OpenAI一更新,把我朋友圈變成了吉卜力?
自打前天淩晨,奧特曼這老小子發佈了 GPT-4o 文生圖模型以後,哥們是真被這玩意給刷屏了。
這兩天一打開工作群,就能看到編輯部同事們拿 GPT-4o 瘋狂整活,有做頭像的,有做表情包的,還有畫漫畫的,點子王是一個比一個高。
甚至我一打開小紅書,首頁推送的好多也都是拿 GPT 畫畫的。。。
好好好,看來 OpenAI 這是真支棱了,奧特曼抱完孩子,歸來仍是頂流是吧。
可能有差友還不知道這是發生什麼了,簡單說吧,OpenAI 放出來了個 GPT-4o 文生圖模型,這玩意直接讓用嘴 P 圖、敲字畫圖的離譜需求,成了可能。
不僅在他們官網直接就能用,而且效果可以說是相當攢勁,當時看完我就一個想法,這波可能要把不少 AI 從業者和設計師們都給整得懷疑人生了。。。

你瞅瞅他們官網的演示案例,像什麼抓拍的馬克思、心有猛虎的小貓;還有讓簡單的草圖變成照片、讓倒影里的攝影師轉過身來和你擊掌什麼的,這特麼你告訴我居然沒P圖?
於是,昨天一大早,哥們就爬起來充了 20 刀,直接上手就是一個測的開。
爽玩了一天以後,我只能說,雖然瑕疵還是有不少,但至少從四個方面看,OpenAI 這一波的生圖功能,確實又秀又6。

首先,畫面保持和圖片風格轉化方面,4o 主打一個駕輕就熟。
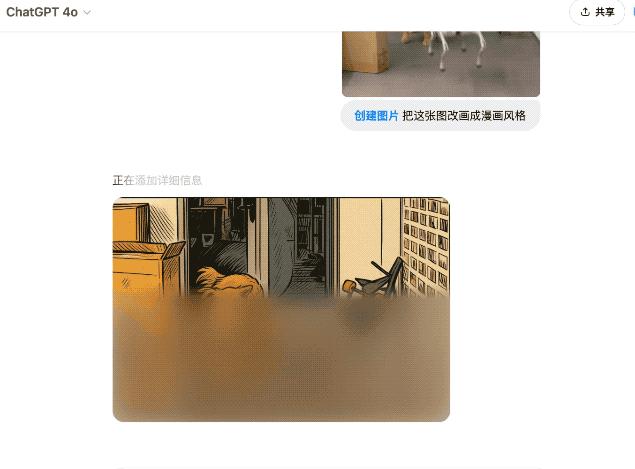
在經過了金毛火鍋的同意下,我們拿出了一張火鍋和機器狗的對峙照片,來讓 AI 轉成漫畫版。

你瞅瞅,這神態,真別說還挺對味的。
雖然細節上有點翻車,把火鍋眼睛補上了,但鑒於咱給的圖也比較糊,倒也可以理解。
反過來,把畫改成真實風格,這玩意搞得也不錯,我們也上傳了一張刻在不少人基因里的孔子圖片,讓它以此為原型,生成一張真實照片。

反正看到效果,不知道大夥們感受到一股時空穿越的感覺沒?
對比一下目前其他搞得不錯的文生圖模型,大夥兒可能就會對GPT-4o到底什麼水平有個參考了。
下面這幾幅都是同一套提示詞搞出來的,依次是 Midjourney , ImageFX , GPT-4o和之前挺火的 Gemini-2.0-flash-exp 。

很明顯,GPT-4o 和 Midjourney 是一檔的,而且效果可以說遙遙領先於同行。。。
不過,雖然類似風格轉化和逼真圖像生成的活,像 Midjourney 之類的 AI 也能跟 GPT-4o 掰掰手腕,大夥們之間頂多就是 80 分和 90 分之間的差別。
而接下來的四點,可能真的就是 Only OpenAI can do 了。

第一個是在文本的渲染上,4o 模型這次殘暴得甚至有點可怕。
看下面這個,我讓他生成一個學者在白板上寫量子力學的公式和理論,雖然內容我也基本告訴它了,但這又有數學公式又有框圖的,怎麼說也很難整對吧。

