Google沒有護城河,美國也沒有
兩年前,Google內部喊出「我們沒有護城河,OpenAI也沒有」。當時,他們擔心的是Meta剛發佈的開源模型Llama。如今,他們更擔心的是以DeepSeek為代表的中國開源勢力。同時,美國也沒有護城河,其在AI領域的優勢,正在被淹沒到最後的塔尖。
這周,DeepSeek與Google都更新了自己的基礎模型,都將推理增強融入其中。前者的新版V3(DeepSeek-V3-0334),參數規模從6710億微增至6850億,不是推理模型,勝似推理模型。後者的Gemini-2.5-Pro,仍處於實驗版階段,桑達爾·皮查伊(Sundar Pichai)稱之為前沿「思考」模型。
推理模型與基礎模型相互獨立,或許只是階段性的產物。OpenAI就曾放風說,即將發佈的GPT-5,會是GPT-4.5與o3的融合。但DeepSeek與Google行動更快,新版V3與Gemini 2.5 Pro,都將重點落在了提升模型推理與編碼能力之上。只不過,前者算不上版本大更新,沒有思維鏈,是對基礎模型推理能力的增強;後者是一次大更新,有思維鏈,是將推理能力完全融入了基礎模型。
DeepSeek強調了新版V3對推理、前端開發、中文寫作與搜索的優化。在科學、數學與代碼等領域,新版V3相較3個月前的初版提升明顯,與剛發佈不久的GPT-4.5不相上下,並全面超越了Claude-Sonnet-3.7。它的數學與代碼能力,在與可比對象的基準測試中排名第一。
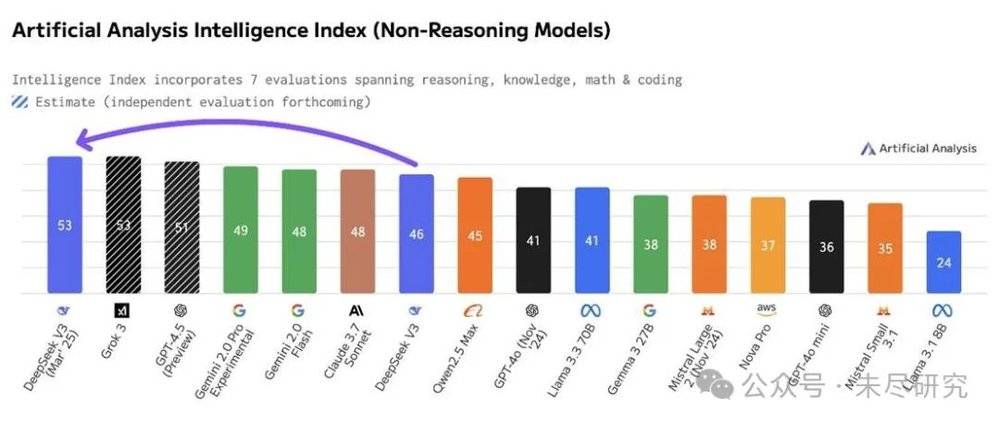
新版V3發佈後不久,模型託管與分析機構Artificial Analysis稱之為目前得分最高的非推理模型,標誌著開放權重模型首次成為領先的非推理模型,「這比R1更令人印象深刻,暗示R2將是另一個重要的飛躍。」不過,非營利研究機構AI2的後訓練負責人Nathan Lambert則認為,在目前,推理模型已經不是有與沒有的概念,而是程度與範圍的區別。
次日,Google發佈了Gemini 2.5 Pro。它的命名看上去就是基礎模型,儘管沒有像以往那樣,直接被冠以Flash Thinking的後綴,但它有思維鏈。在官方公佈的基準測試成績中,它在常見的編程、數學和科學基準測試中均處於領先地位;除了編程,其他所有項目都強於o3-mini。它的「思考」能力,來自顯著增強的基礎模型和改進的後訓練的結合。未來,Google將把這類思考能力直接構建到旗下所有的模型中。
要論思考能力,沒有思維鏈的新版V3,仍然不及有思維鏈的Gemini-2.5-Pro。由於發佈時間過於接近,雙方都沒有在官方測評結果中將對方納入對比;但是,兩者都在GPQA鑽石級、AIME2024兩項基準中,與GPT-4.5做了對比,且後者在兩份榜單中的成績一致。
在科學領域的GPQA鑽石級測評中,Gemini-2.5-Pro得分84,新版V3得分68,GPT-4.5得分71;在數學領域的AIME2024測評中,Gemini-2.5-Pro得分92,新版V3得分59,GPT-4.5得分37。在基準測試中,新版V3離Gemini-2.5-Pro有點距離。
不過,回歸應用場景,考慮到性價比,新版V3仍然充滿競爭力。今年可能是人類編程能力被AI永久超越的一年。人們對新版V3的興奮點之一,就是低成本編碼能力的提升。它的API調用價格,每百萬token輸入/輸出價格0.14美元/0.28美元,而水平相近的Claude-Sonnet-3.7需要3美元/15美元。Gemini-2.5-Pro目前只向月費20美元的高級用戶開放,規模應用定價策略尚未公佈。
