阿里雲通義千問發佈新一代端到端多模態旗艦模型 Qwen2.5-Omni 並開源,看聽說寫樣樣精通
感謝IT之家網民 烏蠅哥的左手 的線索投遞!
IT之家 3 月 27 日消息,今日淩晨,阿里雲發佈通義千問 Qwen 模型家族中新一代端到端多模態旗艦模型 ——Qwen2.5-Omni,並在 Hugging Face、ModelScope、DashScope 和 GitHub 上開源。
阿里雲表示,該模型專為全方位多模態感知設計,能夠無縫處理文本、圖像、音頻和影片等多種輸入形式,並通過實時流式響應同時生成文本與自然語音合成輸出。IT之家彙總其主要特點如下:
-
全能創新架構:Qwen 團隊提出了一種全新的 Thinker-Talker 架構,這是一種端到端的多模態模型,旨在支持文本 / 圖像 / 音頻 / 影片的跨模態理解,同時以流式方式生成文本和自然語音響應。Qwen 提出了一種新的位置編碼技術,稱為 TMRoPE(Time-aligned Multimodal RoPE),通過時間軸對齊實現影片與音頻輸入的精準同步。
-
實時音影片交互:架構旨在支持完全實時交互,支持分塊輸入和即時輸出。
-
自然流暢的語音生成:在語音生成的自然性和穩定性方面超越了許多現有的流式和非流式替代方案。
-
全模態性能優勢:在同等規模的單模態模型進行基準測試時,表現出卓越的性能。Qwen2.5-Omni 在音頻能力上優於類似大小的 Qwen2-Audio,並與 Qwen2.5-VL-7B 保持同等水平。
-
卓越的端到端語音指令跟隨能力:Qwen2.5-Omni 在端到端語音指令跟隨方面表現出與文本輸入處理相媲美的效果,在 MMLU 通用知識理解和 GSM8K 數學推理等基準測試中表現優異。

據官方介紹,Qwen2.5-Omni 採用 Thinker-Talker 雙核架構。Thinker 模塊如同大腦,負責處理文本、音頻、影片等多模態輸入,生成高層語義表徵及對應文本內容;Talker 模塊則類似發聲器官,以流式方式接收 Thinker 實時輸出的語義表徵與文本,流暢合成離散語音單元。Thinker 基於 Transformer 解碼器架構,融合音頻 / 圖像編碼器進行特徵提取;Talker 則採用雙軌自回歸 Transformer 解碼器設計,在訓練和推理過程中直接接收來自 Thinker 的高維表徵,並共享全部歷史上下文信息,形成端到端的統一模型架構。