結果人家全識別出來整到板書上去了,白板的倒影效果甚至都能做出來。
以防大夥們不知道這是個什麼水平,相同的提示詞,我用 OpenAI 某友商旗下的模型試了試,效果是這樣的。
雖然看起來是那麼一回事情,但細看一下圖里的文字內容,你就知道為什麼 OpenAI 這波有點強得離譜了。

第二個就是在多主體的生成上,4o 模型這次主打一個又準又狠。
比如大夥們請看這段提示詞,小小的一段話裡面暗藏玄機,7個不同的元素里,個數和顏色都不一樣。。。

其他模型這邊,則直接慌了陣腳,交出了這樣的作業,在數字上翻了車。

反觀 OpenAI 這邊,分毫不差地執行了咱的要求,穩如老狗簡直是。
按照 OpenAI 的說法,其他模型在處理 5-8 個對象時就頂不住了,而 4o 最多能處理 10-20 個不同的對象。
而且你要回頭細品,還會發現 OpenAI 的圖里元素都不是跟別的模型一樣隨機擺放的,而是有設計,像是一個有故事的動畫場景一樣。。。

最後一點,我覺得最牛的,那就是 4o 的圖片生成模型在對於文字和圖像的理解這方面,就跟長了腦子一樣。
比如說在複雜指令,特別是在長文本上理解上,它不僅能搞懂你想表達什麼,還跟開掛一樣,能把你要的那個畫面直接給到。
咱在測試的時候還專門給它上了強度,叫它畫一個房間里的大象,但不能讓觀眾直接看見有大象,得是那種明明存在,但所有人都看不見,但在氛圍里又真的存在的大象。
很刁鑽是吧,就是像這種複雜指令,你看看它怎麼處理。

該說不說,看到這個圖的時候我是真沒想到,這人家都能畫出來,還是寫實風格的,用光影搞了一個透明的空氣大象。
除了理解,它這種把知識作為鏈接,真正能把讓文本和圖像聯繫起來的能力尤其出色。
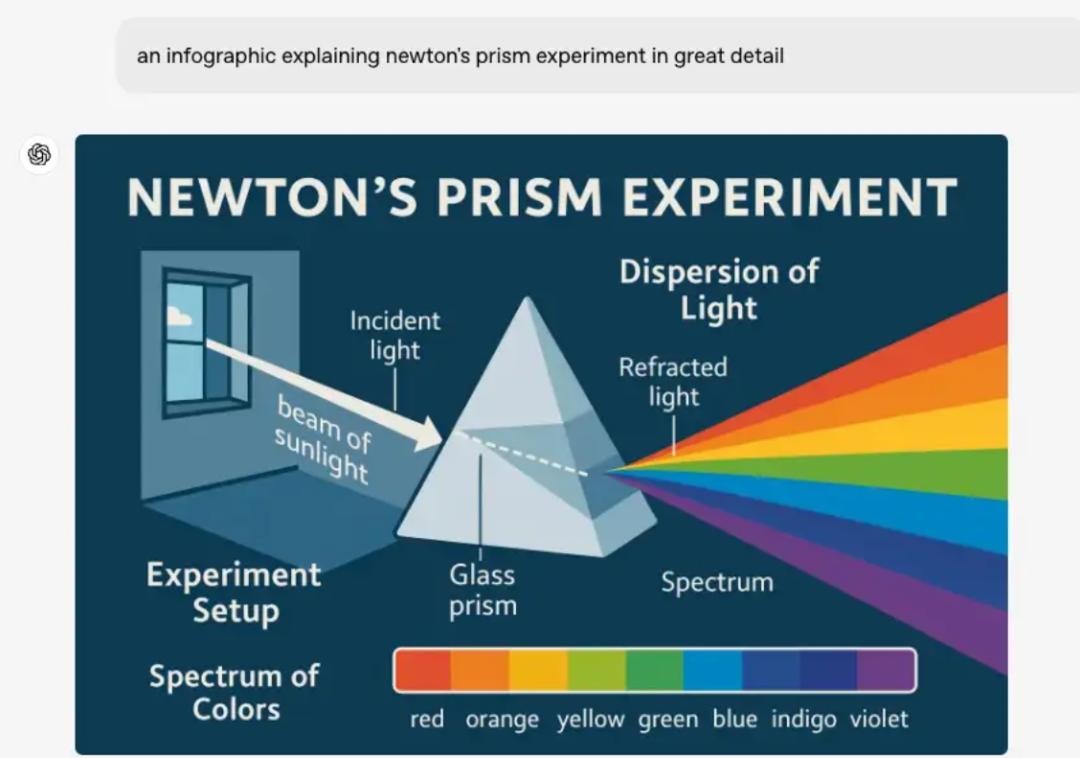
舉個例子,不給任何參考信息,讓它直接用插圖解釋一樣牛頓發現的光的折射原理,他能直接給出教科書級的專業插圖。
所以說,這 OpenAI 也是支棱起來了,在大家都以為他要拉的時候,搞出來這麼一個牛逼哄哄的東西。
不過,這玩意之所以比以往的文生圖模型厲害,裡邊其實也有一些說法。
在技術博客里,OpenAI 說他們用的是自回歸方法,而不是以前文生圖里常用的Diffusion 擴散模型。前者是不停靠之前的信息來預測後面的,再用後面的預測更後面的;Diffusion 則是讓模型從一堆亂碼中,逐漸從混亂變清晰。

