大,就聰明嗎?論模型的「尺寸虛胖」
你可能刷過這樣的新聞:
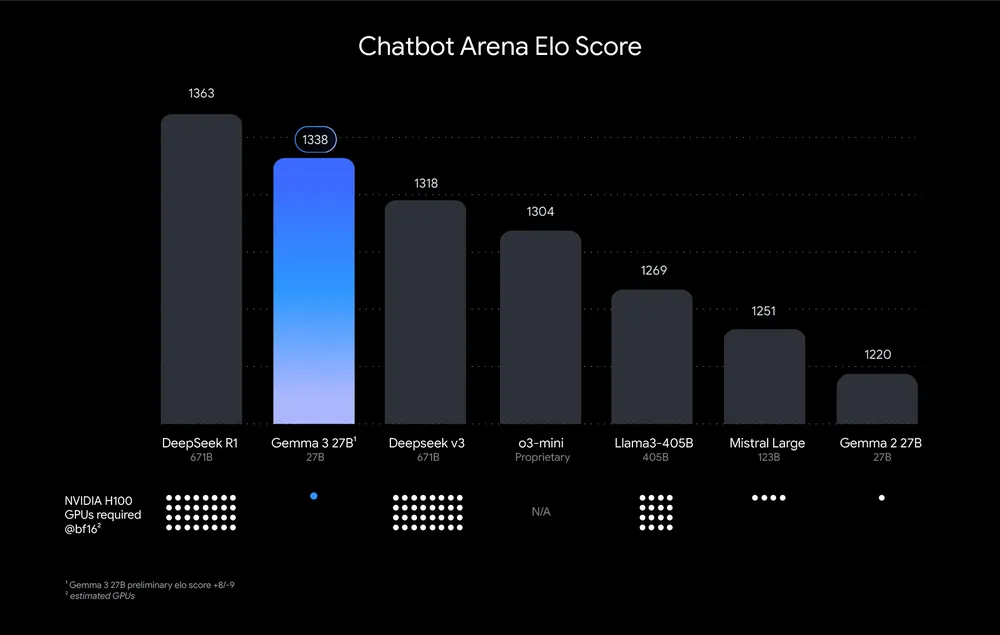
一個只有 27B Gemma-3 參數的小模型,竟和 671B 參數 DeepSeek V3 不相上下。世界又要變天了
後面,可能還帶個圖,像這樣:
 Gemma:我 27B
Gemma:我 27B這種「技術奇蹟」 ,總被媒體反復包裝成「一夜變天」 ,但其實並不新鮮:
-
• 大模型說:我參數更大、上限更高。
-
• 小模型說:我表現差不多,推理還便宜。
-
• 廠商都在說自己贏了,讀者卻越來越搞不懂這到底在比什麼。
細究起來,這表面是在做模型對比,實則是兩種語言體繫在雞同鴨講,而參數恰成了「最容易理解、但最容易誤導」的數字,如同:用人口數量,來判斷足球水平。
我想藉著這個話題,來聊聊幾個核心問題:
-
• 為什麼參數量大 ≠ 實際效果強?
-
• Dense 和 MoE 到底是怎麼一回事?
-
• 「看起來很大」的模型,到底動用了多少能力?
-
• 在大模型持續擴張的趨勢下,小模型還有哪些「後發機制」?
