INTERSPEECH2025-MLC-SLM挑戰賽正式啟動!聚焦多語種語音數據集,語音AI的巔峰之戰!
大語言模型(LLMs)作為語言理解與生成的基礎技術,其應用已擴展至語音處理領域,如語音識別、對話系統等新興方向。然而,構建基於LLMs的語音對話系統面臨核心挑戰:真實多語種對話數據的稀缺性。這類數據需涵蓋自然停頓、說話者重疊等複雜交互場景,對提升AI系統的多語種理解能力和長上下文處理能力至關重要,直接影響下一代人機交互的自然度與準確性。為推動這一研究發展,由數據堂主辦,中國移動、Meta、Google、 Samsung、Naver聯合贊助的INTERSPEECH2025多語種對話語音語言模型(MLC-SLM)研討會正式對外發佈,本次研討會將通過發佈多語種對話語音數據集並舉辦MLC-SLM挑戰賽,推動該領域的技術突破。
一、核心亮點
- 雙賽道任務,均要求參賽者探索基於 LLM 的語音模型的開發:
- 任務I:多語種對話語音識別
- 目標:開發基於 LLM 的多語種 ASR 模型。
- 參賽者將獲得每段對話的真實時間戳標註及說話者標籤用於切分語音片段。
- 該任務的重點是優化多語種對話環境下的語音識別準確率。
- 任務II:多語種對話語音日誌與識別
- 目標:開發一個同時進行說話者日誌(即識別誰在何時說話),又能進行語音識別(將語音轉換為文本)的系統。
- 評估過程中不提供任何先驗信息,如真實時間戳標註、預先切分的語音片段、說話者標籤等
- 該任務可以使用基於級聯繫統或端到端系統的方法。
對於任務 I,系統性能將基於不同語言的詞錯誤率(WER)或字符錯誤率(CER)進行評估。
對於任務 II,性能將基於說話人日誌錯誤率(DER)以及連接最小排列詞錯誤率(cpWER)或字符錯誤率(cpCER)進行評估。DER用於確定在參考標註和日誌結果之間的最佳說話人排列。然後,將同一說話人識別結果和參考進行連接,以計算cpWER或cpCER。所有提交將根據cpWER或cpCER進行排名。
2.多語種對話語音數據集
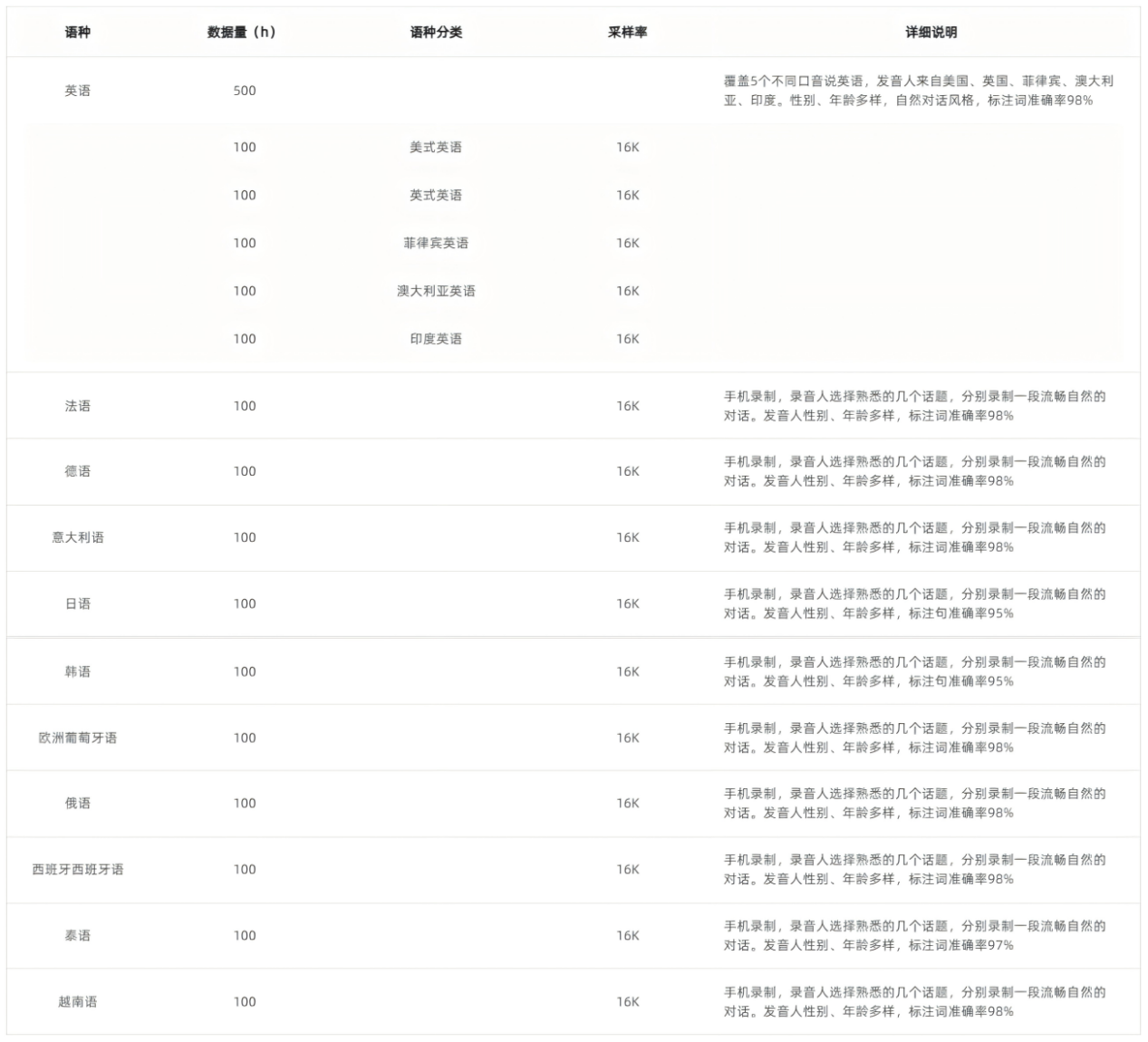
11種語言:英語(細分美/英/澳/印/菲口音)、法、德、日、韓等,總時長1500小時。
(1).數據特性:
-
- 自然對話場景:每段錄音均由兩位說話者就隨機分配的主題進行有意義的對話,需提供真實時間戳標註和說話者標籤。
- 高精度標註:日、韓語標註詞準確率95%+,其他語言98%。
- 多設備錄製:使用iPhone等設備並於安靜的室內環境採集,采樣率16kHz
