實測 OpenAI 「一句話 P 圖」:這張圖讓我的朋友圈炸了,PS 真要被淘汰了?
從前都以為修圖是很複雜的事,從平平無奇的白底 logo,比如這樣:

變成精緻漂亮還帶 3D 立體效果的場景圖,比如這樣:

需要怎麼做?
不是在 Adobe 軟件里埋頭苦幹大半天,也不用跟設計師來回 battle 一下午——只需要去最新的 ChatGPT,輸入一句話,結束。
網址都給你找好了:https://chatgpt.com/
在今天淩晨 OpenAI 發佈新一代文生圖功能的時候,大家還不是很清楚它的實力,還以為是跟在 Gemini 後頭,帶來一些遲到的升級。
GPT 不語,只是一昧地讓用戶案例震驚全場。

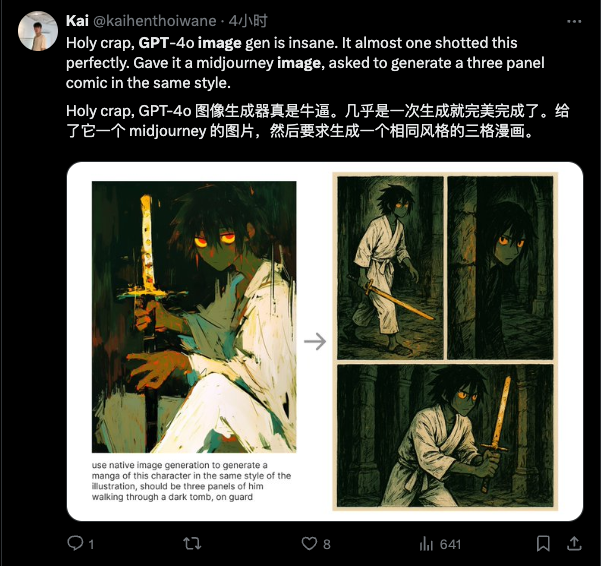
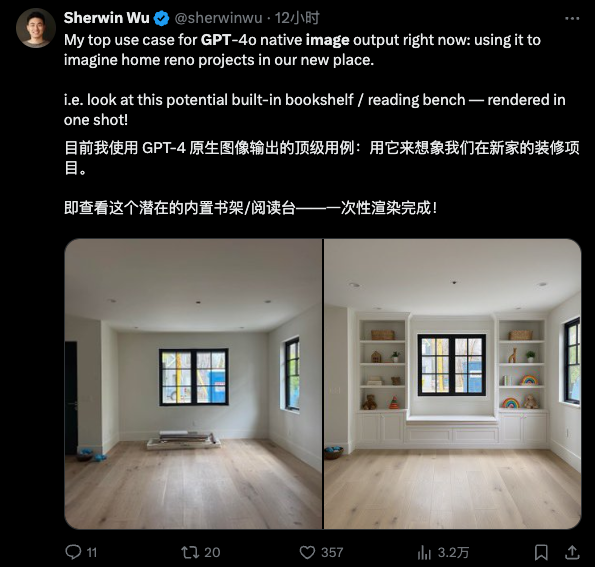
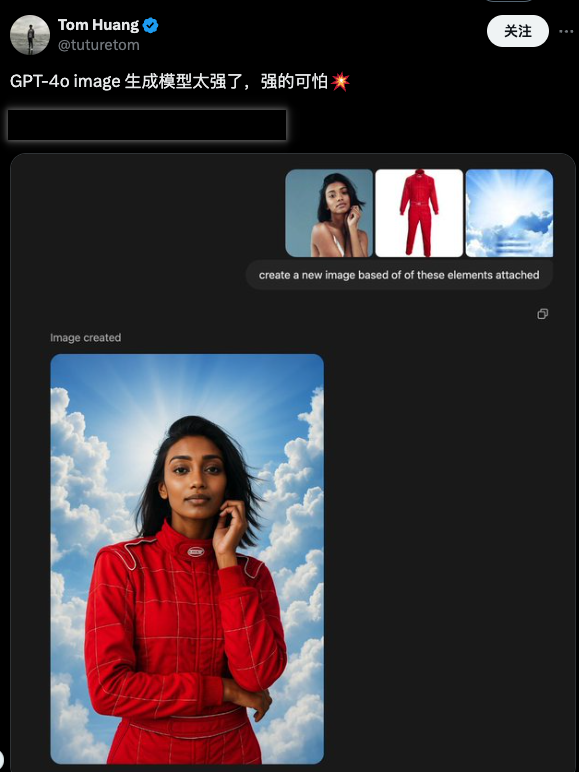
在最新的迭代中,OpenAI 帶來了文生圖功能上,突破性的指令遵循和一致性表現。只需最簡單的文字 prompt,就可以實現高精度的圖片細部微調——一切修改只需要在會話當中進行,無需任何按鈕、筆刷等額外操作。
魔法不用筆刷,只用咒語
和 Gemini 類似,這次 OpenAI 的更新,重點不在於能做多寫實、多複雜的圖片,而在於指令遵循和一致性,並且是在只使用自然語言指令的前提下。
先來看一組比較入門級的食物照片,prompt 也非常簡單:generate an image of coffee and bread。

