VBench-2.0:面向影片生成新世代的評測框架

近一年以來,AI 影片生成技術發展迅猛。自 2024 年初 Sora 問世後,大家驚喜地發現:原來 AI 可以生成如此逼真的影片,一時間各大高校實驗室、互聯網巨頭 AI Lab 以及創業公司紛紛入局影片生成領域。
閉源模型(如 Kling、Gen、Pika)在視覺效果方面令人驚歎,近期也有 HunyuanVideo、Wanx 等完全開源的模型在 VBench 榜單上表現出色,讓我們看到了社區在推動技術革新上的無限潛力。
然而,當大家都在驚呼「視覺效果太牛了」的同時,難免會產生新的思考:影片生成的下一步究竟該往哪裡走?表面逼真度真的就代表一切嗎?還能有哪些更深層次的能力值得我們深挖?
從「表面真實性」到「內在真實性」
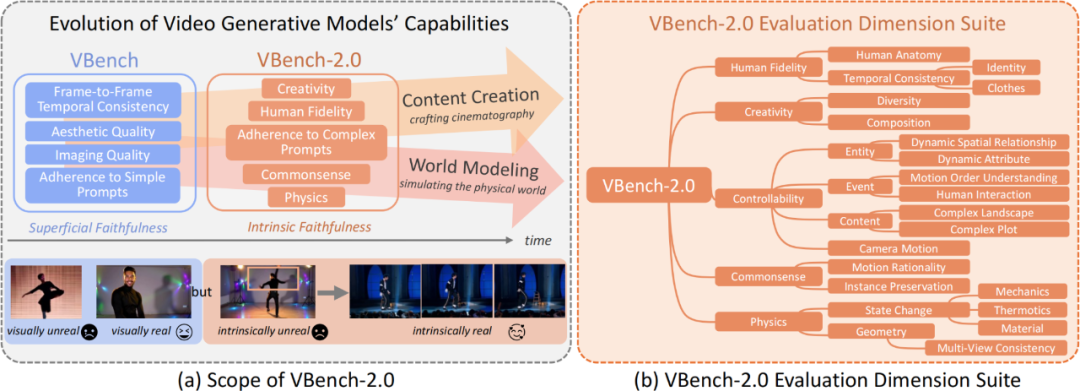
初代 VBench 作為業內權威的影片生成評測體系,主要關注影片的視覺觀感,例如每一幀的清晰度、幀與幀之間的平滑銜接,以及影片和文本描述間的基本一致性。這些要素也被稱為表面真實性(Superficial Faithfulness),它解決了影片「看起來是否逼真」和「好不好看」的問題,並為現階段模型提供了統一衡量標尺。
然而,要讓影片生成真正邁向更高層次的應用——例如 AI 輔助電影製作、複雜場景模擬等,就不僅需要影片「看起來逼真」,更需要它具備對物理規律、常識推理、人體解剖、場景組合等世界模型(World Model)層面的深度理解,也就是內在真實性(Intrinsic Faithfulness)。只有能夠遵循現實世界規則的模型,才有可能在長劇情、複雜動作和內容創作中更具潛力。
VBench-2.0:向「內在真實性」進發
為引領影片生成技術從表面逼真邁向內在逼真,南洋理工大學 S-Lab 和上海人工智能實驗室聯合推出 VBench-2.0。

-
論文標題:VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
-
論文鏈接:https://arxiv.org/abs/2503.21755
-
影片:https://www.youtube.com/watch?v=kJrzKy9tgAc
-
代碼:https://github.com/Vchitect/VBench
-
網頁:https://github.com/Vchitect/VBench-2.0-project
在繼承 VBench-1.0 對「表面真實性」關注的同時,VBench-2.0 更強調以下關鍵評測維度:
-
Human Fidelity(人體動作與結構)
關注做體操時動作是否連貫、角色動作是否合乎人體解剖常識等。
-
Controllability(可控性)
考察模型能否精確地執行用戶給出的指令,例如相機運動、人物位置等微調效果。
-
Creativity(創造性)
觀察模型在場景組合和故事情節拓展等方面的想像力。
-
Physics(物理規律)
浮力、重力、碰撞效果是否合理?模型能否生成符合物理定律的動作或場景變化?
