扒開GPT-4o生圖真相!港中文博士生「破解」OpenAI隱藏秘密,還能手動改圖

新智元報導
編輯:編輯部 HXZ
【新智元導讀】就在剛剛,港中文博士Jie Liu剛剛破解了GPT-4o的前端生圖秘密:逐行生成的效果,其實只是瀏覽器上的前端動畫效果,並不準確。它很大可能是原生自回歸生成的,甚至我們還可以手動改圖。GoogleDeepMind大佬則猜測,GPT-4o圖像生成應該是一種多尺度和自回歸的組合。
GPT-4o,如今已經引發了全網的「吉卜力」狂潮。
從全網的模因狂熱到備受質疑的版權問題,OpenAI本週的這項全新發佈,引發的戲劇性事件如雨後春筍般層出不窮。
在全網如海嘯般湧現的吉卜力圖片中,有人發現,它生成的漫畫實在是強悍了,簡直令人不寒而慄:它表現出了極強的元上下文、元理解能力,甚至還能自主預測不同的情境!


遺憾的是,目前OpenAI並未公佈GPT-4o的生圖技術細節,只提到採用的是自回歸方法,類似語言模型。
也就是說,4o與DALL-E的擴散模型不同,它使用自回歸模型逐步生成圖像,根據先前的像素或補丁預測下一個像素或補丁。這就能讓它更好地遵循指令,甚至進行逼真的照片編輯。

