OpenAI發佈生圖神器狙擊Google,一句話精細P圖
本文來自微信公眾號:APPSO (ID:appsolution),原文標題:《剛剛,OpenAI 發佈生圖神器狙擊 Google!一句話 P 圖奧特曼現場玩梗,免費能用》,題圖來自:新模型AI生成
就在剛剛,OpenAI宣佈在GPT-4o模型中集成了迄今為止最先進的圖像生成器。
OpenAI CEO Sam Altman在X平台繼續誇誇群主上線,表示初次見到模型生成的圖片時,難以相信是AI所為,並期待用戶能發揮創意。

新功能亮點如下:
能夠精確渲染文本內容
支持多模態輸入輸出(文本、圖像、音頻)
能理解複雜指令並結合上下文
能創建具有真實感的第一人稱視角圖像
遵循指令,可以處理上傳的圖片並進行編輯或風格轉換
先來感受一下新模型生成的圖片:



最新版本的系統卡寫到,與作為擴散模型的DALL·E不同,4o圖像生成是一個自回歸模型,原生嵌入在ChatGPT中。
具體來說,比起其他圖像生成模型,GPT-4o能處理多達10—20個不同物體的複雜指令,遠超競爭對手5—8個的限制,差距不是一般大。
一句話P圖也行,該模型同樣支持多輪圖像生成,聊著天就能優化圖像,確保角色等元素在多次迭代中保持一致性。

