GPT-4o 圖像生成的秘密,OpenAI 沒說,網民已經拚出真相?
轉自 | 機器之心
自從 OpenAI 發佈 GPT-4o 圖像生成功能以來,短短幾天時間,我們眼睛里看的,耳朵裡聽的,幾乎都是關於它的消息。
不會 PS 也能化身繪圖專家,隨便打開一個社交媒體,一眼望去都是 GPT-4o 生成的案例。
比如,吉卜力畫風的特朗普「積極坦誠對話」澤連斯基:

然而,OpenAI 一向並不 Open,這次也不例外。他們只是發佈一份 GPT-4o 系統卡附錄(增補文件),其中也主要是論述了評估、安全和治理方面的內容。

地址:https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
對於技術,在這份長達 13 頁的附錄文件中,也僅在最開始時提到了一句:「不同於基於擴散模型的 DALL・E,4o 圖像生成是一個嵌入在 ChatGPT 中的自回歸模型。」
OpenAI 對技術保密,也抵擋不住大家對 GPT-4o 工作方式的熱情,現在網絡上已經出現了各種猜測、逆向工程。
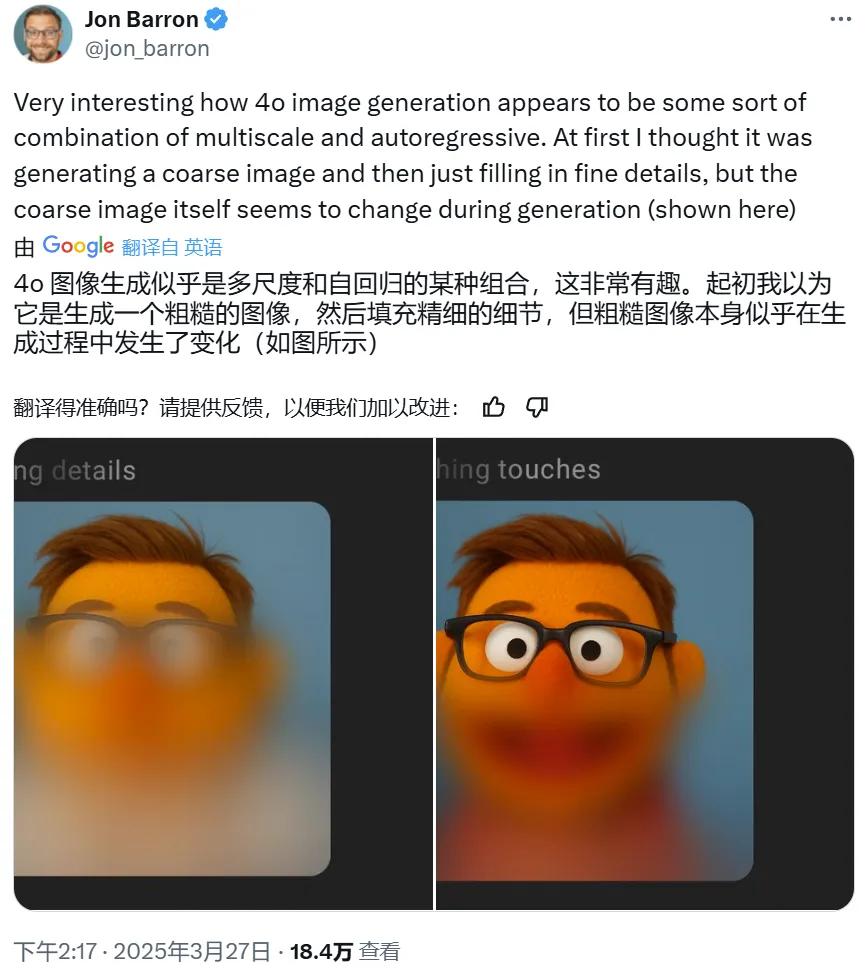
比如Google DeepMind 研究者 Jon Barron 根據 4o 出圖的過程猜測其可能是組合使用了某種多尺度技術與自回歸。
不過,值得一提的是,香港中文大學博士生劉傑(Jie Liu)在研究 GPT-4o 的前端時發現,用戶在生成圖像時看到的逐行生成圖像的效果其實只是瀏覽器上的前端動畫效果,並不能準確真實地反映其圖像生成的具體過程。實際上,在每次生成過程中,OpenAI 的服務器只會向用戶端發送 5 張中間圖像。您甚至可以在控制台手動調整模糊函數的高度來改變生成圖像的模糊範圍!