-
Commonsense(常識推理)
在日常情景或邏輯推斷中是否展現出合理性,例如「吃東西」時,食物是否真的進入了口中,角色行為是否合乎常理等。
VBench-2.0 針對以上維度提出了大量的精細化測評場景與自動化評估策略,其中包含通用的多模態模型(VLMs、LLMs)及在特定領域表現優異的「專家」方法(如針對人體異常動作的檢測)等。為了確保評測結果的可靠性,我們與真實人類打分結果進行了大規模對照,力求讓自動評測與人的直覺判斷保持一致。
-
分層與解耦的 18 個評測維度
-
開源 Prompt List 體系
-
與人類觀感對齊的自動評測
-
多視角觀察助力下一代影片生成
在下面這些常被網民「抽水」的場景中,模型往往暴露了缺乏「內在真實度」的短板。VBench-2.0 能系統地評判這些一直被網民詬病的影片生成模型的缺陷,而且很準哦!
VBench 評測體系:雙劍合璧,覆蓋更全面
-
VBench-1.0:適用於評估影片生成的「表面真實性」,如視覺質量、文本匹配與整體流暢度等。在現階段為各家模型的進步提供了強力支持。
-
VBench-2.0:在保留 VBench-1.0 優勢的同時,進一步聚焦影片的「內在真實性」。當我們想真正判斷一個模型有沒有「世界模型」,能否用在更深層次的創作和應用場景時,VBench-2.0 的評測就尤為關鍵。
我們建議研究者同時使用 VBench-1.0 與 VBench-2.0 對模型進行評估:前者能直觀地衡量影片的視覺效果和基礎一致性,後者則深入探討模型在物理、常識、複雜行為等領域的表現,幫助你更好地理解模型的實際潛力。
現有模型表現:開源與閉源,皆有亮點
