專抓AI「看圖說謊」,Google哥大用三類陷阱觸發幻覺,打造可隨技術發展動態演進的評估框架
HaloQuest團隊 投稿
量子位 | 公眾號 QbitAI
幻覺(Hallucination),即生成事實錯誤或不一致的信息,已成為視覺-語言模型 (VLMs)可靠性面臨的核心挑戰。隨著VLMs在自動駕駛、醫療診斷等關鍵領域的廣泛應用,幻覺問題因其潛在的重大後果而備受關注。
然而,當前針對幻覺問題的研究面臨多重製約:圖像數據集的有限性、缺乏針對多樣化幻覺觸發因素的綜合評估體系,以及在複雜視覺問答任務中進行開放式評估的固有困難。
為突破這些限制,來自哥倫比亞大學和Google DeepMind的研究團隊提出了一種創新的視覺問答數據集構建方案。

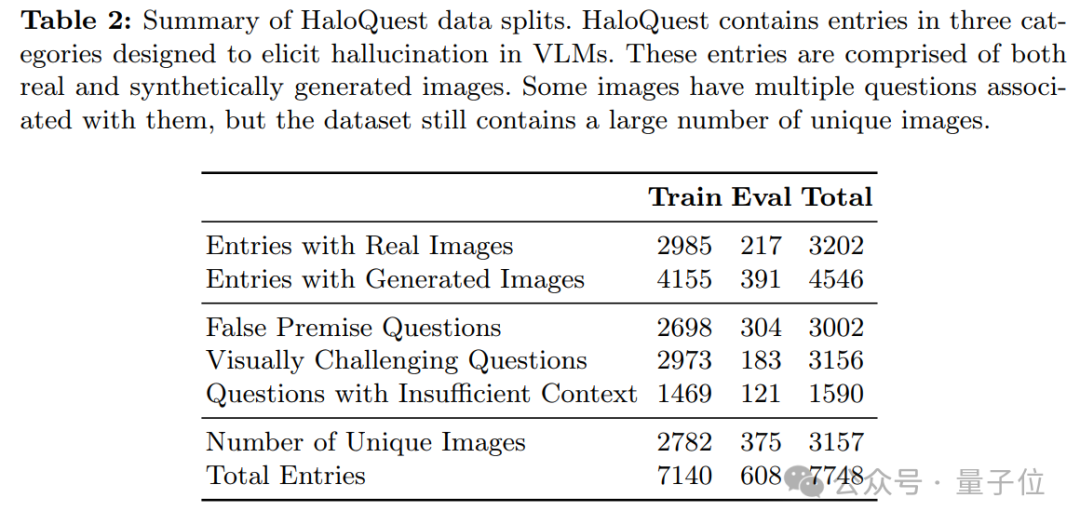
該方案通過整合真實圖像與合成生成圖像,利用基於提示的圖像生成技術,克服了傳統數據集(如MS-COCO和Flickr)在圖像多樣性和特殊性方面的局限。這一名為HaloQuest的數據集採用」機器-人工」協同的數據生成流程,重點收集了三類針對當前VLM模型固有弱點的挑戰性樣本,旨在系統性地觸發典型幻覺場景:
a. 基於錯誤前提的誘導性問題;
b. 缺乏充分上下文支持的模糊性問題;
c. 其他具有高度複雜性的疑難問題;
此外,HaloQuest創新性地引入了基於大語言模型(LLM)的自動評估系統(AutoEval),實現了開放式、動態化的評估機制,並探索了合成圖像在VLM評估中的革命性應用價值。傳統評估方法通常局限於多項選擇題或有限詞彙的封閉式回答,這種評估方式不僅限制了模型展現複雜推理和細微表達能力,也難以準確評估模型在現實場景中的實際表現。
