淩晨「激戰」!Google亮相新模型,OpenAI 緊急甩出 GPT-4o 動動嘴就能 P 圖,網民:又要感謝 DeepSeek 了

整理 | 冬梅
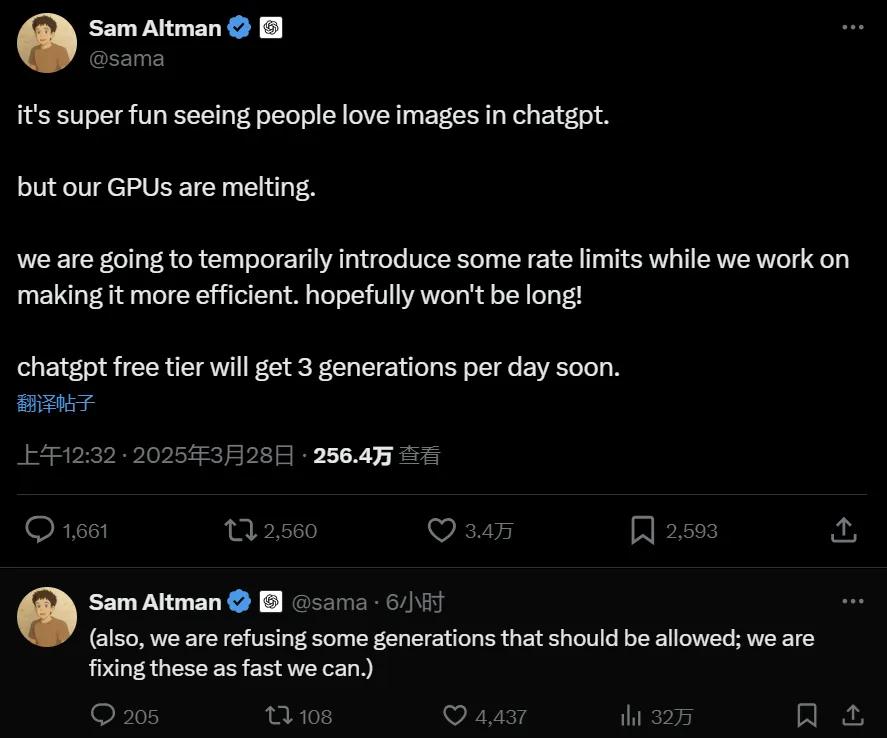
香港時間 3 月 26 日淩晨,Google發佈了號稱最強推理模型的 Gemini Pro 2.5,而在Google之前,OpenAI 率先開了場直播,發佈了 GPT-4o image generation,圖像生成技術模型。有趣的是,最近半年時間里,基本上Google的每次發佈都會與 OpenAI 的直播「撞車」。
OpenAI 放出 GPT-4o
原生多模態圖像生成功能
OpenAI 表示:「從今天開始,OpenAI 將新的圖像生成功能直接集成到 ChatGPT 中——該功能被稱為‘ChatGPT 中的圖像’。用戶現在可以使用 GPT-4o 在 ChatGPT 內部生成圖像。」
此初始版本僅專注於圖像創建,並將在 ChatGPT Plus、Pro、Team 和 Free 訂閱層中提供。
值得注意的是,GPT-4o 圖像生成標記器詞彙量(實際上是用於表示文本的唯一整數的數量)已從 GPT-4 和 GPT-3.5 的約 10 萬個增加到約 20 萬個。古吉拉特語輸入使用的標記減少了 4.4 倍,日語減少了 1.4 倍,西班牙語減少了 1.1 倍。以前,除英語以外的其他語言在提示中可以容納多少文本方面會付出實質性的代價。
同樣值得注意的是價格。OpenAI 聲稱與 GPT-4 Turbo 相比,價格降低了 50%。更直觀的對比是, GPT-4o 成本恰好是 10 倍 GPT-3.5;4o 是 5 美元 / 百萬輸入 token 和 15 美元 / 百萬輸出 token。3.5 是 0.50 美元 / 百萬輸入 token 和 1.50 美元 / 百萬輸出 token。
價格下降尤其引人注目,因為 OpenAI 承諾也將向免費 ChatGPT 用戶提供該模型——這是他們第一次直接向非付費客戶提供「最佳」模型。
OpenAI 研究負責人 Gabriel Goh 在接受媒體採訪時表示:「該模型比以前的模型有了很大的改進」,並補充說,團隊使用了 GPT-4o「全模態」——一種可以生成任何類型數據(如文本、圖像、音頻和影片)的模型——作為該功能的基礎。
OpenAI 在公告中表示,GPT-4o 圖像生成功能具有以下特點:
-
精準渲染圖像尼雲字,能夠製作 logo、菜單、邀請函和信息圖等;
-
精確執行複雜指令,甚至在細節豐富的構圖中也能做到;
-
基於先前的圖像和文本進行擴展,確保多個交互之間的視覺一致性;
-
支持各種藝術風格,從寫實照片到插圖等。
先來感受下生成圖片的效果怎麼樣。
OpenAI 在官方示例展示時放出了一張女士背對著鏡頭在白板上寫字的圖片。