比如設計個遊戲角色,改來改去外觀都能穩住,還能分析用戶上傳的圖像、細節抓得準,並指導後續圖像生成。
目前,新功能已向Plus、Pro、Team和免費用戶開放,Enterprise和Edu用戶即將獲得訪問權限。別急,開發者們幾週後也能通過API用上這功能。
使用GPT-4o創建和自定義圖像非常簡單,只需描述需求,包括縱橫比、精確顏色或透明背景等規格。不過要是細節多,渲染可能得等上一分鐘,畢竟慢工出細活嘛。
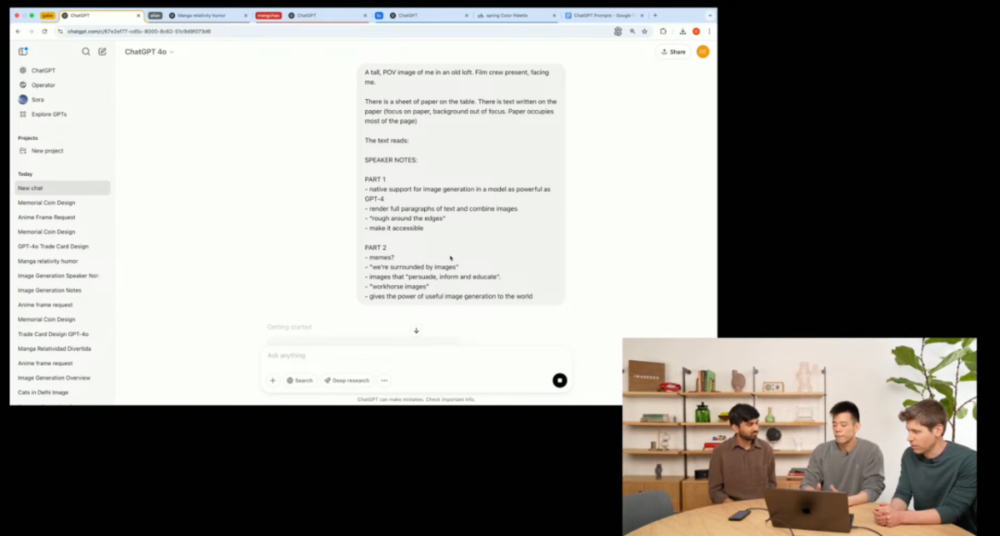
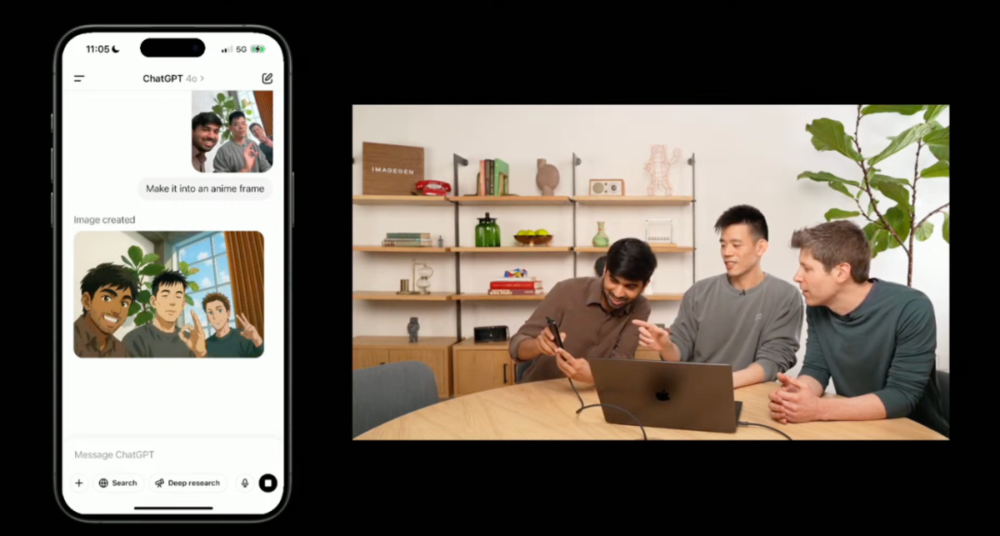
今天淩晨召開的發佈會也向我們展示了幾個具體的案例。比如說,演示者拍了張仨人的合照,讓ChatGPT改成動漫風。
結果模型不僅保留了三人的特徵(如鬍鬚、表情等),還能理解並融合「動漫」這一視覺風格。
接著他又讓它改成互聯網梗圖,加上了「I FEEL THE AGI」的文字,果然,OpenAI的發佈會少了AGI總感覺差點意思,屬實是傳統藝能了。
又或者,演示者要求模型創建一個「描述相對論的彩色漫畫頁面,並添加幽默元素」。
模型生成一個結構完整的漫畫頁面,包含了相對論相關概念的解釋,融合了不同語言的文字,並通過視覺表現形式呈現出幽默效果。
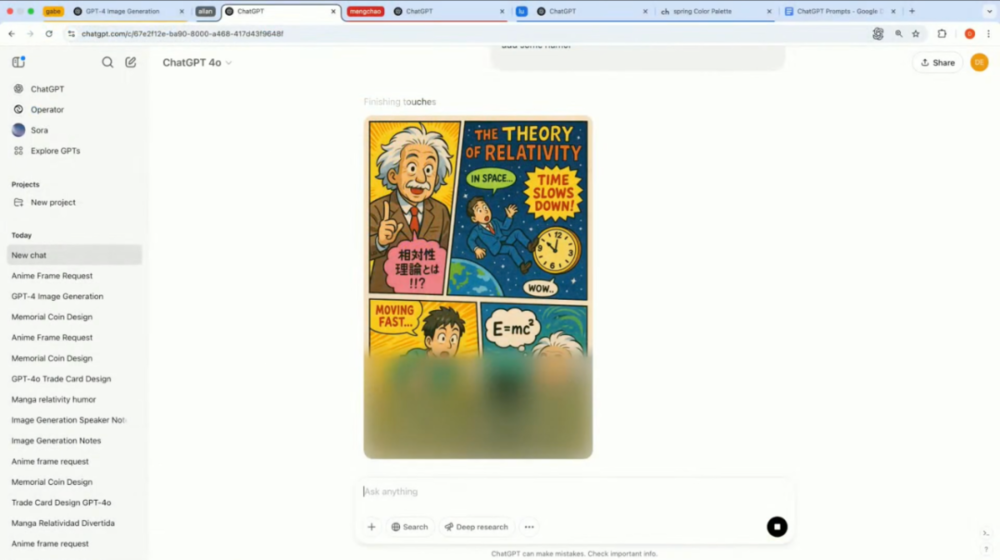
換句話說,能夠將抽像科學概念可視化,有望利好教育領域。
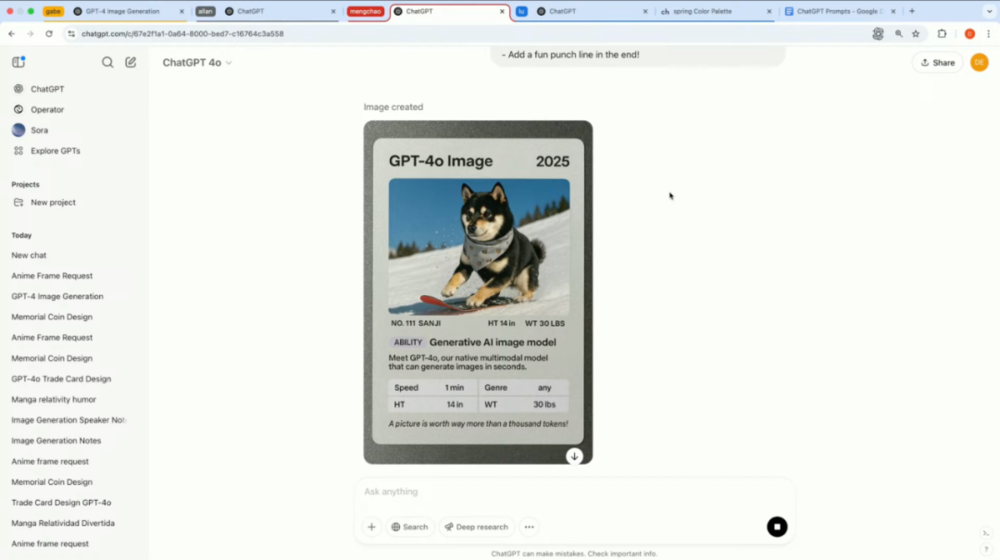
還有演示者先上傳了一張Sora發佈會的交易卡片照片作為參考,然後上傳了自己寵物狗的照片,並提供了卡片上應包含的具體信息(名稱、年份、能力、體重身高等)。
模型很快整出一張風格統一的卡片。卡片里,狗狗站在滑雪板上帥氣出場,文字排版清晰準確。
繼續上強度,演示人員拿前兩個演示的圖加上背景兩張圖,讓模型設計一枚紀念幣,並指定了特定的顏色代碼(春季色彩)和文字要求。
模型成功將四張不同圖像以和諧方式融合到一個幣面設計中。他隨後還要求將背景改為透明,以便實際打印,模型穩穩改好,設計也沒走樣。

