GPT-4o 「吉卜力」爆火,Prompt、SD 白學了?!大模型能力進化碾壓一切

作者 | 褚杏娟、華衛
策劃|Tina
ChatGPT 的新 AI 圖像生成功能上線僅兩天,社交媒體上便已充斥著以日本動畫工作室吉卜力風格的 AI 生成梗圖,埃隆·馬斯克、《指環王》和美國總統唐納德·特朗普都沒「逃過」,甚至 OpenAI 首席執行官薩姆·奧爾特曼也將他的新頭像設置為吉卜力風格的圖片。 (吉卜力工作室以製作《龍貓》和《千與千尋》等熱門影片而聞名。 )
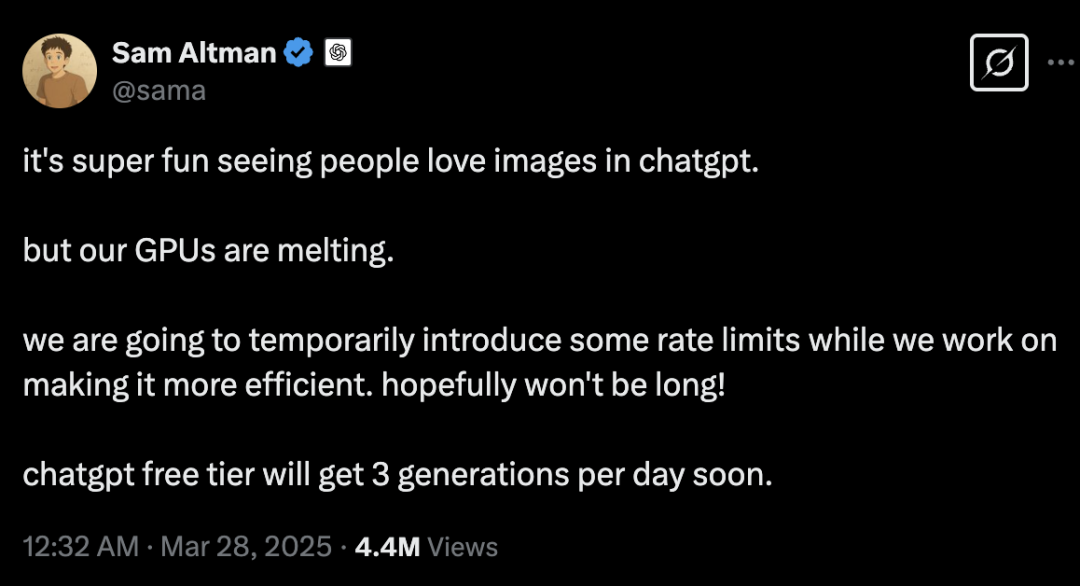
大量用戶正在將現有的圖像上傳到 ChatGPT,並要求聊天機器人以新的風格重新創作這些圖像。今天,奧爾特曼在 X 上發文表示:「看到大家如此喜愛 ChatGPT 的圖像功能非常有趣,但我們的 GPU 快扛不住了。」雖未具體說明限制次數,但 Altman 稱該措施不會持續太長時間,因為他們正在嘗試提升處理海量請求的效率,免費用戶將「很快」能每天最多生成三張圖像。
雖然後續 OpenAI 又宣佈了對 GPT-4o 進行了更新,但顯然人們的注意力還在「玩圖」上。
「我認為,這個功能是過去半年里 OpenAI 發佈的 GPT-4o 中最有價值的一個,它確實非常炸裂。相比之下,正式上線的 Sora 以及後來連續 12 天的直播所展示的內容,大多都沒有超出人們的預期。」原快手可圖大模型負責人李岩說道。
與 SD 等模型比,
GPT-4o 贏在了哪裡?