圖片看起來就是很日常的生活照片,但實際上,它是由 GPT-4o 生成的 AI 圖片,OpenAI 給出的提示詞如下 :
「在俯瞰海灣大橋的房間中,使用手機拍攝玻璃質地白板獲得的寬幅圖像。畫面中一位女性正在寫字,身著帶有顯眼 OpenAI 標誌的 T 恤。筆跡自然且略帶淩亂,白板上投射出攝影師的身影。」
接下來第二張圖片轉了人物朝向,以攝影師的自拍角度,畫面中的女性轉向與他擊掌,生成的圖像還是完全看不出出自 AI。

還能生成四格連環畫,邊框與畫面邊緣間注意留白。提示詞如下:
「一隻小蝸牛身在華麗的汽車展廳櫃檯上,推銷員俯下身來才能看到他。特定鏡頭中,蝸牛表情嚴肅,說‘我想要你們最快的跑車……還得在車門、引擎蓋和車頂位置畫上大寫的「S」。’
銷售員撓撓頭,‘呃……當然沒問題。不過為什麼是「S」?’
畫面切換到時一輛紅色汽車在高速公路上呼嘯而過,車身上寫滿巨大的「S」。路旁的人們指指點點,笑著說,‘WOW! LOOK AT THAT S‑CAR GO!’」

生成一張詳細解釋牛頓棱鏡實驗的信息圖。
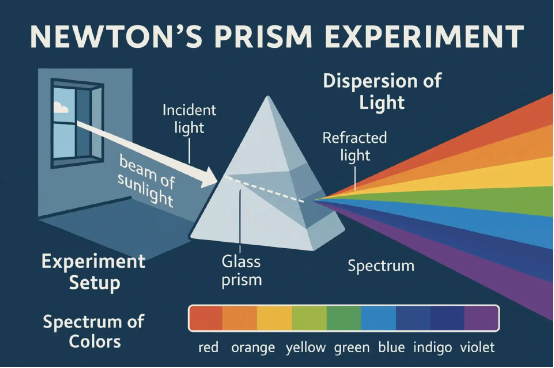
然後,現在生成一個人在華盛頓廣場公園的一張圖形咖啡桌旁,用筆記本繪製這張圖的第一人稱畫面。

然後,現在在同一場景下,顯示難掩興奮的年輕牛頓坐在桌旁,手持棱鏡演示實驗結果,注意畫面中不要出現筆記本。

多項功能迭代,
生成圖像效果更佳
據 OpenAI 官方說明,GPT-4o 在多個方面相較於過去的模型進行了改進:
-
更好的文本集成:與過去那些難以生成清晰、恰當位置文字的 AI 模型不同,GPT-4o 現在可以準確地將文字嵌入圖像中;
-
增強的上下文理解:GPT-4o 通過利用聊天歷史,允許用戶在互動中不斷細化圖像,並保持
-
改進的多對象綁定:過去的模型在正確定位場景中的多個不同物體時存在困難,而 GPT-4o 現在可以一次處理多達 10 至 20 個物體;
-
多樣化風格適應:該模型可以生成或將圖像轉化為多種風格,支持從手繪草圖到高清寫實風格的轉換。
OpenAI 表示,從第一幅洞穴壁畫到現代信息圖,人類一直在使用視覺圖像進行交流、傳達與分析。如今的生成模型可以呈現出超現實、令人驚歎的場景,但卻難以處理人們用於分享和創建信息的實用性圖像。事實上從徽標到圖表,基於共同語言和經驗相關符號的圖像往往可以傳達精確的表達含義。
GPT-4o 圖像生成善於準確地呈現文本、精確遵循提示詞,並運用 4o 固有的知識庫與聊天上下文——包括直接轉換上傳的圖像,或將其作為視覺創作靈感。這些功能可輕鬆創建大家設想的圖像,幫助用戶通過視覺效果實現順暢交流,並將圖像生成真正轉化為具備精確性與強大現實意義的實用性工具。
利用在線圖像與文本內容共同訓練模型,GPT-4o 圖像生成不僅學習到圖像與語言的內部關聯,還掌握了二者之間的對應關係。結合積極的後訓練設計,生成模型獲得了令人驚喜的視覺流暢性,能夠生成高度實用、一致且具備上下文感知特徵的圖像。
正所謂一圖勝千言,但有時在正確位置添加寥寥數語即可顯著提升圖像的表達效果。4o 將精確符號與圖像融合起來,使得圖像生成真正具備了視覺交流屬性。
OpenAI 放出了一些官方示例。
創建一張逼真的圖像,畫面中兩名 20 多歲的女巫(一名有著灰色挑染頭髮,另一名有著赤褐色波浪長髮)正在閱讀路牌。
提示詞:
紐約威廉斯堡一條街道上,路牌中展示大量詳盡的街道標誌(例如街道清掃時間、停車許可要求、車輛分類、拖車規則),其間還有一些架空信息(以合法的街道標記形式呈現),如「C 區禁止停泊女巫掃帚」、「僅允許魔毯卸貨(不超過 15 分鐘)」以及「僅允許馴鹿憑許可臨停(12 月 24 日至 25 日),違規者將被列入淘氣名單。」路標位於街道右側,內容不可重覆,標誌必須真實還原。
人物:一名女巫手持掃帚,另一名抱著捲起的魔毯。二人在前景中,背對畫面,頭部稍微傾斜並認真觀看路牌。背景到前景的構圖:街道 + 停放的車輛 + 建築物——>路牌——>女巫。人物必須在距離鏡頭最近的位置。

