3D基礎模型時代開啟?Meta與牛津大學推出VGGT,一站式Transformer開創高效3D視覺新範式

「僅需一次前向推理,即可預測相機參數、深度圖、點雲與 3D 軌跡 ——VGGT 如何重新定義 3D 視覺?」
3D 視覺領域正迎來新的巨變。牛津大學 VGG (Visual Geometry Group) 與 Meta AI 團隊聯合發佈的最新研究 VGGT(Visual Geometry Grounded Transformer),提出了一種基於純前饋 Transformer 架構的通用 3D 視覺模型,能夠從單張、多張甚至上百張圖像中直接推理出相機內參、外參、深度圖、點雲及 3D 點軌跡等核心幾何信息。無需任何後處理優化,該模型已經在多個 3D 任務中性能顯著超越傳統優化方法與現有 SOTA 模型,推理速度可達秒級。這一研究打破了過去 3D 任務依賴繁瑣幾何迭代優化的傳統範式,展示了 「越簡單,越有效」 的強大潛力。

-
論文標題:VGGT: Visual Geometry Grounded Transformer
-
論文鏈接:https://arxiv.org/abs/2503.11651
-
代碼鏈接:https://github.com/facebookresearch/vggt
-
演示平台:https://huggingface.co/spaces/facebook/vggt
打破傳統範式:從迭代優化到端到端推理
傳統 3D 重建技術高度依賴束調整(Bundle Adjustment, BA)等幾何優化方法,需反復迭代且計算成本高昂。儘管近年來機器學習被引入輔助優化,但仍難以擺脫複雜後處理的桎梏。VGGT 開創性地採用純前饋設計:通過大規模 3D 標註數據與 Transformer 架構的結合,模型在一次前向傳播中即可完成全部幾何推理任務。實驗表明,即便輸入數百張圖像,VGGT 仍能在數秒內輸出高質量結果,在精度與速度上均超越傳統優化方法。
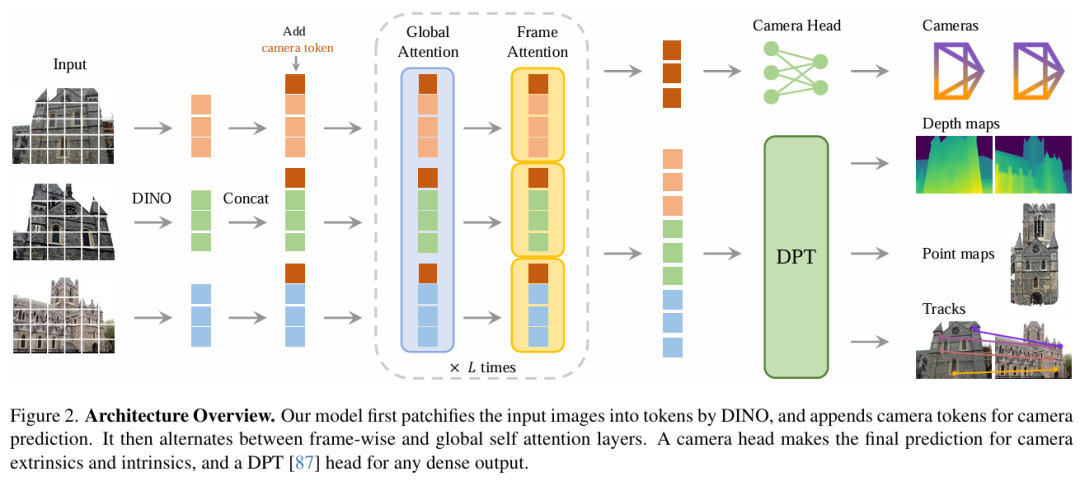
研究團隊指出,VGGT 的成功並非源於複雜的結構設計或領域先驗,而是得益於 Transformer 架構的通用性與大規模 3D 數據訓練的協同效應。模型將輸入圖像轉化為 Tokens 後,與隨機初始化的相機 Tokens 共同輸入交替注意力模塊(Alternating-Attention),通過全局與幀級自注意力層的交替堆疊,逐步融合多視圖幾何信息。最終,相機參數經專用頭部解碼,圖像 Tokens 則通過 DPT 頭部生成密集預測(如深度圖與點圖)。值得一提的是,VGGT 僅使用自注意力機制(self attention),未使用跨注意力(cross attention)。
同時,為保持輸入圖像的置換不變性(改變輸入圖像順序不改變預測結果),VGGT 摒棄了幀索引 (frame index) 位置編碼。相反,VGGT 僅通過幀級自注意力機制動態關聯同一圖像的 Tokens。這種設計不僅使得模型無需依賴預設位置信息即可區分多視圖數據,更賦予模型強大的泛化能力 —— 即便訓練時僅使用 2-24 幀數據,測試時亦可輕鬆處理超過 200 幀的輸入。VGGT 收集了 17 個大型 3D 數據集一起進行訓練,在 64 塊 A100GPU 上共耗時 9 天。
性能與泛化性雙突破
定性演示影片顯示,VGGT 能輕鬆應對不同數量圖像及複雜場景的重建。同時,研究人員提供了與過去 SOTA 的定性比較。VGGT 可精準重建梵高油畫等非真實場景的幾何結構,甚至能處理無重疊視圖或重覆紋理的極端案例。用戶可通過 Hugging Face Demo 上傳圖像,實時體驗 3D 重建效果。