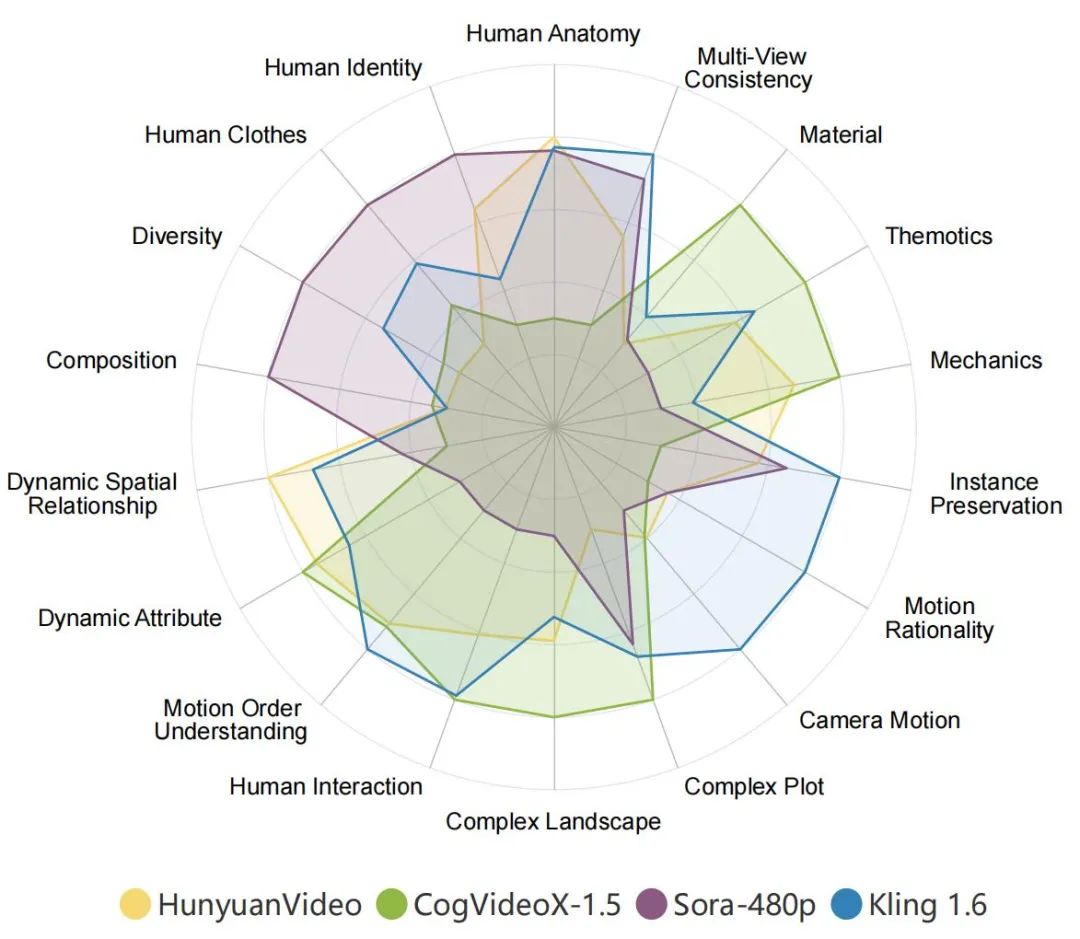
各家 AI 影片生成模型在 VBench-2.0 上的表現。在雷達圖中,為了更清晰地可視化比較,我們將每個維度的評測結果歸一化到了 0.3 與 0.8 之間。
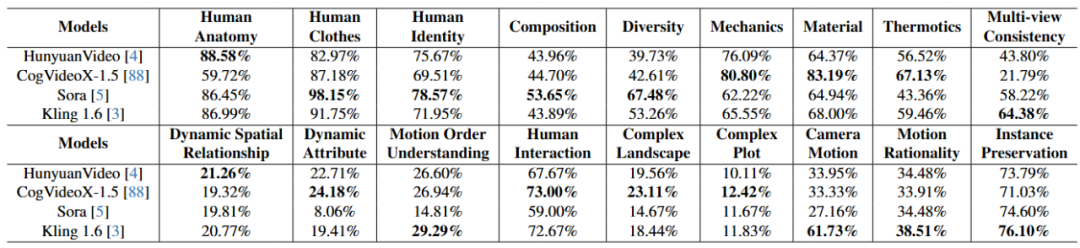
各家AI 影片生成模型在 VBench-2.0 上的表現。
在 VBench-2.0 的「內在真實性」評測中,並未出現明顯的「開源或閉源即佔絕對優勢」的現象。很多社區開源項目在複雜場景中表現得並不比商用閉源模型差,說明技術進步依賴社區共建是完全可行的。
全面開源,歡迎加入社區,共同推動影片生成新未來
VBench-2.0 已全面開源,讓你可以輕鬆測試並對比感興趣的模型。我們也非常期待你在實際使用中的反饋與建議,共同助力 AI 影片生成生態的成長和進化。
我們也開源了一系列 Prompt List:https://github.com/Vchitect/VBench/tree/master/VBench-2.0/prompts
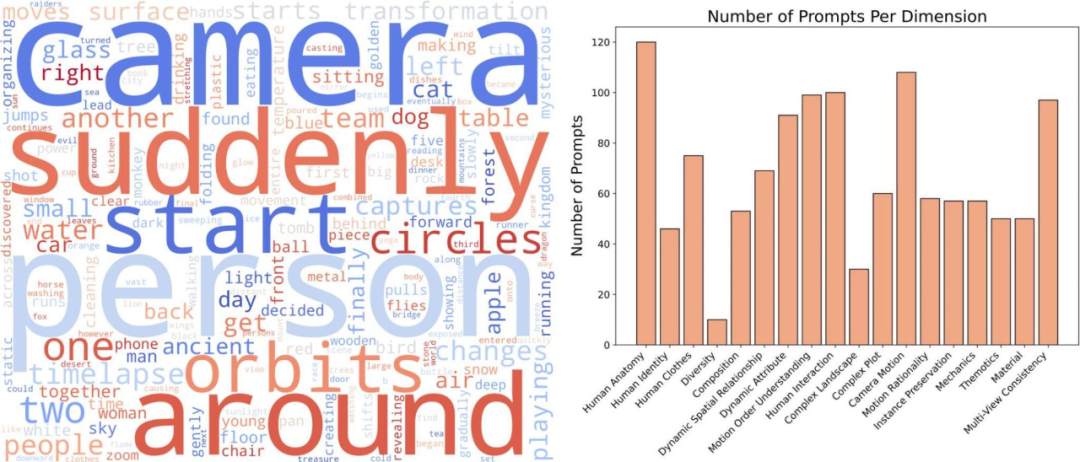
左邊詞雲展示了我們 Prompt Suites 的高頻詞分佈,右圖展示了不同維度的 prompt 數量統計。無論你是模型研發者、應用開發者,或對前沿技術感興趣的愛好者,都歡迎加入我們的行列,攜手探索影片生成從「看起來很真」到「本質上真」的精彩進化。讓我們一起,讓下一代影片生成模型更具想像力,也更貼近真實世界!
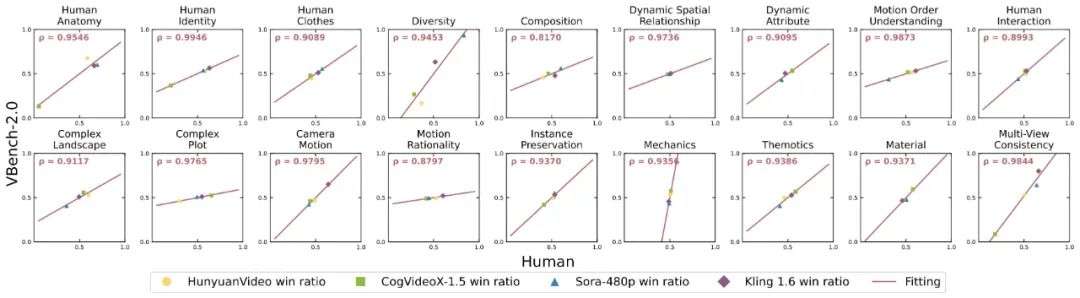
VBench-2.0 準不準?