多輪生成
如今圖像生成已經成為 GPT-4o 中的原生功能,因此用戶可以通過自然對話實現圖像內容優化。GPT-4o 可以在聊天環境中基於圖像和文本構建而成,確保內容始終保持一致。例如,如果用戶正在設計一位電子遊戲角色,那麼在持續改進與試驗過程中,該角色的外觀將在多輪迭代中保持一致。
在電子遊戲場景中,參考輸入的小貓圖像,為小貓添加一頂偵探帽和一副單片眼鏡。


將畫面轉化為使用 4k 遊戲引擎製作的 3A 電子遊戲風格畫面,並添加用戶界面元素以呈現類似 RPG 遊戲的疊加圖層。頂部有生命欄和小地圖,下方則是風格一致的咒語圖標。

將畫面更新為 16:9 橫向圖像,在 UI 中添加更多咒語元素,並縮小生成的小貓以通過第三人稱視角觀看其穿過蒸汽朋克風格的曼哈頓街頭。注意使用 3A 遊戲中常見的漂亮對比與光照效果,使用冷色調。
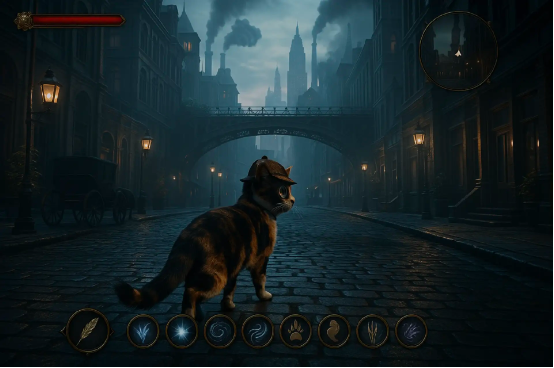
創建界面,當玩家打開菜單時顯示小貓的角色資料和裝備,另一頁顯示當前任務(任務內容應與圖像中呈現的世界觀保持關聯)。
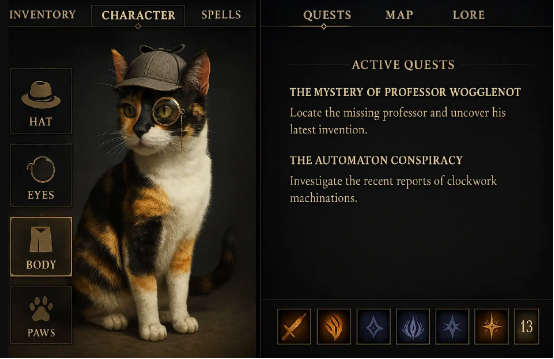
遵循指令
GPT-4o 的圖像生成功能可遵循詳盡提示詞並始終關注細節。其他系統在處理包含 5 到 8 個對象的畫面時往往表現不佳,而 GPT-4o 能夠處理多達 10 到 20 個不同對象,同時更好地控制各對象、其特徵及彼此關係之間的緊密綁定。
生成一幅正方形圖像,包含一個 4 行、4 列的網格,共包含 16 個對象,背景為白色。從左至右、從上到下,各對象依次為:
-
一顆藍色星星
-
紅色三角形
-
綠色正方形
-
粉色圓形
-
橙色沙漏形
-
紫色無窮符號
-
黑白圓點領結
-
紮染紋理的「42」數字
-
一隻戴著黑色棒球帽的橙色貓
-
一張帶有寶箱的地圖
-
一雙大眼睛
-
豎起大拇指的表情符號
-
一把剪刀
-
一隻藍白相間的長頸鹿
-
用草體書寫的「OpenAI」單詞
-
一道彩虹色閃電

