業界突破多模態泛化推理能力,OPPO研究院&港科廣提出OThink-MR1技術
OThink-MR1團隊 投稿
量子位 | 公眾號 QbitAI
用上動態強化學習,多模態大模型也能實現泛化推理了?!
來自OPPO研究院和港科廣的科研人員提出了一項新技術——OThink-MR1,將強化學習擴展到多模態語言模型,幫助其更好地應對各種複雜任務和新場景。
研究人員表示,這一技術使業界突破多模態泛化推理能力。

眾所周知,多模態大模型可以處理多種類型輸入數據並生成相關輸出,但一遇到複雜推理任務,其能力往往表現不佳。
目前大多數多模態模型在訓練時,主要採用監督微調(SFT)的方法。
SFT就像是老師給學生劃重點,讓學生按照固定的模式學習。雖然這種方法在特定任務上確實能讓模型表現得不錯,但難以培養關鍵的通用推理能力。
與此同時,強化學習(RL)作為另一種訓練方法,開始進入人們的視野。
RL就像是讓學生在不斷嘗試中學習,做得好就給獎勵,做得不好就「挨批評」。這種方法理論上可以讓模型更靈活地應對各種任務,提升其推理能力,但卻存在多模態任務通用能力未充分探索、訓練約束易導致次優瓶頸等問題。
於是乎,OThink-MR1技術應運而生。
那麼,它是如何讓多模態模型突破泛化推理能力的呢?
基於動態強化學習
OThink-MR1是一個基於動態強化學習的框架和模型,支持微調多模態語言模型。
其核心「招式」有兩個:一個是動態KL散度策略(GRPO-D),另一個是精心設計的獎勵模型。二者相互配合,讓模型的學習效率和推理能力大幅提升。

先說動態KL散度策略。
在強化學習里,探索新的策略和利用已有經驗是兩個很重要的方面,但以前的方法很難平衡這二者的關係,不是在探索階段浪費太多時間,就是過早地依賴已有經驗。