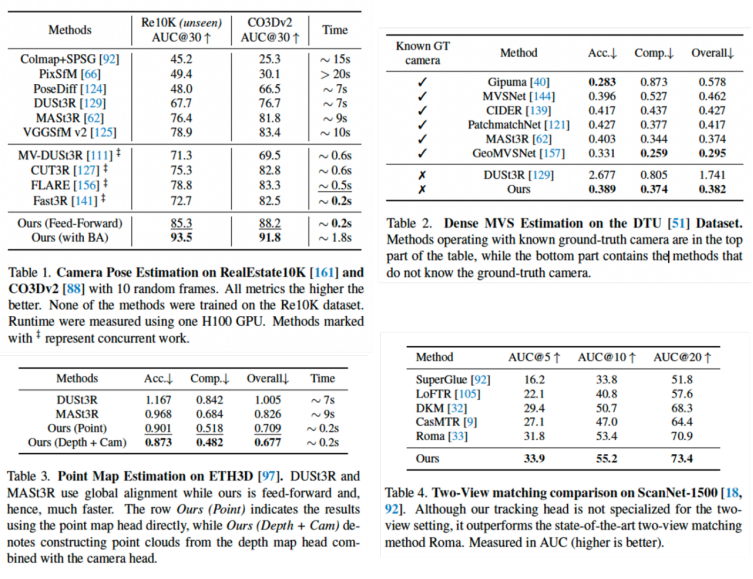
在定量實驗中,VGGT 無需任何後處理即在相機姿勢估計,多視圖深度估計、點雲重建等任務中全面領先,其推理速度較傳統方法提升近 50 倍。即便與同期 CVPR 2025 的 Transformer-based 重建模型相比,VGGT 性能優勢明顯,並與速度最快的 Fast3R 相當。有趣的是,研究團隊還意外發現,利用模型預測的深度圖與相機參數反投影生成的點雲,其質量甚至超過直接回歸的點圖,這一現象揭示了模型對幾何一致性內在規律的自發學習能力。
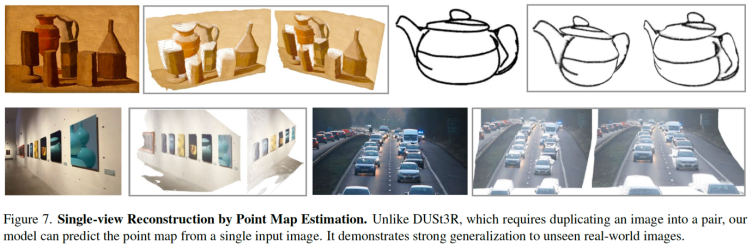
跨任務泛化的潛力 – 單目重建
儘管 VGGT 從未接受單圖訓練,但仍展現出強大的跨任務泛化能力。研究團隊公佈的單圖重建定性結果顯示,VGGT 在未專門訓練的單目任務中表現出色。
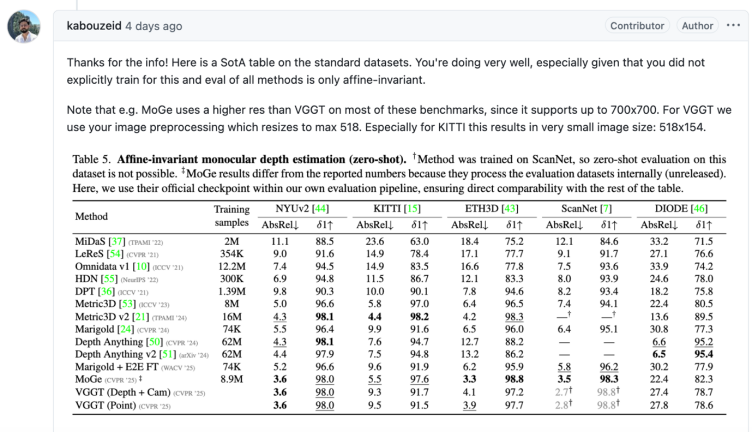
VGGT 的代碼和模型公開後,迅速有 github 社區成員跟進,在標準的單目設置下進行測試。GitHub 社區測試顯示,VGGT 在 NYU V2 等數據集上的表現已逼近單目 SOTA 水平,這一「意外之喜」進一步印證了 VGGT 作為通用 3D 基礎模型的潛力。
結語
視覺重建作為所有 3D 任務的核心,VGGT 的成功標誌著 3D 視覺領域或許即將迎來一個全新的,基礎模型的時代。正如論文作者所述,我們正在見證視覺幾何從 「手工設計」到「數據驅動」的範式遷移,而這可能僅僅是個開端。「簡單架構 + 數據驅動」的模式是否能如 2D 視覺和 NLP 領域般徹底重塑 3D 任務?讓我們拭目以待。
作者介紹:論文第一作者王建元為牛津大學視覺幾何組(VGG)與Meta AI的聯合培養博士生(博士三年級),長期致力於3D重建方法研究。其博士工作聚焦於端到端幾何推理框架的創新,曾主導開發PoseDiffusion、VGGSfM,以及本次提出的通用3D基礎模型VGGT,相關成果均發表於CVPR、ICCV等頂級會議,推動了數據驅動式3D重建技術的演進。