清華稀疏Attention,無需訓練加速一切模型!

在當今各類大語言模型以及影片模型中,長序列場景越來越普遍,而 Attention 的計算複雜度隨著序列長度呈平方增長,成為長序列任務下的主要計算瓶頸。此前,清華大學陳鍵飛團隊提出的即插即用量化的 SageAttention 系列工作已實現 3 倍加速於 FlashAttention,且在各類大模型上均保持了端到端的精度,已被業界和社區廣泛使用。為了進一步加速 Attention,清華大學陳鍵飛團隊進一步提出了無需訓練可直接使用的稀疏 Attention(SpargeAttn)可用來加速任意模型。實現了 4-7 倍相比於 FlashAttention 的推理加速,且在語言,影片、圖像生成等大模型上均保持了端到端的精度表現。

-
論文標題:SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
-
論文鏈接:https://arxiv.org/abs/2502.18137
-
開源代碼:https://github.com/thu-ml/SpargeAttn
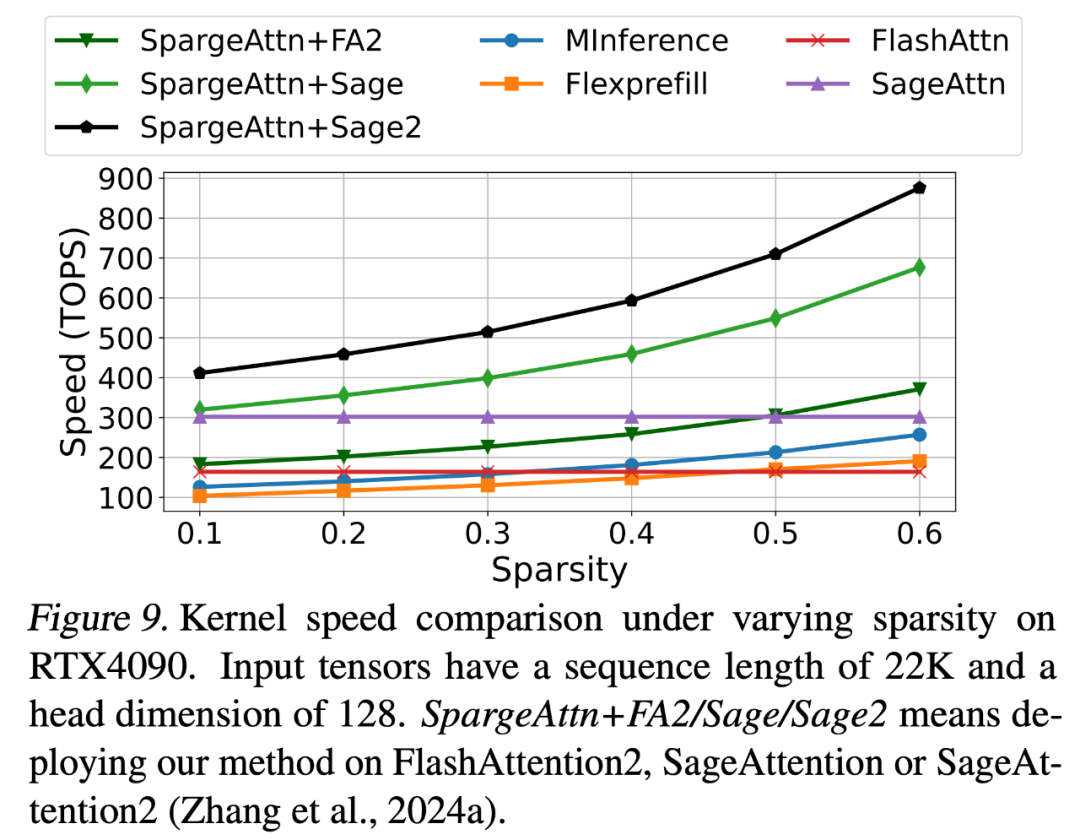
下圖展示了 SpargeAttn 的速度,可以發現在 RTX4090 上,SpargeAttn 在 60% 稀疏度的情況下可以達到 900TOPS 的速度,甚至是使用 A100 顯卡速度的 4.5 倍(A100 上 FlashAttention 只有 200TOPS)。