針對每個維度,我們計算了 VBench-2.0 評測結果與人工評測結果之間的相關度,進而驗證我們方法與人類觀感的一致性。
下圖中,橫軸代表不同維度的人工評測結果,縱軸則展示了 VBench-2.0 方法自動評測的結果,可以看到我們方法在各個維度都與人類感知高度對齊。
帶給影片生成的更多思考
VBench-2.0 不僅可以對現有模型進行評測,更重要的是,還可以發現不同模型中可能存在的各種問題,為下一代影片生成模型的發展提供有價值的洞見。
不同需求,選用不同模型
-
比較天馬行空的創意性的生成:Sora
-
想要生成人相關的運動鏡頭:HunyuanVideo 或者 Kling 1.6
-
想要實現精確的相機控制:Kling 1.6
-
想要生成嚴格遵從文本指示的影片:CogVideoX-1.5
-
想要模擬基礎的物理定律:CogVideoX-1.5
會有全能模型出現嗎?蹲守一波 2025 與 2026 年的發展。
基礎動作和屬性變化仍是短板
我們發現在非常簡單的位置移動或者屬性變化上,所有模型的效果都不好,這說明現在的模型的訓練數據中並沒有顯式包括位置、屬性變化這一類的文本。這可能是 video caption 模型能力上的缺陷。
可能的解決辦法包括:
-
用提示詞或者 In-context 學習的範式來提示 video caption 模型
-
人工添加部分該類型文本數據
故事級長文本引導生成有待突破
現在主流影片生成時長普遍只有幾秒,但未來在電影、動畫等更長場景中,如何保持劇情連貫仍是重大挑戰。
現在的模型都還不支撐故事級別(5 個連續的小情節)的影片生成,其中最主要的原因是現在的影片生成模型的時長都還在 5-10 秒這個級別,還遠遠沒有到考慮分鐘級別的故事敘述。
這將是未來內容、電影創作中非常重要的一個能力。
平衡文本優化器(Prompt Refiner)與創造力
文本優化器有助於提高影片與描述的精確對齊,但也可能抑制模型的多樣性輸出。如何兼顧高質量與高創造力值得研究者深入探討。
現在先進的模型都會使用文本優化器來規範或者細粒度化用戶的文本輸入。但是我們發現使用文本優化器會在一定程度上提高生成的影片的視覺質量,更貼近於文本的描述。但是會在一定程度上影響生成的多樣性以及創造力。
因此,如果你想要針對一個文本生成風格差異比較大的影片,在能關閉文本優化器的情況下請關閉它;而如果你想要更高質量、與文本輸入更吻合的影片,那麼使用文本優化器是更好的選擇。
而對於研究者來說,如何構建一個既能提高影片質量,又不會影響其創造力的優化器是一個挑戰。
從表面到內核,全面評估
有些模型的 Demo 雖然炫酷,但在物理、邏輯推斷或敘事性上仍有不足。正如 VBench-2.0 所強調的「內在真實度」,我們不能只憑第一觀感就匆忙下定論。
表面真實性(例如,電影攝影能力)是觀看影片時的第一印象,這也是為什麼許多人會將高美學評分、高流暢度等特點與優秀模型聯繫在一起。
然而,情況並非總是如此。內在真實性(例如,敘事能力、世界模擬能力)也是決定一個影片生成模型是否能夠在未來應用於真實場景的關鍵因素。比如 CogVideoX 在 VBench 中的影片質量得分不算最高,視覺體驗可能也不如最近一兩個月新出的最強模型,但在 VBench-2.0 的許多關注內在真實性(Intrinsic Faithfulness)的維度上表現良好。
由此可見,想要真正評估一個影片生成模型的全方位能力和潛力,單看 Demo 遠遠不夠。VBench-2.0 引導我們從更全面的角度來認識與衡量模型。
進一步瞭解
我們誠摯邀請所有對影片生成領域感興趣的研究者與開發者共同參與 VBench 體系的評測(VBench-1.0 和 VBench-2.0),一起探索影片生成從「看起來很真」到「本質上真」的跨越。讓我們攜手推動下一代影片生成模型在表面與內核上同時進化。