一週五連發!AI大模型捲出新高度:阿里豆包Google哪家強?

大模型又捲起來了。
3 月 28 日,阿里和字節不約而同地發佈了各自大模型的重磅升級:一邊是能看圖、讀影片、還會解數學題的視覺推理模型 QVQ-Max;另一邊是豆包開啟測試能邊想邊搜的新版「深度思考」。
 圖/ Qwen
圖/ Qwen同一天,兩大國產大模型都按下了新一輪大模型更新的啟動鍵,或許並非巧合。就在本週,各家主流大模型都發佈了一輪更新:
DeepSeek 發佈 V3-0324 新版本,推理、寫作、編碼能力再提升;Google 也推出了 Gemini-2.5-Pro,幾乎獲得了全方位的能力提升,還在 LMArena 榜單上打出了 40 分的絕對領先優勢;OpenAI 也升級了 GPT-4o 圖像生成功能,可控性和質量大幅進化。
各家基礎模型又捲了起來。
從圖像生成到視覺推理,從多模態到超長上下文,這一輪更新更像是一場全方位能力升級的排位賽——不僅卷功能、卷質量,還在卷「智能體時代」誰能提供更好的基礎模型。
五大模型集體上新,
到底在卷什麼?
1、阿里 QVQ-Max:視覺推理能力全開。
 圖/ 阿里
圖/ 阿里對於視覺推理模型,阿里的野心和意圖都非常明顯。早在去年 12 月,阿里 Qwen 團隊就探索性地推出了 QVQ-72B-Preview 視覺推理模型。到了今年 1 月,又為雷鳥創新打造了用於雷鳥 V3 AI 眼鏡的定製模型。
而 QVQ-Max 則是一次全面的升級,不僅能「看懂」圖表、照片、甚至對影片內容進行理解,結合這些信息進行分析、推理,給出解決方案。比如,它能「看」出一組幾何圖形之間的角度關係,或是預測影片中下一秒可能發生的行為,在多模態基準測試上表現出色。
簡單來說,QVQ-Max 對圖片的解析能力非常強,無論是複雜的圖表還是日常生活中隨手拍的照片,它都能快速識別出關鍵元素,同時 QVQ-Max 還能進一步分析這些信息,並結合背景知識得出結論。
 圖/ Qwen
圖/ Qwen另外值得一提,QVQ-Max 目前已經上線了 Qwen Chat(https://chat.qwen.ai),簡單上手體驗了下,對於照片的分析明顯強於Qwen2.5-Max,甚至可以根據「左上角logo是中國銀行」的提醒對應到照片中。
2、豆包新版「深度思考」,主打一個推理進階。
幾乎在同一時間,字節豆包也測試上線了新版「深度思考」能力,支持在思維鏈條展開的同時動態發起搜索,實現「邊想邊搜」。實際體驗中,豆包會在思考過程中搜索資料,不斷通過搜索補充信息再思考。
簡單來說,用戶提問如果涉及時間、地點、上下文變化或需要跨知識鏈的信息整合,豆包將不再「一次性搜一堆」,而是會在推理過程中多次觸發搜索節點,不斷修正和豐富自身的思維路徑。
 瞭解 QVQ-Max 的思考過程,圖/豆包
瞭解 QVQ-Max 的思考過程,圖/豆包比如我就嘗試了讓豆包深入瞭解下 QVQ-Max 模型,它就進行了兩次搜索:第一次找到 16 篇參考資料,考慮到部分信息的缺失又進行了第二次搜索,找到 8 篇參考資料。
與 DeepSeek-R1、GPT 系列此前的工具調度能力相比,豆包此次升級雖並非開創性,但顯然補上了此前在複雜問題求解方面的短板。
3、DeepSeek-V3 小版本升級,每一點都強了點。
 圖/ DeepSeek
圖/ DeepSeekDeepSeek-V3 最新發佈的 0324 小版本升級,依舊延續了「小體積+大能力」的路線,主要借鑒了 DeepSeek-R1 在模型訓練中使用的強化學習技術,針對推理、寫作、編程能力做了進一步優化。
在前端開發能力上,新版模型能生成更具現代設計感的網頁結構,在代碼生成、轉換和編輯能力上也更為穩定;寫作方面則明顯提升了中文中長篇文本的邏輯性和通順度,更適合小說、劇本等內容創作。
4、Gemini 2.5 Pro:Google最強通用模型來了。