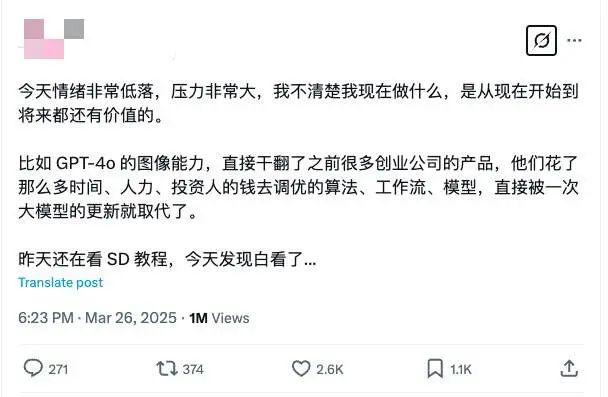
「昨天還在看 SD 教程,今天發現白看了……」知名開發者 Jimmy Cheung 發帖說道,「今天情緒非常低落,壓力非常大,我不清楚我現在做什麼,是從現在開始到將來都還有價值的。」
李岩表示,這次 GPT-4o 火爆的關鍵在於實現了對話式圖像生成。
實際上,基於自然語言指令的圖像編輯能力之前已經有了,比如字節 SeedEdit 和 Google Gemini 2.0 都具備相似能力。但在實際生成過程中,指令響應能力沒有那麼強,效果做得沒有那麼好。
例如在一致性保持方面,當要求去除背景中的某個物體時,模型可能還去掉了其他的東西;或者在對人物進行特定修改時,最終效果可能是不像原來的人了。此外,還存在指令不響應的問題,比如要求添加某些元素時未能執行。
但這次 GPT-4o 的交互方式所達到的文本跟圖像的響應是非常精準的,大大超出了大家的預期。
李岩分析,雖然 OpenAI 沒有發佈詳細的技術報告,但有一點非常明確:他們一定採用了自回歸框架(Autoregressive Model, AR),只有自回歸框架才能實現如此自然的圖文交互效果。後續大概率也接入了 decode 模塊後再做圖像生成,但其整體框架已經完全統一到了自回歸框架之下。
具體說來,Flux、Stable Diffusion 等模型,現在的做法都是將文本表徵和圖像生成過程進行解耦,然後擴散模型出圖。這種方式通常要先對文本進行完整表徵,例如通過 CLIP 或大語言模型提取特徵,然後將該特徵直接輸入擴散模型,並要求擴散模型在生成圖像的整個過程中持續參考這個固定的文本特徵。這個文本特徵的來源是用戶輸入的 prompt,某種編碼器的方式會對 prompt 進行特徵提取。
然而問題在於:特徵提取完成後,信息量就被固定了。在文本到圖像的生成過程中,100% 的原始信息都存在於用戶輸入的文本 prompt 中,但經過文本編碼或表徵提取後可能只剩下 70% 的信息,這意味著後續最多就只能基於這 70% 的信息量進行圖像生成。
當前幾乎所有圖像生成模型都採用了上述模式。但可以看出,這些模型在生成文本表徵時都會不可避免地造成信息損失,而這種損失一旦形成固定的 embedding 或表徵就無法挽回,這一階段出現的信息缺失,後續擴散模型在生成圖像時是無法回溯彌補的。
當前,擴散模型的擴充方式是 prompt engineering(提示詞工程)。但是,提示詞工程只能擴展成顯式描述,比如輸入「一個漂亮的小女孩」,系統會將其擴展為非常詳細的描述,包括小女孩戴著什麼樣的帽子、出現在什麼樣的背景下等等。但這種方式在後續建模中仍然需要提取文本特徵,依然會造成信息損失。只要是採用二階段的方式,即先建模文本再以文本為條件輸入擴散模型,就必然會因為文本建模過程中的信息損失導致最終生成的圖像無法與文本描述 100% 對齊。