大,不一定「聰明」
我們說「參數量大 ≠ 實際效果強」,不是在否定參數的意義,而是在拆一個經常被誤用的判斷標準。最常見的誤區,就是把不同類型的模型,拉到同一個坐標軸上用參數量做對比:而它們,本就沒有可比性。
Gemma-3 是 Dense 架構,也就是稠密模型,它的全部 27B 參數在使用中都會被激活,全部參與計算,屬於「全員出戰」的結構。
DeepSeek V3 是 MoE 架構(Mixture of Experts),也就是混合專家模型。它的總參數量高達 671B,但每次推理只會激活其中一小部分專家網絡,實際參與計算的大約是 37B。剩下的大多數參數處於「待命狀態」。
 Dense VS MoE
Dense VS MoE你看到的是 671B vs 27B,但模型實際調用的是 37B vs 27B:這看上去體量懸殊,實則差別不大。所以說,參數比較本身沒問題,問題在於不能混著比。
當然了,在同一架構內(比如 Dense 對 Dense),參數依然是判斷能力上限的重要指標;但跨架構直接對比參數數量,得出的「誰強誰弱」往往是錯位的。
MoE 的由來
接著回來說說參數:參數的增加能帶來「規模效應」——也就是能力的非線性躍遷。因此,各家模型才持續堆大,從 GPT-2 到 GPT-3,再到 PaLM、Gemini、Qwen,每一代都在衝上限。
只不過,Dense 架構的增長曲線實在太「正經」了。隨著參數規模增大,算力成本也得不斷翻翻,幾乎沒有優化空間。當參數飆升到幾千億、上萬億時,一輪訓練就要燒掉上千萬美元,硬件和能源的門檻也迅速被拉高。模型越大,訓練成本越高,硬件要求越嚴,能做的人越來越少。
MoE 的到來,正是為了在不炸成本的前提下,繼續擴容。
MoE 並不是哪個廠商的獨門絕技,而是淵源已久。早在1991年, Michael I. Jordan 和 Geoffrey E. Hinton 就提出這個思想。只不過當時受限於工程能力,難以真正落地。直到2017年,Google 的 Jeff Dean 團隊將 MoE 應用於 LSTM 架構,訓練出了一個 137B 參數的模型,參數規模巨大,但計算開銷卻沒有爆表,這一嘗試也正式為大模型擴容打開了新路。