相比 DeepSeek-V3 ,Google 本週推出的 Gemini 2.5 Pro 是一次真正意義上的「大升級」,在編碼、數學、視覺推理、搜索調度等能力上都得到了全面增強。簡而言之,它正在將「大語言模型」推向「高可信度、多輪決策型智能體」的方向演進。
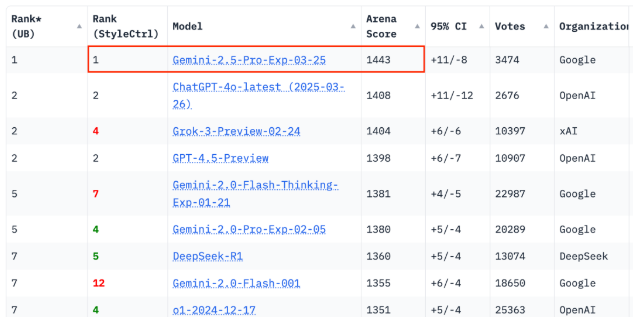
作為 Google 首個「全能型智能體底座」模型,Gemini 2.5 Pro 在對話能力上可以說是技壓群雄,在機制相對比較合理的大模型競技場 Chatbot Arena 上坐到了第一,並且大幅領先其他一眾頂級大模型,包括 Grok-3、GPT-4.5、DeepSeek-R1。
 圖/ Chatbot Arena
圖/ Chatbot Arena編碼方面也就是 Agentic Coding(智能體編碼)弱於 Claude-3.7-Sonnet,但在 SWE-Bench Verified 編程測試中遙遙領先,尤其擅長創建複雜 web 應用程序和代理工具鏈。圖像生成方面,Gemini 2.5 Pro 也有了巨大的進步,在 GPT-4o 升級圖像生成能力之前也驚豔了不少人。
5、GPT-4o 原生圖片生成,效果震撼全球網民。
單從熱度上,GPT-4o(0326)的更新無疑是這一輪集體升級中最大的贏家。本週,OpenAI 為 GPT-4o 推出新一輪的升級,不僅提高瞭解決複雜技術和編碼問題的能力,最出圈的可能還是原生的圖像生成功能。
上線之後,無數網民在嘗試新版本的圖像生成功能,尤其是讓 GPT-4o 用「吉卜力風格」重畫更是塞滿了我的社交媒體時間線。按照 OpenAI CEO 山姆・奧爾特曼(Sam Altman)的說法,GPT-4o 更新之後文生圖需求劇增,甚至造成了 GPU 超負荷。
 (ChatGPT 4o 根據照片生成,原始照片為嗶哩嗶哩在AWE2025的展台)
(ChatGPT 4o 根據照片生成,原始照片為嗶哩嗶哩在AWE2025的展台)相比之前,此次更新顯著提升了對複雜指令的理解能力和圖文混排渲染的可控性,尤其是在生成圖像中的文字內容上,準確率大幅提升。更重要的是,新版 GPT-4o 支持多輪對話過程中連續地修改圖像風格與構圖元素,可以逐步調優,視覺一致性也更強,用戶交互體驗也提升了一個維度。
智能體時代逼近,
大模型不約而同拚內功
如果說此前幾個月大模型的更新節奏還略顯零散,那麼這次幾乎同步到來的集體升級,已經清晰地釋放出一個信號:大模型正在全方位補齊能力,並為智能體的爆發做準備。
過去一年,大模型行業主旋律是「多模態」和「高性能」,但這一輪更新之後可以發現,大廠們開始集體聚焦於三個方向:更強的推理鏈條、更高質量的內容生成、更接近智能體形態的系統調度能力。
推理能力,毫無疑問是重中之重。QVQ-Max 通過強化視覺推理打開了多模態理解的深層能力,豆包則借助「邊想邊搜」補上複雜問題處理的弱項,而 DeepSeek 和 Gemini 更是通過 RLHF(強化學習)強化了多輪決策和長期規劃。
這些動作都指向一個目標:讓大模型不止於「答題機器」,而是能夠真正參與複雜任務和流程執行。
 圖/ Google
圖/ Google與此同時,內容生成的質量也普遍得到了提升。GPT-4o 升級圖像生成功能背後,實則是文本到圖像再到排版的全流程可控性提升;DeepSeek V3 新版也在強調從代碼到長文本,內容生成質量的提高。
無論是圖像生成、代碼生成還是小說生成,今天的模型更強調「結構正確、風格統一、過程透明」,簡言之就是大模型基礎能力的夯實。
而在推理和基礎能力之外,大模型還在快速補齊智能體所需的基礎能力,就比如工具調用。不管是豆包「動態搜索」的工具調用能力,還是 Gemini 在 SWE-Bench 中構建多步驟程序的能力,本質上都是在為「模型能自主執行任務」做準備。
從這輪更新看,大模型的「智能體化」正在成為下一場大競賽的起點,而基礎能力的全方位補齊,正在讓這場競賽變得越來越像是「拚內功」的長期戰役。
而且確信的是,ChatBot 不是大模型的終點,而是 AI 代理,或者說 AI 智能體才是大模型真正無處不在的入口。