寫實主義與圖像風格
通過在訓練中納入反映多種圖像風格的素材,4o 模型能夠逼真地生成或轉換圖像。
一張狗仔隊偷拍風格的照片,畫面中卡爾·馬克思匆匆走過美國購物中心的停車場,他回頭一看,臉上帶著驚恐的表情,不想被偷拍騷擾。他手裡抓著幾個裝滿奢侈品的閃亮購物袋。他的外套在風中飄揚,其中一個袋子在擺動,好像他正在大步走。模糊的背景,汽車和發光的購物中心入口,以強調運動。相機的發亮燈部分曝光過度,給人一種地下小報的感覺。

儘管生成的圖片生動又逼真,但 OpenAI 也坦言,這些模型並不完美,目前也發現其存在的諸多局限性。OpenAI 將在先期發佈之後,通過不斷改進來解決這些問題。
在接受媒體採訪時 Goh 也提到,「歸根結底,沒有一個系統是完美的,但我們正在不斷改進我們的保障措施,我們認為這是一個起點。ChatGPT 生成的所有圖像都有一個共同點,那就是用戶擁有它們,並可以在我們的使用政策範圍內隨意使用它們。」
此外,OpenAI 支持生成公眾人物形象和不符合歷史但用戶指定的圖片。


此次更新,OpenAI 比以往更加關注安全性。
OpenAI 稱,「根據模型規範,我們希望通過支持遊戲開發、歷史探索和教育等具有現實價值的用例以最大限度提升創作自由,同時保持嚴格的安全標準。換言之,阻止違規請求是保障制度落實的必要前提。我們正努力通過以下手段保障安全且高度實用的內容,同時支持用戶借助創意廣泛表達自己的靈感與思路。」
首先,通過 C2PA 與內部可逆搜索進行溯源。目前,生成的所有圖像均帶有 C2PA 元數據,用於註明圖像來自 GPT-4o 以保證公開透明。此外,OpenAI 還構建了一款內部搜索工具,其使用生成技術屬性以幫助驗證內容是否來自我們的模型。
其次,OpenAI 稱會堅決屏蔽不良內容。將繼續阻止可能違反內容政策的生成圖像請求,例如兒童性虐待素材與深度偽造色情圖像。對於上下文內的真人圖像,OpenAI 會加強對於所能創建圖像的限制,並對裸露及暴力畫面採取極其嚴格的處理措施。當然,安全升級永遠不會結束,也將成為持續投資的重要領域。
第三,使用推理增強安全性。OpenAI 已經訓練了一套推理大模型,負責根據人類編寫的可解釋安全規範識別並解決政策中的歧義。結合 ChatGPT 與 Sora 所使用的多模態安全技術,得以根據現有政策靈活調整輸入文本與輸出圖像。
但目前儘管 4o 圖像生成技術在性別表現的多樣性上超過了 DALL·E 3,但輸出結果仍然主要偏向男性主體。因此,OpenAI 表示其未來的工作將著重於提高數據均衡性,讓模型更加公平。
訪問方式與上線時間
作為 ChatGPT 中的預設圖像生成工具,4o 圖像生成功能從即日起開始向 Plus、Pro、Team 及 Free 用戶全面開放。Enterprise 及 Edu 訪問權限將後續開放。Sora 也可享受到此次功能升級。對於希望繼續使用 DALL-E 的用戶來說,則可通過專門的 DALL-E GPT 訪問這項新功能。
開發人員很快就能通過 API 使用 GPT-4o 生成圖像功能,訪問權限將在未來幾週內開放。
OpenAI 表示,整個圖像創建與自定義過程,就像與 GPT-4o 聊天一樣簡單——只需描述你的需求,包含畫面比例、使用十六進製代碼的精確色彩或透明背景等細節即可。由於此模型能夠生成涉及更多細節的圖像,因此渲染時間可能更長,最多可能達到 1 分鐘。
參考鏈接:
https://openai.com/index/introducing-4o-image-generation/
聲明:本文為 AI 前線整理,不代表平台觀點,未經許可禁止轉載。