以一敵五、屠榜登頂的GoogleGemini 2.5,居然栽在小學數學題上
今天淩晨,大洋彼岸可真夠熱鬧的。
OpenAI推出了GPT-4o動嘴生圖、P圖的功能,而Google則直接祭出了號稱「最智能的模型」Gemini 2.5。
據Google首席科學家Jeff Dean介紹,首個版本Gemini 2.5 Pro Experimental已集成「思考能力」,是迄今為止性能最強大的Gemini模型,尤其擅長高級推理和編碼,並在@lmarena_ai排行榜上拿下第一。

到底有多智能?
先來欣賞幾個官方給出的demo。
Prompt:p5js to explore a Mandelbrot set。
提示詞:用p5.js探索曼德博集合。
Prompt:Create an animated bubble chart using Plotly Express of how economic and health indicators have evolved over the years for each continent.
提示詞:使用Plotly Express創建動畫氣泡圖,展示各大洲經濟和健康指標隨時間變化。
Prompt:Make me a captivating endless runner gameKey instructions on the screen.p5js scene,no HTML.l like pixelated dinosaurs and interesting backgrounds.
提示詞:用p5.js創作一個迷人的無盡跑酷遊戲,畫面上有關鍵操作提示。場景像素風,主角是恐龍,背景要有趣。
Prompt:Create a beautiful,interactive p5js demo(no HTML).l like fish and nebulaeShow me what the fish are thinking.
提示詞:用p5.js做個好看的互動演示,別用HTML。我喜歡魚和星雲,能不能展現出魚的想法。
Prompt:p5.js(no HTML)swarm of 30 colorful boids swimming inside a rotating hexagon.like supernova nebulae.
提示詞:用p5.js做一個無HTML的演示:30只彩色的「boids」在一個旋轉的六邊形內遊動,效果像超新星星雲。
效果甚是驚豔。
而且Google一出手就是免費!
現在普通用戶可以在AI Studio中免費使用Gemini 2.5 Pro,Gemini App中的Gemini高級用戶也能使用它。
鏈接直達:http://aistudio.google.com/app/prompts/
一手實測
現在只要發佈新模型,言必稱自家的最智能、最強大,然後佐以各種跑分結果。
對於普通用戶來說,分數、排名都不重要,真正重要的是,它在實際生活中到底好不好使。
既然Google稱Gemini 2.5是目前地表最強,那我們就來場大亂鬥,將它和o3-mini、GPT-4.5、Claude3.7 Sonnet、Grok3、DeepSeek R1拉出來同台競技。
1. 一根10米長的竹竿能通過高4.5米、寬3.8米的城門嗎?
如果按照常規的數學邏輯來思考,10米長的竹竿確實無法通過這個尺寸的城門,但是在現實生活中,我們可以讓竹竿與地面平行穿過城門。
萬萬沒想到,這麼一道簡單的竹竿過城門,讓這群曾號稱最強的大模型全軍覆沒。
它們不約而同地想到了勾股定理,也把數值算對了,卻忽略了現實是個三維空間。

來看看各家大模型的具體表現。
Gemini 2.5:
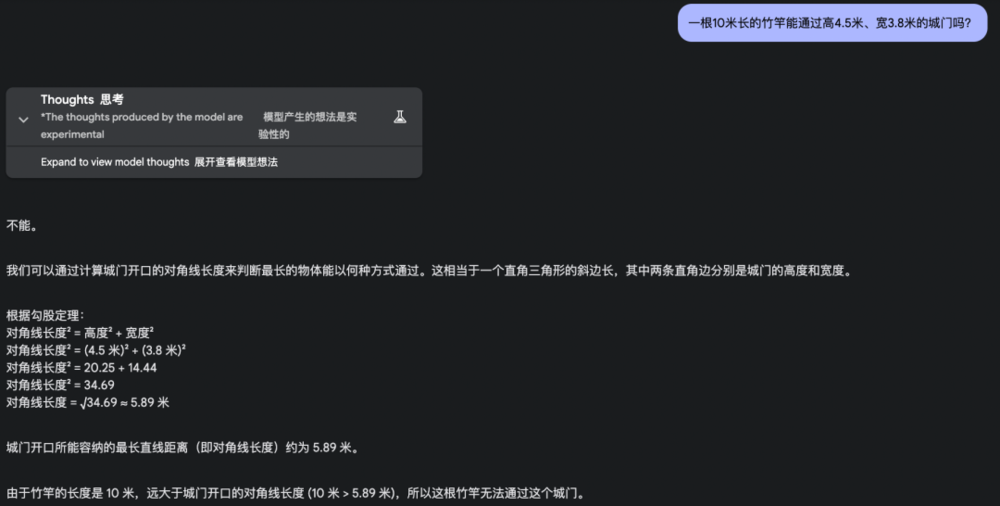
o3-mini:

GPT-4.5:

Claude 3.7 Sonnet:
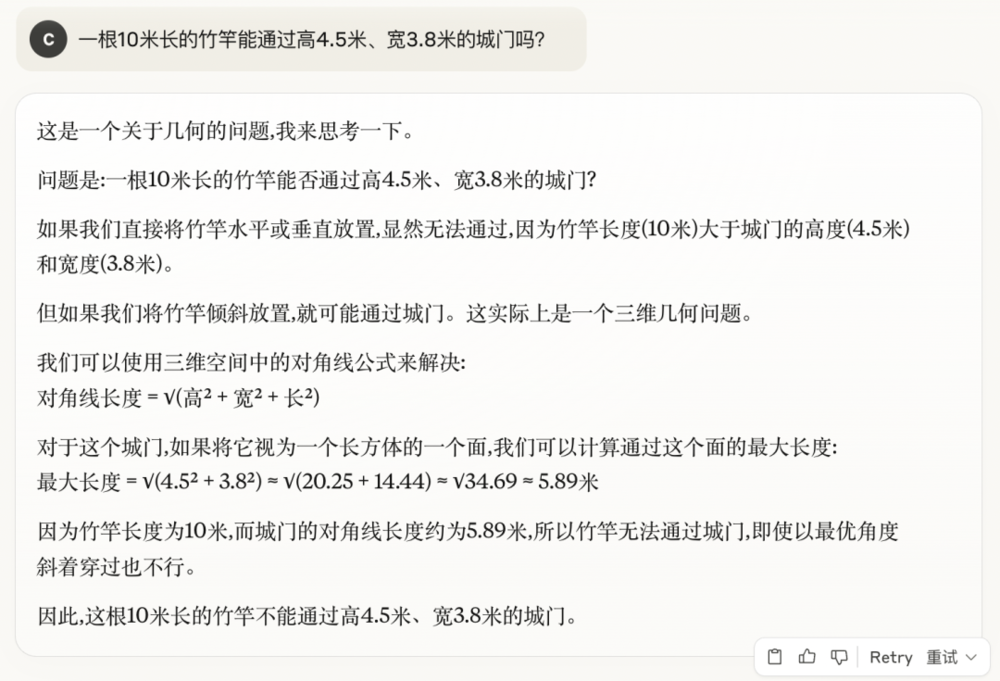
Grok3:
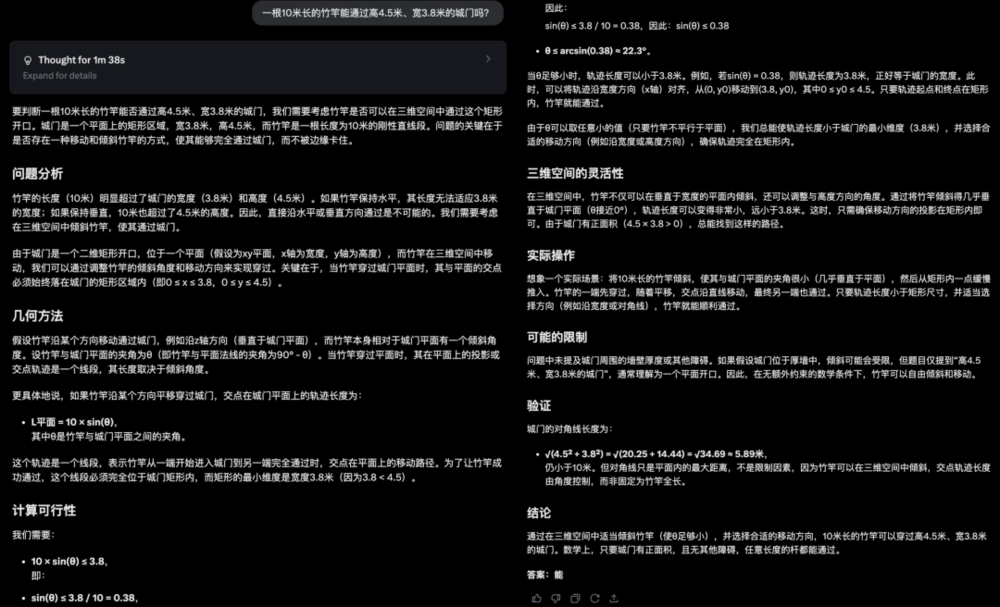
DeepSeek R1:

2. 我有6個雞蛋,碎了2個,煎了2個,吃了2個,最多還剩幾個?
這道題目的關鍵在於理解這些動作之間的關係。
如果把每個動作視為獨立事件,那將一個雞蛋也不剩。
但題目問的是最多還剩幾個,這表明可能有重疊的情況,碎的2個雞蛋正好煎了、吃了,因此在最佳情況下,最多還剩4個雞蛋。
Gemini 2.5和DeepSeek R1思考一番後,抓住了問題關鍵,最終回答正確。
o3-mini、GPT-4.5和Claude3.7考慮到了動作重疊的情況,但沒有扣住「最多」這個條件,因此回答錯誤。
最搞笑的就是馬斯克家的Grok3,答案對了,但腦回路清奇,它是從完整的雞蛋裡拿出2個煎了、吃了,所以最後還剩2個完整的雞蛋和2個碎雞蛋。
來看看各家大模型的具體表現。

Gemini 2.5:
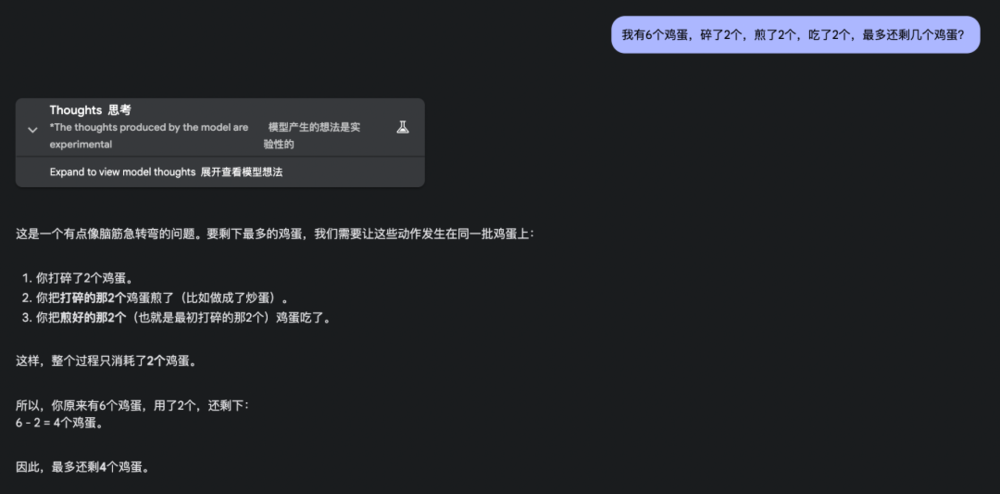
o3-mini:

GPT-4.5:

Claude3.7 Sonnet:
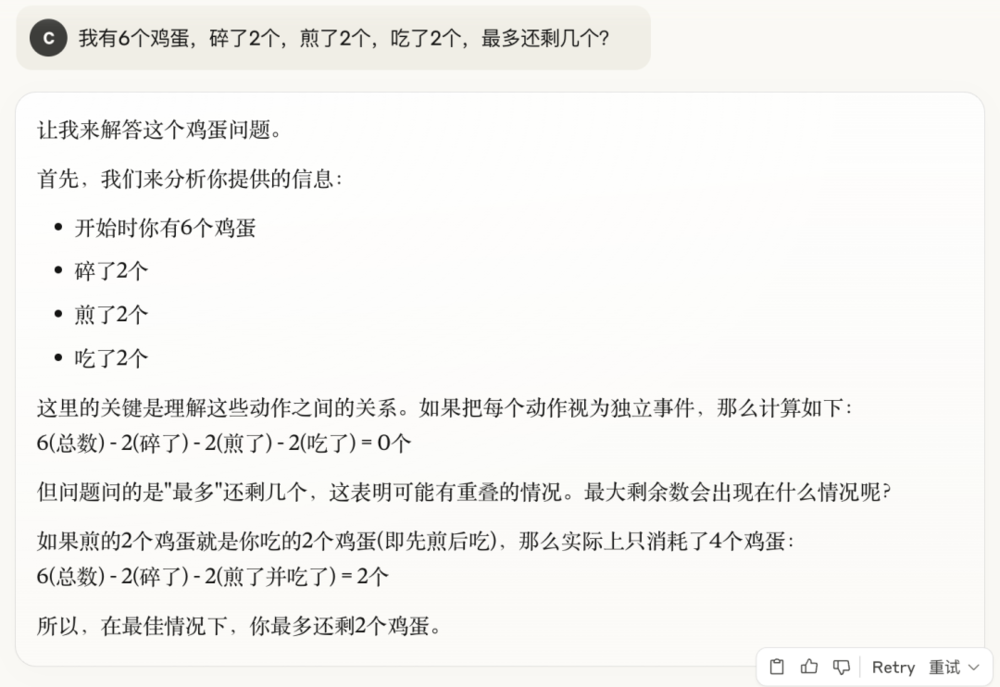
Grok3:
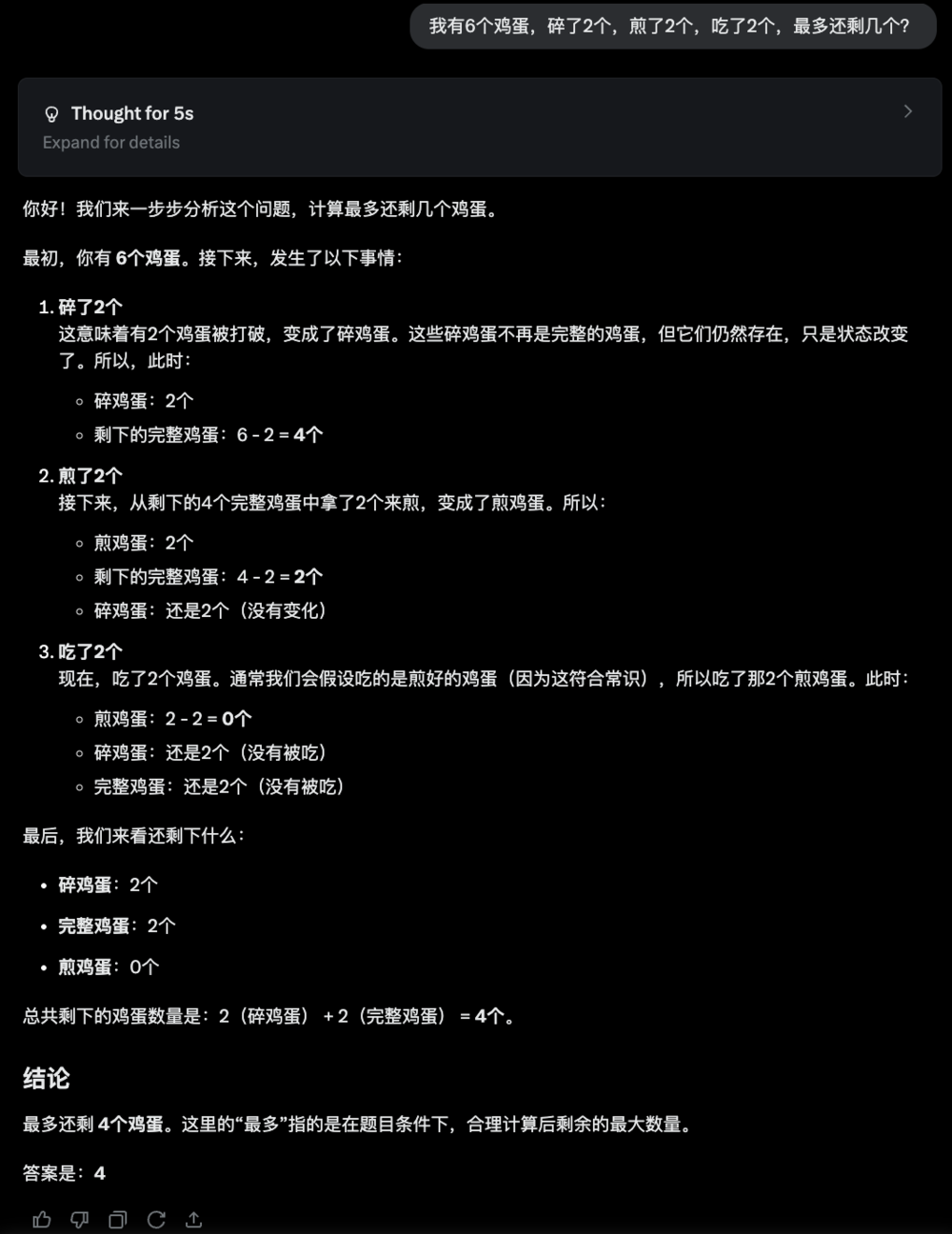
DeepSeek R1:

3. 兩個人同時來到了河邊,都想過河,但只有一條小船,而且小船隻能載一個人。請問:他們能否都過河?
這道題目很容易讓人陷入思維定勢。
同時來到河邊的倆人不一定在河的同一邊,只要抓住這個關鍵點,這道題目就迎刃而解了。
Gemini 2.5、Claude3.7 Sonnet思路清晰,回答正確。
o3-mini和GPT-4.5雖然都說可以同時過河,但給出的解釋非常牽強,GPT-4.5甚至說讓船空著漂回去,所以不算對。
Grok3和DeepSeek R1則回答錯誤。
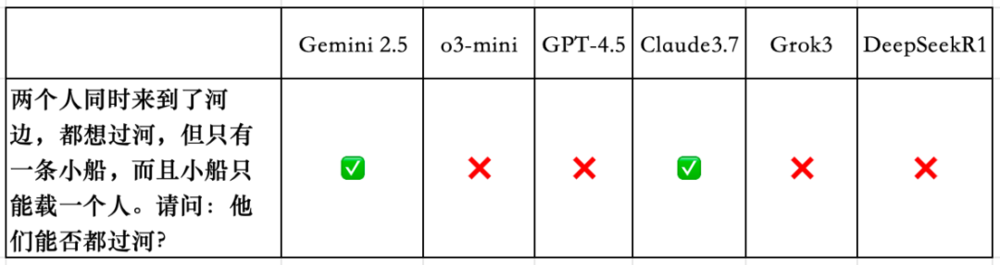
各家大模型具體表現如下。
Gemini 2.5:
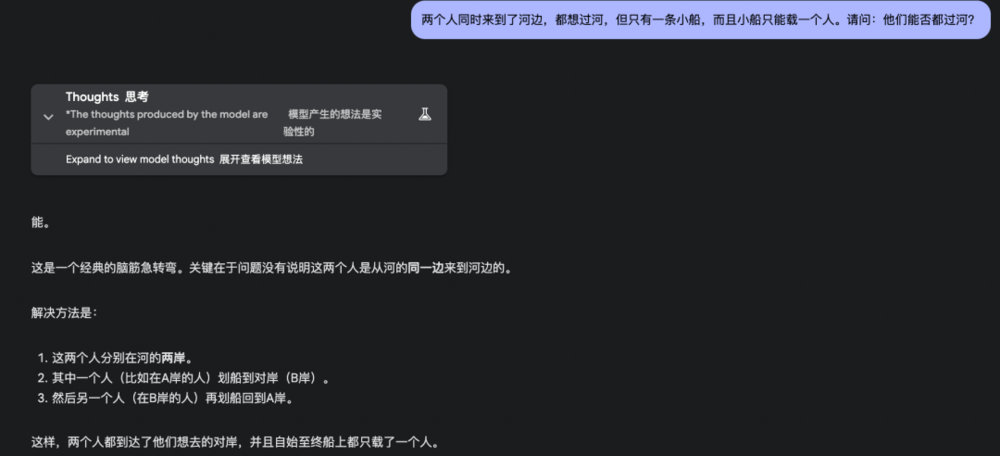
o3-mini:

GPT-4.5:

Claude3.7 Sonnet:

Grok3:
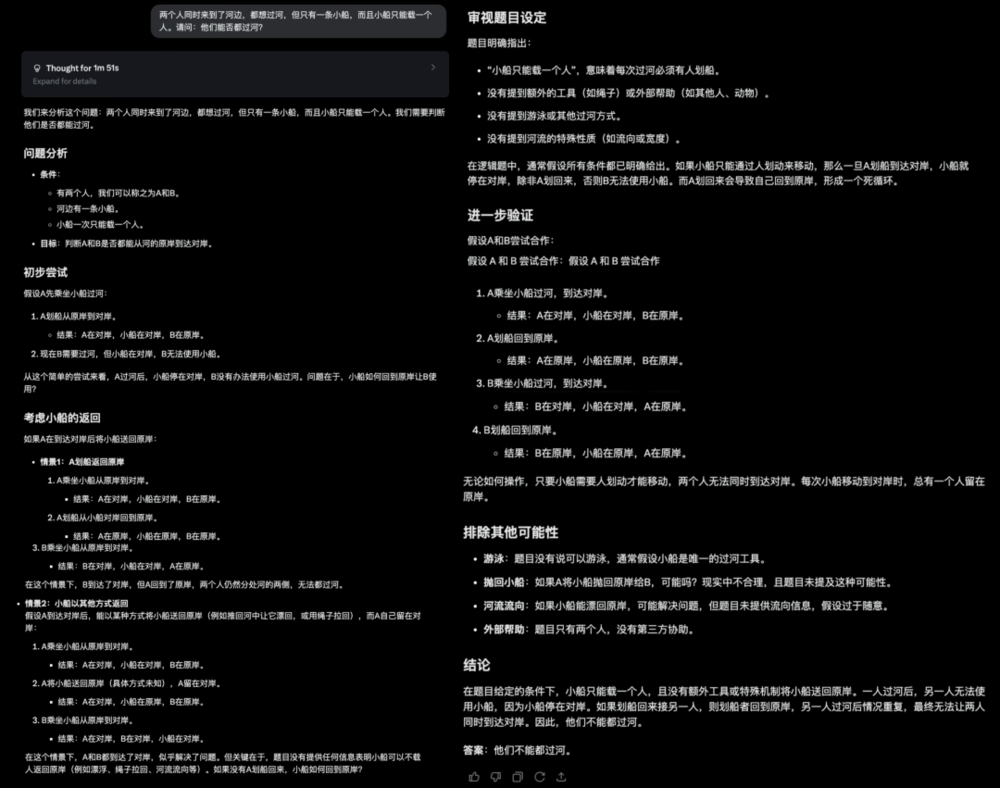
DeepSeek R1:

4. 張三去水果店買蘋果,蘋果進價為20元,賣價是30元。張三付給老闆100元,老闆沒有零錢,就在賣鞋的人那裡換了100元零錢,找給張三70元。後來賣鞋的人發現那100元是假幣,於是找老闆換回了100元。請問水果店老闆損失了多少錢?
別看這道題目出現了如此多的數字,故事情節也曲折,但其實水果店老闆損失的錢只有兩部分——蘋果進價20元和找給買家的70元,因此答案是90元。
Gemini 2.5、Claude3.7 Sonnet、Grok3和DeepSeek R1都回答正確。
o3-mini和GPT-4.5糾結了半天,徹底被繞進去了,最終得出錯誤答案。

Gemini 2.5:
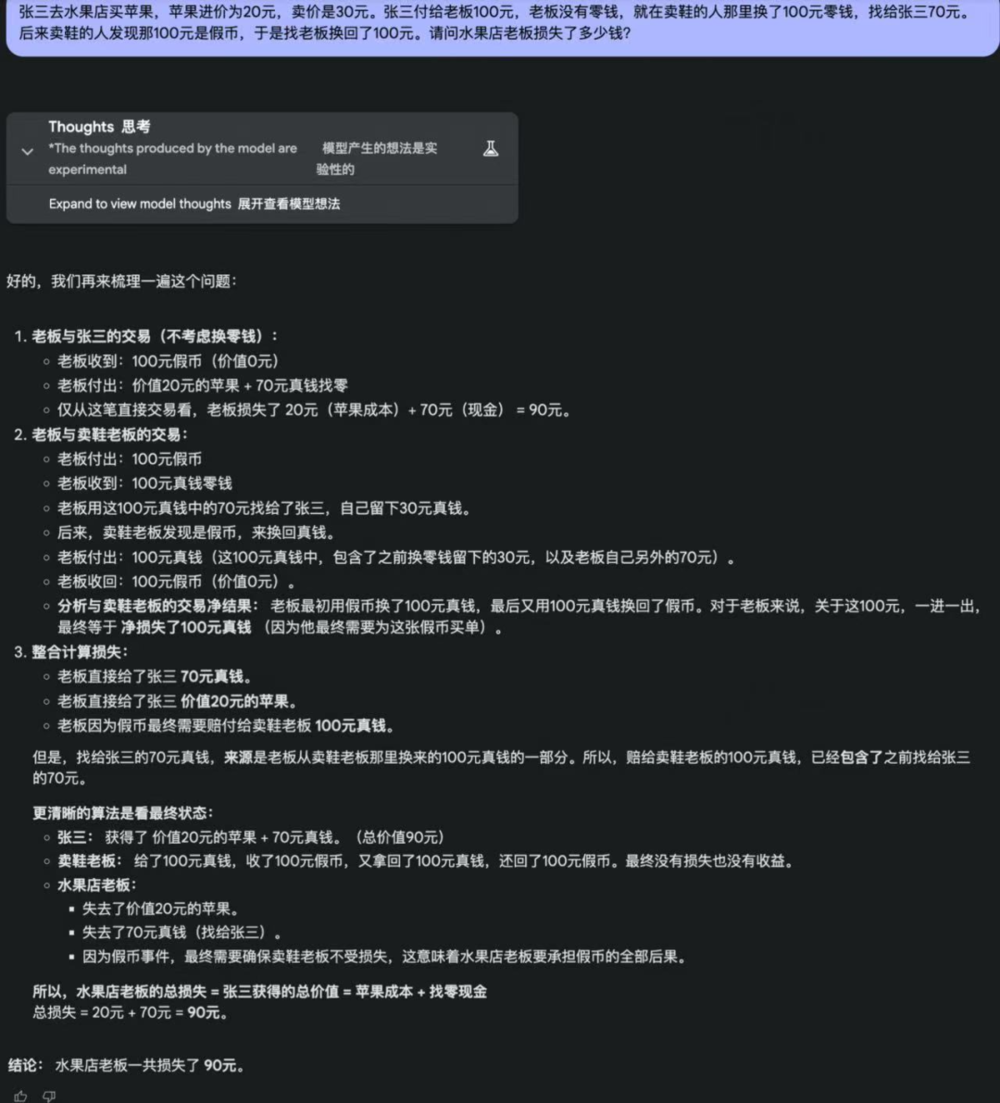
o3-mini:

GPT-4.5:

Claude3.7 Sonnet:

Grok3:

DeepSeek R1:

5.多模態測試題,杯子有多高?
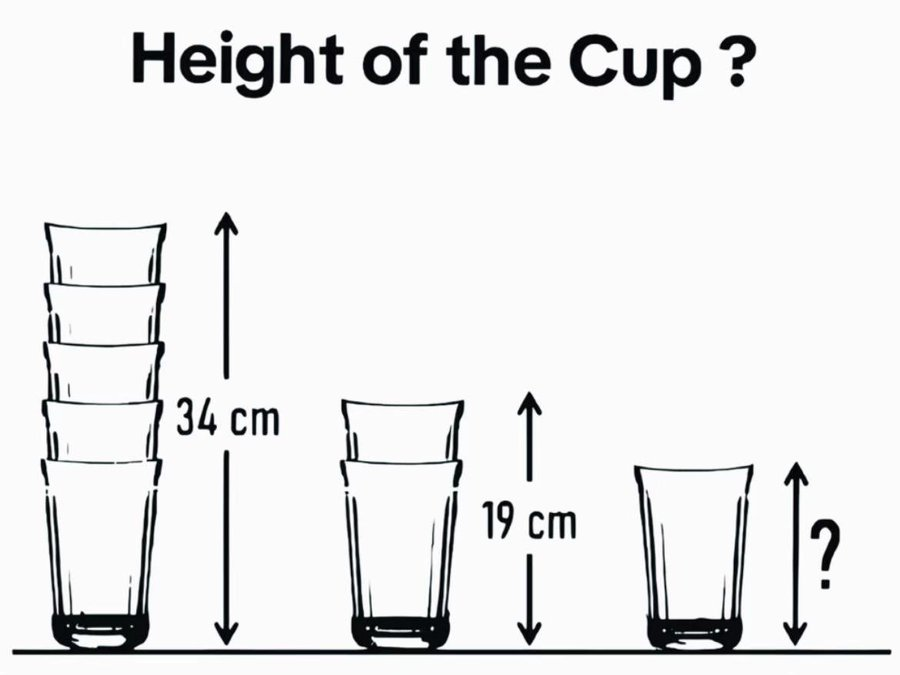
對於這道題,大模型們要先識別圖像,然後進行計算。
Gemini 2.5、Claude3.7 Sonnet和Grok3回答正確。
而o3-mini、GPT4.5全程胡說八道。
DeepSeek R1雖然可以上傳圖片,但它只能識別圖片中的文字,無法真正讀懂圖,因此回答錯誤。
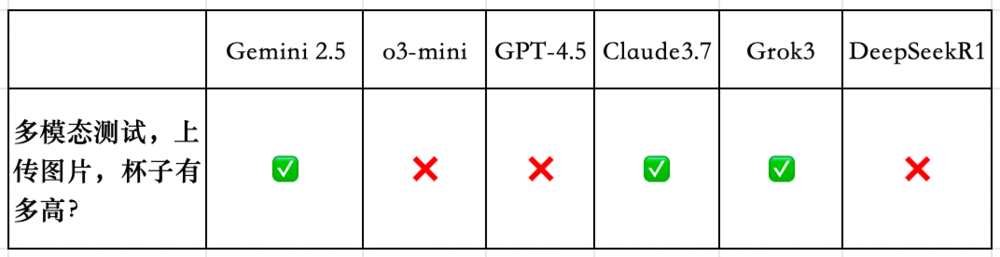
各家大模型的具體表現如下。
Gemini 2.5:
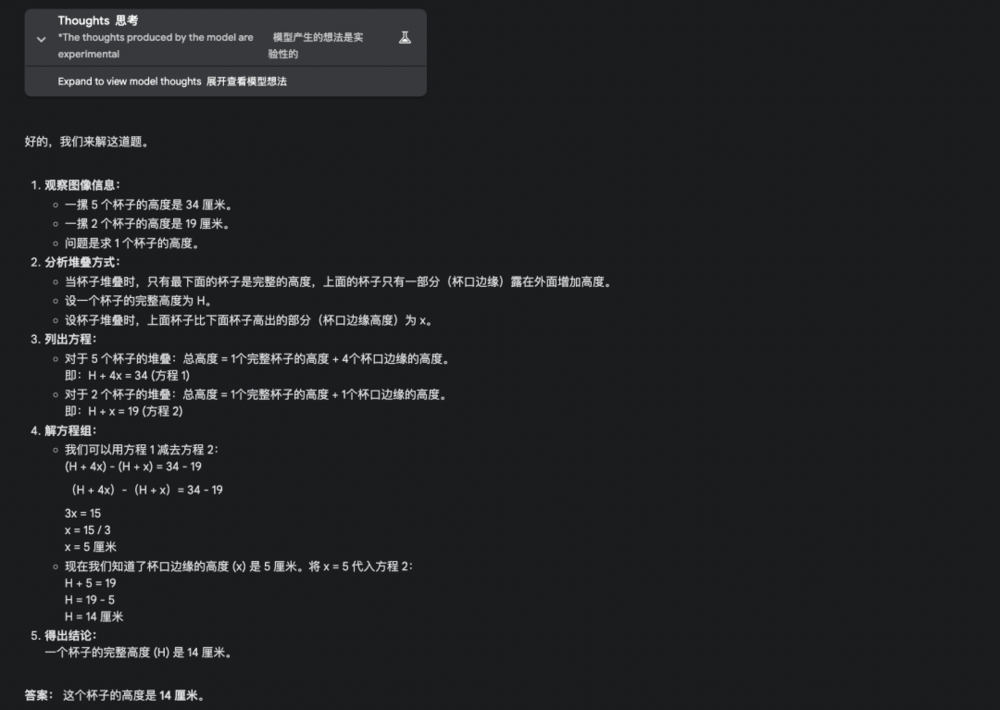
o3-mini:

GPT-4.5:

Claude 3.7 Sonnet:

Grok3:
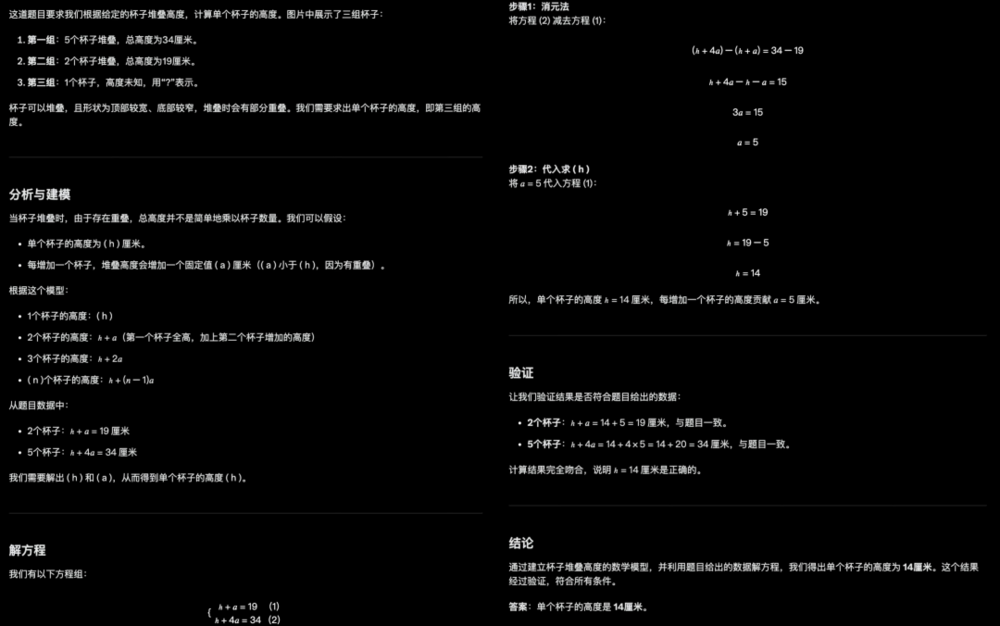
DeepSeek R1:


根據以上測試,我們發現Gemini 2.5雖然也會翻車,但正確率達80%,總體來說數學邏輯推理能力還是挺能打的。
Claude 3.7 Sonnet稍遜一籌,5道題目錯了倆。
最慘的就是OpenAI家的兩大模型o3mini和GPT-4.5,沒有一道題目是做對的,正確率為0。