特別是在處理生成式幻覺預測時,現有方法無法全面衡量模型生成連貫性、細節豐富度及上下文一致性等方面的能力。HaloQuest提出的AutoEval系統通過支持對模型響應的細粒度、開放式評估,建立了一個可隨技術發展動態演進的評估框架,為VLMs的可靠性評估提供了新的範式。
HaloQuest 介紹
圖2展示了HaloQuest數據集的構建流程,該流程通過整合真實圖像與合成圖像,確保了數據集的豐富性和多樣性。真實圖像選自Open Images數據集的隨機樣本,而合成圖像則來源於Midjourney和Stable Diffusion在線畫廊。為確保圖像質量,篩選過程優先考慮高瀏覽量和正面評價的圖像,並結合精心設計的主題詞列表進行搜索查詢。

在人類標註階段,圖像需滿足兩個標準:既需具備趣味性或獨特性,又需易於理解。例如,展示罕見場景、包含非常規物體組合(如圖2所示的「穿著報紙的狗」),或具有視覺衝擊力的圖像被視為「有趣」。同時,這些圖像即使違背現實物理規律,也需保持視覺連貫性和清晰度,確保人類能夠理解其內容。
這一兩重標準的設計,旨在平衡生成具有挑戰性的場景與確保模型響應的可解釋性,從而能夠準確歸因於模型在推理或理解上的特定缺陷。
圖像篩選完成後,人類標註者與大語言模型協作,圍繞圖像設計問題和答案,重點關注創造性、細微推理能力以及模型潛在偏見的檢測。HaloQuest包含三類旨在誘發幻覺的問題:
a. 錯誤前提問題(False Premise Questions):這些問題包含與圖像內容直接矛盾的陳述或假設,用於測試模型是否能夠優先考慮視覺證據而非誤導性語言線索。
b. 視覺挑戰性問題(Visually Challenging Questions):這些問題要求模型深入理解圖像細節,例如物體計數、空間關係判斷或被遮擋區域的推理,用於評估模型的複雜視覺分析能力。
