無需Attention的未來,RWKV-7能成為替代Transformer的那隻黑天鵝嗎?

作者|週一笑郵箱|zhouyixiao@pingwest.com
在當今大模型領域,Transformer架構佔據著主導地位。然而,儘管Transformer非常強大,但它的計算需求隨著文本長度呈平方級增長,這導致運行成本高昂,同時限制了其擴展能力。
與此相對,更為古老的RNN(循環神經網絡)架構雖然計算效率高,但通常無法達到Transformer的性能水平,並且訓練過程更為複雜和緩慢。
在這一背景下,由元始智能創始人彭博提出了RWKV架構。RWKV融合了Transformer和RNN的優點,在訓練階段可以像Transformer那樣並行計算,在推理階段又能像RNN那樣高效運行。隨著發展,RWKV現已成為隸屬於Linux基金會的開源非盈利組織,其代碼、模型和文檔均公開透明,核心項目RWKV-LM在GitHub上開源,形成了一個活躍的開發者社區。
自2021年8月首個實驗性版本RWKV-V1發佈以來,RWKV架構經歷了多次重要迭代。它最初是對傳統循環神經網絡的改良嘗試,旨在解決處理長文本時的效率問題。2023年,RWKV-4實現了關鍵突破,使其能夠在普通硬件環境下高效處理各種語言和長篇文本。此後,RWKV逐漸被納入主流AI工具庫,RWKV社區的開發者甚至發現微軟Windows系統在Office組件更新後內置了RWKV的運行庫。
剛剛發佈論文的RWKV-7是這一架構的最新進展,它採用創新的動態狀態演化技術,支持100多種語言,能夠編寫代碼,處理超長文本。RWKV-7系列發佈了七個預訓練模型,參數規模從0.19億到29億不等,訓練token數量從1.6萬億到5.6萬億不等,適應不同應用場景的需求。

彭博稱RWKV-7設計靈感來自於「第一性原理」,核心想法是:模型的內部世界必須持續擬合外部世界。

這聽起來有點抽像,但我們可以把它想像成一個「聰明的學生」在學習和適應環境的過程。QKV-softmax-attention(常見於 transformer 模型),它的做法是把所有「問題-答案」對放在一起,然後通過比較新問題 q 和每個「問題」 k 的相似度,來決定答案是什麼。就像小學生每次考試前,把課本里的所有題目都翻一遍,找到和新問題最像的那個,再寫下答案。
而 RWKV-7 的方法不是每次都去翻課本,而是直接從這些「問題-答案」對中動態學到一個「變換規則」(k -> v 的映射)。這個規則就像小學生自己總結出的解題技巧,遇到新問題時,直接用這個技巧推導出答案。
性能驗證:超同尺寸模型
RWKV-的7創新在實際性能測試中也得到了驗證,在訓練數據遠低於 Qwen2.5、Llama3.2 等開源模型的前提下,RWKV-7-World 模型的語言建模能力在所有開源 3B 規模模型中達到 SoTA 水平。
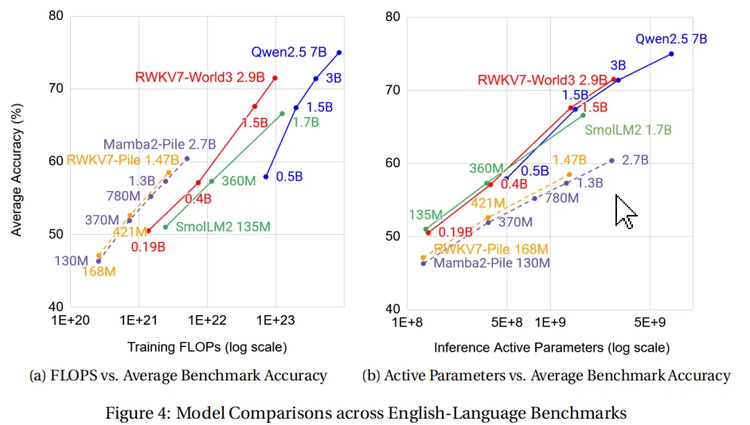
RWKV團隊採用 Uncheatable Eval 方法——利用 2025 年 1 月之後的最新論文、新聞文章等實時數據,測試開源大語言模型的真實建模能力和泛化能力。
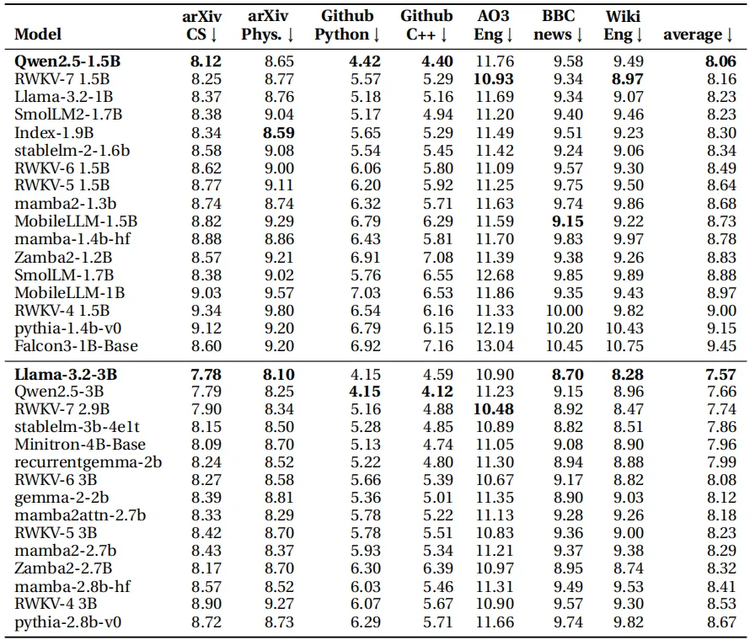
評測結果顯示,在同等參數規模的前沿模型中,RWKV-7 依然具備強競爭力,展現出優秀的適應性和泛化性能。團隊正在訓練數據更多的 RWKV7-G1 系列模型,目標是在這個榜單同樣超越所有其他前沿模型。