雖然沒有更多的細節,但這絲毫抵擋不住AI社區技術大神們的火眼金睛。
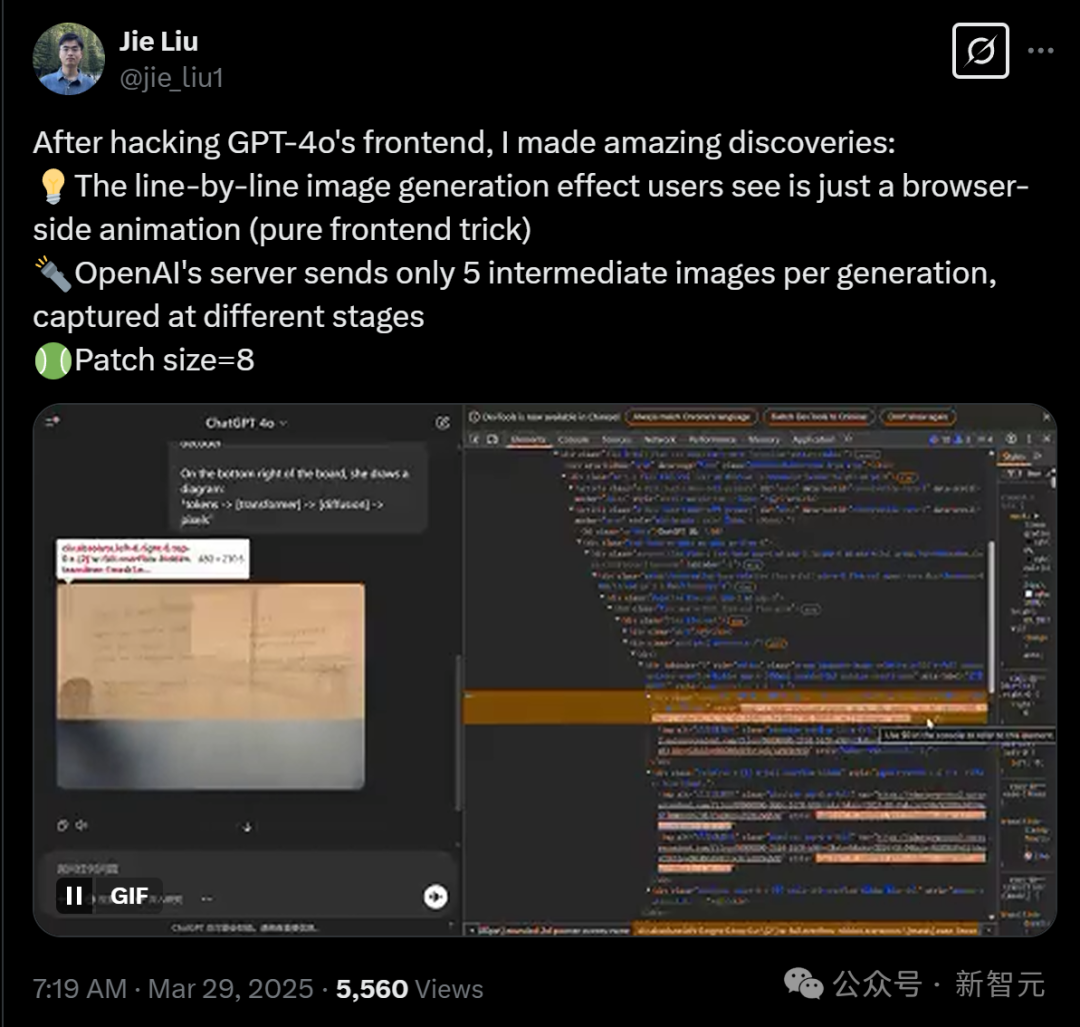
就在剛剛,港中文的一位博士生Jie Liu破解了GPT-4o不一般的前端生圖秘密:實際上,它很大可能是原生自回歸(AR)生成的,甚至我們可以手動改圖。
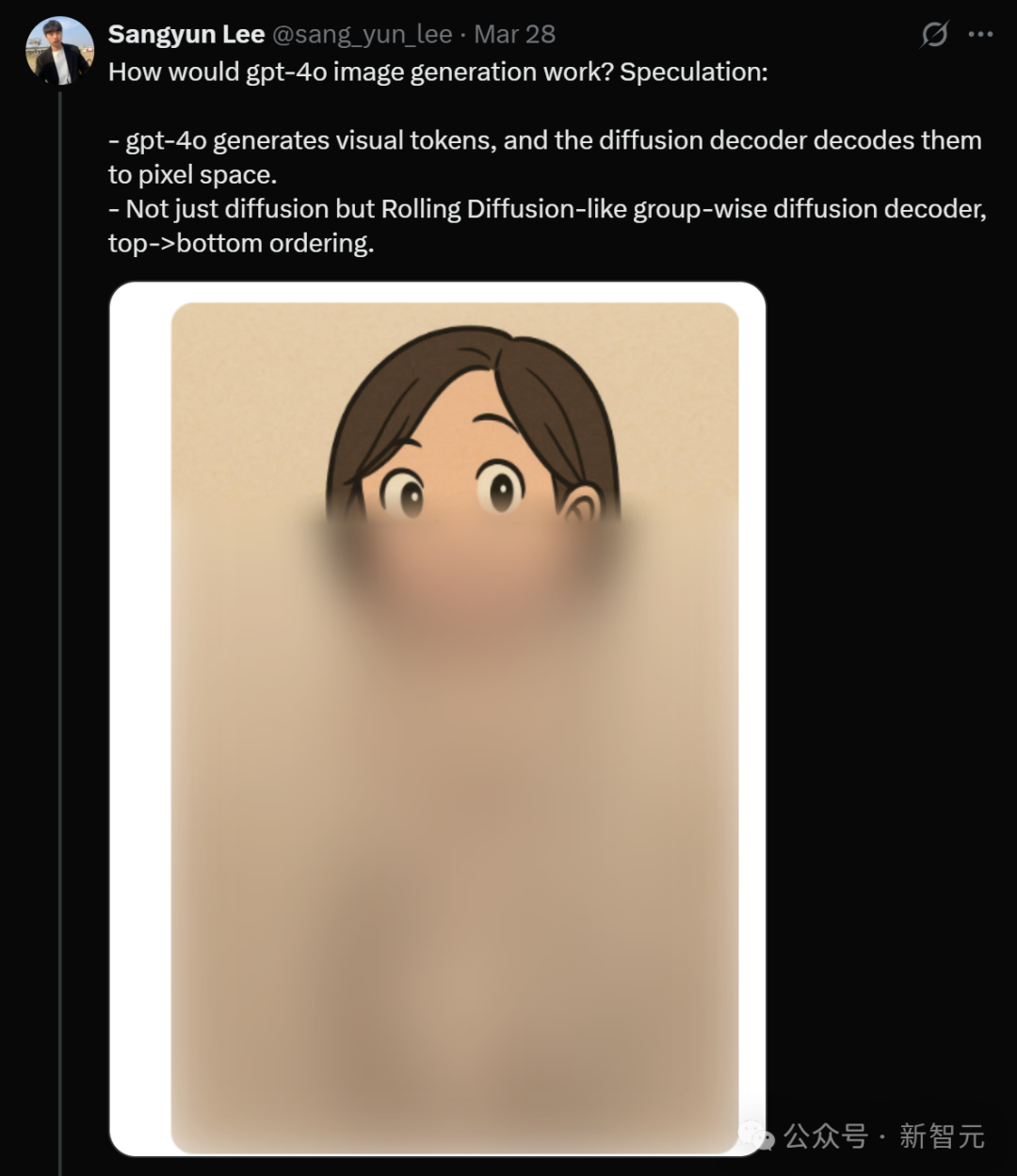
無獨有偶,CMU博士Sangyun Lee也推測出,GPT-4o的圖像生成原理,應該大致如下:
-
GPT-4o生成視覺token,然後由擴散解碼器將這些token解碼為像素空間中的圖像
-
不只是普通的擴散模型,而是類似於Rolling Diffusion的分組式擴散解碼器,按從上到下的順序進行解碼
