傳神語聯發佈深度思考大模型-T1:根原創鑄基, 任度雙腦開啟AI深度思考新高度
2025年3月24日,傳神語聯A紀元系列線上發佈活動的第一天,傳神語聯重磅發佈任度雙腦深度思考大模型-T1(以下簡稱任度大模型-T1),為大模型領域貢獻了又一創新性成果。
那麼,你或許會好奇,在大模型層出不窮的今天,傳神語聯為什麼還執著於推出大模型?底氣來自哪裡?跟隨數據猿主編張豔飛、傳神語聯創始人何恩培、傳神語聯研究院院長何征宇在3月24日的線上發佈,一起揭秘。
大模型先行者:用根原創奠定底氣
張豔飛:在當前市面上已有眾多如DeepSeek、千問、豆包等大模型的情況下,為什麼你們還要入局?
何恩培:我們並非剛剛入局。早在GPT火起來之前,我們已經在法律、語言服務等領域研究和應用大模型技術。去年5月份,OpenAI的Sam Altman提到在GPT5、GPT6中將數據和推理做分離,這一點還是刺激了我,因為我們已經實現了技術,我覺得還應該更自信一點站出來。因為我們主要TOB,沒有做過什麼公開發佈,於是我們在2024年11月正式發佈了任度雙腦大模型。最新的深度思考版本T1早在2月就出來了,只是在傳神A紀元一週年向大家公開發佈,進一步鞏固我們在大模型領域的技術優勢。
張豔飛:那數推分離技術,就是你們敢於和大廠PK的底氣嗎?
何恩培:準確的說我們的底氣來自根原創,這是我們過去、現在以及未來所有創新的基石和底氣。我們從底層算法框架到模型架構,完全自主研發,且通過了中國信通院0開源依賴的驗證,做到了完全獨立自主。當然更重要的是「根原創」技術還做到了「更先進」,我們一次次走在大模型時代的前列,驗證了我們的技術先進性,這才是真正的底氣。
當然,數推分離是我們的大模型的架構設計。基於數推分離架構,任度大模型-T1實現了「雙腦」聯合推理,以僅9B的小參數規模實現了大智能,性能可媲美參數量為其幾十倍,甚至一兩百倍的大模型。同時,基於此架構,我們的大模型成長出了實時學習、長效記憶能力,可以實現數據不離場(私域)、無需專業技術人員情況下與企業數據深度融合,並可以持續實時學習客戶新數據。
真正的深度思考,實現AI革命性突破
張豔飛:看來,任度大模型-T1確實有自己的獨特能力,那體現在哪些方面呢?
何征宇:任度大模型-T1在繼承任度雙腦大模型實時學習、長效記憶、高性參比等核心能力的基礎上,實現了在深度思考、高效能等多維度上的新突破,解決了當前AI如何具備真正的結構化思考能力、如何降低模型部署能耗和成本、如何確保數據安全與可控等諸多行業問題,是企業數字化轉型的理想選擇。
總結來說,任度大模型-T1依託自研的zANN神經網絡架構,做到像人類一樣深度理解並處理信息,實現複雜邏輯推理和抽像思考。
現在,為大家帶來一些詳細的展示。
結構化思考:推理更透明、更高效。任度大模型-T1能夠將複雜問題分解為多個邏輯清晰的步驟,並逐步分析和解決。其思考過程更加透明和可解釋,不再是難以理解的「流水賬」形式。例如,在解決數學問題時,任度大模型-T1會從問題分析、已知信息提取、列方程組到最終求解,每一步都清晰可見。不僅讓用戶更容易理解模型的推理過程,還顯著提升了問題解決的效率和準確性。
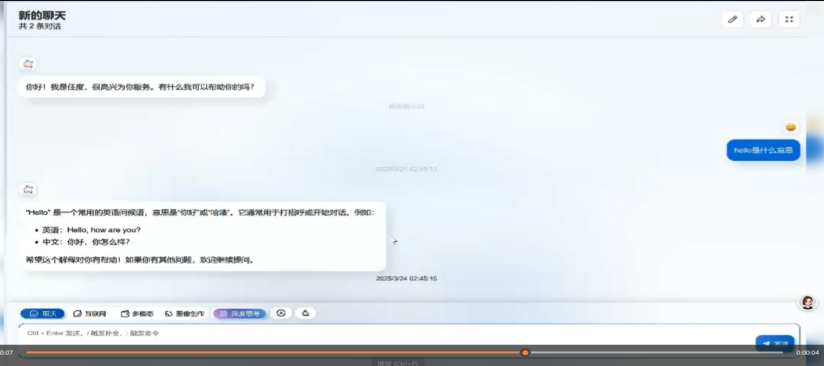