AI生成圖像造成的危害已經不是什麼新鮮的話題了。為了安全,所有生成圖像都帶有C2PA元數據標識,OpenAI還構建了內部搜索工具,驗證內容來源,以及阻止違反內容政策的圖像請求。
當要求生成真人圖像時,OpenAI則管得更嚴。包括Altman也表示,OpenAI希望工具預設不生成冒犯性內容,除非用戶明確要求,並在合理範圍內實現。
新功能也存在比較明顯的短板。比如偶爾裁剪不恰當、低上下文提示下可能產生幻覺、渲染非拉丁語言文本困難、局部調整不夠細等。OpenAI說了,這些小問題會在發佈後慢慢優化。

此外,Google於今天淩晨也發佈了旗下迄今為止最強大的AI模型。
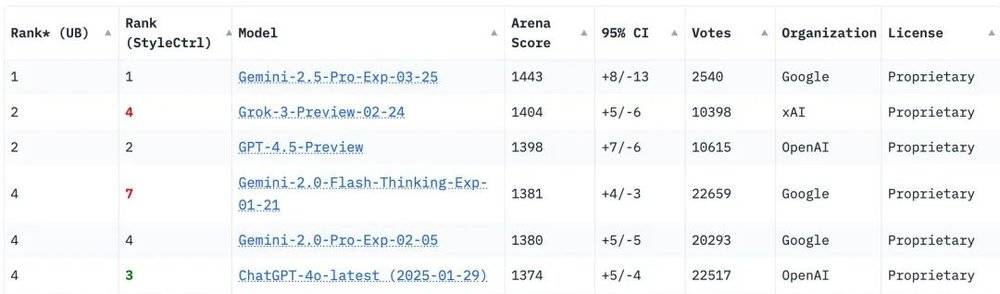
Google CEO Sundar Pichai在線打Call,稱Gemini 2.5 Pro Experimental是一款最先進的「思維」模型,在多個基準測試中領先,特別是在推理和編程能力上有了顯著的提升。
在大模型競技場Chatbot Arena中,新模型力的排名壓Gork 3,再次遙遙領先。
按照OpenAI過往的「狙擊」作風,新模型的發佈一方面是對上週Google發佈的圖像模型進行回擊,另一方面同樣是狙擊Gemini 2.5 Pro Experimental。
你方唱罷我登場,AI巨頭們針鋒相對的戲碼只會越演越烈,消停?看來是想都別想了。
本文來自微信公眾號:APPSO (ID:appsolution)