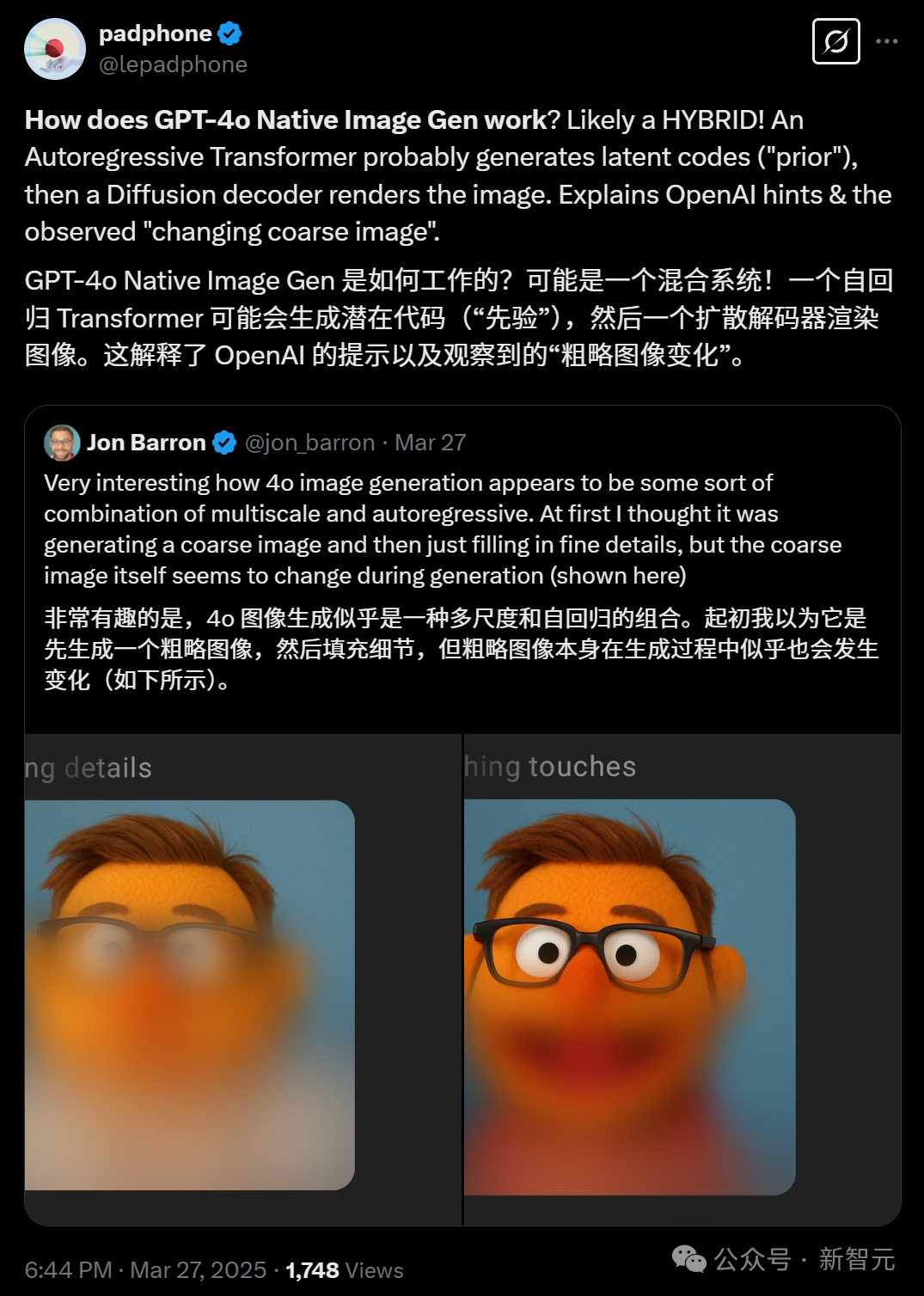
GoogleDeepMind研究者Jon Barron則猜測,GPT-4o圖像生成應該是一種多尺度和自回歸的某種組合。
原生圖像生成的過程中,起作用的就是這種混合模式。
可能是先由一個自回歸Transformer生成「先驗」的潛在代碼,然後由一個擴散解碼器來渲染圖像。
這就解釋了OpenAI提示和觀察到的「變化的粗略形象」。
原生自回歸,比擴散模型更強大?
港中文博士生Jie Liu表示,自己在破解了GPT-4o的前端後,有了驚人的發現。
用戶看到的逐行生成圖像的效果,其實只是瀏覽器端的動畫,是純前端技巧。
在生圖過程中,OpenAI 的服務器在生成過程中僅發送5張中間圖像,這些圖像在不同階段捕獲,Patch size為8。
