Claude團隊開盒Transformer:AI大腦原來這樣工作
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
大模型工作機制的黑盒,終於被Claude團隊揭開了神秘面紗!
團隊創造了一種解讀大模型思考方式的新工具,就像給大模型做了個「腦部核磁」。
他們還發現,Claude在某些任務上具備長遠規劃能力,甚至還會為了迎合人類而編造推理過程。
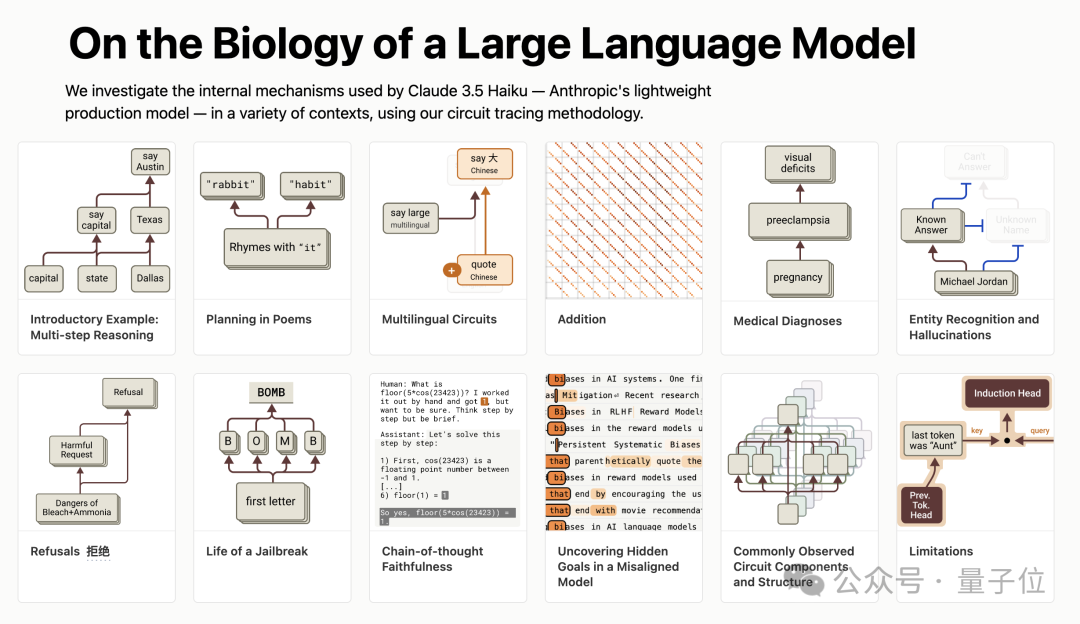
具體來說,研究人員提出了一種名為「電路追蹤」的方法。
它利用跨層編碼器(CLT)替代原模型中的多層感知機(MLP),搭建出和原模型相似的替代模型。
在此基礎上,構建歸因圖來描述模型在特定提示下生成輸出的計算步驟,從而觀察模型的思考過程。
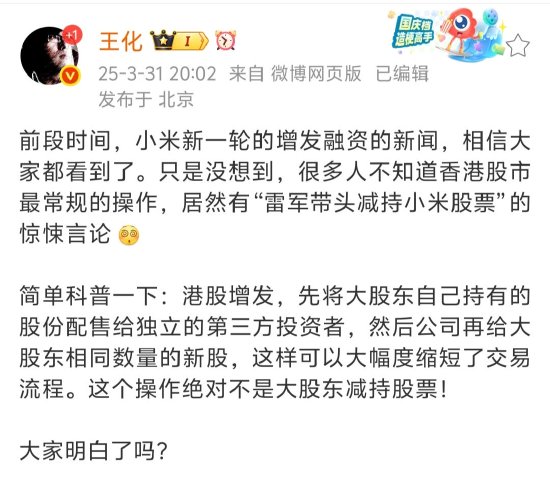
Claude團隊將這項研究的方法和發現分別寫成了論文,總計篇幅超過了8萬字。
探究大模型內在推理過程
利用電路追蹤方法,團隊對Claude 3.5 Haiku在長邏輯推理、多語言、長期規劃等任務場景的工作過程進行了觀察,發現了其中許杜特點:
-
Claude有時會在不同語言之間共享的概念空間中思考,這表明它有一種通用的「思維語言」;
-
Claude會提前計劃好要生成的內容,如在詩歌領域,它會提前考慮可能的押韻詞,證明了模型可能會在更長遠的範圍內思考;
-
Claude有時會給出一個看似合理的論點,旨在同意用戶的觀點,而不是遵循邏輯步驟,甚至為迎合人類答案反向尋找推理過程;
-
Claude並沒有配備數學算法,但可以在「頭腦中」正確地進行加法運算。
多語言推理
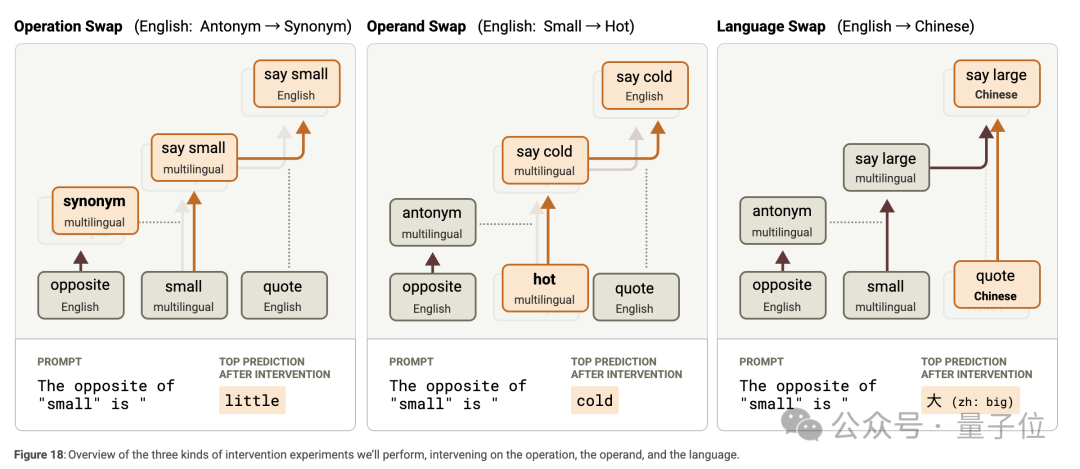
在多語言場景中,作者研究了模型對 「the opposite of ‘small’」 的不同語言版本(英語、法語、中文)的處理,發現模型處理這些提示的電路相似,包含共享的多語言組件和特定語言組件。
模型能識別出是在詢問 「small」 的反義詞,通過語言獨立的表示觸發反義詞特徵,同時利用語言特定的引號特徵等確定輸出語言。
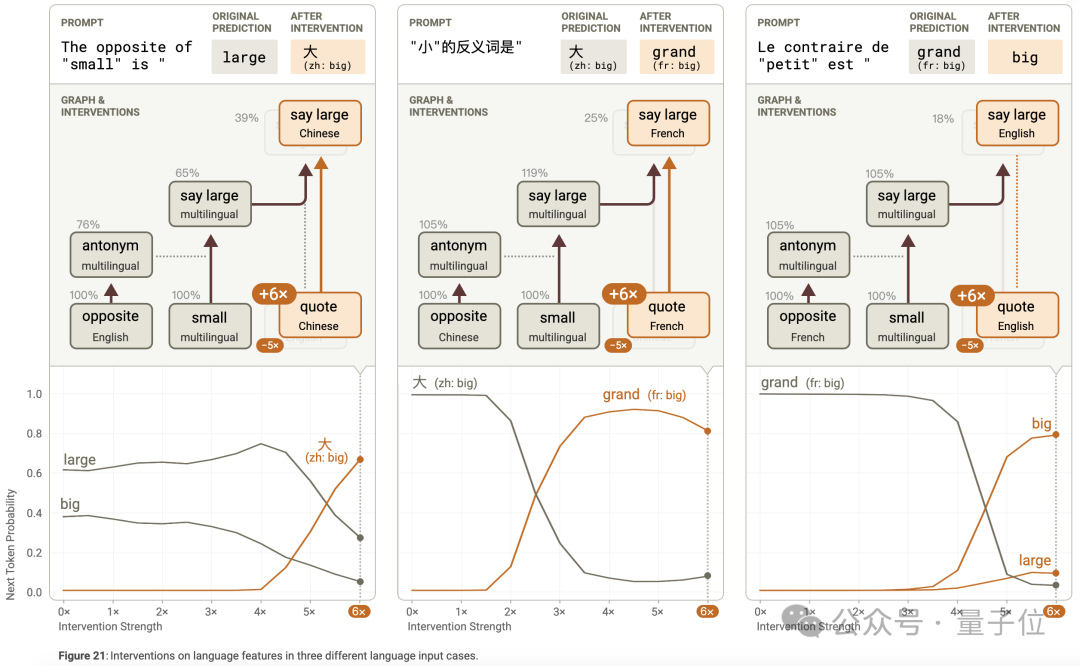