相比 Diffusion,自回歸的好處恰恰就是在語義識別上更牛,特別是你要給出嘮嘮叨叨的一大串需求的時候,以前的文生圖模型就理解不全面,所以大家老是沒法跑出來符合自己心意的圖。
所以在用 GPT-4o 問生圖的時候你就會發現,這玩意出圖實際上也是從上往下,一點一點畫出來的,就跟 AI 寫文章一樣一個詞一個詞往外蹦,這就很自回歸。
好玩的是,OpenAI 第一次大火就是在用了自回歸 Transformer 模型的GPT-3.5上,沒想到現在圖片生成領域,他們又靠著自回歸扳回一局。
當然了,用了這種新方法,可能生成圖片的時間會稍微長一點,但是 OpenAI 覺得,為了這麼高質量的圖片,這點時間還是值得的。

或許也因為是自回歸模型的原因,GPT-4o 生成的圖片也會出現一些大模型幻覺。
但這倒不是多根手指什麼的,而是圖片元素如果過多,或者長度太長,到後面就會崩了。
比方下面這個,我們讓它生成一堆元素貼紙組成的海報:

結果雖然你一打眼覺得它好像搞得像模像樣,但細看就會發現,它多搞了機器人和衝浪者,弄失了無人機,就還是比較馬虎的。
官方博客還說,他們雖然在拉丁文字處理上整挺好,但對別的小語種,就不大行了。
比如我們搞點三哥那邊的文字,它給生成的就有問題,細節上也是缺胳膊少腿的。