智能判斷:簡單問題直接解決,複雜問題深度思考。任度大模型-T1能夠自動識別問題的複雜度。對於簡單問題,直接給出答案,避免了不必要的深度思考過程。例如,當被問及「hello」是什麼意思時,任度大模型-T1會直接給出答案,而不會啟動複雜的深度思考流程。相比之下,不少大模型即使面對簡單問題,仍然會進行複雜的思考過程,效率低、能耗高。
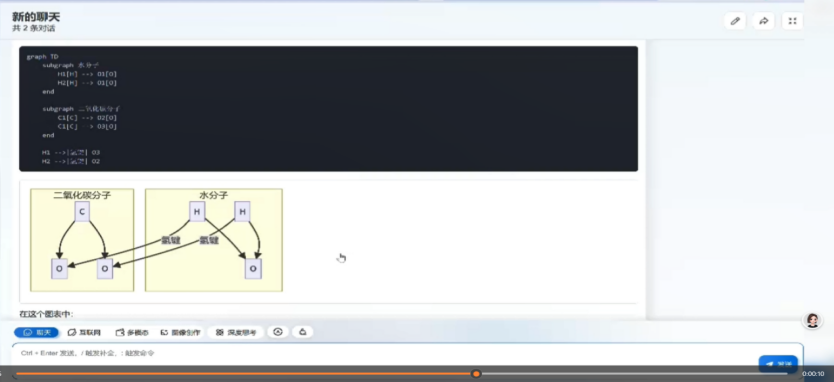
圖形化展示:直觀清晰,易於理解。任度大模型-T1在輸出結果時,採用了圖形化展示的方式,讓複雜的信息更加直觀和易於理解。例如,當被要求分析水分子和二氧化碳分子的關係時,任度大模型-T1會直接以圖示的方式呈現,不僅讓用戶一目瞭然,還顯著提升了信息的傳達效率,而不少大模型只能以代碼或文字形式進行描述。
多場景應用落地,重構企業智能生產力
張豔飛:行業應用是檢驗大模型能力的試驗田,任度大模型-T1現在的應用落地情況如何?
何恩培:基於深厚的數據應用能力,任度大模型-T1在航天航空、生物醫藥、金融、法律等多個領域,已經形成了典型案例,展現了強大的數據處理和分析能力。
張豔飛:那具體來聊一下,比如,現在醫學科研的比較火熱的方向當中, AI For Science是十分典型的,任度大模型-T1有沒有案例可以分享下?
何恩培:AI For Science是我們重點且擅長的領域,比如我們與全球頂尖的幹細胞科學家合作,構建幹細胞綜合研究大模型,進行幹細胞綜合研究,並開發麵向健康伴侶的端側小模型——「為能」,將幹細胞生物治療和人工智能有機結合,實現發現-診斷-分析研究-治療方案全健康鏈的大模型賦能。
張豔飛:聽說你們也接入了DeepSeek?你們是怎麼考慮的?
何征宇:準確的說不是「接入」DeepSeek,而是推出了首義任度雙腦一體機,深度融合了任度雙腦9B大模型、DeepSeek-R1 671B大模型的能力,幫助企業形成知識沉澱-分析-決策的閉環。我們是從多個角度考慮的。對用戶來說,他們有選擇使用哪個大模型的自由度。但同時,用戶也需要保障自身數據的安全可控。因此,我們推出了雙模型一體機,這樣一來,敏感數據層使用任度大模型,應用層則可以選擇DeepSeek或其他大模型,確保數據安全和業務靈活性。
繪製智能時代新藍圖,技術共建安全生態
張豔飛:你們對未來的展望是什麼?
何恩培:在業務定位上,傳神有根原創的深度學習框架和模型架構,這非常利於我們向兩個方向發展,一個是為科學研究賦能,也就是正在流行的方向AI FOR SCIENCE,一個是向端側發展,實現從萬物互聯到「萬腦互聯」,讓人工智能賦能服務我們生活每個角落。從產業生態上我們正在聯合一些原創公司發起原創聯盟,向合作夥伴開放技術,共同構建國產原創的AI研究和應用生態,通過自主研發和根原創技術,擺脫對國外技術的依賴,確保核心技術的自主可控,為國家構建一個安全、可靠的AI生態體系。
任度雙腦深度思考大模型-T1的發佈,不僅是對參數競賽時代的終結宣言,更是開啟AI”質效革命”新紀元的里程碑。我們堅信,任度雙腦深度思考大模型-T1將進一步展現出差異化競爭優勢,以超強的性能,卓越的深度思考能力,成為企業數字化轉型的新質生產力。