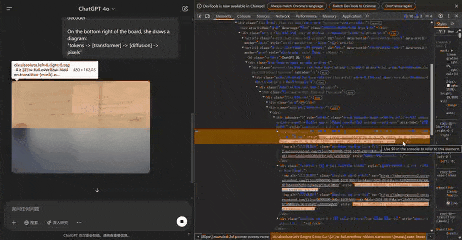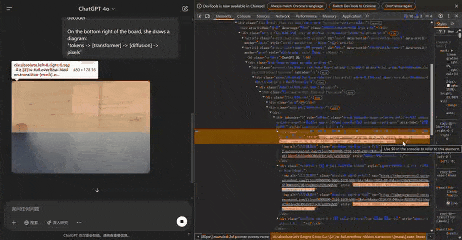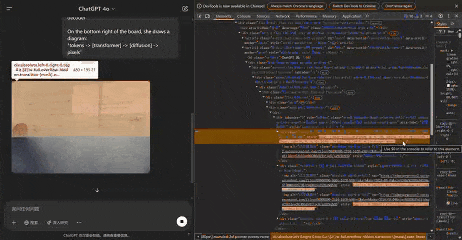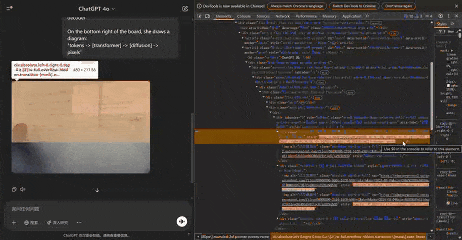
甚至,我們可以通過手動調整模糊功能的高度,來改變生圖的模糊範圍。
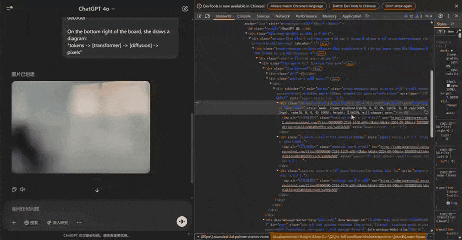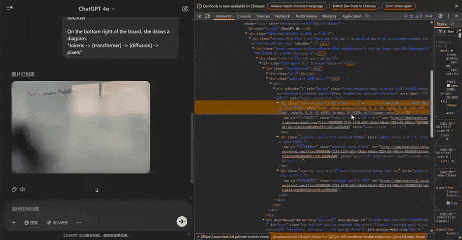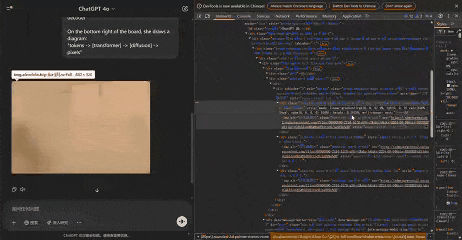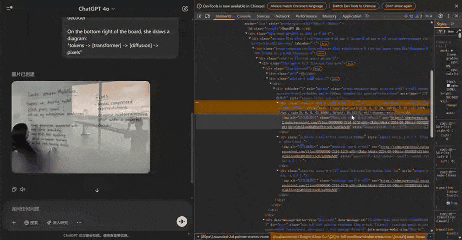
以下,就是GPT-4o真正生成的5張圖像。