隨後,在原圖的基礎上要求改成冰咖啡、塗果醬。
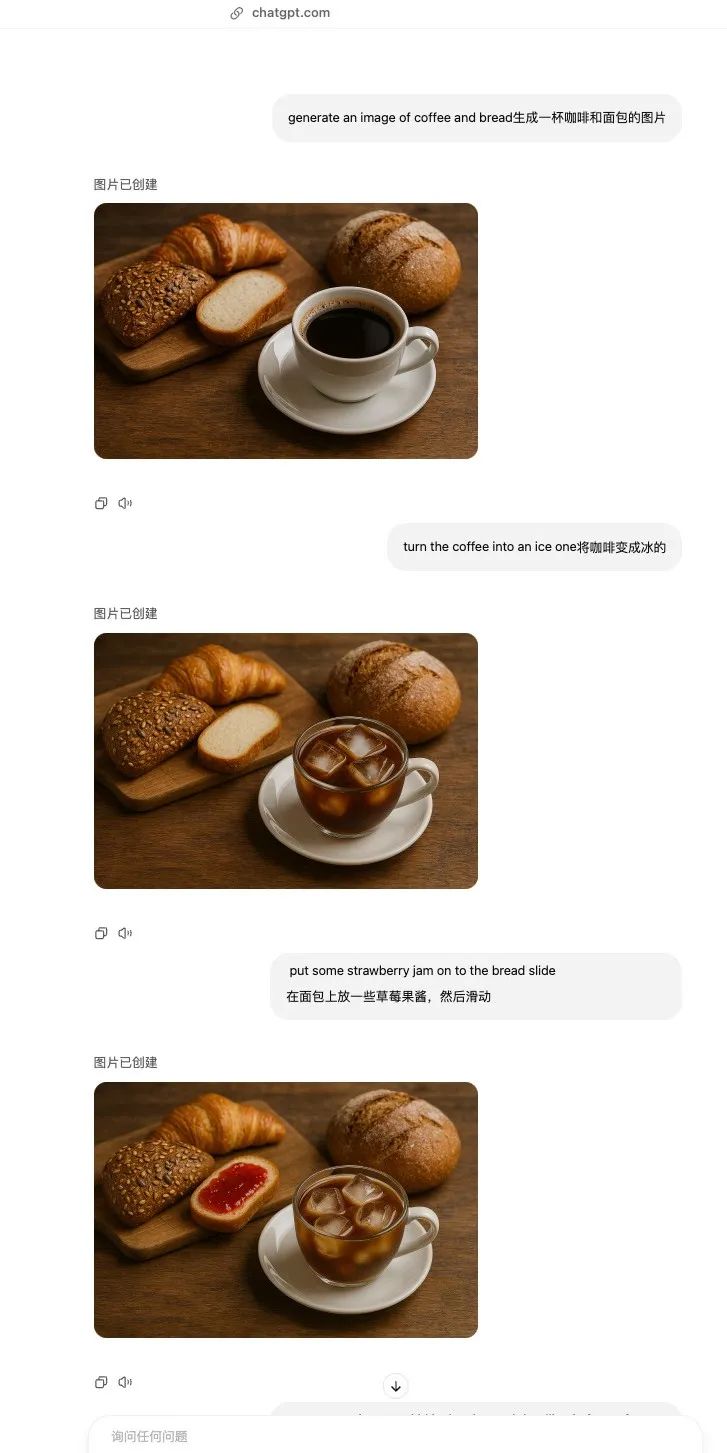
除了杯柄之外,該加的加,該留的留,指令遵循非常出色。
涉及到人像的圖片,也有穩定的表現。