GPT-4o 之所以強大,關鍵在於它能有效處理用戶提供的簡潔信息。例如,用戶通常只會簡單地輸入:「幫我畫一隻小貓或小狗」,但不會給出具體是什麼樣的貓或狗。現在,GPT-4o 統一到大語言模型的自回歸框架下,所以天然具備了語義泛化能力。這種能力本質上源於模型本身的知識儲備,使其能夠準確理解用戶簡單文字背後代表的真正的、稠密的信息量是什麼。
正是由於 GPT-4o 擁有強大的大語言模型作為知識基礎,它才能在完整的端到端框架中實現如此精準的理解和生成能力,這一點至關重要。模型輸入的就是用戶的原始 prompt,然後直接出圖,中間過程中沒有二階段損失,都是一階段做的,可以充分利用大語言模型所帶來的隱式知識,包括擴充 prompt 等。
另外一點是,原來的方法僅支持單輪操作,即輸入文字生成提示詞,再通過特徵提取生成圖像,但無法支持多輪條件控制。
GPT-4o 可以直接將圖片按照上傳圖片的風格生成新圖像,其中關鍵在於需要理解上下文中的具體指向,如「剛才提到的狗的照片是哪一張」,這需要大語言模型具備跨模態理解能力。在自回歸框架下,上下文從純文本擴展到了文本 + 圖像,因此模型能輕鬆 get 上下文,甚至遠程的上下文。
值得注意的是,從出圖質量來看,目前基於自回歸框架的生成效果並沒有碾壓式地超過擴散模型,甚至可能還不如擴散模型的表現。現階段,兩者的生成質量水平其實相差不大。
李岩指出,這僅僅是就出圖效果而言,我們更應該關注的是交互方式的差異。未來在交互體驗方面,自回歸框架顯然具有更大的理論優勢,它能夠更好地兼容完全開放的自由度,實現更接近自然語言對話式的交互方式。
「這種 Interleaved 的圖文交錯技術才是真正原生的多模態大模型。」李岩認為,在當前行業中,真正意義上的原生全模態的大模型領域里,OpenAI 還是走在最靠前的。
此外,李岩表示,「文生圖架構沒有什麼可以爭議的了,在 2025 年這個話題就不是話題了。」
自回歸框架對於多模態裡面的文本模態、音頻模態,自不用多說,基本上已經證明了是可行的,難點在於視覺模態。現在行業內最好的模型,包括開源的 Flux、閉源的可靈、Sora 等,還在用 DIT 的架構,真正做到高精度的視覺生成現在還離不開擴散模型,但圖像生成領域,單靠自回歸框架實際上是有可能達到一個新的高度的,這件事情 GPT-4o 已經給出了答案。
李岩還大膽設想,如果 GPT-4o 接入聯網功能並整合 RAG 技術,其在圖像生成方面的潛力將更加巨大。通過 RAG 技術,模型可以直接檢索到用戶所指的網絡流行梗或熱點,用戶就不需要再上傳參考圖片了。例如,當用戶想生成網絡流行表情包時,GPT-4o 可能無需參考圖片,僅憑對網絡流行文化的理解就能準確捕捉到用戶想要的梗,這將進一步提升文生圖應用的便捷性和準確性。
是否會吞噬所有產品?