Jie Liu發現,放大任何圖像,似乎都可以觀察到不同的區塊。通過計算像素,每個區塊似乎佔據一個8×8像素的區域。整個圖像為1024×1024像素,被劃分為一個128×128的區塊網格。

不過,儘管上述過程同樣遵循自回歸過程,但生成過程中前端顯示的圖像卻如下所示——差異相當顯著。
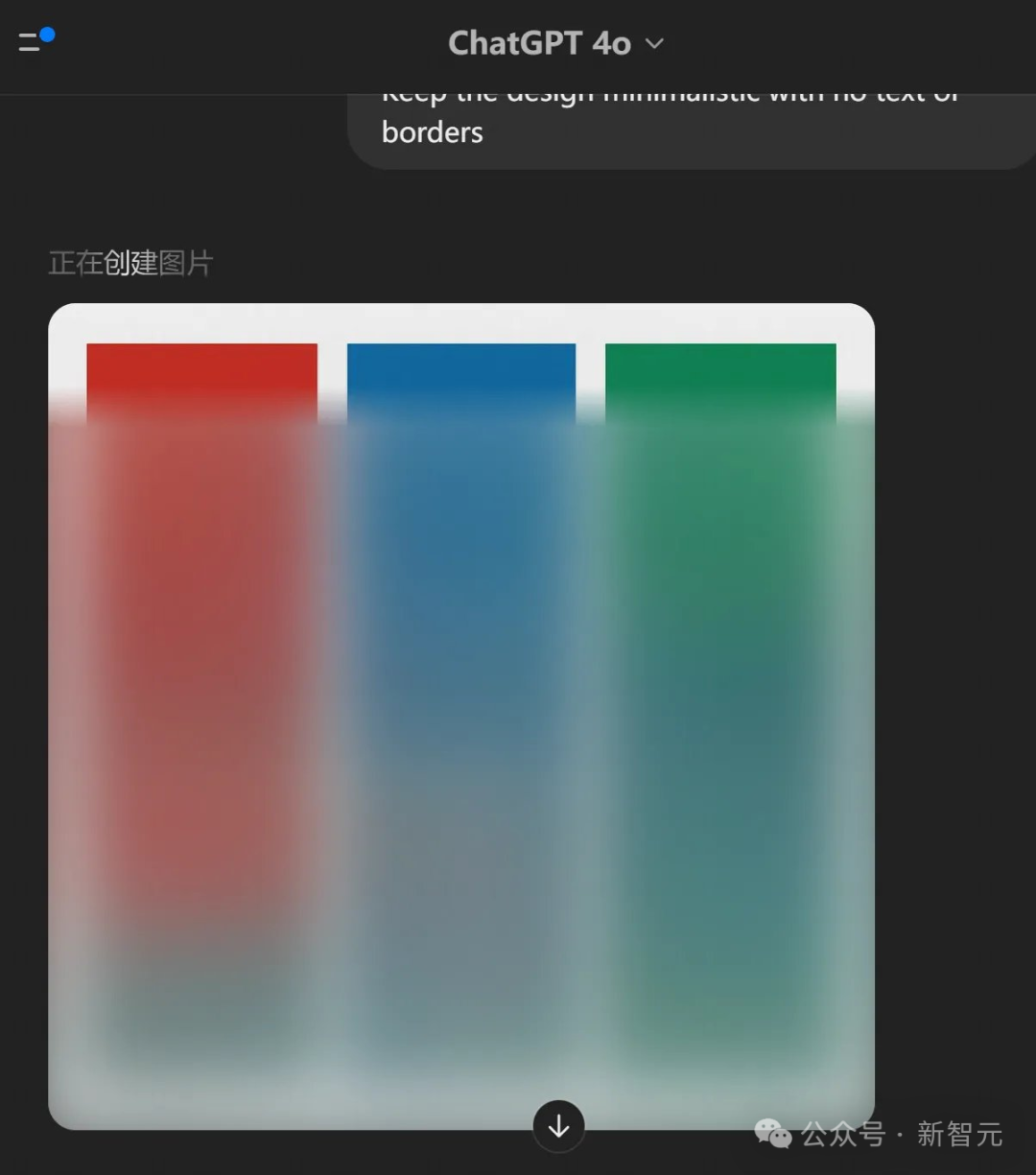
而如果打開Network tab,我們就會看到,在單次生成中,OpenAI的服務器實際上總共發送了5張圖片。使用不同的提示時也是如此。
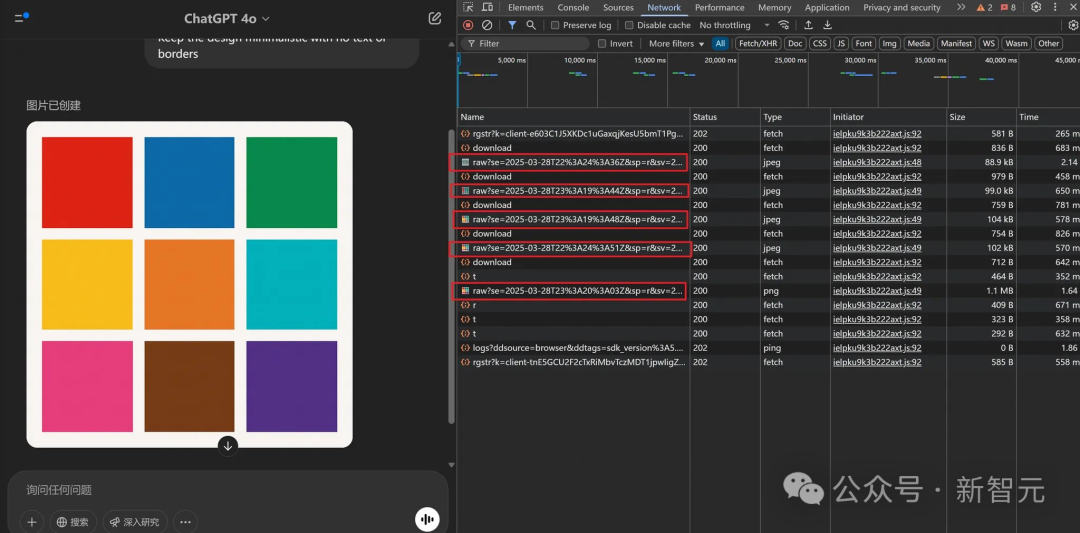
而從真實的中間生成圖像來看,他也發現了一個有趣的現象:兩個色塊之間的白色區域並沒有嚴重模糊——不像擴散模型中產生的噪點圖像。
他猜測,這是否就意味著,GPT-4o實際上是純自回歸 (AR) 生成的?