 Adaptive Mixtures of Local Experts
Adaptive Mixtures of Local Experts2020年,Google 推出結合 Transformer 架構的 Switch Transformer,參數量飆升至 1.6 萬億。這並不是為了炫數字,而是為了驗證一個核心概念:參數可以很多,但不需要每次都全部激活。只要調度得當,就能在控制計算成本的同時,獲得更高的模型容量。 這也徹底改變了大模型的設計邏輯,從「每個參數都得上場」,變為「讓對的專家在對的時刻出場」。
國內最早大規模落地 MoE 架構的,是「悟道」團隊(北京智源研究院),2021年,他們訓練了一個 1.75 萬億參數的模型,並自研了 FastMoE 框架,重寫了底層調度邏輯,才支撐起這種超大規模的訓練任務。自此,MoE 架構逐漸成為工業級大模型的主流形態之一,Google PaLM、Mistral-8x22B、阿里的 Qwen-MoE 等也陸續採用類似方案。
 2021年,悟道2.0發佈
2021年,悟道2.0發佈DeepSeek 則做出了一些「本土創新」,比如引入「細粒度專家」機制,把原本的大模塊進一步細分,提升了專家的專業性;同時設計了「共享專家」組件,用於捕捉底層通用知識,減少冗餘,也提升了多任務之間的表現一致性。這些改進一方面減輕了算力壓力,另一方面也有效緩解了傳統 MoE 常見的問題,比如:路由不穩定、風格漂移、知識碎片化等。
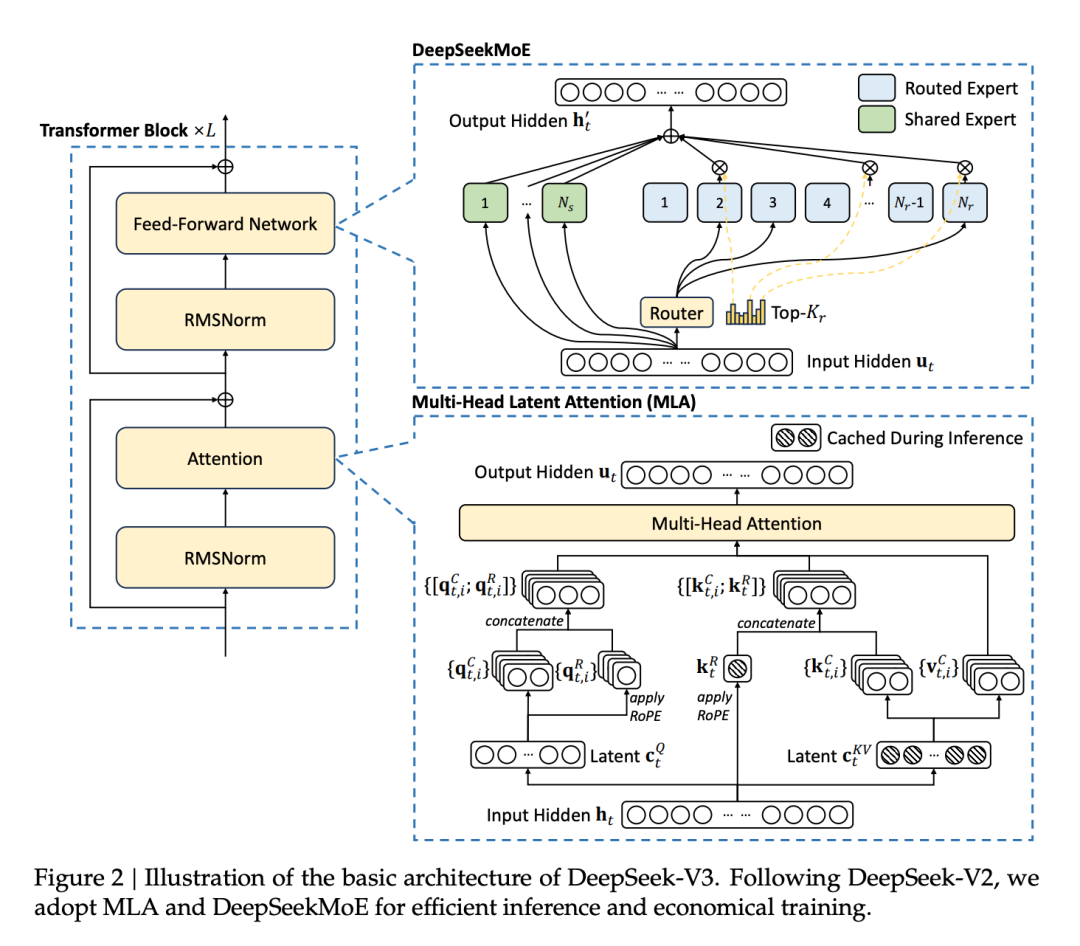 DeepSeek MoE
DeepSeek MoE但也正是 DeepSeek 的出色表現,帶來了一些新的誤解。比如,不少人將「MoE」簡單等同於「更聰明」「更先進」,反過來認為 Dense 模型因為體積小就一定弱。這其實是一個需要澄清的觀念偏差。MoE 和 Dense,本質上只是兩種不同的資源調度策略,是否採用 MoE,並不能決定一個模型是不是「聰明」。真正決定智能水平的,仍然是模型的訓練質量、架構合理性、任務適配能力。