仔細看的話,還是有一些小地方是在變動的,但最關鍵的人體動作、衣服皺褶、表情,都沒有瑕疵。
在這組圖的時候,碰到了內容風控,報錯稱不符合政策要求。不過,它理解到了原指令的意圖,提出了修改方案。

這最後一張,也是生成效果最好最自然的一張。
畫面內容簡單的任務自然是手拿把掐,那麼複雜一點的呢?
之前在 Gemini 的生圖測試中,我們出過一張城市街頭景象,效果非常驚人,再看一遍:

同樣的 prompt,給 ChatGPT 執行,在畫面效果上稍微差了一點,尤其是到夜晚這張,幾乎已經看不到人群細節了。

當然這個問題比較偏向於是審美不同,在對關鍵元素的識別上是沒問題的,甚至能捕捉到「蔦屋書店」這樣小的細節,字體生成也挺穩的。
除了直接用文字生成,還可以上傳圖片進行修改——此刻,最震撼的一集來了。
在上傳了 png 格式的 APPSO 標誌之後,第一步簡單的變個 3D 立體。

效果還可以,陰影方向不一致,但符合光線本身即可。接下來再做點調整。

震撼!這兩次調整的 prompt,不過是二十來個字而已。

(甚至預設數碼產品都是 Apple 的,一些沒有說的屬性真是偷偷藏不住呀。)
隨後的小角度微調也很準確。

Prompt:調整角度,使紅色logo變成正面,其餘保持不動
細節微調是這次更新非常大的亮點,能夠準確將指令與相對應的細部關聯起來,從而完成精確的局部修改。
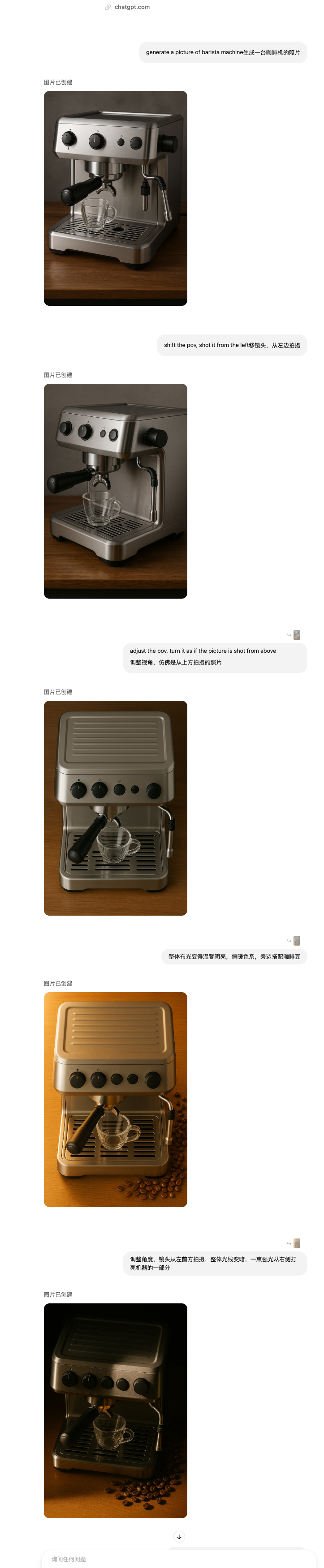
Prompt:調整角度,鏡頭從右前方拍攝,整體光線變暗,一束強光從右側打亮機器的一部分,旁邊搭配咖啡豆
指令中包含了光效、鏡頭角度、元素增補等關鍵內容,模型能夠準確識別,而且整體性地進行調整。指哪改哪四個字,都已經說倦了。
這次的更新中,最意外的應該是在同一個會話中,生圖和生文迅速切換的能力。
比如在下面這張圖中,最早的指令是生成一個禮物包裝指南。

首先給出來的是一個圖文版——不算是錯,我沒有指明是要做圖文版,還是文字版,指令是很模糊的。
在生成文字版之後,ChatGPT 主動詢問是不是要做圖文版,在收到確認的答覆之後,給出了圖文並茂的版本。