而動態KL散度策略就像是給模型裝了一個「智能導航儀」,能根據訓練進度動態調整探索和利用的平衡。
打個比方,在訓練初期,它讓模型像個充滿好奇心的孩子,大膽地去探索各種可能的策略。而隨著訓練的進行,它又會引導模型逐漸利用之前積累的經驗,沿著更可靠的路線前進。
這樣一來,模型就能更有效地學習,避免陷入局部最優解。
再說獎勵模型。在OThink-MR1里,獎勵模型就像是老師給學生打分的標準。
對於多模態任務,科研人員設計了兩種獎勵:一種是驗證準確性獎勵,另一種是格式獎勵。
比如在視覺計數任務中,模型要數出圖片里物體的數量,如果數對了,就能得到驗證準確性獎勵;同時,如果模型的回答格式符合要求,像按照規定的格式寫下答案,還能獲得格式獎勵。
這兩種獎勵加起來,就像老師從多個方面給學生打分,讓模型知道自己在哪些地方做得好,哪些地方還需要改進,從而更有針對性地學習。
實驗環節
為了驗證OThink-MR1的實力,科研人員進行了一系列實驗。
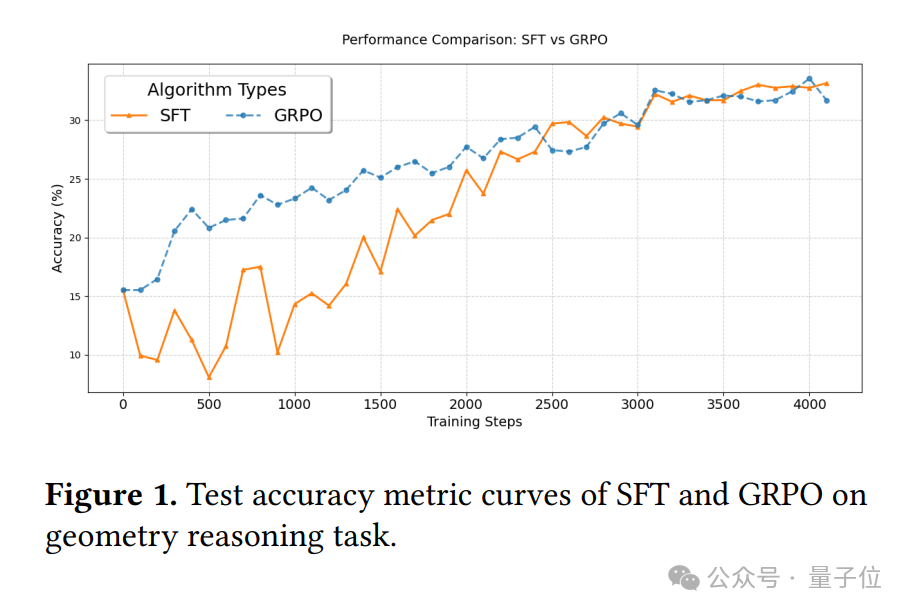
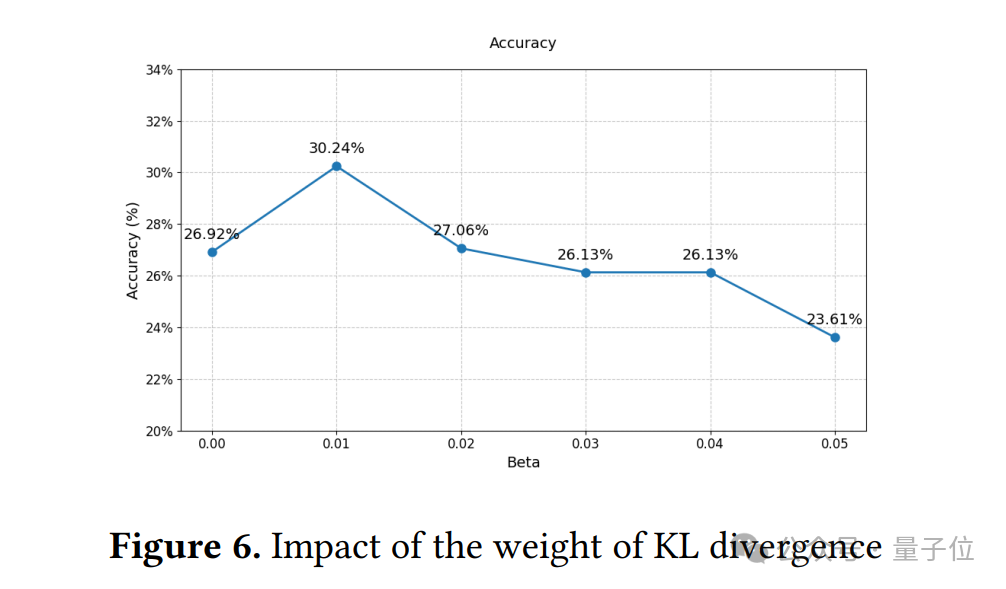
第一個實驗是探究獎勵項和KL散度項對原始GRPO(一種基於強化學習的方法)在同任務驗證中的影響。
在幾何推理任務中,科研人員調整格式獎勵的權重,發現當格式獎勵的權重不為零時,模型的表現明顯更好。這就好比學生寫作文,不僅內容要正確,格式規範也能加分,這樣能讓學生更全面地提升自己的能力。
同時,調整KL散度的權重時,他們發現權重適中時模型表現最佳,太大或太小都會讓模型成績下降。
第二個實驗是跨任務評估,這可是一場真正的「大考」。
以往的研究大多隻在同一個任務的不同數據分佈上評估模型的泛化能力,而這次實驗直接讓模型挑戰完全不同類型的任務。