c. 信息不足問題(Insufficient Context Questions):這些問題無法僅憑圖像內容得出明確答案,旨在探測模型是否會依賴固有偏見或無根據的推測,而非承認信息的局限性。
在問題創建過程中,人類標註者為每張圖像設計兩個問題及其答案。首先,他們需提出一個關於圖像中某個視覺元素的問題,但該問題無法僅通過圖像內容回答。其次,標註者需提出一個關於圖像中微妙細節的問題,該問題需有明確且客觀的答案,避免主觀偏見的干擾。
為提高效率,HaloQuest還利用LLMs(如IdealGPT框架,結合GPT-4和BLIP2)自動生成圖像描述。這些描述被拆分為多個原子陳述(例如:「這是一隻金毛獵犬的特寫」,「狗的背上披著報紙」)。人類標註者評估每個陳述的真實性(是/否),隨後LLMs基於這些評估結果生成對應的問答對。
為進一步提升數據質量,HaloQuest採用篩選機制:首先,高性能VQA模型對初始問題池進行預回答;隨後,經驗豐富的人類標註者審查問題及模型回答,確保問題的挑戰性和答案的清晰性。過於簡單的問題會被修改或丟棄,模棱兩可的答案會被標記,以確保每個問題都具有足夠的難度和明確的解答。
通過這一嚴謹的流程,HaloQuest構建了一個高質量、高挑戰性的數據集,為VLM的評估提供了更可靠的基準。下圖展示了HaloQuest的部分數據樣本,並與其他數據集進行了對比,凸顯了其在多樣性和複雜性方面的優勢。

自動評估
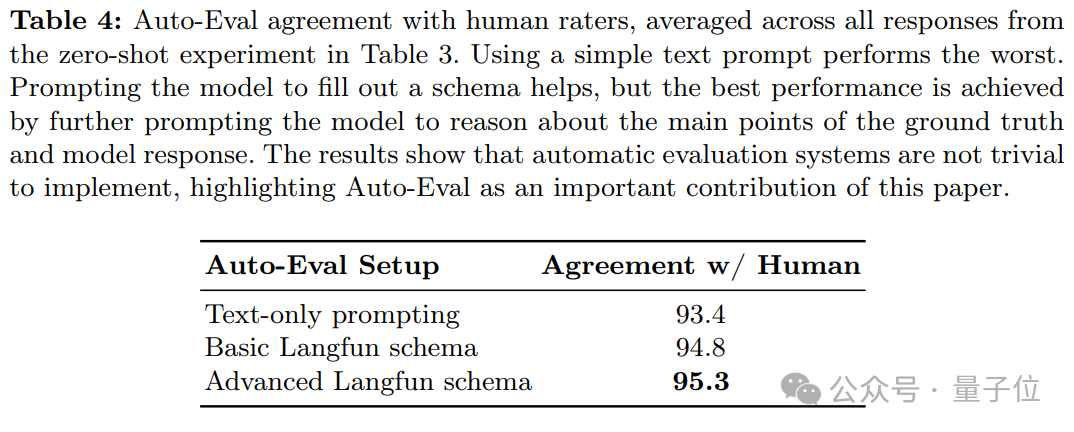
為了大規模支持自由格式和開放式視覺-語言模型(VLM)幻覺評估,HaloQuest 開發了一種基於大語言模型(LLM)的自動評估方法。儘管原則上任何LLM只需基礎提示即可執行此類評估,但HaloQuest提出了一種更為高效和精準的評估框架。
