA 元數據,即會被標記成來自 GPT‑4o 的圖像。OpenAI 表示,這樣做是為了提供透明性。並且他們宣佈已經構建了一個內部搜索工具,可利用生成結果的技術屬性來幫助驗證某個內容是否出自他們的模型。
阻止不良內容
OpenAI 表示將繼續阻止可能違反其內容政策的生成圖像請求。他們表示,當真人圖像處於上下文中時,會加強對可以創建的圖像類型的限制。
「與任何發佈一樣,安全性永不止步,而是一個持續的投資領域。隨著我們更多地瞭解該模型在現實世界中的使用情況,我們將相應地調整我們的政策。」
使用推理來增強安全性
與審議性對齊(deliberative alignment)類似,OpenAI 表示已經訓練了一個可以直接根據人工編寫的可解釋安全規範工作的推理 LLM。
「我們在開發過程中使用了這個推理 LLM 來幫助我們識別和解決我們政策中的歧義。結合我們為 ChatGPT 和 Sora 開發的多模態技術進步和現有的安全技術,這能讓我們根據我們的政策來調節輸入文本和輸出圖像。」
有關安全性的更多論述和研究結果請訪問 OpenAI 同步發佈的 GPT-4o 系統卡附錄。

附錄地址:https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
哪些用戶可以使用?
OpenAI 表示,從今天開始,4o 圖像生成能力將向 Plus、Pro、Team 和免費用戶推出,作為 ChatGPT 中的預設圖像生成器,企業版和教育版用戶還需等待一段時間。它也可以在 Sora 中使用。對於那些 DALL・E 在其心中佔有特殊地位的人來說,仍然可以通過一個專門的 DALL・E GPT 訪問它。
API 用戶呢?OpenAI 表示也快了:訪問權限將在未來幾週內推出。
最後,OpenAI 表示:「使用 GPT-4o,創建和定製圖像就像天一樣簡單 —— 只需描述你需要什麼,包括任何細節,如寬高比、使用十六進製代碼的精確顏色或透明背景。」不過,OpenAI 也指出,由於此模型能生成更詳細的圖像,因此圖像渲染時間更長,通常長達一分鐘。
參考鏈接:https://openai.com/index/introducing-4o-image-generation/