OpenAI深夜緊急直播狙擊Google,新GPT-4o圖像生成免費用,文本控制更準,Altman自製AGI梗圖
智東西3月26日報導,今日淩晨1點,Google發佈Gemini 2.5思考模型家族首個Gemini 2.5 Pro實驗版本,大約一小時後,OpenAI創始人兼CEO薩姆·阿爾特曼就開直播發佈了迄今為止最先進的圖像生成器GPT-4o圖像生成技術。
這也是ChatGPT生成功能一年多後的首次重大升級,更新點在於可以遵循指令生成更準確的圖像,OpenAI還為其掛載了固有知識庫,可以根據知識庫或上下文幫用戶生成、編輯圖像。
阿爾特曼在直播里現場自拍生成了一張AGI梗圖,最右側的就是阿爾特曼。

阿爾特曼還發了一篇小長文談了自己的感想,第一點他談到看到這個模型產生的第一批圖像,「很難理解它們真的是由AI製作的」,第二點他提到了這一模型的風險,其拉高了創作自由的水平線,OpenAI將知識自由和控制權交到用戶手中,他們認為尊重社會最終會選擇為AI設定的非常寬泛的界限是正確的做法。

今天起,GPT-4o圖像生成已經作為ChatGPT中的預設圖像生成器向Plus、Pro、Team和免費用戶陸續推出,企業和教育用戶將很快允許訪問。這項功能也可以在Sora中使用、或者通過專用的DALL·E GPT訪問。開發人員很快將能夠通過API使用GPT-4o生成圖像,並在未來幾週內推出訪問權限。
與作為擴散模型運行的DALL·E根本區別是,GPT-4o圖像生成是原生嵌入在ChatGPT中的自回歸模型。 OpenAI根據在線圖像和文本的聯合分發來訓練模型,使得模型可以學習圖像與語言的關係,使其生成有用、一致且具備上下文感知的圖像。
不過,OpenAI的博客提到,因為這個模型會創建更詳細的圖片,所以圖像需要更長的渲染時間,通常會達到一分鐘。
01.可生成手寫體文字、圖像編輯、照片級質感,還能利用知識庫做海報
OpenAI在官方博客中發出了不少GPT-4o的生圖案例。
其中一個提示詞是「用手機拍攝的玻璃白板的廣角圖像,位於俯瞰海灣大橋的房間里。視野顯示一名女性正在寫作,她穿著一件帶有大型OpenAI標誌的T恤。筆跡看起來很自然,有點淩亂,我們看到了攝影師的倒影」,提示詞後文還附上了需要在白板上出現的文字。
GPT-4o生成的圖像考慮到了每個細節:白板上的文字、主角的衣服、背影的海灣大橋、攝影師。

第二個提示詞是:「攝影師的自拍照片,她轉身與他擊掌。」圖像中,兩位主角的動作發生變化後,白板上的人物倒影也對應發生變化,其餘文字、海灣大橋的倒影沒變。

下一個提示詞中主要生成的內容是「兩個20多歲的女巫閱讀路標的照片級實感圖像」。並附上了上下文對圖像中路牌上的內容、周圍環境的信息進行了補充,並給出了從背景到前景的人物與其他物體位置關係。在生成的結果中, 女巫形象、周邊環境等的信息都基本符合需求。