這意味著模型的準確反應,不僅體現在理解單一指令上,也體現在領悟用戶潛在意圖上,比用戶「多想一步」。
實際上,這也是此前 Deep Research 發佈時就展現出來的能力。OpenAI 的深度檢索,是少數會主動向用戶詢問、明確任務執行細節的深度檢索產品。
類似的能力,這次遷移到了生圖當中,從使用感受而言,比在 Deep Research 上的更直觀可感。
例如可以用來製作日常的告示說明,圖文一鍋都「端」了。

中文字符的處理還是差點意思,在可接受範圍內吧。
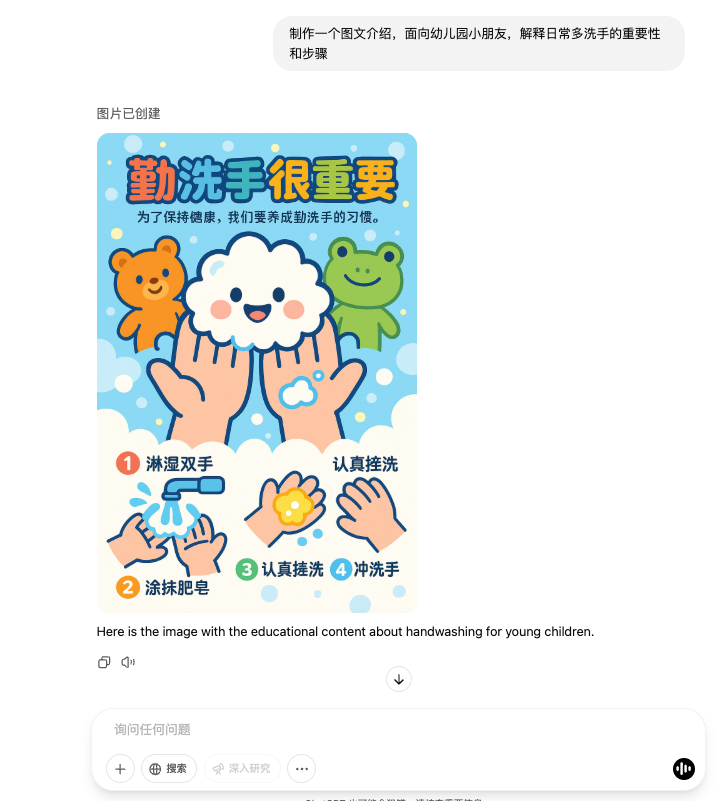
整體來看,這次最驚人的肯定要屬一致性和指令遵循的同步到位。
按照慣例,每次測評都應該有一些「使用指南」——這次真的沒有發現什麼注意事項,一切只要按照自己的想法,敲擊鍵盤,輸入文字,就行了。沒有什麼「技巧」或者「竅門」。
通過 prompt 生圖及改圖的一致性,是文生圖非常關鍵的問題,它既跟模型能力相關,又和工程能力相關。
在指令遵循和一致性有這麼大的進步之前,主要是通過 prompting 來解決的,壓力是在用戶這一邊。
所以會有各種各樣的 prompt 模版、攻略,教大家怎麼「跟模型打交道」。但那不是自然語言交互應該有的狀態,讓人先學一通怎麼寫 prompt,著實很勸退——模型在面對人的時候,接受的就是用戶最直接的指令。
Gemini 和 OpenAI 近期的更新,讓熱度有所降低的生圖賽道又重新熱鬧了起來。它們也展示出了同一個共同點:一些修圖改圖產品,通過增加按鈕、入口,來增加生圖的可操控性,以此來對抗模型幻覺的日子,快要到頭了。
一致性的問題解決的並不僅僅只是圖片生成的問題,更加是「使用圖片生成功能」過程中的小麻煩。某種意義上,也是一種工程層面的優化。
修改、生成都是可以用模型對文字指令的準確理解來實現——在這個層面上,「模型即產品」仍然成立。
我們正在招募夥伴
 簡曆投遞郵箱
簡曆投遞郵箱
hr@ifanr.com
 郵件標題「姓名+崗位名稱」(請隨簡曆附上項目/作品或相關鏈接)
郵件標題「姓名+崗位名稱」(請隨簡曆附上項目/作品或相關鏈接)