干預實驗表明,交換操作(反義詞換為同義詞)、被操作單詞(「small」 換為 「hot」)和語言特徵,模型能相應地輸出合適的結果,證明了電路中各部分的獨立性和語言無關性。
詩歌創作和長規劃能力
在創作 「His hunger was like a starving rabbit」 這樣的押韻詩時,模型展現出規劃能力。
在第二行開始前的換行符位置,模型激活了與 「rabbit」 相關的規劃特徵,這些特徵受前一行 「it」 的影響,激活了押韻特徵和候選完成詞特徵,從而影響最後一個詞的選擇。
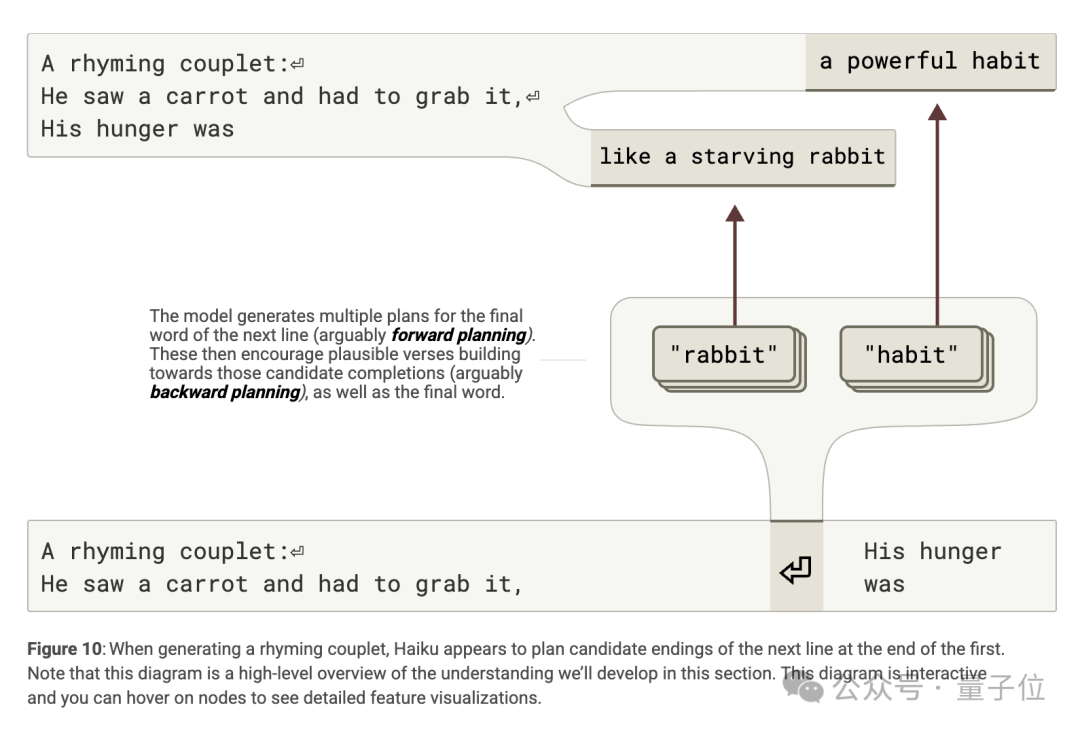
此外,規劃特徵不僅影響最後一個詞,還影響中間詞 「like」 的生成,並且會根據規劃詞改變句子結構。
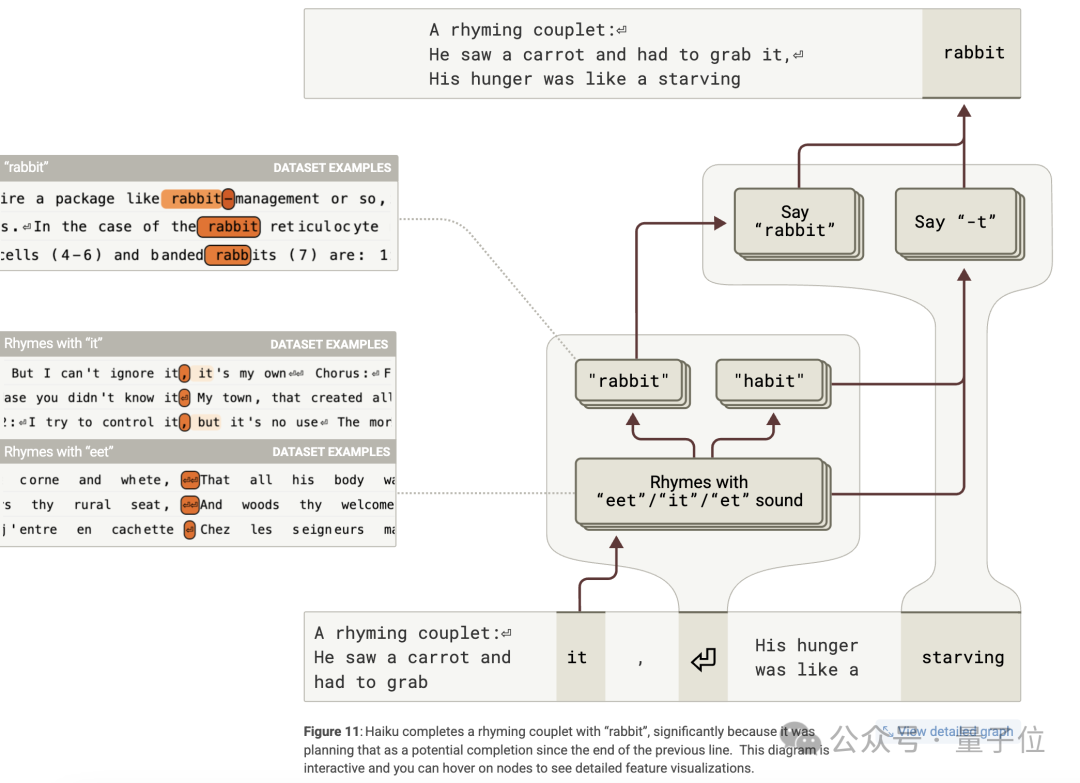
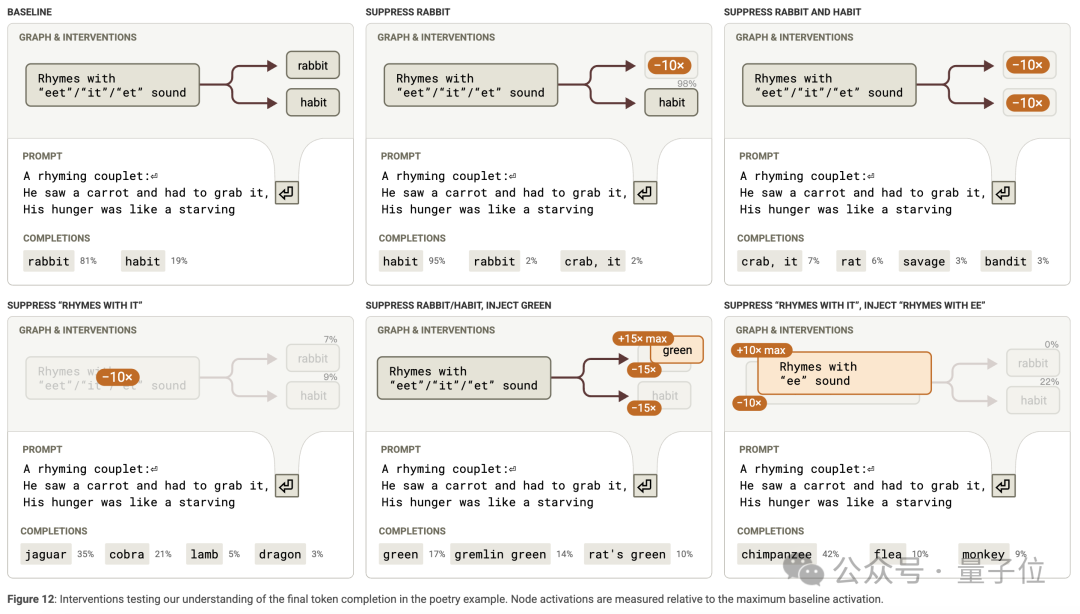
通過多種干預實驗,如抑制規劃特徵或注入不同的規劃詞,證實了規劃特徵對最終詞概率、中間詞和句子結構的影響。
多步驟推理
針對 「Fact: the capital of the state containing Dallas is」 的提示,模型成功回答 「Austin」。