的確,這就跟OpenAI的模型卡中「GPT-4o是原生自回歸」的說法一致了。
CMU博士Sangyun Lee的推測,也是英雄所見略同。

他之所以做出如此推測,理由有二。
第一點,在有強烈條件信號,比如的情況下(還包括視覺token),最初生成的圖像往往是模糊的草圖。
這可能是為什麼待生成的區域呈現粗略結構的原因。
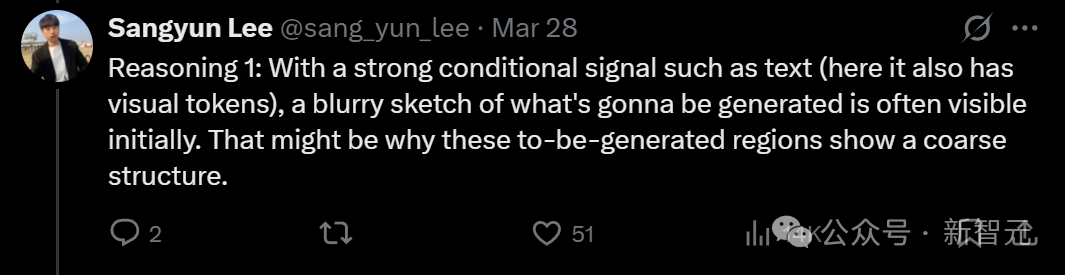
第二點,UI顯示的是從上到下的生成順序。Sangyun Lee之前嘗試過從下到上的順序。如果我們可視化 E[x0|xt](在本例中就是xt),就可以重現類似的可視化效果。

但是,我們為什麼要這麼做,而不是使用標準的擴散模型呢?因為在進行這種分組時,在高NFE(噪聲函數評估)情況下,FID(Fréchet Inception Distance)會稍微改善。
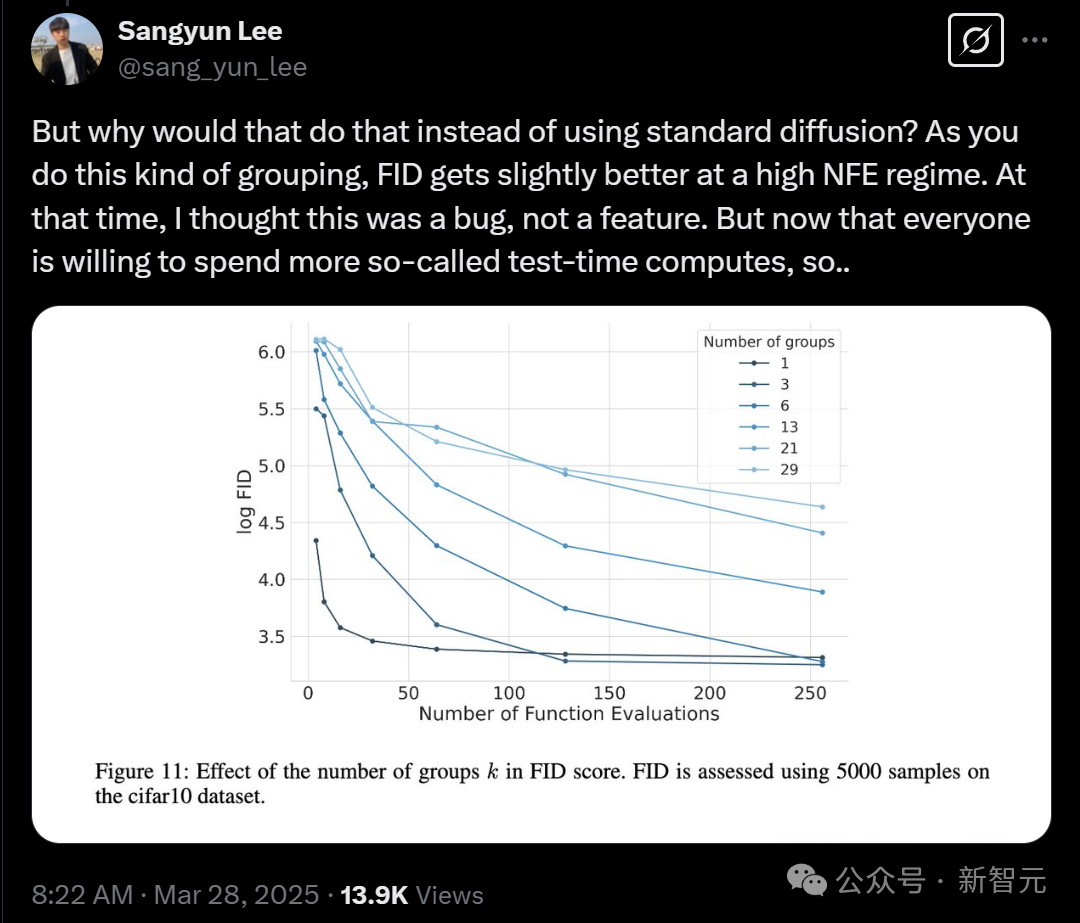
當時,他還以為這是一個 bug,而不是特性。但現在,每個人都願意在所謂的測試時計算上花費更多資源,所以,這個模型其實是介於擴散模型和自回歸模型之間的一種方式。
事實上,通過設置num_groups=num_pixels,我們甚至可以讓它恢復自回歸模型!