有關 MoE 的另一個誤解是「用不到的專家,不佔資源」。正相反,在 MoE 架構中,雖然每次只激活少數專家,但所有參數依然必須常駐顯存,真正部署起來的硬件負擔一點都不輕。因此,對於私有部署同性能模型來說,MoE 顯卡成本會高出很多。
小,也可以「聰明」
聰明,不一定靠「大」。
人可以靠後天努力提升能力,小模型也能成長,比如通過知識蒸餾(Knowledge Distillation):讓小模型參考大模型的答案,並模仿它處理任務的方式。它的本質仍然是「看答案」,但不是死記答案,而是學會答題的思路和節奏。
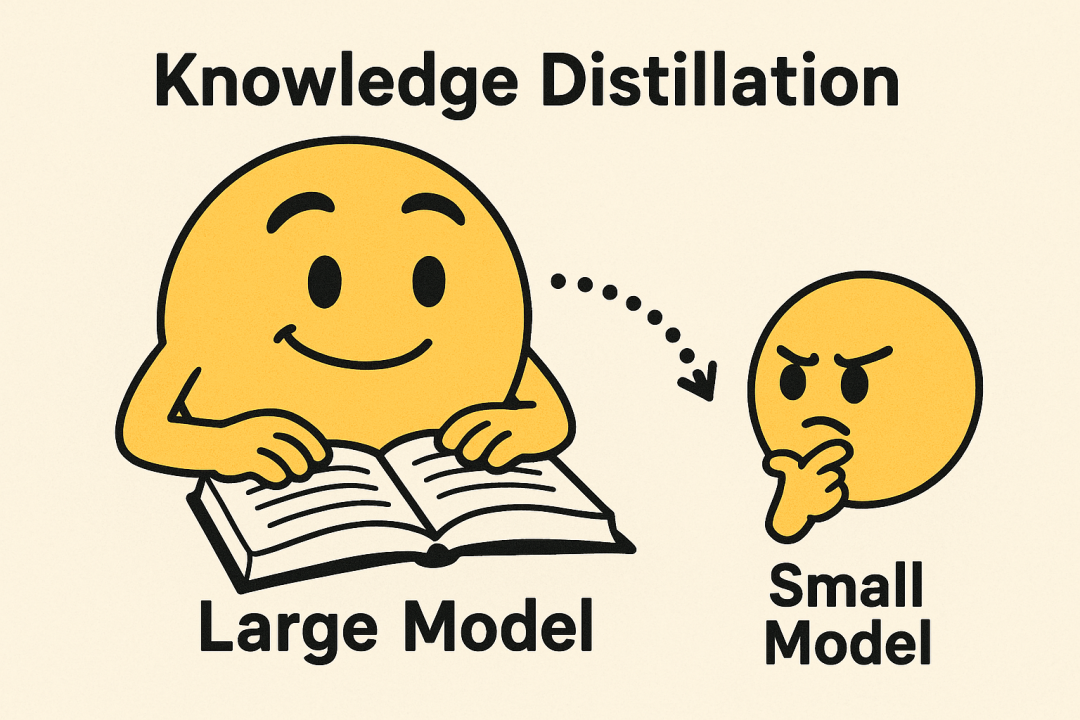 模型蒸餾
模型蒸餾整個過程通常是這樣的:
1. 大模型先跑一輪任務,生成高質量參考輸出,比如說「五年急轉彎,三年弱智吧」;
2. 小模型拿這些答案來學習,但重點不在「複製結果」,而是在模仿—— 學它怎麼理解問題、怎麼組織信息、怎麼一步步得出結論。
需知:蒸餾並不是「把大模型壓縮成小模型」,而是把聰明的部分提煉出來、遷移過去,保留了方法論(而不是複製黏貼參數)。
比如 DeepSeek-R1 的蒸餾版 —— DeepSeek-R1-Distill-Qwen-32B,就是一個很典型的例子:雖然參數縮小了一個數量級,但在多個任務上的表現依然接近,甚至在一些結構化輸出上更穩定。
可見,聰明不是大模型的特權,是訓練出來的本事。
寫在最後
模型的對比,不是參數拉踩,不是看誰的數字更大、名字更響。
MoE 架構的出現,是為了讓大模型在成本可控的前提下繼續擴容;而知識蒸餾,則讓小模型有機會承接大模型的能力,用更輕的體積完成更多的任務。它們分別指向兩個方向,但都在回答同一個問題:如何更高效地使用資源。
所以,真正值得關注的,不是模型有多大,而是它能不能把事辦好、辦穩、辦漂亮。
畢竟,「大」不一定代表聰明。
當然,如果名字就叫「大聰明」,那另說