Anthropic用「AI顯微鏡」扒開Claude「大腦結構」,揭示語言模型行為背後機制
當地時間 3 月 27 日,Anthropic 在一篇技術論文中介紹了一種名為「通路追蹤」的技術,該技術讓人們能夠逐步追蹤大語言模型內部的決策過程。
 (來源:Anthropic)
(來源:Anthropic)研究中,Anthropic 採用通路追蹤技術,來觀察其大語言模型 Claude 3.5 Haiku 在執行各種任務時的表現。
通路,可以將模型的不同組件連接在一起。2024 年,Anthropic 發現 Claude 中的某些組件與現實世界中的概念相對應。基於上述發現以及其他已有成果,Anthropic 在本次論文中揭示了各個組件之間的一些聯繫。
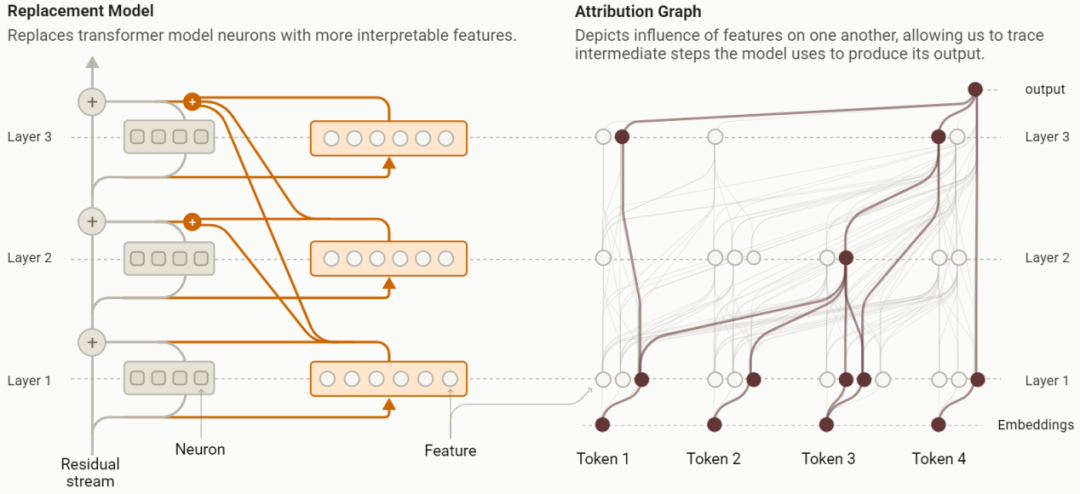
論文中,Anthropic 介紹了一種揭示語言模型行為背後機制的方法。其通過在替代模型中追蹤到的各個計算步驟,來生成模型在目標提示詞上計算過程的圖表描述。
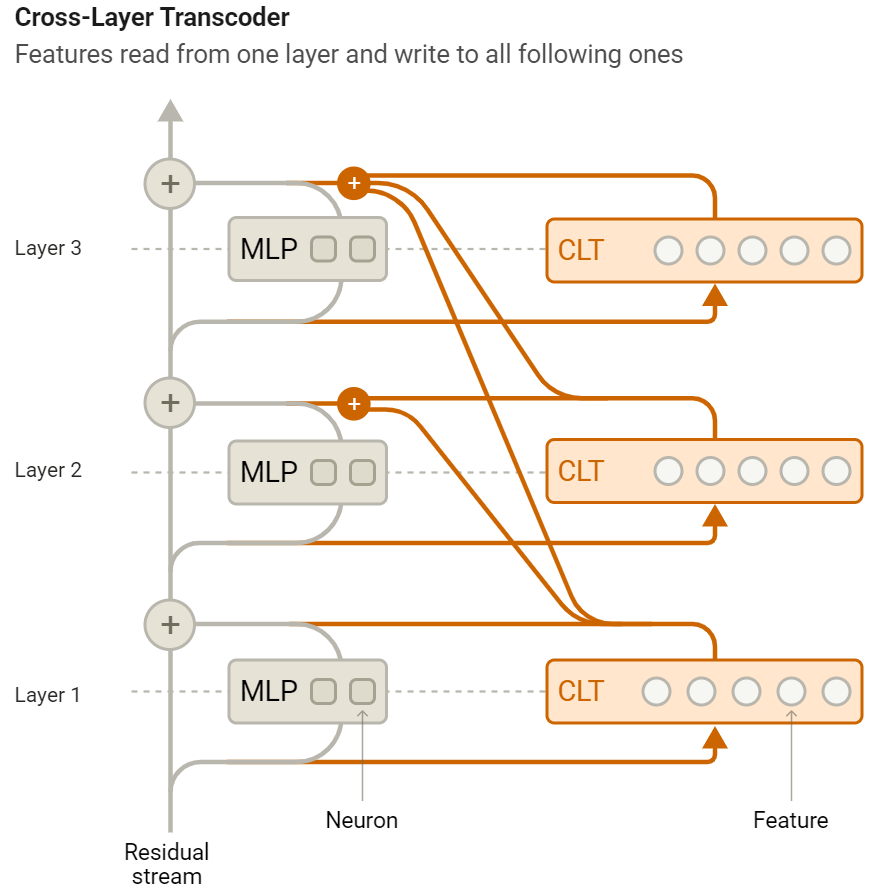
這種替代模型使用一個更易解釋的組件(Anthropic 將其稱之為跨層轉碼器),來替換原始模型中待模擬的部分(Anthropic 將其稱之為多層感知器)。
與此同時,Anthropic 還開發了一套可視化和驗證工具,以用於研究支持 18 層語言模型的簡單行為的「歸因圖」。
 (來源:Anthropic)
(來源:Anthropic)
讓跨層轉碼器實現帕累托改進
據瞭解,深度學習模型通過分佈在許多計算單元上的一系列轉換來產生輸出。
此前,業內曾嘗試採取機制可解釋性的方法,來使用那些人類可以理解的語言來描述這些轉變。
Anthropic 團隊的方法,則遵循兩步走的策略。
第一步,識別出模型在其計算過程中所使用的特徵,也就是那些具有可解釋性的基本組成部分。
第二部,描述這些特徵通過相互作用來生成模型輸出的過程,也就是描述其運行機制。
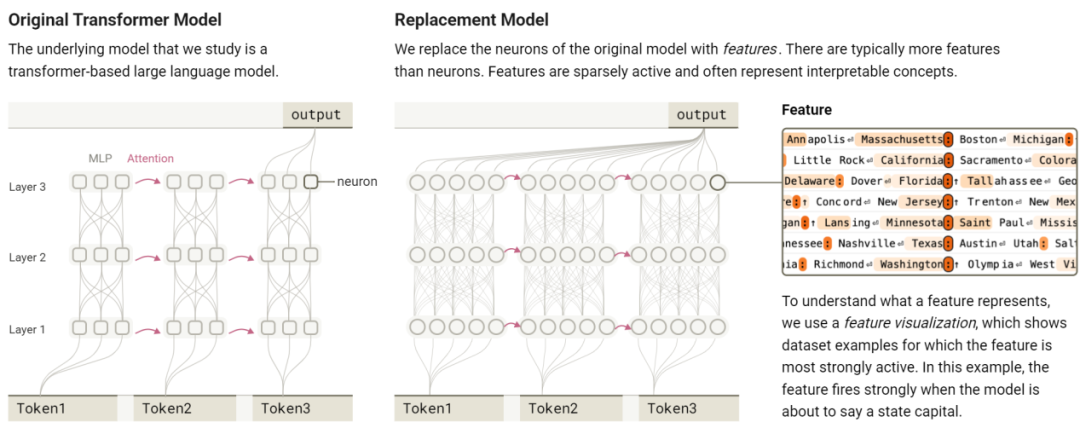
Anthropic 認為,一種符合直覺的方法是將模型的原始神經元作為基本組成部分。
正是利用這種方法,此前已有研究成功識別了視覺模型中的通路,這些通路是由「似乎代表有意義的視覺概念」的神經元構建的。
然而,模型神經元通常是多義的,並混合著許多不相關的概念。
在 AI 領域,多義性通常指一個詞語、句子或數據在不同語境下可能具有多種含義或解釋的現象。業內認為,多義性的原因之一可能是由於疊加現象的存在,由於模型需要表徵的概念數量超過神經元數量,因此它們不得不將概念表徵分散到多個神經元中。
神經網絡的基本計算單元(即神經元),與有意義概念之間的這種不匹配,已經被證明是影響機制解釋研究進展的主要障礙,尤其在理解語言模型時更是如此。
近年來,稀疏編碼模型比如稀疏自編碼器、轉碼器和交叉編碼器,已被用於識別疊加表徵中可解釋特徵。