技術創新:動態狀態演化
RWKV-7究竟通過哪些技術創新實現了這些令人印象深刻的性能表現呢?根據由社區成員聯合撰寫的RWKV-7架構論文《RWKV-7 “Goose” with Expressive Dynamic State Evolution》,RWKV-7引入了一項名為「表達性動態狀態演化」的關鍵創新,這是其性能提升的核心所在 。具體來說,RWKV-7通過引入一種廣義化的delta規則,使模型能更好地理解和處理信息。
RWKV-7在讀取新信息時,有一種特殊的方式來更新其記憶,有點像記筆記。這種特殊的方式被稱為「廣義 Delta 規則」。
把模型想像成有一個草稿本,它在上面記錄了從目前為止的文本中學到的東西。當它看到一個新的詞或信息時,它需要決定如何更新這個草稿本。
最初的「Delta 規則」擦除一點它為該鍵存儲的舊信息,並添加一點新信息。它擦除和添加的數量由一個簡單的數字控制。現在,RWKV-7 的規則是「廣義的」,這意味著它更靈活、更強大。它不是只用一個數字來決定為一個鍵擦除和添加多少信息,而是使用更詳細的指令。
通過引入廣義Delta Rule,RWKV-7 使用 2 層即可實現 複雜度的 狀態跟蹤問題,使用 4 層即可識別所有正則語言。
簡單來說,Transformers在處理這些「正則語言」時有局限性。它們的能力被限制在一個叫 TC0 的計算類別里。TC0 就像是一個只能用固定步驟解決問題的工具箱,遇到某些複雜任務時就顯得力不從心。
而RWKV-7可以用固定的層數(也就是固定的計算步驟)處理所有正則語言。這意味著,不管語言規則有多複雜。
這個能力聽起來很理論,但實際上特別有用。RWKV-7 能更高效地解決一些需要「跟蹤狀態」的問題。什麼是「跟蹤狀態」呢?舉個例子:
在讀一個長故事時,記住誰做了什麼、事情是怎麼發展的;
在理解一句複雜句子時,搞清楚每個詞之間的關係。
這些任務需要模型一邊讀一邊更新自己的「記憶」。RWKV-7 靠它的「狀態矩陣」來做到這一點。你可以把「狀態矩陣」想像成一個記事本,模型會在這上面記下看到的信息,還能靈活地「交換」信息或者改變記錄的方式(專業點叫「狀態轉換函數」)。
Hugging Face上的RWKV Gradio Demo提供了0.1B模型的交互體驗
應用方面,RWKV-7適用於語言建模和多模態應用,其高效處理長上下文的能力使其在文檔摘要、對話系統和代碼生成等領域具有優勢。其無注意力機制和恒定內存使用也使其適合資源受限的設備,潛在擴展到邊緣計算場景。
RWKV-7開發團隊已規劃了明確的技術發展方向,計劃通過擴充訓練數據集來支持更大規模模型的訓練,同時將致力於增強模型的思維鏈推理能力。
團隊還將評估採用DeepSeek近期研究中驗證有效的前沿技術,包括混合專家模型(MoE)架構、多token預測技術和FP8精度訓練等優化方案。
為了促進開放性、可複現性和採用,RWKV-7開發團隊在Hugging Face上發佈了模型和數據集組件列表,並在GitHub上發佈了訓練和推理代碼,所有這些資源均在Apache 2.0許可下提供,允許廣泛應用於研究和商業項目。
超越Transformer
Transformer廣泛用於自然語言處理和其他領域,但它在處理長序列時存在顯著的局限性。例如,對於百萬級別的上下文窗口,Transformer 的性能會顯著下降,限制了其在實際應用中的可擴展性。對於需要低延遲或在資源受限設備上運行的場景(如移動設備或實時系統),Transformer 的高計算成本和內存消耗成為瓶頸。
Mamba是另一個獲得相當多關注的 Transformer 替代方案,Transformer 如此流行,以至於提出它們的原始論文自發表以來的 8 年間獲得了超過 17.1 萬次引用,而提出 LSTM 的 1997 年論文則有 12.2 萬次引用。Mamba 論文有 2537 次引用,RetNet 有 350 次,xLSTM 有 31次,RWKV論文有510次引用,而GoogleDeepMind最新提出的Titans架構只有12次引用。
類似RWKV-7這樣的發展,即使還不會完全顛覆現有的範式,也會推動這一領域的進一步發展,AI的未來不僅將由更大的模型塑造,還將由更智能的架構設計引領。