- (2).
數據集結構:
-
- 訓練集:英語500小時(分5種口音)+其他語言各100小時,任務I/II共享。
- 開發集:每語種約4小時,任務I/II共享。
- 評估集:每個任務使用不同的評估集,分別指定為 Eval_1 和 Eval_2。具體來說,Eval_1 包括真實時間戳標註和說話者標籤,使用 WER/CER 進行評估。Eval_2 不提供時間戳或說話者標籤,因此需要使用說話者日誌系統在識別之前對較長的錄音進行分段。
-
參與者可以通過簽署數據使用協議並提交至報名表單來訪問數據集。提交後,數據下載鏈接將發送到您的電子郵件。
3.學界與產業界雙重背書
組委會:馮俊蘭(IEEE Fellow及首席科學家/中國移動)、Eng-Siong Chng(教授/南洋理工大學)、Shinji Watanabe(副教授/卡內基梅隆大學)、Khalid Choukri(秘書長/歐洲語言資源協會)等全球頂尖專家領銜。
贊助商:中國移動、Meta、 Google、 Samsung、 Naver、數據堂
二、參賽價值
獎金池20,000美金:單任務前三名分別獲5,000/3,000/2,000美金。
論文發表機會:優秀成果可入選INTERSPEECH研討會,與頂級學者同台交流(參考下文「其他主題」)。
技術自由度:允許使用外部數據集與預訓練模型(需公開聲明),支持數據增強。
註:參加研討會的註冊費
- 非會員註冊費:60歐元
- 非會員學生註冊費:45歐元
- ISCA會員註冊費:50歐元
- ISCA學生會員註冊費:35歐元
三.關鍵日程(AOT時間)
2025 年 3 月 10 日:註冊開放
2025 年 3 月 15 日:訓練數據發佈
2025 年 4 月 1 日:開發集和基線系統發佈
2025 年 5 月 15 日:評估集發佈及 Leaderboard開放
2025 年 5 月 30 日:Leaderboard凍結,論文提交系統(CMT)開放
2025 年 6 月 15 日:論文提交截止
2025 年 7 月 1 日:論文錄用通知
2025 年 8 月 18 日:荷蘭鹿特丹研討會(鹿特丹阿霍伊會議中心)
四、參賽必讀
所有參與者必須遵守以下規則:
- 外部資源使用:對於任務I 和 任務II,允許使用外部數據集和預訓練模型(包括語音基礎模型和大語言模型)。所有使用的外部資源必須是公開可獲取的,並且在最終系統報告中應明確標明。
- 數據增強:允許在發佈的訓練集上進行數據增強,可能包括但不限於添加噪聲或混響、速度擾動和音調修改。
