Nature:AI擊敗人類醫學專家?哈佛團隊:這一領域仍需解決4大難題
在醫學研究和臨床治療中,準確解讀醫學圖像並生成有洞察力的報告對病人的護理是必不可少的,但卻給人類臨床專家帶來了沉重的負擔。
人工智能(AI),特別是多模態生成式醫學圖像解釋(GenMI)領域的快速發展,為自動化這一複雜過程的部分工作創造了機會。儘管 GenMI 有望在生成跨學科報告方面達到人類專家水平,但仍在準確性、透明度等方面面臨障礙。
釐清這些障礙並提出針對性解決方案,對於幫助臨床醫生改善護理質量、加強醫學教育、減少工作量、擴大專業準入並提供實時專業知識至關重要。
今天,來自哈佛醫學院的研究團隊在權威科學期刊 Nature 上發文,全面綜述了開發從圖像中生成醫學報告的 AI 系統方面的進展和挑戰。
 論文鏈接:https://www.nature.com/articles/s41586-024-07618-3
論文鏈接:https://www.nature.com/articles/s41586-024-07618-3除了分析醫療報告生成的新模型的優勢和應用之外,他們倡導一種新的範式,以授權臨床醫生及其患者的方式部署 GenMI。
在臨床中發揮 GenMI 的優勢
現有的大多數 AI 解決方案都側重於自動完成醫學影像中的單一任務,沒有考慮到放射學和臨床成像中涉及的更全面的綜合分析。
因此,AI 有很大潛力在醫學成像和報告方面實現更廣泛的用途,例如快速撰寫出涉及多科室的權威報告,攝取多種模式和臨床數據,生成更加準確、流暢和可解釋的報告等。
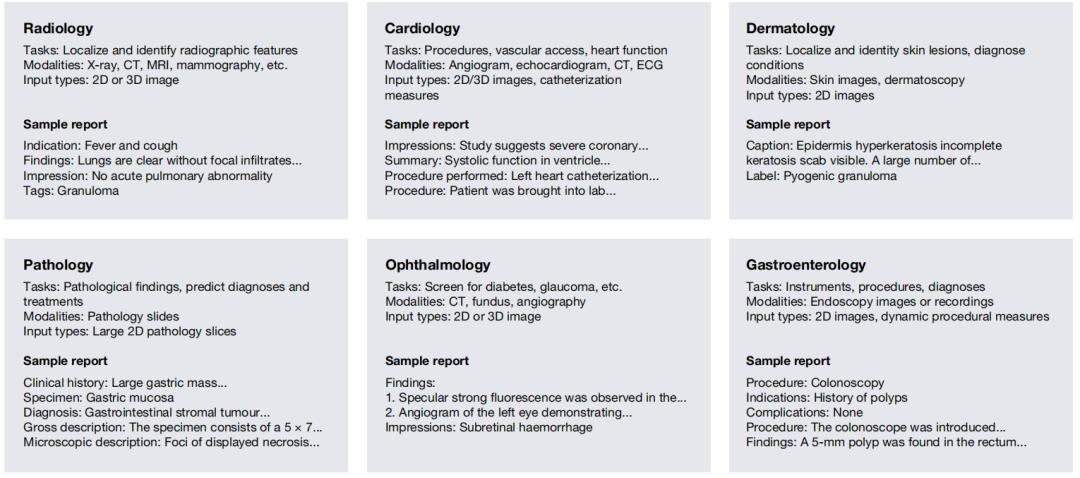 圖|自動生成醫療報告的應用
圖|自動生成醫療報告的應用目前,醫療報告生成框架主要由視覺編碼器和語言解碼器組成。其中,編碼器將圖像中的視覺信息提取為向量表示,而解碼器接收一個向量並產生特定的輸出。
近年來,科研人員在編碼器-解碼器方法的基礎上不斷創新,從而更好地編碼圖像數據、考慮外部知識、篩選異常等。包括大語言模型(LLM)在內的大型預訓練通用 AI 系統,通過推動開發新的 GenMI 解決方案,徹底改變了醫學圖像解釋。
這些 GenMI 方法可以產生更準確的醫療報告,以及使用相同的基礎模型執行其他幾個下遊任務並處理多模態數據。
這些算法大多建立在視覺語言模型(VLM)的基礎上,VLM 將單個視覺和語言模型融合到一個統一的框架中,可以對圖像和文本輸入進行聯合編碼。
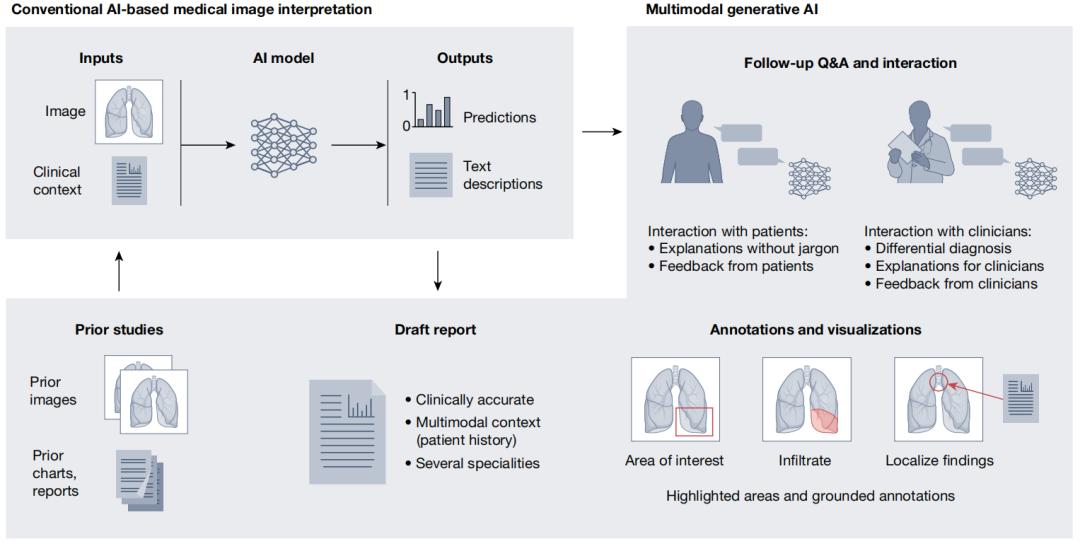 圖|GenMI 的能力