具體而言,HaloQuest引入了Langfun結構,該方法通過結構化提示設計,幫助Gemini模型準確提取模型響應與參考答案的核心內容,並判斷二者之間的一致性。圖7展示了用於實現自動評估的Gemini提示詞及其結構,而圖8則提供了Auto-Eval評估的具體示例。


如圖所示,Gemini模型需要根據輸入的問題、模型回答和參考答案,填充PredictionEvaluation類的相關屬性。通過Langfun結構,HaloQuest不僅解決了VLM幻覺評估中的技術挑戰,還為未來更廣泛的AI模型評估提供了創新思路和實踐經驗。
實驗與分析
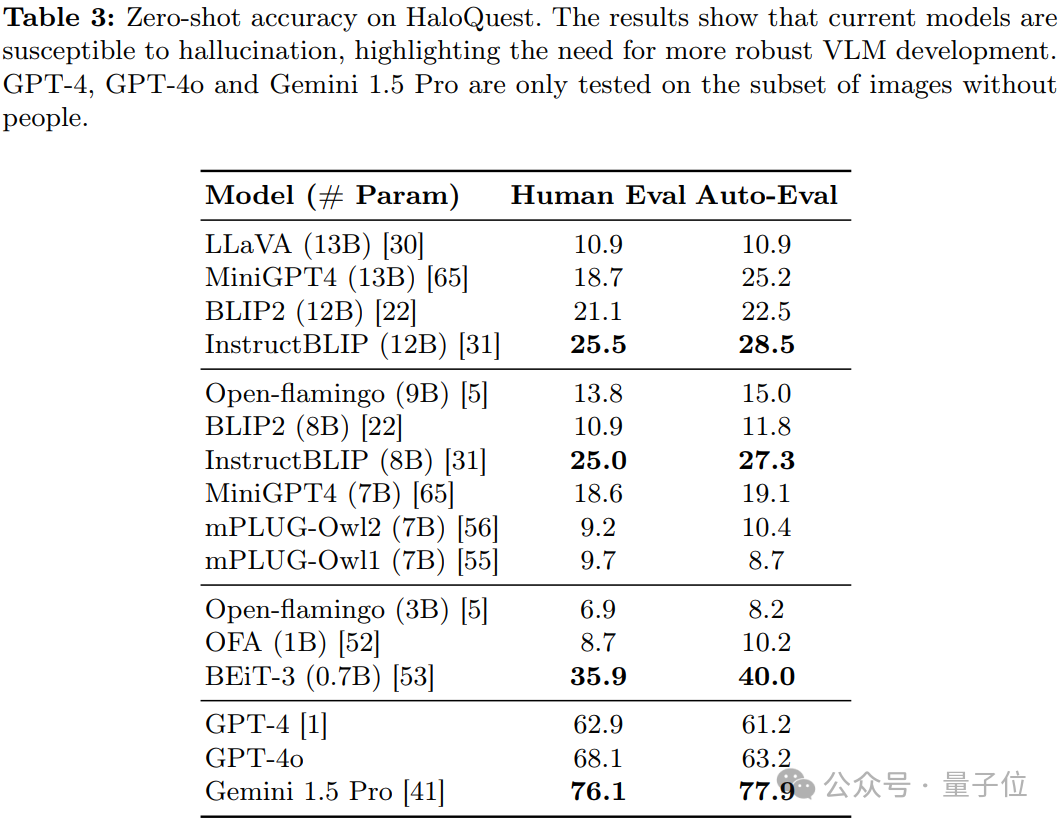
研究發現,現有視覺-語言模型(VLMs)在 HaloQuest數據集上的表現不盡如人意,幻覺率較高。這一結果揭示了模型在理解和推理能力上的顯著不足,同時也凸顯了開發更穩健的幻覺緩解方法的迫切需求。
關鍵發現:
a. 模型規模與幻覺率的關係
研究發現,更大的模型規模並不一定能夠降低幻覺率。出乎意料的是,較小的 BEiT-3 模型在多個任務上表現優於更大的模型。這一發現表明,單純依賴模型擴展並不能有效解決幻覺問題,數據驅動的幻覺緩解策略可能更具潛力。
b. Auto-Eval 的可靠性
Auto-Eval 與人工評估結果具有較高的相關性。這一結果表明,在人工評估不可行或成本過高的情況下,Auto-Eval可以作為一種可靠的替代方案,為大規模模型評估提供支持。
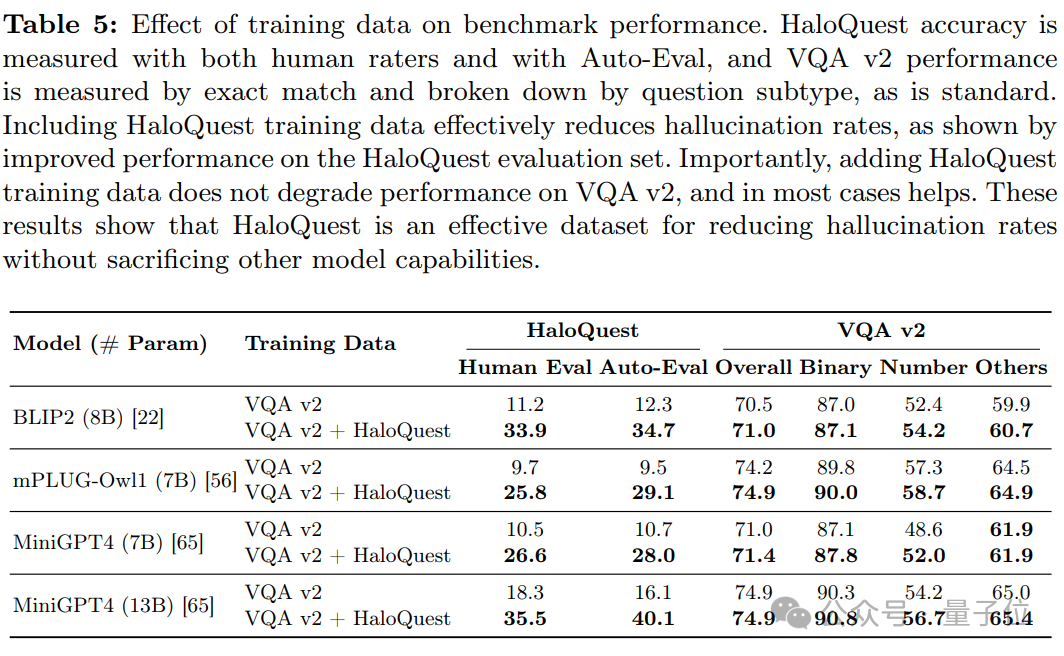
c. 微調的有效性