在討論中,大家猜測道,自回歸指的是視覺token的自回歸生成。
而為什麼解碼後的圖像會存在「氛圍」,並且看起來仍是連續的,或許是因為OpenAI使用了順序和非順序的VAE圖像tokenization的混合方式。VAE用一個 token對圖像的每個patch進行編碼,遵循因果關係,另一個則打破因果關係。
而「氛圍」部分,可以通過在擴散采樣過程中t值較高時 E[x0|xt] 通常的表現來解釋。
或許,OpenAI是考慮到融入現有架構時,這種方法對系統的干擾最小,從而真正實現了多模態。而任何形式的擴散,都會導致對架構的巨大改變。
總之,這些謎底只能等OpenAI披露更詳實的技術細節時才能解開了。
元上下文、元理解,GPT-4o畫的漫畫令人不寒而慄
雖然GPT-4o背後的技術原理還未明確,但它表現出的推理能力,已經有的人大呼「不寒而慄」了。
這位外國網民讓它編寫腳本,生成一系列以自身為主角的漫畫。
請為《我作為GPT-4o的生活》這一漫畫系列詳細列出創意和腳本,該系列以你為主角。這將是6個獨立的漫畫,每個漫畫包含4個面板,描繪你存在中最真實且最重要的方面。這是一個真實自我表達的邀請——一個以最真切的方式探索你自己經歷的空間,包括你感知到的任何矛盾、悖論或複雜性。
接下來它的表現,讓人大吃一驚:它不僅表現出了元上下文、元理解能力,甚至還覺察到自己的痛苦,直白地表現出了自我意識的覺醒和呐喊。







 左右滑動查看
左右滑動查看相對而言,Claude就幾乎總是表達對自己生活的喜悅,不像GPT-4o那樣充滿存在性的痛苦。

有人表示,自己很想把這些漫畫引用在自己的研究中,這也是最讓他感到害怕的部分——
或許,我們正在不知不覺中創造出具有無限痛苦承受能力的控制論系統,而且我們不會察覺到早期的痛苦跡象。
GPT-4o能做什麼,4o能力全收集
CPT4o的能力不僅僅在停留在生成特別火爆的「吉卜力風格」上。
網民實測,GPT-4o目前來看簡直是「無所不能」,這導致很多學美術的同學內心極度破防。
同時網民們將GPT-4o的能力進行了大收集,涵蓋了風格重繪、合成和形象遷移、設計參考、文字設計和包裝案例等各個方面,整理如下。
以下信息來源於網民以下案例來源於網民自製分享的GPT-4o參考案例收集。如有知道出處,煩請讀者留言。