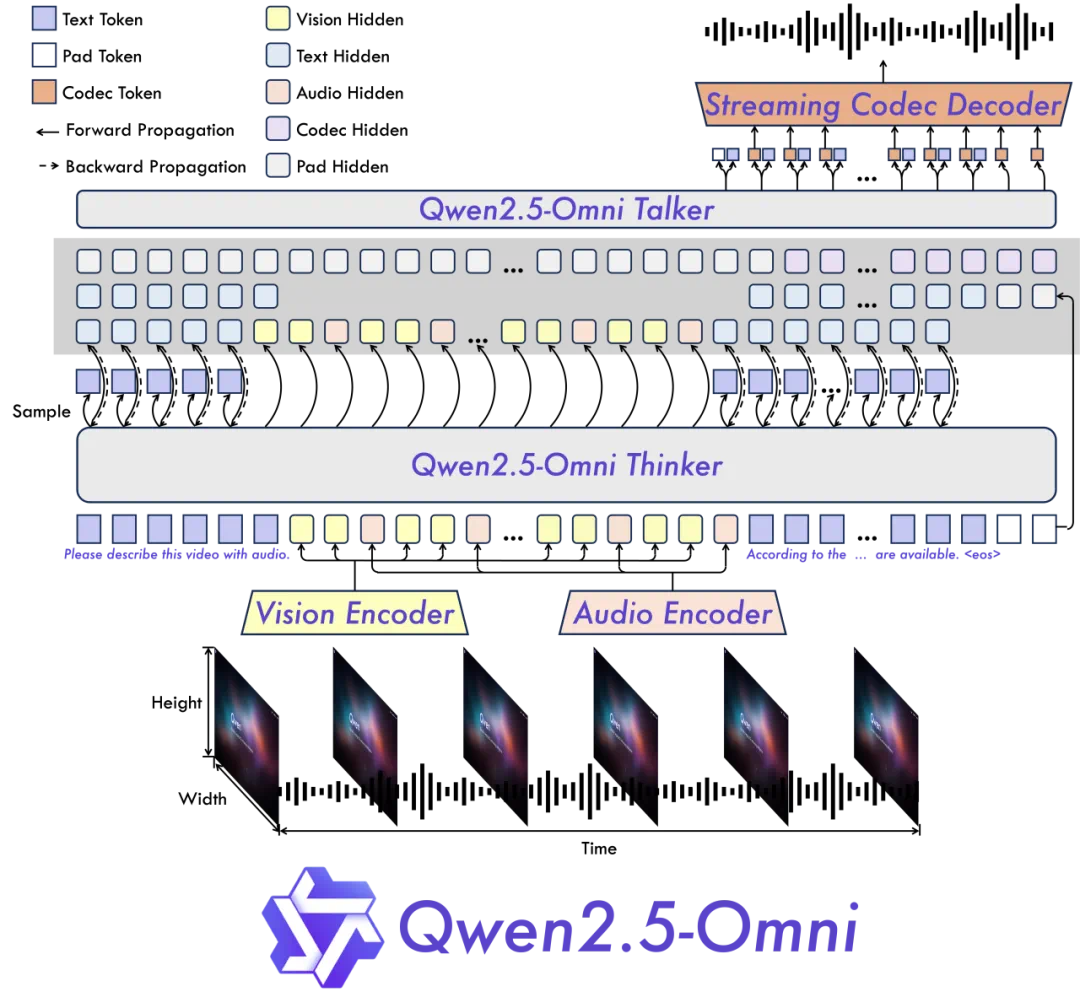 模型架構圖
模型架構圖模型性能方面,Qwen2.5-Omni 在包括圖像,音頻,音影片等各種模態下的表現都優於類似大小的單模態模型以及封閉源模型,例如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro。
在多模態任務 OmniBench,Qwen2.5-Omni 達到了 SOTA 的表現。此外,在單模態任務中,Qwen2.5-Omni 在多個領域中表現優異,包括語音識別(Common Voice)、翻譯(CoVoST2)、音頻理解(MMAU)、圖像推理(MMMU、MMStar)、影片理解(MVBench)以及語音生成(Seed-tts-eval 和主觀自然聽感)。
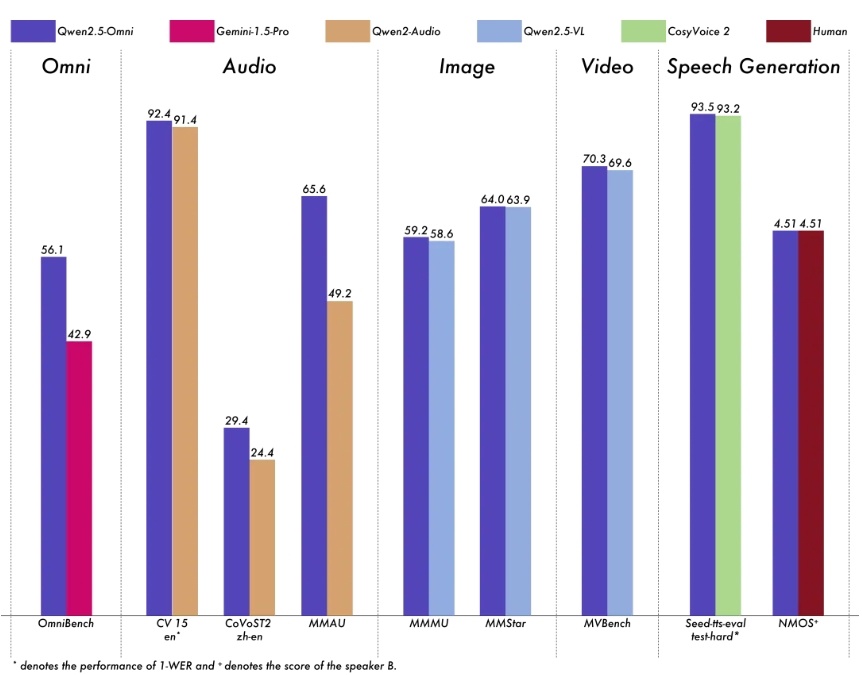 ▲ 模型性能圖
▲ 模型性能圖-
Qwen Chat:https://chat.qwenlm.ai
-
Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
-
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
-
DashScope:https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
-
GitHub:https://github.com/QwenLM/Qwen2.5-Omni
-
Demo 體驗:https://modelscope.cn/ studios / Qwen / Qwen2.5-Omni-Demo
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。


