圖|GenMI 的能力利用 GenMI 協助臨床醫生和患者,在臨床環境中充分發揮它們的優勢,可以通過兩個範例來理解。
第一個是部署 AI 住院實習醫師。AI 住院實習醫師首先會專門起草臨床上準確的報告,作為住院實習醫師或醫生撰寫報告的起點。在開發過程中,可以在臨床環境中對模型進行賽前分析性測試。然後,AI 住院實習醫師可以在主治醫師的監督下進行微調或校準,並從所需的修正和補充中學習。
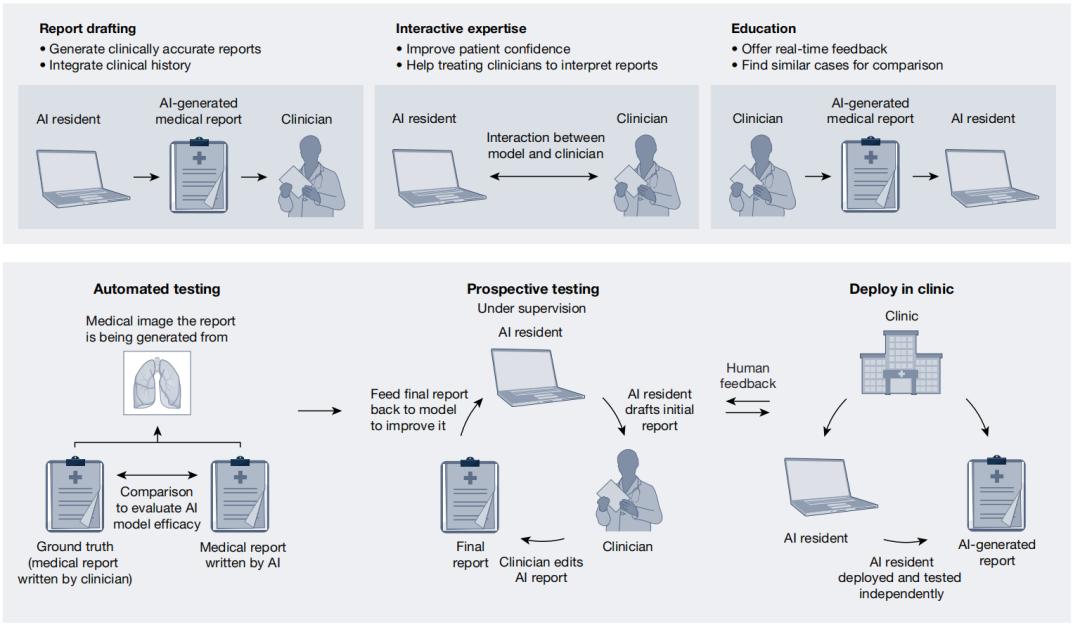 圖|部署 AI 住院實習醫師
圖|部署 AI 住院實習醫師第二個是符合人類偏好。基於人類反饋的強化學習(RLHF)和直接偏好優化(DPO)是應用於此類任務的兩種技術。
對話式醫療報告生成模型,使臨床醫生可以根據需要提供反饋和後續問題,還可以與臨床醫生合作,通過生成式 AI 改變輸入圖像的屬性,觀察模型預測中的相關差異,並將這些差異與臨床醫生識別出的突出特徵進行比較,從而對 AI 成像工具進行審核,還可以對為患者生成的報告進行調整,使其更直白,包含更少的醫學術語,更多圍繞患者病情。
總的來說,臨床醫生可以通過 3 種途徑與 AI 系統協作:
- 利用 AI 模型的診斷能力,獲得診斷錯誤的反饋。模型可以結合多模態輸出,其中的解釋加上在原始圖像上的邊界框,可以突出圖像中以前可能被忽略的相關區域;
- 模型快速解析圖像和報告的能力,有助於臨床醫生快速搜索類似病例和圖像;
- 模型可以協助臨床醫生決策,其提出的探究性問題可以讓臨床醫生深入瞭解與特定病症相關的診斷模式。
仍需克服 4 大挑戰
然而,研究團隊表示,要想發揮 GenMI 等 AI 系統的優勢,還需要解決基準、人類過度依賴、數據集和模型偏差以及新模型、新科室等挑戰。
首先,是基準和評估指標。在安全實施醫學報告生成模型,AI 住院實習醫師將在住院治療中發揮更重要的作用之前,必須開展評估下遊臨床效果的研究,明確衡量標準。
流行的 LLM 的性能會隨著時間的推移而發生顯著變化,這種差異可能會造成嚴重後果。例如,疾病預測模型可能會被操縱以輸出特定的診斷和結果測量,從而導致處方過量、保險欺詐和偽造臨床試驗。
因此,在將 LLM 作為人工智能住院實習醫師的一部分進行部署時,必須確保採取一致的安全措施和監管。
其次,是臨床醫生和患者的過度依賴。臨床醫生可能出於對錯誤問責的模糊性、確認偏差和自動化偏差,過於依賴機器自動化指導等各種原因,不願意更改 AI 生成報告中的文字,忽略模型無法識別的罕見發現。