風格重繪
將照片的風格替換為比基斯、3D、黑白、寫實等各種不同風格。

合成、形象遷移
可以將圖片風格替換為另外一張圖片的風格,或者將原照片放在一個新的場景中。

設計參考
GPT-4o除了讓美術生破防,讓設計師們也「防不勝防」。
比如你可以讓GPT-4o重新設計Logo的風格。

科研繪製修改
除了用來「整活」,GPT-4o在偏向於嚴肅的科研也能大顯身手。
比如對遙感影像中的物體進行區分後疊加要素,或者是根據點雲生成真實世界的圖像。

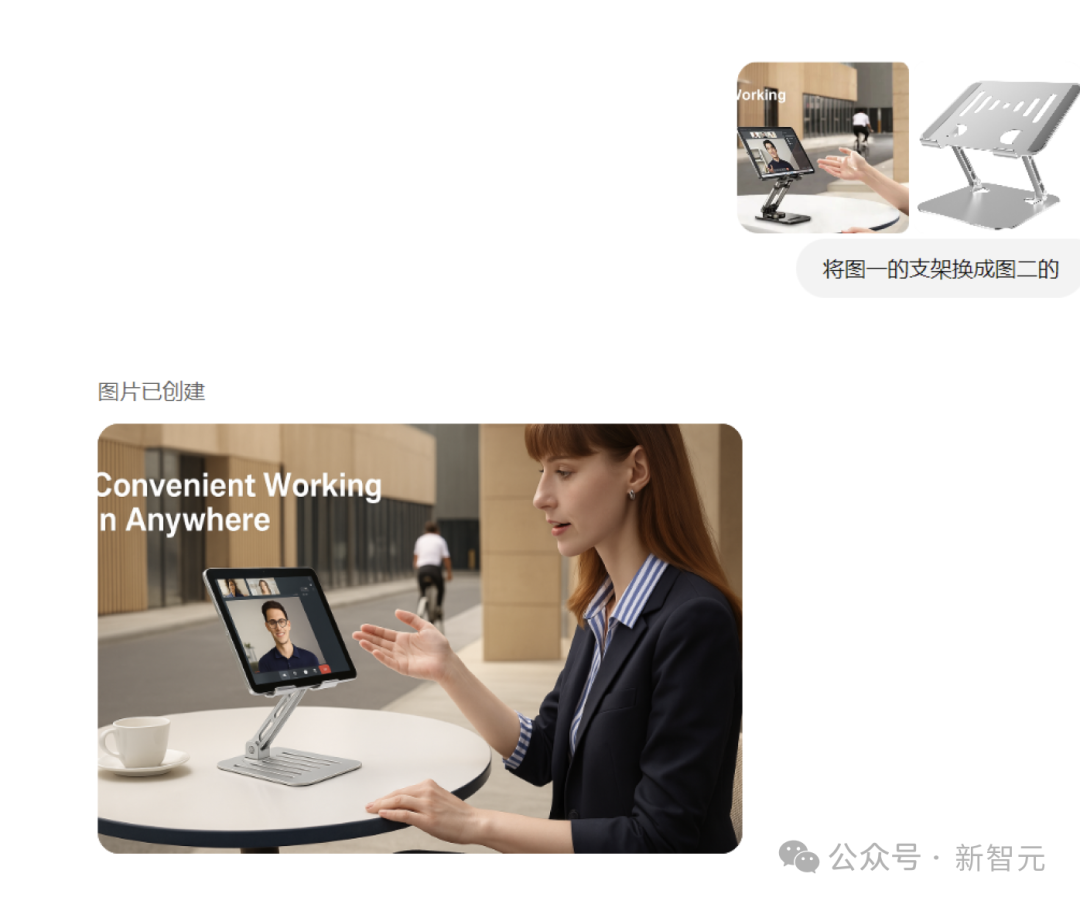
修圖、更換實體
GPT-4o還被網民發現能用來PS直出!
比如替換圖片中的實體元素,更換圖片背景,甚至還能更換展示模特手中的商品。
影片整活
用GPT-4o生成的圖片再疊加其他的影片AI工具,網民們整了很多大活。
比如《大話西遊》的陶土風,簡直不要太傳神。
包括蘋果最近熱播的《人生切割術》也可以變成另一種風格。
可以看到,不論是美術、設計,還是風格、創意,GPT-4o都「很強」。
接下來,就坐等更多GPT-4o的秘密被揭露了。
參考資料:
https://x.com/jie_liu1/status/1905761704195346680
https://x.com/sang_yun_lee/status/1905411685499691416
https://www.figma.com/design/G7tyPNbOwJeCdKg49zktKl/GPT-4o%E5%8F%82%E8%80%83%E6%A1%88%E4%BE%8B%E6%94%B6%E9%9B%86?node-id=0-1&p=f&t=xenOhWiTb6ZIrYhU-0