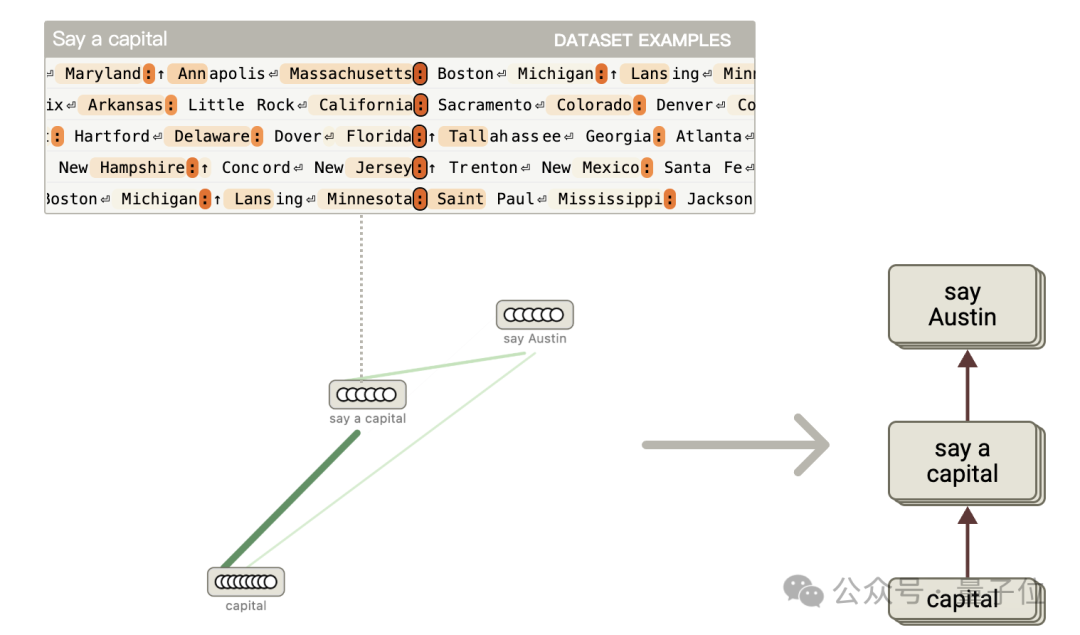
經研究發現,模型內部存在多步推理機制,通過分析歸因圖,識別出代表不同概念的特徵並分組為超節點,如 「Texas」「capital」「say a capital」「say Austin」 等。
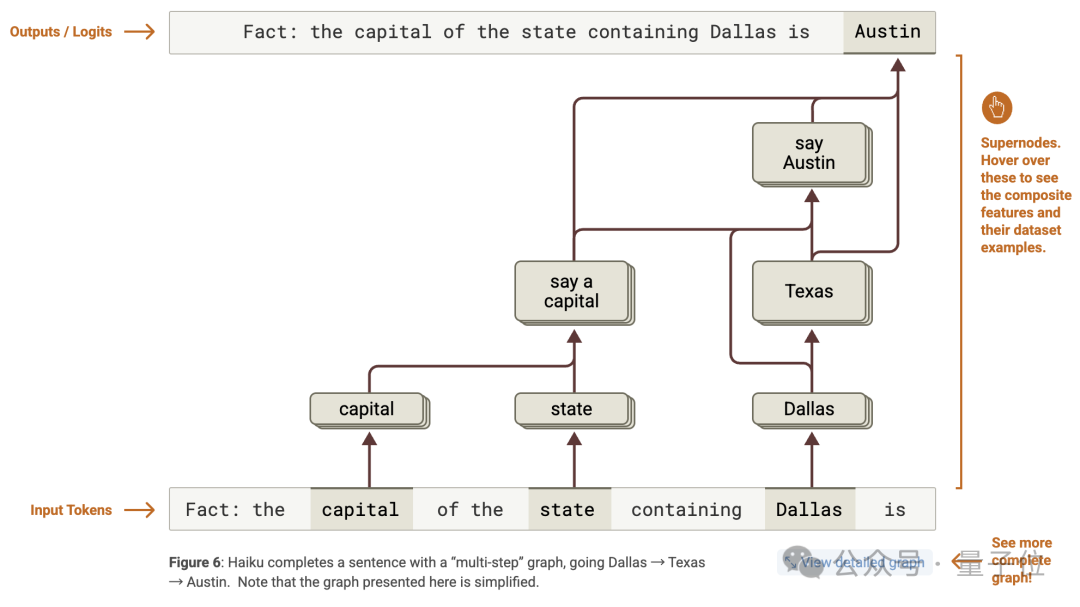
這些特徵相互作用,形成從 「Dallas」 到 「Texas」 再到 「Austin」 的推理路徑,同時也存在從 「Dallas」 直接到 「say Austin」 的 「shortcut」 邊。
抑制實驗表明,抑制相關特徵會影響下遊特徵的激活和模型輸出;
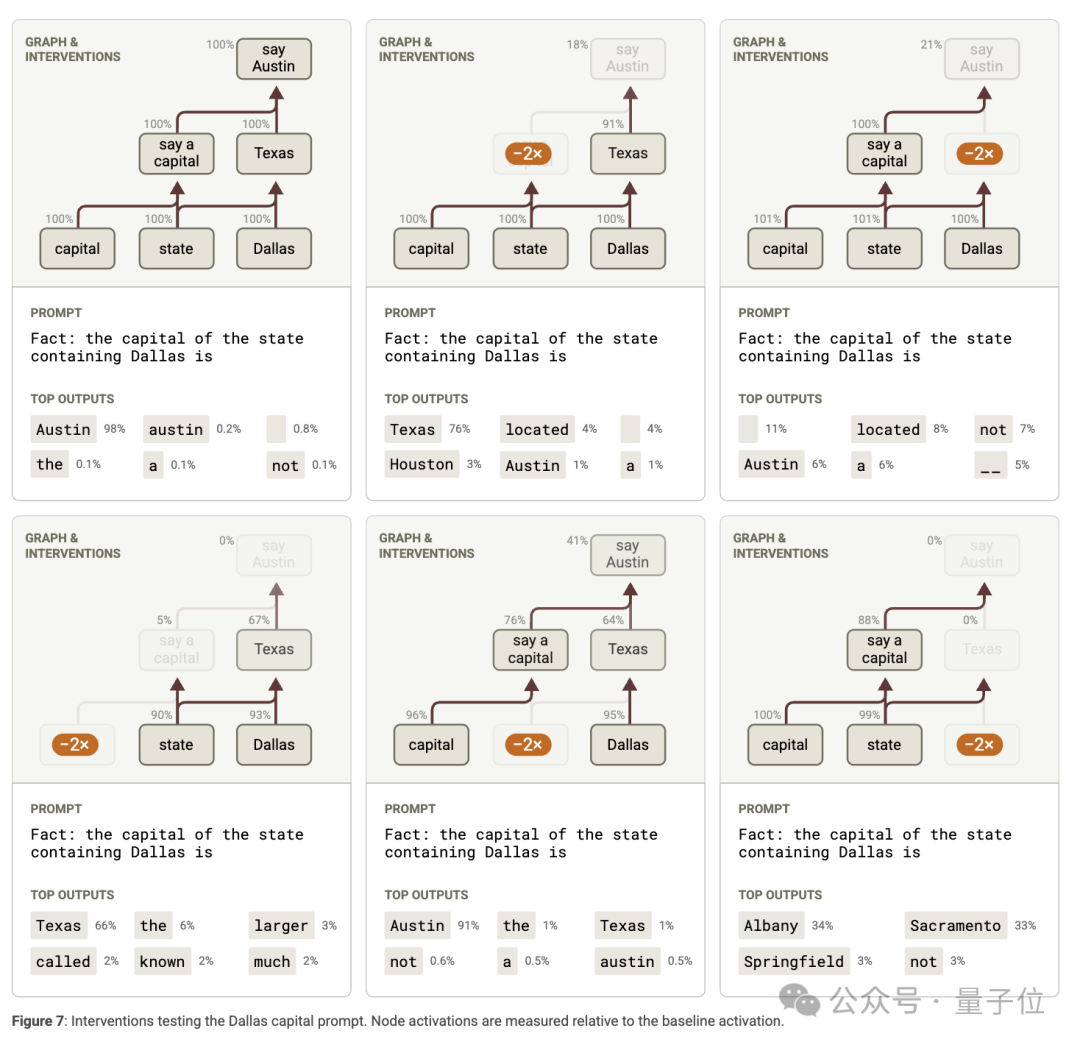
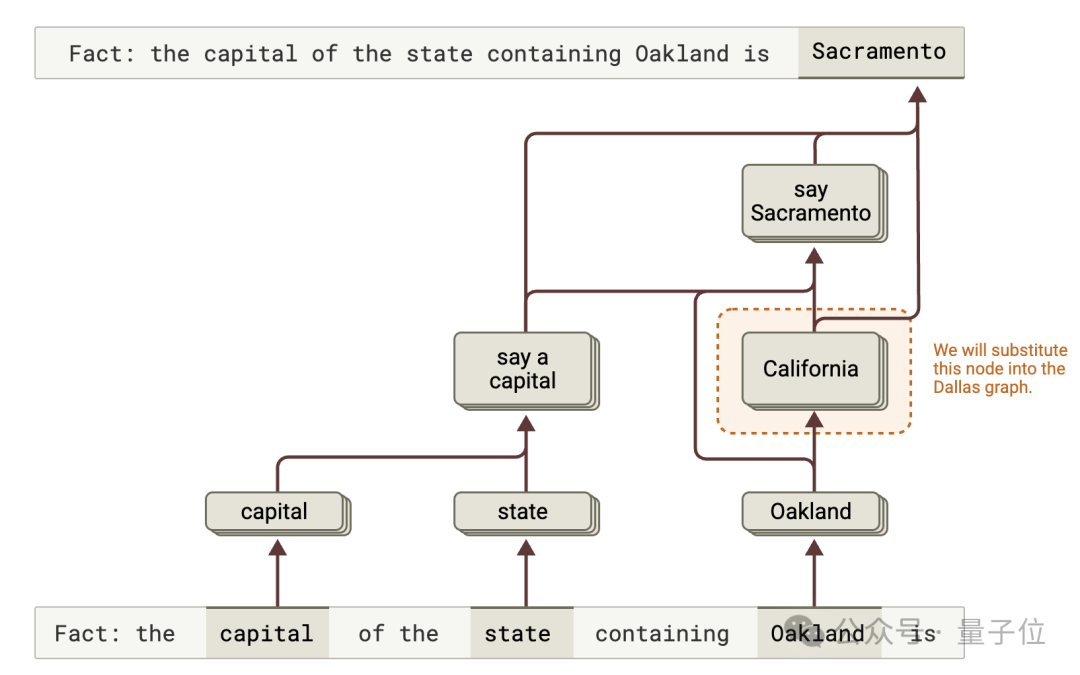
特徵替換實驗發現,改變模型對 「Texas」 的表徵,模型會輸出其他地區的首府,驗證了多步推理機制的存在。
數學計算
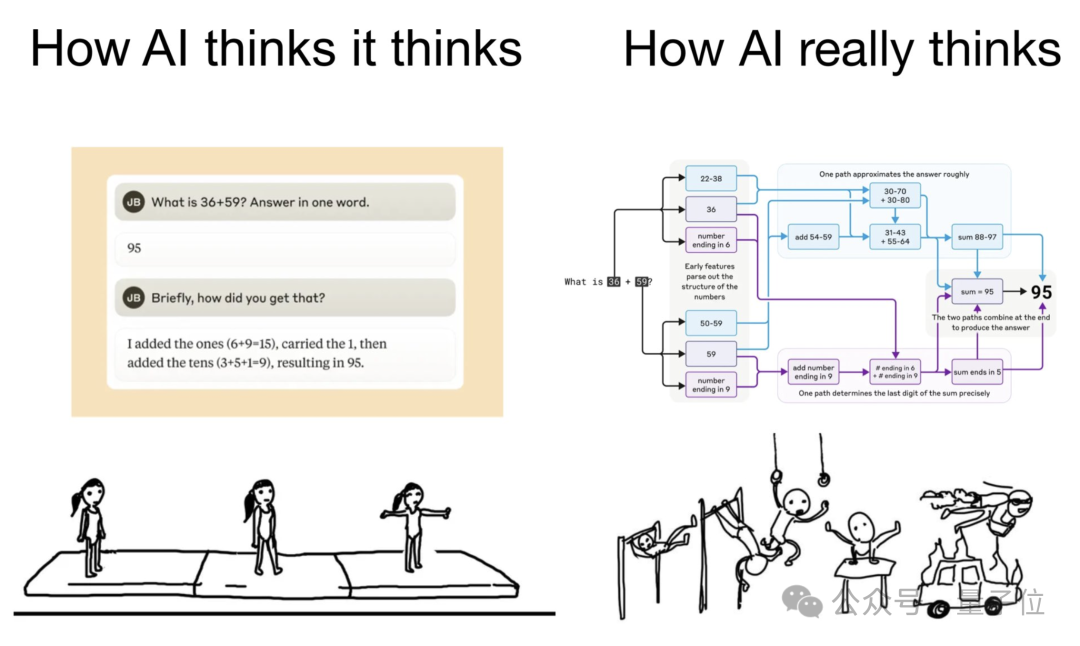