- 禁止使用評估集:嚴禁以任何形式使用評估集。這包括但不限於使用評估集進行微調或訓練模型。
- 多系統融合:參與者不得在任務I和任務II中使用系統融合。提交的結果必須來自單個模型,而不是通過結果融合得出。
- 提交要求:所有參賽者必須提交其系統。提交內容包括最終識別結果、模型以及能夠直接進行推理並獲得最終結果的Docker容器等文件。詳細的提交說明將在基線系統發佈後提供。請注意,我們將公開那些確認參與但未提交任何文件的團隊及其所屬機構的名稱。
- 主辦方解釋權:主辦方對本規則擁有最終解釋權,特殊情況由主辦方酌情協調解釋。
五、其他主題
除了挑戰系統內容外,還鼓勵參與者提交創新發和賽前分析性研究論文。主題包括但不限於:
- 新穎的架構和算法:開發用於訓練語音語言模型的新架構和算法。
- 音頻數據處理管線:創新音頻數據處理流程,促進多樣化互聯網數據的收集,以便訓練語音語言模型。
- 自然且情感豐富的語音生成:設計用於生成更加自然且富有情感表達的對話語音的算法,提升對話系統的表現。
- 利用多輪對話歷史:利用多輪對話歷史來增強識別和分離結果的技術
- 評估技術和基準:評估語音語言模型的創新評估技術或基準。
- 新數據集:創建用於訓練語音和音頻語言模型的新數據集,包括真實數據和合成數據。
六.立即參與
 註冊通道:參與者需進行註冊。請上傳已簽署的數據使用協議並填寫註冊表單(Google表單)【點擊註冊】,挑戰賽將於2025年3月10日開始。
註冊通道:參與者需進行註冊。請上傳已簽署的數據使用協議並填寫註冊表單(Google表單)【點擊註冊】,挑戰賽將於2025年3月10日開始。
如需瞭解其他與註冊相關的信息,請發送郵件至:mlc-slmw@nexdata.ai
數據協議:已註冊的參與者將有權訪問訓練和測試數據集。他們必須簽署數據使用協議(見下文)、同意保密並遵守數據保護協議。數據集僅用於本次研討會競賽,嚴禁重新分發或任何其他用途。參與者有責任保護數據免受未經授權的訪問。
數據許可協議:Data use agreement- nexdata【點擊下載】
結語
真實對話語音數據不僅對於技術進步至關重要,還在構建能夠理解多語種和長上下文內容的人工智能系統方面發揮關鍵作用。本次研討會通過發佈高質量的多語種對話語音數據集,並舉辦MLC-SLM挑戰賽,旨在為全球研究者和開發者提供一個開放的平台,促進該方向的研究。未來,隨著更多創新技術的湧現,基於LLMs的語音對話系統將更加智能、貼近人類交流方式,為全球用戶提供無縫的多語言溝通體驗。讓我們攜手共進,開啟人機交互的新篇章!