這些方法能將模型激活分解為稀疏活躍的組件(即特徵)。而在許多情況下,這些特徵恰好對應著人類可以理解的概念。
儘管當前的稀疏編碼方法在識別特徵上並不完美,但其所產生的結果很容易進行解釋,這正是 Anthropic 研究由這些特徵組成的通路的原因。
論文中,Anthropic 描述了其所使用的方法,所涉及到的關鍵方法論如下。
Anthropic 採用轉碼器的變體來提取特徵,這種方法能構建一個可解釋的替代模型,以便作為原始模型的代理來開展研究。更重要的是,該方法讓 Anthropic 能夠直接分析特徵與特徵之間的交互作用。
Anthropic 的分析基於跨層轉碼器,其中每個特徵從一層殘差流中讀取,並貢獻給原始模型的所有後續多層感知器層的輸出。
Anthropic 使用模型所學習到的跨層轉碼器特徵,來替代模型的多層感知器,從而能在大約一半的情況下匹配底層模型的輸出。
論文中,Anthropic 還重點介紹了「歸因圖」。歸因圖描述了模型在特定提示下為目標 token 生成輸出的步驟。歸因圖中的節點表示活動特徵、提示中的標記嵌入、重構誤差和輸出對數機率。圖中的邊表示節點之間的線性效應,因此每個特徵的活動是其輸入邊的和。
在實驗設置上,Anthropic 的設計方案如下:對於特定的輸入,特徵之間的直接相互作用是線性的。更重要的是,Anthropic 凍結了注意力模式和歸一化分母,並使用轉碼器來實現這種線性關係。此外,特徵之間也存在間接相互作用,這些間接作用由其他特徵介導,並對應於多步驟的路徑。
儘管 Anthropic 提取的特徵具有稀疏性,但在處理特定輸入時活躍特徵的數量仍然過多,這就導致難以直接解讀生成的圖譜。
為了降低複雜度,Anthropic 通過識別對於模型在特定 token 位置輸出貢獻最大的節點和邊,來進行圖譜剪枝。這種方法使其能夠為任意輸入去生成稀疏、可解釋的模型計算圖譜。
與此同時,Anthropic 還設計了一個交互式界面,以用於探索歸因圖及其所包含的特徵,以便能夠快速識別和突出顯示其中的關鍵機制。
需要指出的是在研究神經通路的時候,Anthropic 採取的是間接路徑。由於替代模型採用的機制可能與底層原模型存在差異,因此對於歸因圖中發現的機制進行驗證至關重要。
為此,Anthropic 通過擾動實驗開展驗證。具體而言:當沿特定特徵方向施加擾動時,通過測量其他特徵激活的變化程度,來檢驗這些變化是否與歸因圖的預測一致。
實驗結果表明:儘管存在個別偏差,但是跨不同輸入文本的擾動實驗結果,總體上與歸因圖具有定性一致性。
雖然本次研究聚焦於研究單個提示的歸因圖,但是本次方法也使 Anthropic 能夠直接研究替換模型的權重。
此外,Anthropic 還針對跨層轉碼器及其生成的歸因圖進行了定量評估。結果證明:相比神經元分析和單層轉碼器,跨層轉碼器實現了帕累托改進。帕累托改進指的是一種「零損失」狀態,即通過優化資源配置,達到一種相對理想的平衡。
 (來源:Anthropic)