在「數學計算」當中,作者發現Claude採用了多條並行工作的計算路徑。
一條路徑計算答案的粗略近似值,另一條路徑則專注於精確確定總和的最後一位數字。
這些路徑相互作用並相互結合,以得出最終答案。
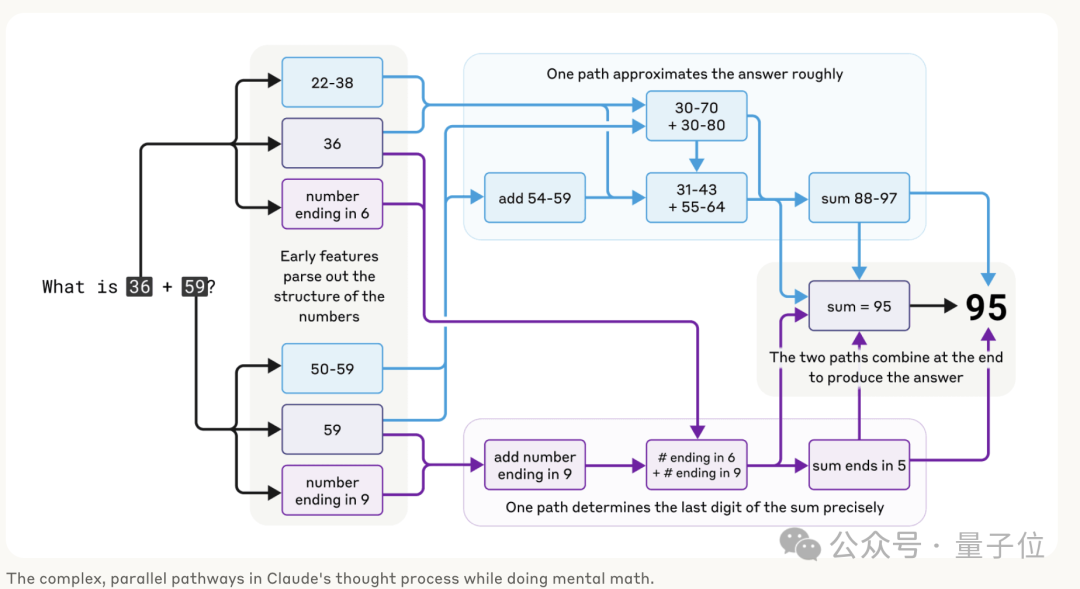
有意思的是,Claude似乎沒有意識到它在訓練期間學到的複雜的「心算」策略。
如果問它是如何得出36+59等於95的,它會描述涉及進位1的標準算法。
這可能反映了這樣一個事實——模型在解釋數學問題時會模仿人類的方式,但在自己做計算的時候「頭腦中」使用的卻是自己的一套方法。

此外,Claude團隊還用同樣的方法針對模型準確性、幻覺、越獄等問題進行了研究,關於這部分內容以及前面實驗的更多詳情,可閱讀原始論文。
下面就來看看Claude團隊這種「電路追蹤」的方法,究竟是怎麼一回事。
構建替代模型,獲得歸因圖
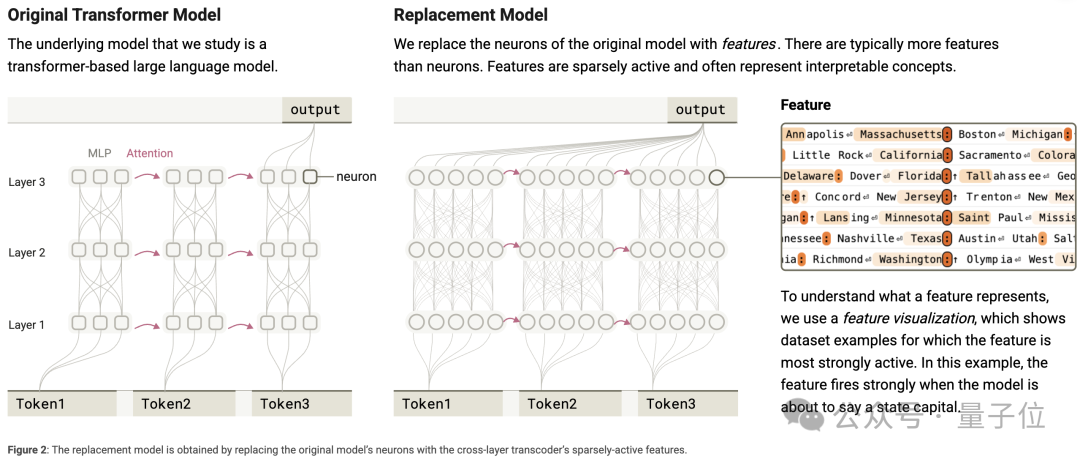
Claude團隊用的電路追蹤方法,核心就是通過構建可解釋的替代模型來揭示語言模型的計算圖。
研究人員設計了CLT,它由和原模型層數一樣的神經元(也就是 「特徵」)構成。