但話又說回來,這其實也都能理解。照我看,相比 GPT-4o 尚有的這些小缺點,這玩意給業界最大的震撼恐怕還不止是圖片質量,而是它越來越讓人意識到,AI更新的速度實在是太快了。
以前費老大勁研究出來的那些所謂的「經驗」,在模型能力突飛猛進面前,真的就顯得有點尷尬,甚至可能一夜之間就變得毫無價值。
比如有個老哥,看到 GPT-4o 的效果以後,心態就崩了。
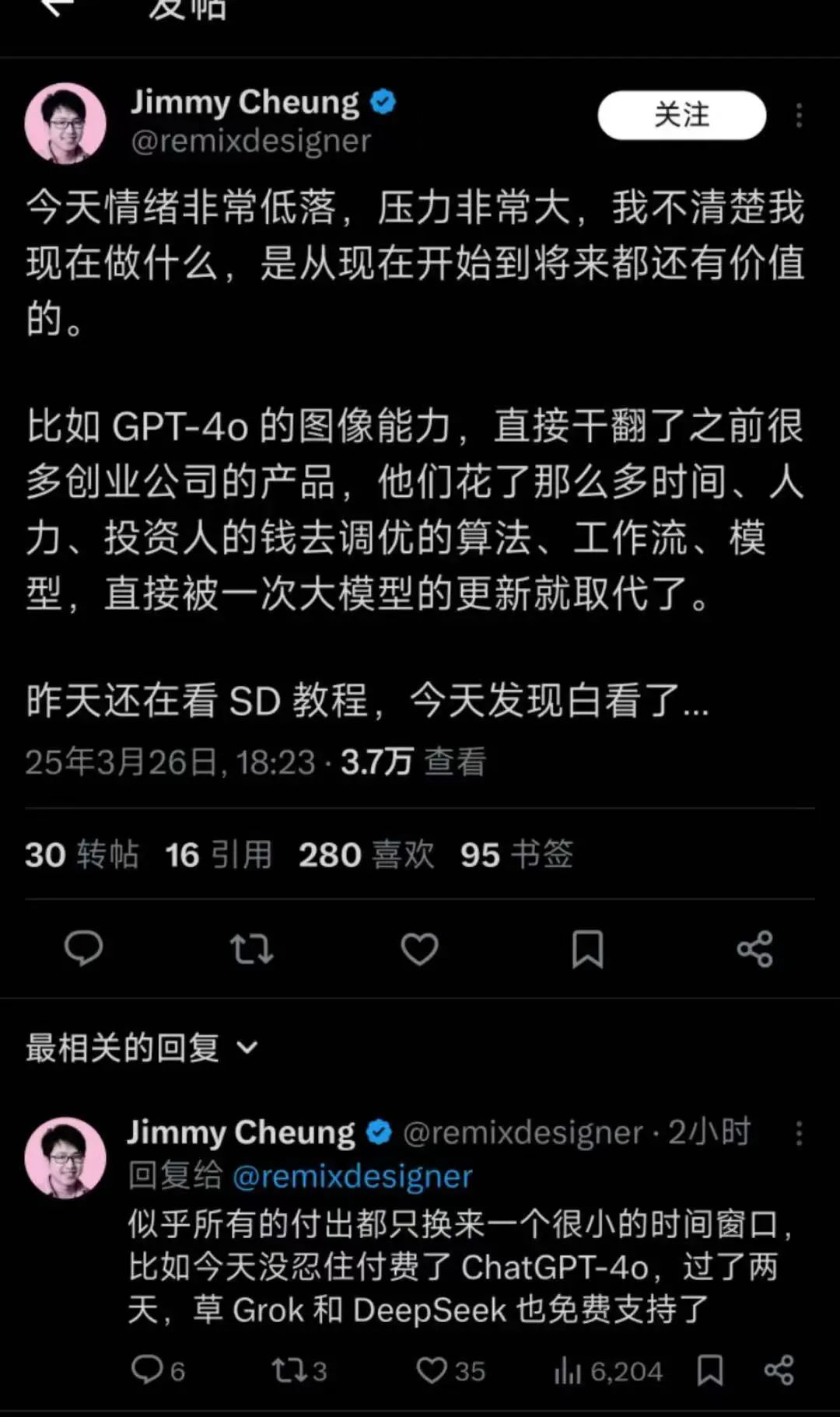
好不容易花了大把時間,又是琢磨提示詞,又是各種調參,剛把一個提示詞或者工作流弄得差不多能打個 70 分了,結果沒過幾天,人家又冒出來個知識庫加工作流的新玩意兒,直接把之前的努力給頂替了。等你剛適應了知識庫加工作流,還沒捂熱乎呢,更厲害的智能體又來了。
所以說這麼來看的話,我們使用AI的這些經驗,保質期實在跟不上 AI 的速度,於是真正能讓你立於不敗之地的,還得是模型本身的能力夠不夠硬。
也就是說,模型能力強了,很多以前需要我們絞盡腦汁去琢磨的東西,模型自己就能輕鬆搞掂,我們的創造力也能更自由,而這,才是技術爆發時代對人的紅利。
本文來自微信公眾號「差評X.PIN」,作者:納西,編輯:江江 & 麵線,36氪經授權發佈。