因此,在推斷 GPT-4o 的工作原理時,其生成時的前端展示效果可能並不是一個好依據。
儘管如此,還是讓我們來看看各路研究者都做出了怎樣的猜測。整體來說,對 GPT-4o 原生圖像生成能力的推斷主要集中在兩個方向:自回歸 + 擴散生成、非擴散的自回歸生成。下面我們詳細盤點一下相關猜想,並會簡單介紹網民們猜想關聯的一些相關論文。
猜想一:自回歸 + 擴散
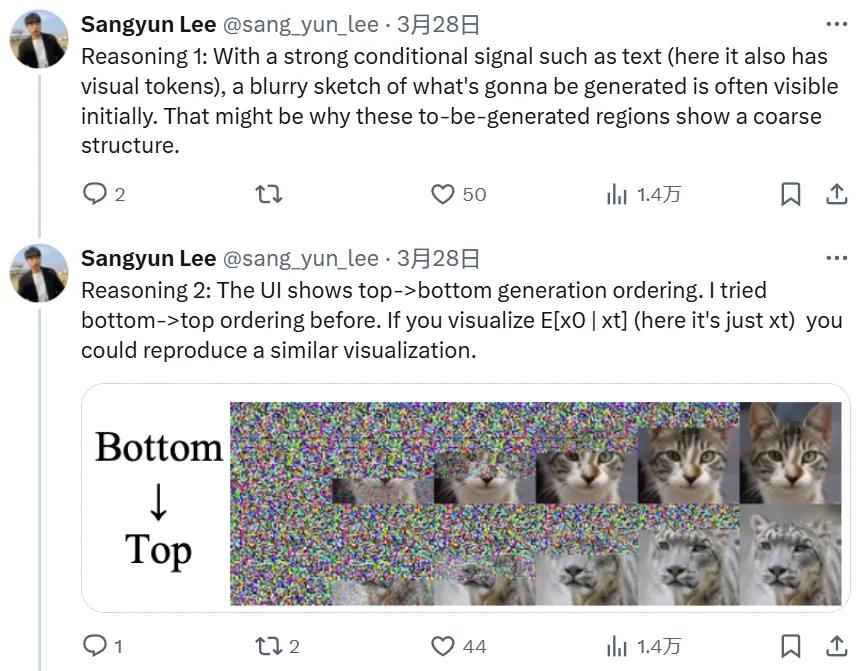
很多網民猜想 GPT-4o 的圖像生成採用了「自回歸 + 擴散」的範式。比如 CMU 博士生 Sangyun Lee 在該功能發佈後不久就發推猜想 GPT-4o 會先生成視覺 token,再由擴散模型將其解碼到像素空間。而且他認為,GPT-4o 使用的擴散方法是類似於 Rolling Diffusion 的分組擴散解碼器,會以從上到下的順序進行解碼。

他進一步給出了自己得出如此猜想的依據。
-
理由 1:如果有一個強大的條件信號(如文本,也可能有視覺 token),用戶通常會先看到將要生成的內容的模糊草圖。因此,那些待生成區域會顯示粗糙的結構。
-
理由 2:其 UI 表明,圖像是從頂部到底部生成的。Sangyun Lee 曾在自己的研究中嘗試過底部到頂部的順序。
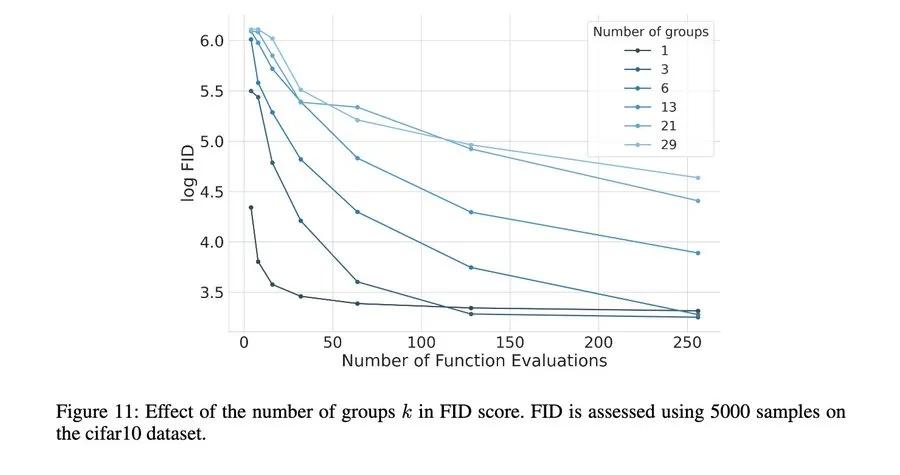
Sangyun Lee 猜想到,這樣的分組模式下,高 NFE(函數評估數量)區域的 FID 會更好一些。但在他研究發現這一點時,他只是認為這是個 bug,而非特性。但現在情況不一樣了,人們都在研究測試時計算。
最後,他得出結論說:「因此,這是一種介於擴散和自回歸模型之間的模型。事實上,通過設置 num_groups=num_pixels,你甚至可以恢復自回歸!」
另外也有其他一些研究者給出了類似的判斷:

如果你對這一猜想感興趣,可以參看以下論文:
-
Rolling Diffusion Models,arXiv:2402.09470;
-
Sequential Data Generation with Groupwise Diffusion Process, arXiv:2310.01400
-
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model,arXiv:2408.11039
猜想二:非擴散的自回歸生成
使用過 GPT-4o 的都知道,其在生成圖像的過程中總是先出現上半部分,然後才生成完整的圖像。
Moonpig 公司 AI 主管 Peter Gostev 認為,GPT-4o 是採用從圖像的頂部流 token 開始生成圖像的,就像文本生成方式一樣。
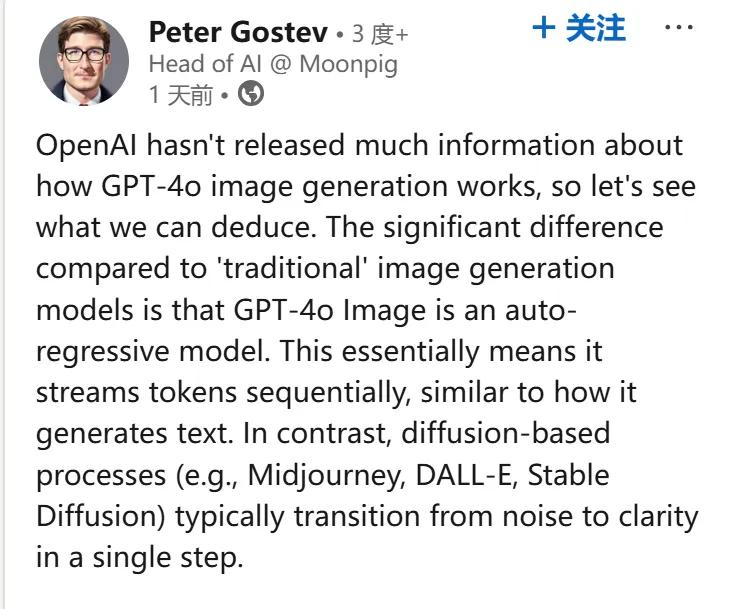
來源:https://www.linkedin.com/feed/update/urn:li:activity:7311176227078172674/
Gostev 表示,與傳統的圖像生成模型相比,GPT-4o 圖像生成的關鍵區別在於它是一個自回歸模型。這意味著它會像生成文本一樣,按順序逐個流式傳輸圖像 token。相比之下,基於擴散過程的模型(例如 Midjourney、DALL-E、Stable Diffusion)通常是從噪聲到清晰圖像一次性完成轉換。

這種自回歸模型的主要優勢在於,模型不需要一次性生成整個全局圖像。相反,它可以通過以下方式來生成圖像:
-
利用其模型權重中嵌入的通用知識;
-
通過按順序流式傳輸 token 來更連貫地生成圖像。