(來源:Anthropic)
實現逆向工程框架
在論文中,Anthropic 還介紹了其所提出的神經網絡逆向工程方法,這一方法包含四個基本步驟:組件分解、組件特徵描述、組件交互行為表徵、描述驗證。
論文中,Anthropic 通過以下方法實現了逆向工程框架:
首先是分解階段:訓練具有稀疏特徵的跨層轉碼器以便替代多層感知器模塊;
其次是描述階段:根據特徵激活的數據集樣本進行特徵描述;
接著是交互分析階段:利用歸因圖表徵特定輸入提示下的特徵交互;
最後是驗證階段:通過因果導向干預實驗驗證所得假設。
研究中,Anthropic 並沒有使用原始神經元。雖然神經元的最高激活值通常可解釋,但是對於較低激活值的來說,它們往往難以進行解讀。
理論上,可以通過設定閾值將神經元激活限制在可解釋區間,但是本次研究發現:與轉碼器或跨層轉碼器相比,這種閾值處理會顯著損害模型性能。
這意味著經過訓練的替代層,能在可解釋性、L0 稀疏度和均方誤差三個維度上,能夠實現更好的帕累托改進。
另外,Anthropic 採用線性直接效應、而非採用非線性歸因方法或消融方法來計算特徵間交互作用。
儘管已有大量研究探討非線性神經網絡中的歸因方法,但是即使在最嚴謹的非線性場景 credit 分配方案中,仍然存在一些固有缺陷。
由於 Anthropic 的目標是希望能夠清晰地推斷大模型的機制原理,因此其通過以下設計來實現條件線性,即在固定注意力模式與歸一化分母的前提下,確保前一層特徵與下一層預激活特徵間的直接交互能夠呈現出線性關係。
這種設計方案可以將問題分解為兩個部分:可以通過機制化方法進行嚴謹理解的部分,以及仍需探索的另一部分。
值得注意的是,實現這種線性直接效應的關鍵前提,正是 Anthropic 此前所採用轉碼器的技術決策。
為了實現更加通用的解決方案,Anthropic 採取了以下做法:
首先,其針對注意力路徑進行整合處理。歸因圖中的每條邊都代表一對特徵間的直接交互作用,其數值是所有可能直接交互路徑的加總。在這些路徑中,有些主要通過殘差流進行傳遞,另一些則經由注意力頭進行傳遞。在本次研究中,Anthropic 暫未區分這些路徑類型,因此這種做法雖然會丟失大量有趣的結構信息,但是能夠顯著簡化分析的複雜度。
其次,其忽略了 QK 通路(QK-circuit)。在 AI 領域,QK 通路是用於解析注意力機制運作原理的關鍵概念。Anthropic 根據框架將理解 Transformer 的過程分為兩部分。一方面,其所關注的問題是:在特定注意力頭或注意力頭集合條件下,到底有著怎樣的特徵-特徵交互?然而這也留下了另一個問題:為什麼注意力頭會關注不同的部分?關於這一問題,Anthropic 尚未對其進行研究。
再次,Anthropic 僅使用稀疏懲罰和重建損失來進行交叉編碼器訓練。儘管其最終目標是找到具有稀疏且可解釋的邊的通路,但在一個機制上忠實於底層模型的替換模型中,Anthropic 並未針對這些目標進行訓練。