在 SpargeAttn 的 Github 倉庫中可以發現,SpargeAttn 的使用方法比較簡潔,只需要進行一次簡單的超參數搜索過程,就可以永久地對任意的模型輸入進行推理加速。
接下來,將從前言,挑戰,方法,以及實驗效果四個方面介紹 SpargeAttn。
前言
隨著大模型需要處理的序列長度越來越長,Attention 的速度優化變得越來越重要。這是因為相比於網絡中其它操作的 O (N) 的時間複雜度,Attention 的時間複雜度是 O (N^2)。儘管 Attention 的計算複雜度為 O (N^2),但幸運的是 Attention 具備很好的稀疏性質,即 P 矩陣的很多值都接近 0。如何利用這種稀疏性來節省計算就成為了 attention 加速的一個重要方向。大多數現有的工作都集中在利用 P 矩陣在語言模型中表現出來的固定的稀疏形狀(如滑動窗口)來節省計算,或是需要重新訓練模型,比如 DeepSeek 的 NSA 以及 Kimi 的 MoBA。此外,現有稀疏 Attention 通常需要較大的上下文窗口(如 64K~1M)才能有明顯加速。SpargeAttn 的目標是開發一個無需訓練、對各種模型(語言 / 影片 / 圖像)通用、精度無損、對中等長度的上下文(如 4-32K)也有加速效果的注意力機制。
 圖 1: 不同的模型表現出不同的稀疏形狀
圖 1: 不同的模型表現出不同的稀疏形狀實現通用的,無需訓練的稀疏 Attenion 有哪些挑戰?
挑戰 1