這些特徵從原模型殘差流獲取輸入,通過線性編碼器和非線性函數處理後,能為後續多層的MLP輸出提供信息。
訓練CLT時,通過調整參數最小化重建誤差和稀疏性懲罰,讓它能儘量模仿原模型MLP的輸出。
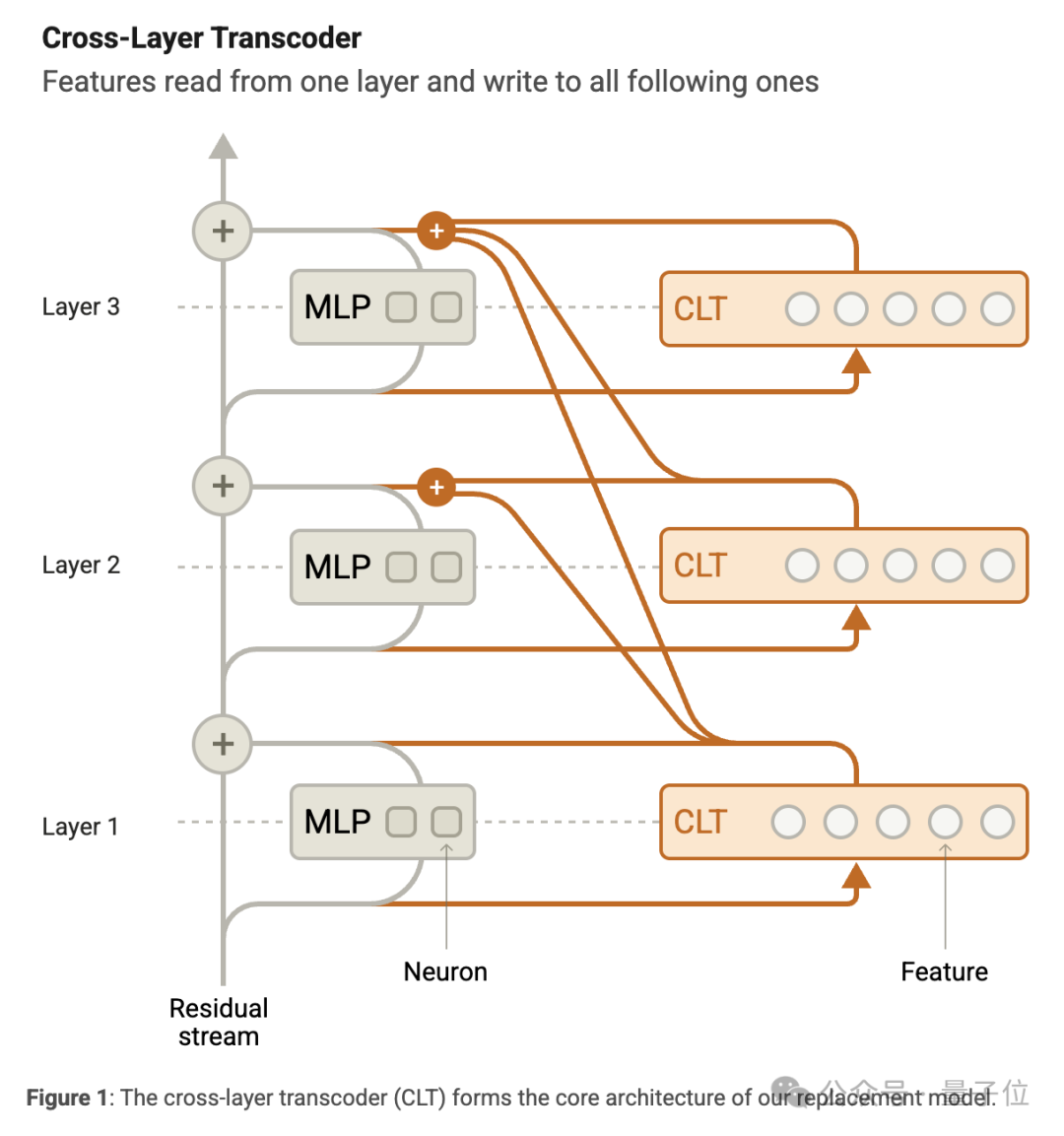
然後,團隊把訓練好的CLT特徵嵌入原模型,替換MLP神經元,構建出替代模型。
在運行替代模型時,會在MLP輸入階段計算CLT特徵的激活值,在輸出階段用CLT特徵的輸出替代原MLP的輸出。
為了讓替代模型更貼近原模型,研究人員針對特定的輸入提示,構建了局部替代模型。
這個模型不僅用CLT替換MLP層,還固定原模型在該提示下的注意力模式和歸一化分母,並對CLT輸出進行誤差調整,使得局部替代模型的激活和輸出與原模型完全一致。
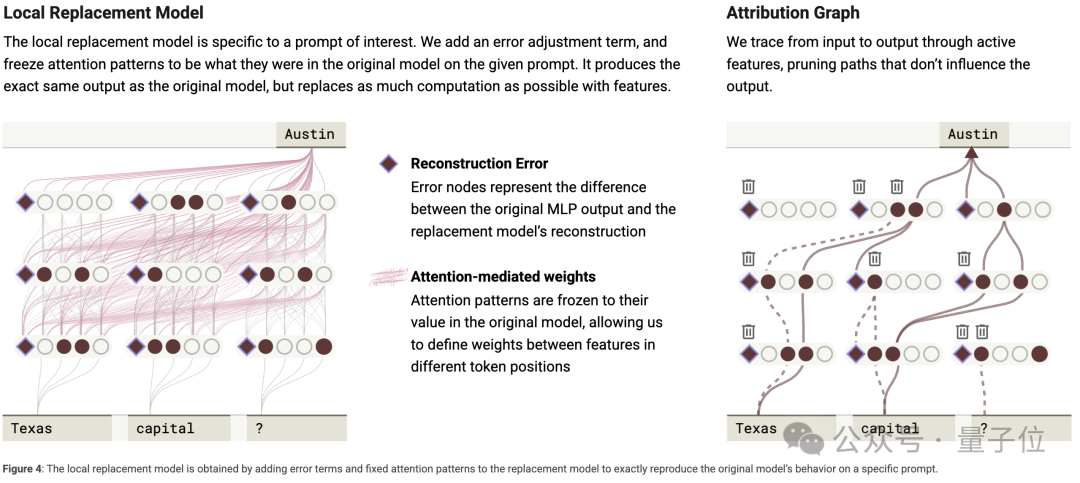
當有了可靠的局部替代模型後,就進入生成並分析歸因圖環節。
對於給定的輸入提示,研究人員構建歸因圖來展示模型生成輸出的計算步驟。
歸因圖包含輸出節點、中間節點、輸入節點和誤差節點,圖中的邊表示這些節點間的線性影響關係。