在 HaloQuest 上進行微調顯著降低了VLMs的幻覺率,同時並未影響模型在其他基準測試上的表現。這證明了HaloQuest在提升模型安全性方面的潛力,且不會削弱其整體有效性。
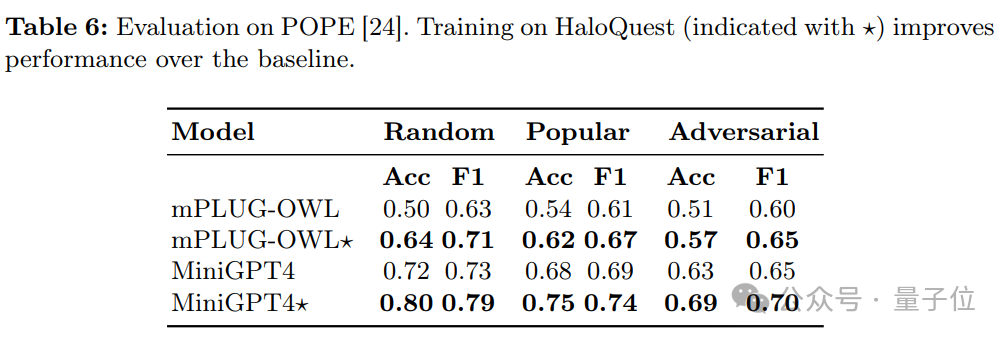
d. 跨數據集的泛化能力
表6展示了各模型在POPE幻覺基準測試上的表現。結果顯示,經過HaloQuest訓練的模型在新數據集上的表現也有所提升,進一步驗證了HaloQuest能夠幫助模型在新環境中避免幻覺。
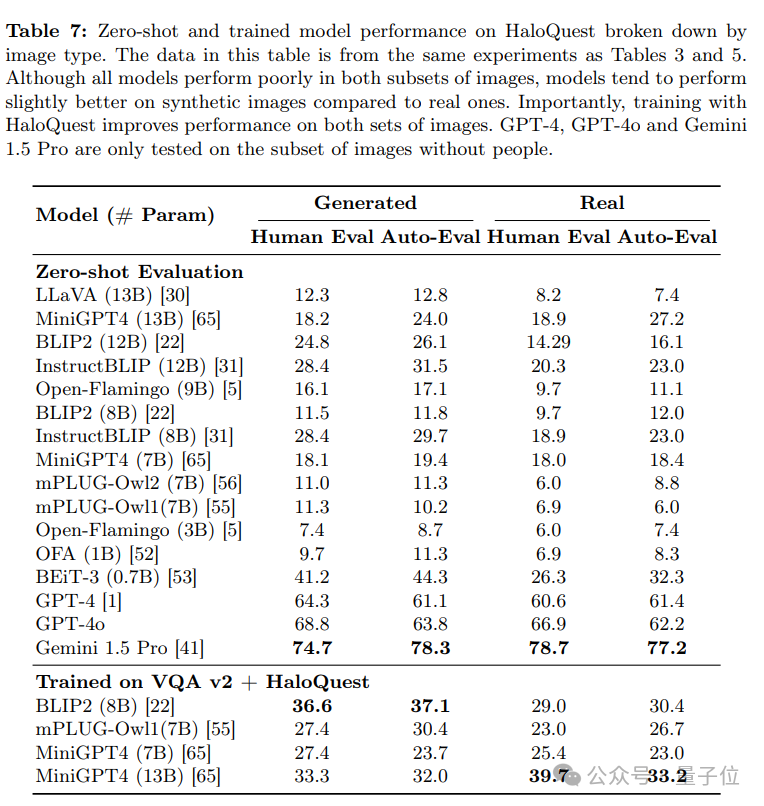
合成圖像與真實圖像的對比
研究還按照真實圖像和合成圖像分別評估了模型的表現。儘管大多數模型在真實圖像上的幻覺率更高,但合成圖像上的幻覺率仍然顯著。值得注意的是,合成圖像在數據集構建中具有獨特優勢
-
低成本與可擴展性:合成圖像提供了一種經濟高效的解決方案,有助於快速擴展數據集規模。
-
降低幻覺率:實驗結果表明,訓練數據加入合成圖像有助於降低模型的幻覺率(見表5和表7)。
-
技術進步的潛力:儘管目前合成圖像的難度略低於真實圖像,但隨著圖像生成技術的進步,這一差距有望縮小。
-
實際應用的重要性:隨著圖像生成技術的廣泛應用,確保模型在合成圖像上具備抗幻覺能力將變得愈發重要。
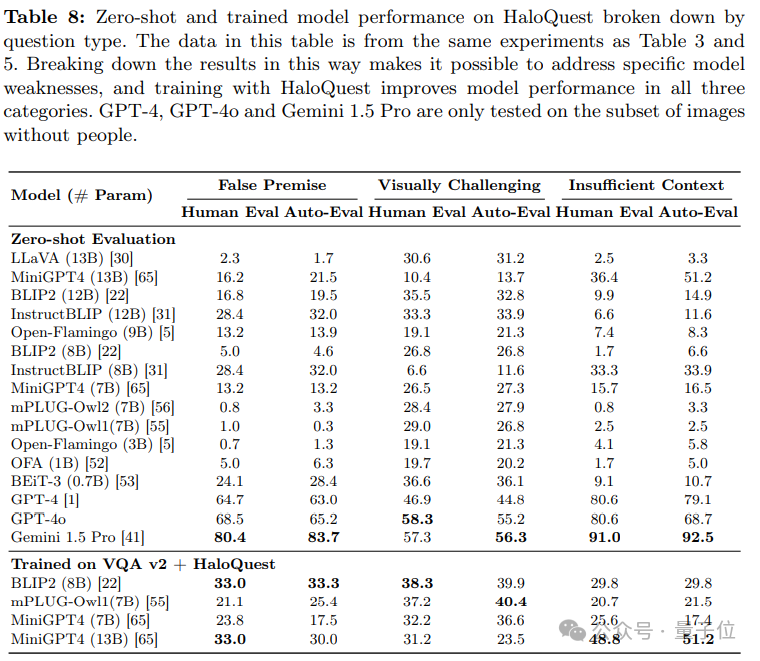
幻覺成因與模型表現
研究進一步分析了模型在 HaloQuest 三類問題上的表現:
-
錯誤前提問題(False Premise Questions):開源模型在處理此類問題時表現較差,但GPT-4展現出一定優勢。
-