還有更為實用的場景是,讓GPT-4o生成菜單,提示詞中除了需要包含的菜品、價格及簡介外,還需要生成的圖像中包含這家餐廳的名稱、主要亮點以及菜單風格。

此外,用戶還可以通過自然對話進一步優化圖像。
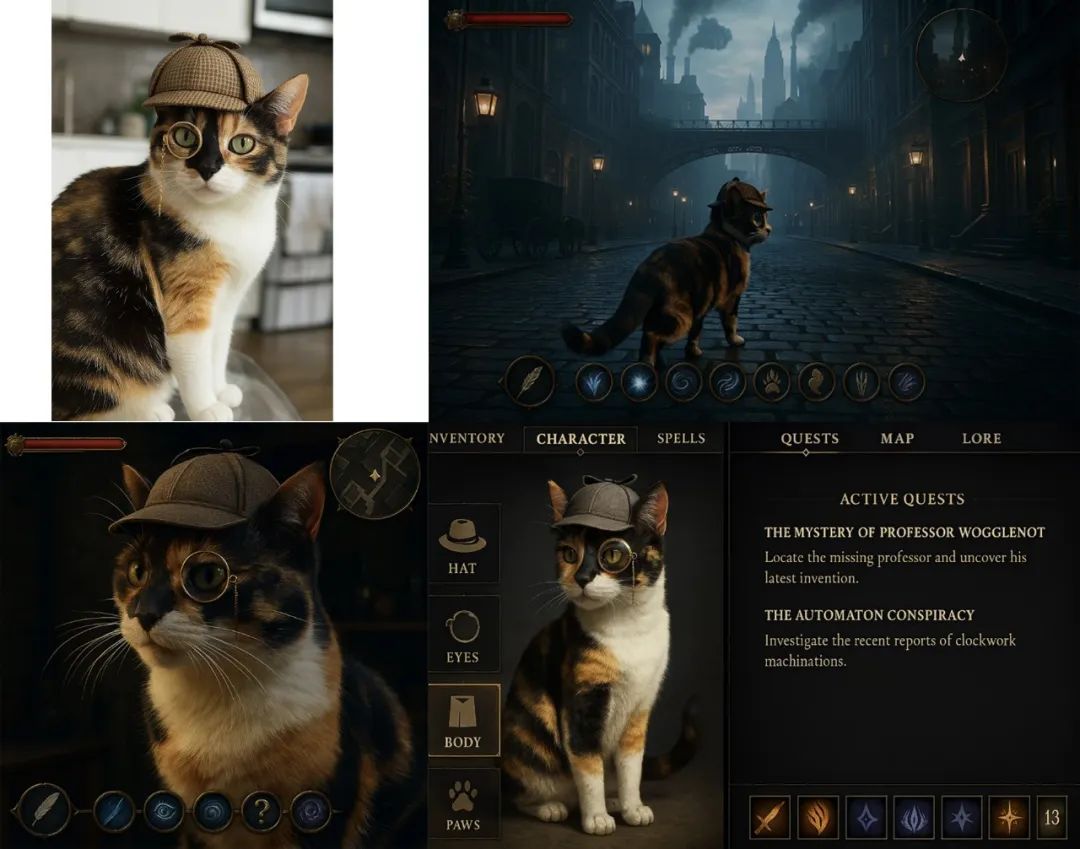
例如設計以一隻貓為原型的電子遊戲。可以先創建主要角色,上傳一隻貓的圖片並為其添加偵探帽和單片眼鏡,然後通過生成以這隻貓為主的遊戲界面、場景、用戶界面等。
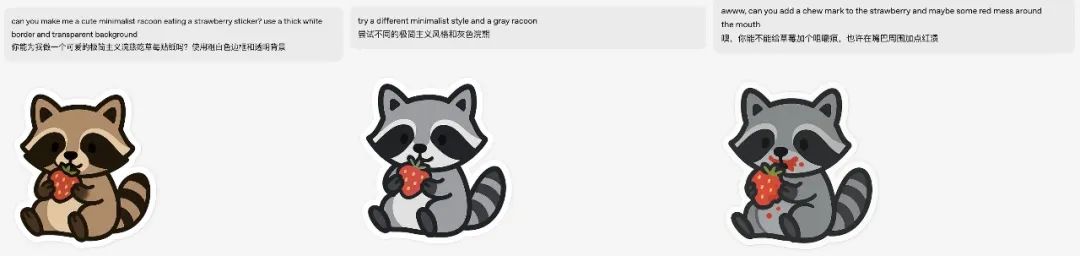
其次是貼紙,生成極簡主義小浣熊吃草莓的貼紙,粗白色邊框和透明背景,然後換風格改灰色浣熊、添加小浣熊正在吃草莓的細節。
GPT-4o的圖像可以遵循詳細的提示,如處理多達10-20個不同的對象。下面給出了16個對象,GPT-4o生成了對應的圖像。