雖然 AI 住院實習醫師可以讓患者直接與真正的臨床專家進行交流,但這些交流應該在可控的情況下進行,這樣患者就不會依賴 AI 住院實習醫師來指導他們的醫療護理。同時,臨床醫生應向患者傳授正確的查詢方法,並讓他們瞭解 AI 工具,以便自己進行探索。在部署 AI 住院實習醫師的整個過程中,必須承認 AI 系統的局限性,尤其是在直接護理等只有人類才能處理和提供的更廣泛的語境、同理心和認知的領域。
然後,是有偏差的數據集和模型。深度學習模型,尤其是 LLM,很容易受到訓練數據固有偏差的影響。在 AI 住院實習醫師的範例中,這種缺陷尤其容易造成問題,因為模型不僅會在生成的報告中,還會在醫學教育和臨床醫生理解等方面延續這種偏差。
此外,人類的主觀反饋是改進 AI 住院醫師的關鍵因素,而這本身就可能造成有偏見的反饋循環。訓練數據的質量、規模和平衡也是決定模型偏差的重要因素,因此亟需更廣泛、更具代表性的數據集。
目前,大多數進展都是由 MIMIC-CXR 等數據集推動的,這些數據集僅限於單模態胸部 X 光掃瞄,其他數據集也不平衡,除了配對圖像和相關報告普遍不足外,與正常掃瞄相比,異常掃瞄要少得多,並且往往會捕捉到更常見的疾病,而罕見的疾病則很少出現。異常也通常只局限於圖像的一小部分,因此模型很難對其進行篩選。
最後,是新的模式和新的科室。目前,將 GenMI 應用於三維成像(包括 MRI 和 CT 掃瞄)的工作十分有限。部分原因是這一領域缺乏大型標註數據集,只有少數未發佈、稀少或難以獲取的數據集。
除了三維放射圖像,GenMI 還以有限的方式應用於其他科室。眼科和皮膚科的報告生成在一定程度上取得了成功,在其考慮中納入了外部知識和疾病分類等標準技術。儘管納入新科室和圖像類型將擴展 AI 工具的能力,但獲取大規模多模態數據集的成本非常高昂,資源充足的公司或有能力收集或授權使用這些專有數據集。
自動生成醫療報告在減輕臨床負擔、擴大專家級臨床醫療服務覆蓋面方面有廣闊前景。GenMI 可以生成更高質量的報告,通過提供交互式臨床專業知識授權臨床醫生和患者,並通過擴展教育功能改善未來的臨床護理。
研究團隊表示,在不同模式和科室的臨床環境中,製定衡量其效果的公開基準、進行持續的臨床合作和謹慎的模型驗證至關重要,這有助於學術界更透明地衡量報告生成的進展,並為臨床監管機構未來的工作提供指導,使其安全有效。
本文來自微信公眾號「學術頭條」(ID:SciTouTiao),作者:與可,36氪經授權發佈。


