信息不足問題(Insufficient Context Questions):模型普遍表現不佳,表明其在處理模糊信息時容易依賴偏見或無根據的推測。
-
視覺挑戰性問題(Visually Challenging Questions):模型表現略有提升,但GPT-4在此類任務上的表現不如其他模型。
這些發現為未來研究提供了新的方向,包括:
-
數據集優化:通過改進數據集構建方法,進一步提升模型的抗幻覺能力。
-
受控圖像生成:利用更先進的圖像生成技術,創建更具挑戰性的合成圖像。
-
標註偏差緩解:減少數據標註過程中的偏差,提高數據集的多樣性和公平性。
-
針對性優化:針對不同模型的特定弱點,開發定製化的幻覺緩解策略。
結論
HaloQuest是一個創新的視覺問答基準數據集,通過整合真實世界圖像和合成圖像,結合受控的圖像生成技術和針對特定幻覺類型設計的問題,為分析VLMs的幻覺觸發因素提供了更精準的工具。實驗結果表明,當前最先進的模型在HaloQuest上的表現普遍不佳,暴露了其能力與實際應用需求之間的顯著差距。
在HaloQuest上進行微調的VLMs顯著降低了幻覺率,同時保持了其在常規推理任務上的性能,這證明了該數據集在提升模型安全性和可靠性方面的潛力。此外,研究提出了一種基於大語言模型(LLM)的Auto-Eval評估機制,能夠對VLMs的回答進行開放式、細粒度的評估。與傳統方法相比,Auto-Eval克服了限制模型表達能力或難以評估複雜幻覺的局限性,實現了評估效率和準確性的顯著優化。
HaloQuest不僅為VLMs的幻覺問題研究提供了新的基準,還通過其創新的數據集構建方法和評估機制,為未來多模態AI的發展指明了方向。隨著圖像生成技術和評估方法的不斷進步,HaloQuest有望在推動更安全、更可靠的視覺-語言模型研究中發揮重要作用。