通用性:Attention 雖然具備稀疏性質,但是其稀疏形狀在不同的模型甚至同一模型的不同層中都是不同的,體現出很強的動態性。如圖 1 所示,前兩種模型分別為影片模型和圖像生成模型,這兩個模型中的 Attention 的稀疏形狀相比語言模型更加沒有規律。設計一種各種模型通用的稀疏 Attention 是困難的。
挑戰 2
可用性:對於各種 Attention 的輸入,很難同時實現準確且高效的稀疏 Attention。這是因為準確性要求了完全精確地預測 P 中的稀疏區域,高效性則要求了此預測的時間開銷極短。在一個極短的時間內完全精準地預測 P 的稀疏形狀是困難的。
方法
為瞭解決上述的兩個挑戰,研究團隊提出了對應的解決辦法。
-
研究團隊提出了一種各模型通用的快速的對 P 矩陣稀疏部分進行預測的算法。該方法選擇性地對 Q, K 矩陣進行壓縮並預測 P 矩陣,接著使用 TopCdf 操作省略 P 中稀疏部分對應的 QK^T 與 PV 的矩陣乘法。
-
研究團隊提出了在 GPU Warp 級別上的稀疏 Online Softmax 算法,該算法通過利用 Online Softmax 中全局最大值與局部最大值之間的差異,進一步省略了一些 PV 的矩陣乘法計算。
-
可選的,針對影片和圖像模型,研究團隊充分利用圖像以及影片中的 Token 局部相似性質,使用高治伯特重排的方法對 Attention 前的 Token 進行重新排列,進一步提高稀疏度。
-
最後,研究團隊將這種稀疏方法與基於量化的 SageAttention 融合到一起,進一步加速 Attention。
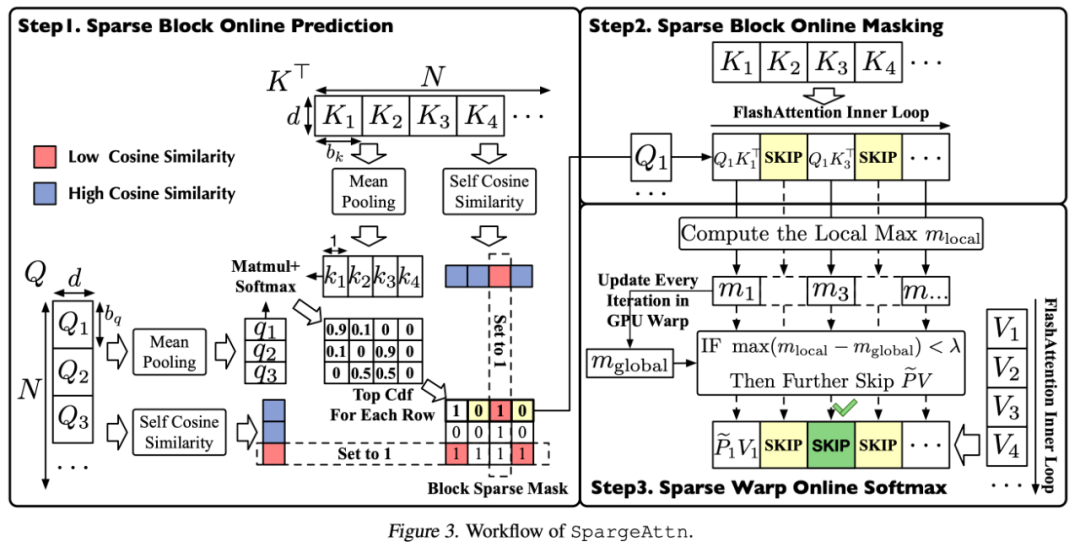 圖 2: SpargeAttn 的算法流程圖