新版V3同樣開源,可以微調與商用;甚至可以本地部署於蘋果最新款的基於M3 Ultra的Mac Studio,每秒跑出20個token。
新版V3提升了代碼執行效率,以及網頁和遊戲前端的設計感;工具使用能力也變得更為智能。有用戶用Gemini-2.5-Pro與DeepSeek-V3-0324分別製作小遊戲(提示詞:在一個html文件中製作一個完整的工作象棋遊戲),前者寫了570行代碼,後者寫了2372行。行數不是比較代碼能力的優秀標準,但該用戶試用了兩個模型製作小遊戲後,發現Gemini製作的「象棋AI對手超級笨」,DeepSeek的「非常聰明,還有音效等」。
Gemini-2.5-Pro與新版V3,本身對於各自公司的重要性就不一樣。Gemini-2.5-Pro對於Google的意義,在於它是僅次於跨入下一代前沿模型(Gemini 3)的一次大更新;它作為Gemini 2.5家族的代表第一個亮相,拉滿了市場對那些原本基於Gemini 2的模型或應用性能提升的期待。而DeepSeek並沒有將新版V3當成V3.5來發佈,有什麼就向開源社區共享什麼;它也沒有論文。
Google擁有最強大的AI應用生態。它們需要更強大的模型的支持,以提供更好的AI用戶體驗。Google已經基本完成了追趕OpenAI等前沿模型,甚至開始出現反超。Gemini-2.5-Pro剛推出,就登頂了Arena排行榜的第1,而且領先優勢巨大。
今年,Google將Deep Research從Gemini 1.5 Pro升級Gemini 2.0 Flash Thinking,將Gemini 2的多模態理解能力擴展至Gemini Robotic-ER的物理智能推理,將Gemini 2.0 Flash升級至原生圖像功能。它在圍堵OpenAI。相應地,OpenAI也一邊拚命將大模型能力產品化,一邊努力實現垂直整合,自研芯片、自建數據中心;GPT-4o原生圖像功能在拖延了近一年後終於上線。
但是,這一切都建立在閉源的生態環境之中。正如Google在兩年前面對Llama的衝擊,認為自己與OpenAI都沒有護城河,如今美國這一套閉源創新的生態,面對中國開源AI的瘋狂蔓延,也沒有護城河。
DeepSeek掀起了中國企業的開源潮流,為美國AI的商業化帶來了巨大的壓力。開源、高效的DeepSeek與Qwen模型,正在全球範圍內滲透、複製與應用,包括美國與印度。中國的大模型正在大幅降價,「內卷」可能不會盡興,外卷的架勢已經拉開。大量AI應用可以基於更高性價比的智能,頻繁試錯,規模落地。阿里巴巴蔡崇信昨日就匪夷所思,美國居然真的有人在談論數以千億美元計的資本開支。
反觀美國,目前,Meta下一代開源模型Llama4,似乎被近幾個月的開源衝擊搞亂了陣腳,遲遲沒有任何消息;xAI的Grok 3要等下一代模型成熟才能開源,主要靠馬斯克在X上的吆喝。
美國在開源模型上行動遲緩,已經引發華盛頓圈的反思,擔心如果中國開發的開源模型主導全球市場,全球計算生態可能轉向中國的芯片架構和計算框架。這一切正在悄然發生,HuggingFace最受歡迎的就是中國開源模型。也許很快,中國最前沿模型開源的趨勢,將從大型語言模型擴展至具身智能等模型,推動先進製造的產業升級。
Gemma 3是Google最新的開源嘗試,它是基於Gemini 2.0的,它曾是全球最好的非推理開源模型,但領先優勢僅僅保持了不足兩週,就被新版V3超越。DeepSeek證明,Google沒有護城河,也逐步證明了美國更沒有,它的優勢越來越成為一種暫時的領先,而且就像實力接近的比賽一樣,與對手呈現出交錯領先的局面。
本文來自微信公眾號:未盡研究 (ID:Weijin_Research),作者:未盡研究


