「這隻是冰山一角」
對於本次研究,美國布朗大學研究大語言模型的積克·梅羅洛(Jack Merullo)表示:「我認為這是一項非常酷的工作,從方法論上講這是一項非常重要的進步。」
以色列特拉維夫大學的埃登·比蘭(Eden Biran)也對此表示讚同:「在像 Claude 這樣的大型先進模型中找到通路是一項不簡單的工程壯舉,這表明通路可以擴展,並且可能是一種解釋語言模型的良好方法。」
需要說明的是,跨層轉碼器需要投入較高的前期成本,但這些成本可以分攤到 Anthropic 後續的通路發現研究中。
Anthropic 指出,這種方法對於通路可解釋性和簡約性的提升,足以證明其具備投資價值。儘管如此,其表示業內人士仍然可以選用單層轉碼器甚至多層感知器神經元等替代方案,因為這些方法同樣能產生有價值的信息。與此同時,Anthropic 認為未來很可能出現優於訓練跨層轉碼器的新方法。
為幫助業內人士更好地複現本次成果,Anthropic 分享了跨層轉碼器實施指南、剪枝方法細節,以及支持交互式圖形分析界面的前端代碼。
Anthropic 的研究人員、本次論文的通訊作者祖舒亞·畢特森(Joshua Batson)說道:「這隻是冰山一角。Anthropic 可能只看到了事情的一小部分,但這已經足以讓我們看到令人難以置信的結構了。」

圖 | Anthropic 的研究人員、本次論文的通訊作者祖舒亞·畢特森(Joshua Batson)(來源:https://www.linkedin.com/in/joshua-batson-63ab9a82/)
由於人們對於大語言模型依舊知之甚少,因此任何新的見解都是向前邁出的一大步。而深入瞭解這些模型在底層到底是如何工作的,將讓人們能夠設計和訓練更好更強大的模型。
不過,這並不意味著 Anthropic 已經找到了模型的所有組成部分。有些地方已經被發現,但很多其他地方仍不清楚,這就像顯微鏡的失真一樣。而且,人類研究人員需要花費數小時,才能追蹤到對於哪怕是非常簡短的提示的反應。更重要的是,大語言模型可以執行大量不同的任務,而 Anthropic 的這一系列研究目前只研究了其中的 10 個任務。
雖然通路追蹤可用於觀察大語言模型內部的結構,但它無法揭示這些結構在訓練過程中是如何以及為何形成的機制。不過,Anthropic 的這項研究標誌著一個新起點的開始,讓人們終於有望找到模型到底是如何工作的真實證據。
參考資料:
https://transformer-circuits.pub/2025/attribution-graphs/methods.html#discussion
https://www.technologyreview.com/2025/03/27/1113916/anthropic-can-now-track-the-bizarre-inner-workings-of-a-large-language-model/
運營/排版:何晨龍