圖 2: SpargeAttn 的算法流程圖SpargeAttn 的算法流程如下所示:

實驗效果
總的來說,SpargeAttn 在影片、圖像、文本生成等大模型均可以實現無需訓練的加速效果,同時保證了各任務上的端到端的精度。
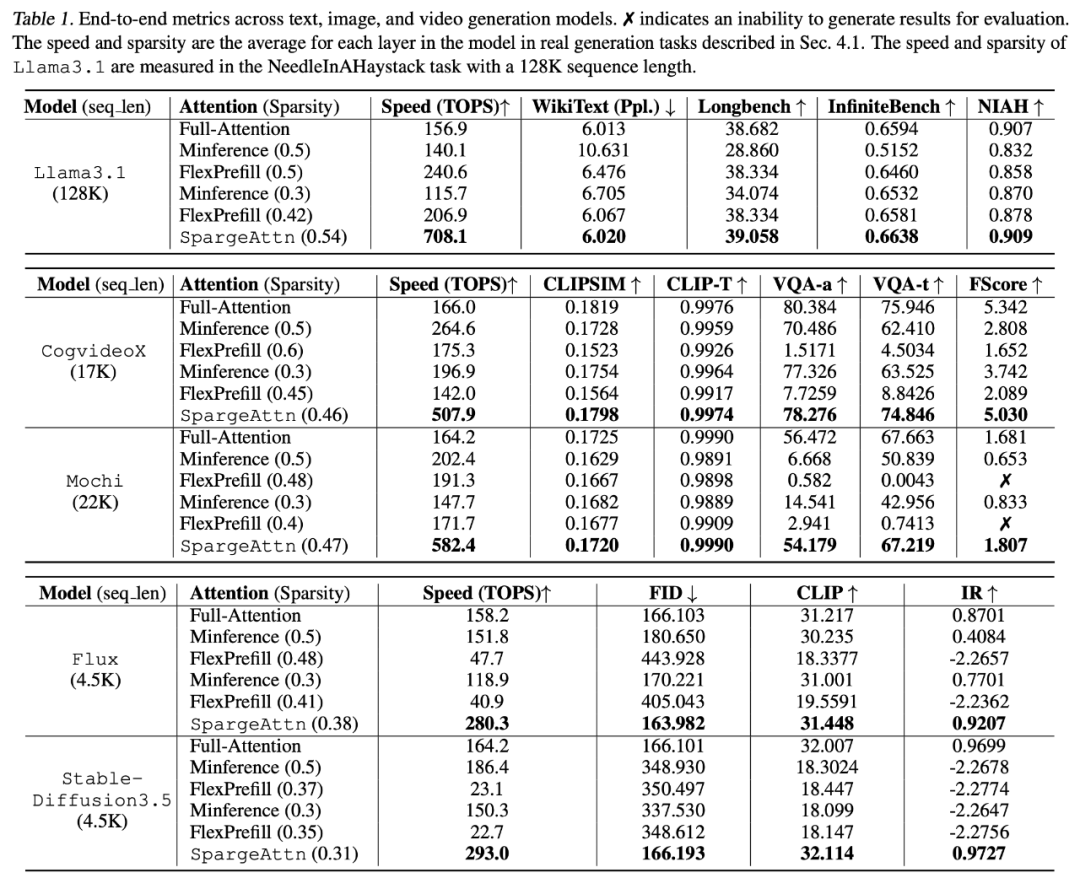
下表展示了 SpargeAttn 在各模型上的稀疏度,Attention 速度,以及各任務上的端到端精度,可以發現 SpargeAttn 在保證了加速的同時沒有影響模型精度:(註:此論文中的所有實驗都是基於 SageAttention 實現,目前 Github 倉庫中已有基於 SageAttention2 的實現,進一步提供了 30% 的加速。
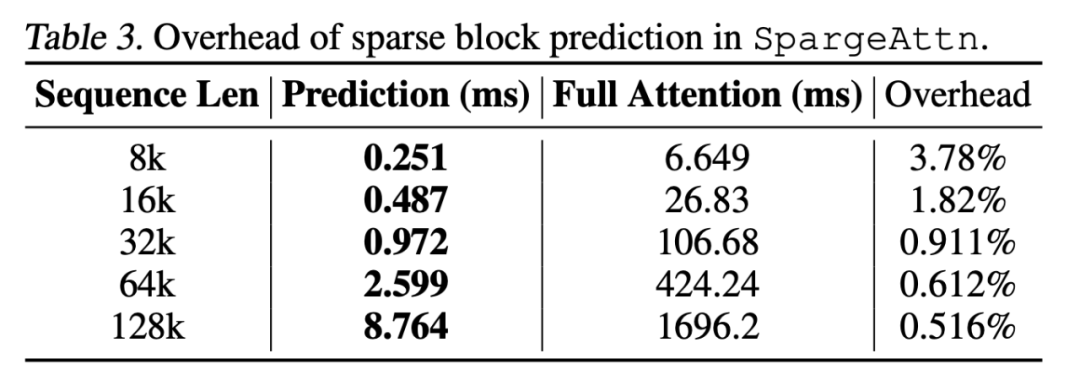
值得一提的是,此前的稀疏 Attention 工作很多無法實際使用的原因之一是稀疏預測部分的 Overhead 較大,而 SpargeAttn 團隊還將稀疏預測部分的代碼進行了極致優化,將 Overhead 壓縮到了幾乎在各種長度的序列下都可以忽略的地步:
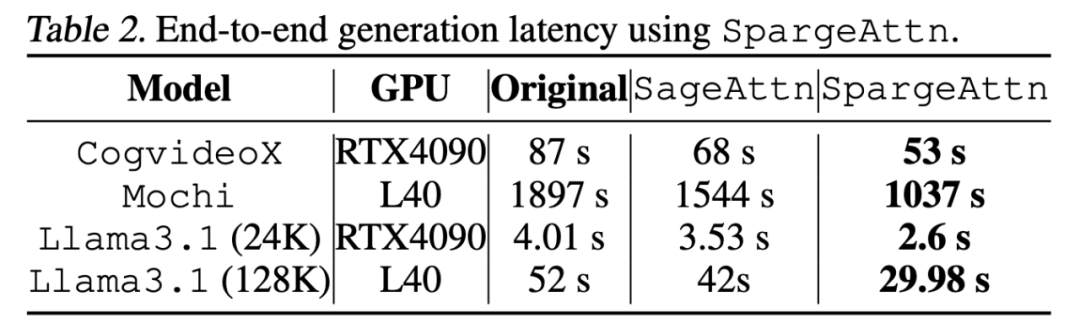
下表展示了對於各模型的端到端的加速效果,以影片生成模型 Mochi 為例,SpargeAttn 提供了近兩倍的端到端加速效果:(註:此論文中的所有實驗都是基於 SageAttention 實現,目前 Github 倉庫中已有基於 SageAttention2 的實現,進一步提供了 30% 的加速)