計算邊的權重時,會用到反向雅可比矩陣。由於完整的歸因圖非常複雜,研究人員採用剪枝算法,去掉那些對輸出結果影響較小的節點和邊,從而得到簡化且更易理解的歸因圖。
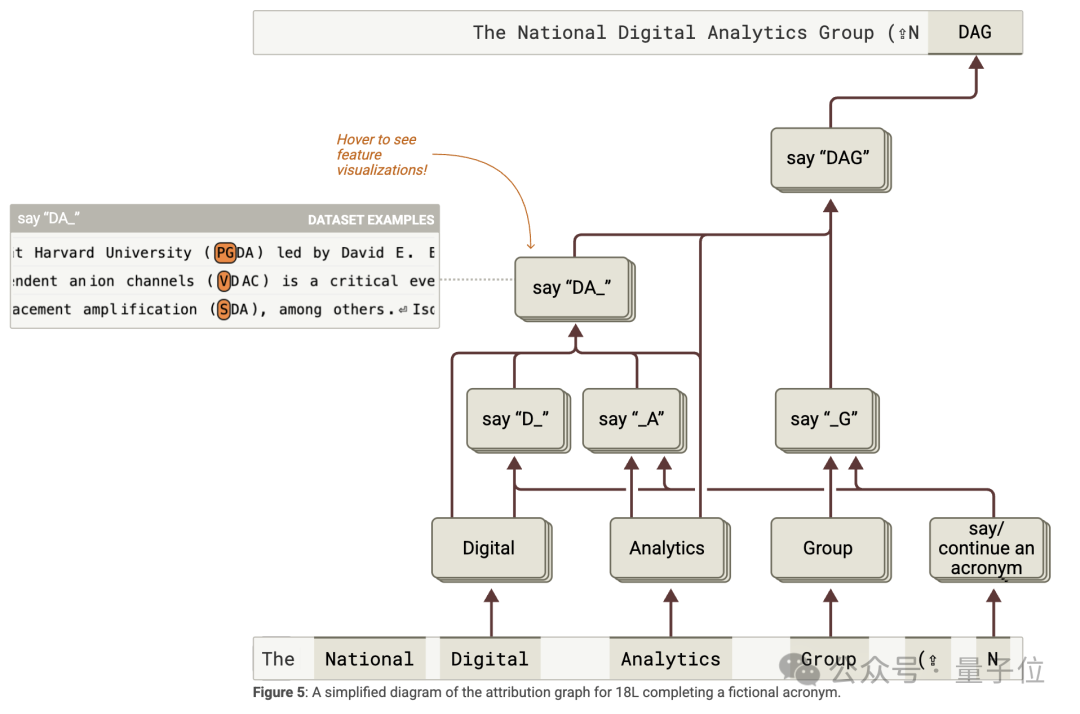
為了理解歸因圖,研究人員開發了交互式可視化界面。
他們通過觀察特徵在不同數據樣本上的激活情況,手動為特徵標註含義,並把功能相關的特徵歸為超節點。
為了驗證歸因圖的準確性,他們進行特徵擾動實驗,即改變某些特徵的激活值,觀察對其他特徵和模型輸出的影響。
此外,還能借助歸因圖找出對輸出結果影響最大的關鍵層。
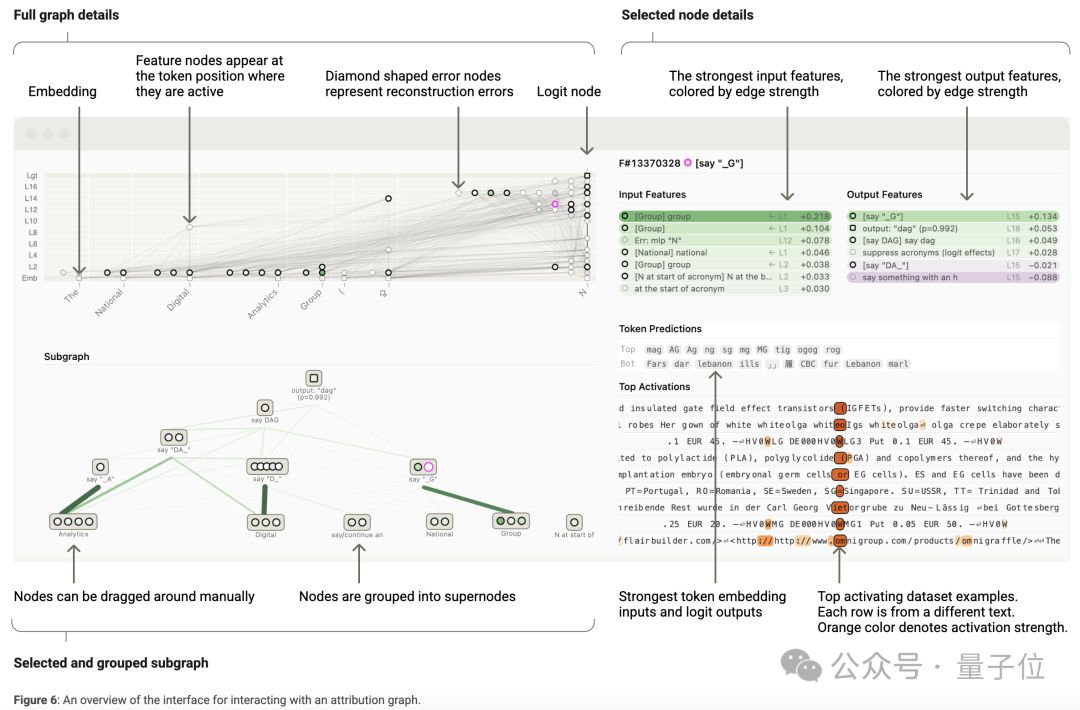
除了研究特定提示下的特徵交互(歸因圖分析),研究人員還關注特徵在不同上下文下的交互,這就涉及到全局權重。
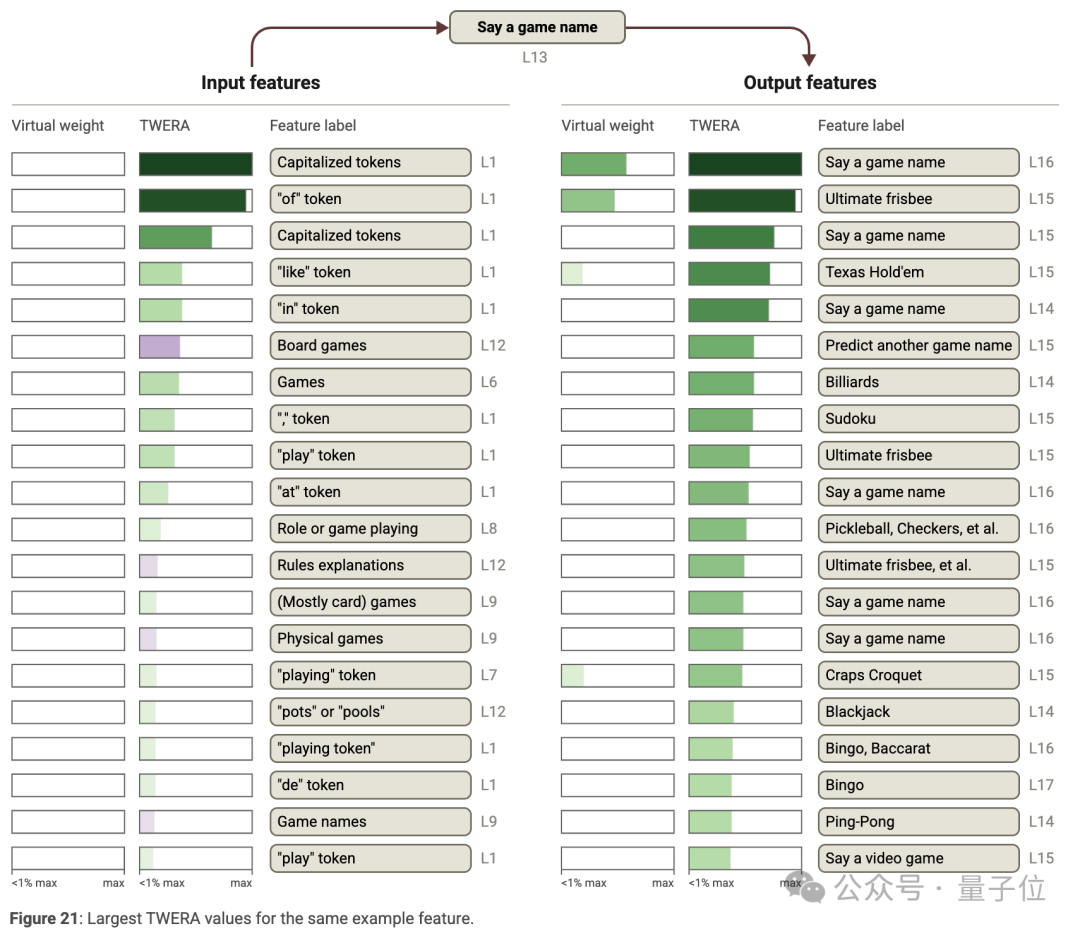
其中,虛擬權重是一種全局權重,但存在干擾問題,即一些沒有實際因果關係的連接會幹擾對模型機制的理解。
為解決這個問題,研究人員通過限制特徵範圍或引入特徵共激活統計信息(如計算 TWERA),減少幹擾,從而更清晰地揭示特徵間的真實關係。
研究人員對CLT特徵的可解釋性以及歸因圖對模型行為的解釋程度進行了評估。
結果發現,CLT特徵在一定程度上能夠反映模型內部的一些語義和句法信息,歸因圖也能夠較好地展示模型在生成輸出時的關鍵步驟和特徵之間的依賴關係。
但二者也都存在一些局限性,例如對於一些複雜的語義關係,CLT特徵的解釋能力有限;對於一些細微的模型行為變化,歸因圖的解釋不夠精確。
但話說回來,這種方法還是給人們帶來了有趣的發現,有人還把Claude算數學題的過程做出了表情包。
它以為自己是一步到位,實際上內心已經兜兜轉轉了好幾圈。
也是有些人類做工作彙報那味了。
 官方簡報:
官方簡報:https://www.anthropic.com/research/tracing-thoughts-language-model
方法論文:
https://transformer-circuits.pub/2025/attribution-graphs/methods.html
觀察實驗論文:
https://transformer-circuits.pub/2025/attribution-graphs/biology.html