OpenAI 發佈 GPT-4o 文生圖功能後,Jimmy Cheung 的評價是:GPT-4o 的圖像能力,直接干翻了之前很多創業公司的產品,他們花了那麼多時間、人力、投資人的錢去調優的算法、工作流、模型,直接被一次大模型的更新就取代了。
除了 Jimmy Cheung 「抽水」「SD 白學了」,還有網民感歎,學了兩年的作圖工具流 comfyUI 也白學了。一部分人直接大呼:工作流已死。事實上,對於像 comfyUI 這樣的工作流產品而言,情況可能沒有那麼悲觀。
「GPT-4o 目前為止的結果確實挺顛覆,但在真正的商業化可用的能力上,現在不太行,相當長一段時間還是要依賴 comfyUI。」李岩說道。
比如,當前 GPT-4o 的出圖大小並不能滿足實際商拍場景里的需求,解像度的提高會需要一些外接能力。另外,OpenAI 在照片改換風格時是做全圖的重繪,細化到了圖像的每一個像素點,但在實際情況中,用戶可能只需要改某一塊地方,其他地方,甚至一個像素值都不能動,這樣的需求就需要 comfyUI 這類非常細粒度的工作流方式去精細化處理。
comfyUI 裡面有後處理、摳圖、調整亮度等很多鏈路,支持使用基於圖形、節點和流程圖的界面來設計和執行高級的穩定擴散流水線。
「對於輕娛樂場景或者要求沒有那麼高的批量生產場景,GPT-4o 現在已經可以發揮價值了。但對於容忍度比較低、項目要求非常高的場景,未來相當長一段時間里還是要依賴 comfyUI。」李岩總結道。
但是,GPT-4o 對於 Prompt 工程可能會是致命打擊。
「Prompt 工程這件事有可能以後變得也沒那麼重要了。」李岩解釋稱,現在 Prompt 對文生圖、文生影片模型很重要,是因為整個文本側和圖像側還沒有辦法做到那麼強的 alignment 效果,所以需要儘可能把文本側的內容寫明確、減少信息損失,因此誕生了 prompt engineer。但實際上未來這部分工作如果如果能統一到 GPT-4o 的框架里,這份工作大家慢慢就不需要了。就算 Prompt 寫的不好也沒關係,還可以再改,只需把不滿意的改進點用自然語言描述給模型,模型就會理解到底應該怎麼改。
在李岩看來,GPT-4o 這次更加證明了工具型產品會更容易被大模型能力吞噬。比如美顏類工具,對於不懂美顏的男生來說,語言交互就可以得到理想的效果。
但顯然,作為正在遭受「衝擊」的 Midjourney 並不這樣想。Midjourney CEO David Holz 犀利指出:GPT-4o 的圖像生成速度慢、效果又差,OpenAI 只是為了籌集資金,而且在以一種不良競爭的方式行事。這不過是一時的噱頭,並非創作工具,不出一週就沒人會再談論它了。
據稱,Midjourney 準備在下週推出最新的 V7 版。值得注意的是,領導 Midjourney V2 至 V7 模型開發的核心人物 theseriousadult 在 3 月 21 日宣佈離職,之後將加入 Cursor 轉做 AI 編程 Agent。
而早在 GPT-4o 掀起此次關於「大模型是否會吞噬所有產品」的熱議之前,AI 科技公司 Pleias 聯合創始人 Alexander Doria 就提出了「模型就是產品」的觀點。他明確指出:所有投資者一直都在押注應用層,但在人工智能進化的下一階段,應用層很可能是最先被自動化和顛覆的。同時,Doria 還認為,OpenAI 的 DeepResearch 和 Claude Sonnet 3.7,以及「不僅把模型當作產品,而且將其視為通用基礎設施層」的 DeepSeek,都是「模型作為產品」的典型示例。
不過,就目前的大模型能力來看,大模型暫不能覆蓋到所有的應用產品。但這種低門檻的使用形式,似乎正一步步瓦解許多現有的各類產品邏輯和形態。
結束語
大模型更多是在做技術平權這件事,就是讓很多不懂技術的人逐漸都可以公平地使用大模型。在技術迅速變化的當下,每個人,甚至企業都很容易被迫進行戰略調整,甚至轉向。
李岩的建議是,首先,要明確自己在這個行業中的具體業務需求。其次,在實際工作中,每個人都應該採取兩種策略:一是「低頭走路」,確保自己對所用工具的理解和運用熟練,從而穩步前進;二是「抬頭看路」,關注行業的發展和變化。這兩者不是相互排斥,而是需要同時進行,以便我們在專注工作的同時,及時調整方向。
李岩認為,未來大模型的發展將深刻影響各行業的組織形態和人員能力結構。以傳統的人才金字塔為例,其結構通常分為底層、中腰部和頂層。目前看來,底層能力畫像的人會被大面積「吞噬」,接著是腰部能力的人群,而最頭部的那部分人永遠不會被大模型吞噬,因為大模型本身也需要他們的 feedback 和教化。
「所以,每一個人應該儘量避免做技術含量低的工作,而是慢慢往上去走。」李岩說道。
聲明:本文為 AI 前線整理,不代表平台觀點,未經許可禁止轉載。