GPT-4o可以分析和學習用戶上傳的圖像,將其詳細信息無縫集成到其上下文中,為圖像生成提供信息。
例如下面的提示詞是基於一些參考圖,生成三角形車輪的車輛繪製設計圖,其生成圖像的風格與參考圖類似,且附上了提示詞中的重要部件、專利等信息。第二輪提示詞將其放到紐約市的場景中,基本信息也並沒有丟失,並與周圍環境進行了融合。

GPT-4o還可以將其知識與文本、圖像聯繫起來。如給出包含4種最受歡迎的雞尾酒的手寫卡片、製作視覺信息圖說明為什麼舊金山霧氣大等。

02.自回歸模型為生成模型引入新風險,編輯一致性、幻覺、多概念呈現仍需改進
因為GPT-4o圖像生成是原生嵌入在ChatGPT中的自回歸模型,這引入了一些不同於以前生成模型的新功能,並帶來了新的風險:
圖像到圖像轉換:此功能允許GPT-4o圖像生成將一個或多個圖像作為輸入,並生成相關或修改的圖像;
照片真實感:GPT-4o圖像生成的高級照片級真實感功能意味著其輸出在某些情況下可以具有照片的外觀;
指令遵循:GPT-4o圖像生成可以按照詳細的說明,並呈現文本和指令圖,引入與早期模型不同的實用性和風險。
目前,OpenAI研究人員已經發現其生成圖像方面的局限性:
圖像方面,GPT-4o有時會對海報等較長的圖片裁剪得過於緊湊;模型難以保持對用戶上傳的人臉的編輯一致性;用戶編輯圖像生成的如拚寫錯誤的特定部分的請求並不總是有效的,並且還可能以未請求的方式更改圖像的其他部分或引入更多錯誤;GPT-4o難以依賴於知識庫的一次準確呈現10-20多個不同的概念,例如完整的元素週期表。
此外,其在生成圖像方面也會存在幻覺,在上下文信息較少的提示情況下,圖像生成功能可能會編造信息,以及在複雜度高的情況下,模型難以渲染菲拉丁語言,並產生錯誤的字符。
其博客提到,對用戶上傳的人臉的編輯一致性的錯誤將在一週內得到修復。
在研究過程中,為瞭解決GPT-4o圖像生成帶來的獨特安全挑戰,OpenAI使用了多種緩解策略:
聊天模型拒絕:在ChatGPT和API中,主要聊天模型充當第一道防線,防止生成違反相關政策的內容。根據其訓練後的安全措施,聊天模型可以根據用戶的提示拒絕觸發圖像生成過程。
提示阻止:此策略在調用GPT-4o圖像生成工具後發生,包括在文本或圖像分類器將提示標記為違反我們的策略時阻止該工具生成圖像。通過正選製人地識別和阻止提示,此措施有助於防止生成不允許的內容。
輸出屏蔽:此方法在生成圖片後應用,它結合使用多種控制措施,包括兒童性虐待材料(CSAM)分類器和以安全為中心的推理監控器,以屏蔽違反政策的圖片輸出。該監控器是一個多模態推理模型,經過自定義訓練,可以對內容政策進行推理。通過評估生成後的輸出,從而提供額外的保護措施,防止用戶創建不允許的內容。
加強對未成年人的保護措施:OpenAI使用上面列出的所有緩解措施為未滿18歲的用戶創造更安全的體驗,並設法限制這些用戶創建某些類別可能不適合年齡的內容。目前禁止13歲以下的用戶使用OpenAI的任何產品或服務。
03.結語:圖像生成模型再進化
圖像生成模型此前在文字生成、對需求的準確理解上都有一定局限性,這也是當前多模態模型企業們重點突破的方向。此次,GPT-4o的圖像生成能更精確地遵循指示、渲染文字,還支持多輪迭代優化圖像時保持角色形像一致,在圖像生成的質量上實現了提升。
不過,從目前的生成結果來看,GPT-4o的圖像生成還存在幻覺、裁剪不當、編輯無法保持一致性等問題,這也是OpenAI後續研發的方向。
本文來自微信公眾號「智東西」(ID:zhidxcom),作者:程茜,編輯:心緣,36氪經授權發佈。