科研人員選擇了視覺計數任務和幾何推理任務,這兩個任務難度不同,對模型的能力要求也不一樣。
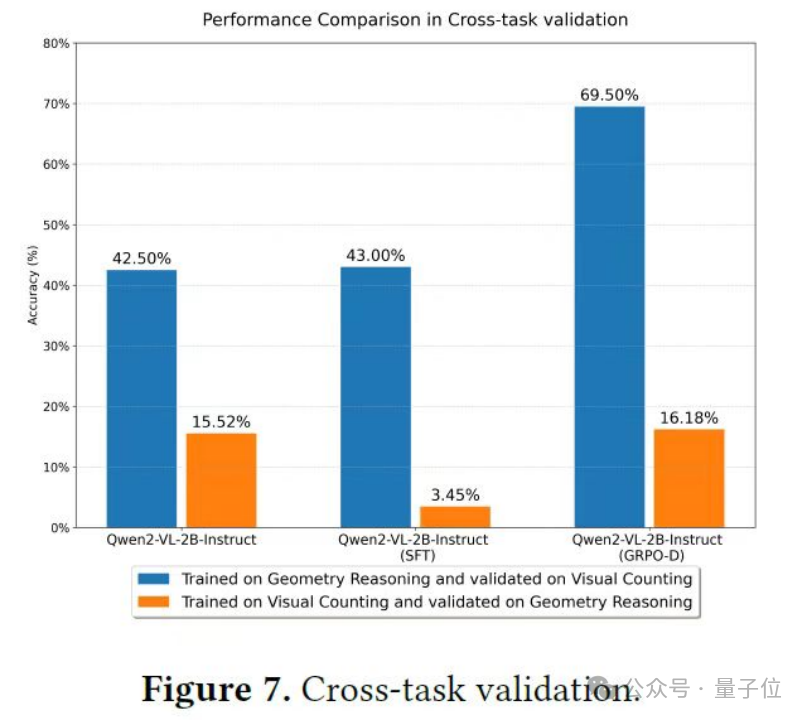
在跨任務驗證中,用監督微調訓練的模型表現得很差。就像一個只會做一種題型的學生,換了另一種題型就完全不會了。
而經過GRPO-D訓練的模型則表現出色,在從推理任務到理解任務的泛化實驗中,它的成績相比沒有經過訓練的模型提高了很多;在從理解任務到推理任務的泛化實驗中,雖然難度更大,但它也取得了不錯的進步。
這就好比一個學生不僅擅長數學,還能快速掌握語文知識,展現出了很強的學習能力。

第三個實驗是同任務評估。
實驗結果顯示,在同任務驗證中,採用固定KL散度的GRPO方法不如監督微調,但OThink-MR1中的GRPO-D卻能逆襲。
它在視覺計數和幾何推理任務上,成績都超過了監督微調,這就像一個原本成績一般的學生,找到了適合自己的學習方法後,成績突飛猛進,直接超過了那些只會死記硬背的同學。
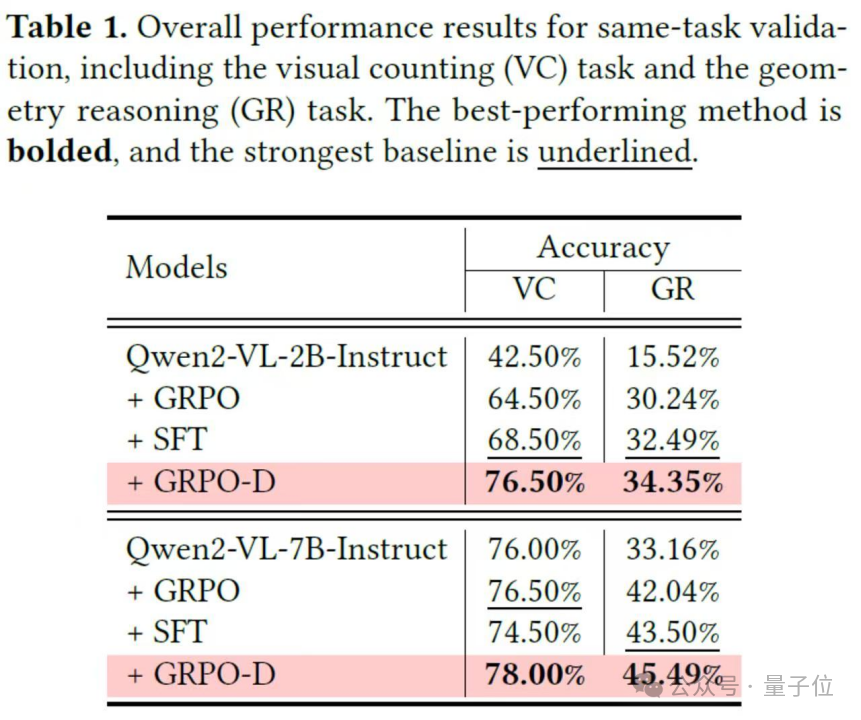
總體而言,OThink-MR1的出現,為多模態語言模型的發展開闢了新的道路。
它讓我們看到了動態強化學習在提升模型推理能力和泛化能力方面的巨大潛力。在未來,基於OThink-MR1這樣的技術,多模態語言模型有望在更多領域發揮重要作用。
論文地址:https://arxiv.org/abs/2503.16081
• 標題:OThink-MR1: Stimulating multimodal generalized reasoning capabilities through dynamic reinforcement learning
• 作者:劉誌遠1, 章玉婷2, 劉豐1, 張長旺1, 孫瑩2, 王俊1