更進一步的,Gostev 認為,如果你使用 ChatGPT 並點擊檢查(Inspect),然後在瀏覽器中導航到網絡(Network)標籤,就可以監控瀏覽器與服務器之間的流量。這讓你能夠查看 ChatGPT 在圖像生成過程中發送的中間圖像,從而獲得一些有價值的線索。
Gostev 給出了一些初步的觀察結果(可能並不完整):
-
圖像是從上到下生成的;
-
這個過程確實涉及流 token,與擴散方法截然不同;
-
從一開始,就可以看到圖像的大致輪廓;
-
先前生成的像素在生成過程中可能會發生顯著變化;
-
這可能表明模型採用了某種連貫性優化,尤其是在接近完成階段時更加明顯。
最後,Gostev 表示還有一些無法直接從圖像中看到的額外觀察結果:
-
對於簡單的圖像生成,GPT-4o 速度要快得多,通常只有一個中間圖像,而不是多個。這可能暗示使用了推測解碼或其他類似方法;
-
圖像生成還具備背景移除功能,從目前的情況來說,最初 GPT-4o 生成圖片會呈現一個假的棋盤格背景,直到最後才移除實際背景,這會略微降低圖像質量。這似乎是一個額外的處理過程,而不是 GPT-4o 本身的功能。
開發者 @KeyTryer 也給出了自己的猜想。他說 4o 是一種自回歸模型,通過多次通過來逐像素地生成圖像,而不是像擴散模型那樣執行去噪步驟。
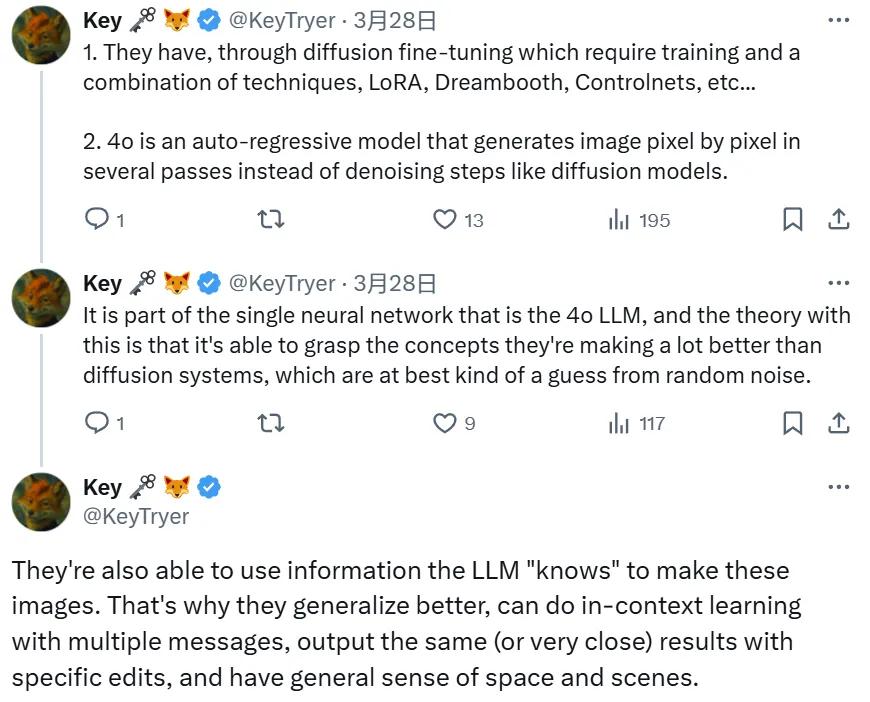
而這種能力本身就是 GPT-4o LLM 神經網絡的一部分。理論上講,它能夠比擴散系統更好地掌握它們正在操作的概念,而擴散系統只是對隨機噪聲的一種猜測。
GPT-4o 還能夠使用 LLM「知道」的信息來生成圖像。也因此,它們具有更好的泛化能力,能夠使用多條消息進行上下文學習,通過特定的編輯輸出相同(或非常接近)的結果,並且具有廣義的空間和場景感。
芬蘭赫爾辛基的大學副教授 Luigi Acerbi 也指出,GPT-4o 基本就只是使用 Transformer 來預測下一個 token,並且其原生圖像生成能力一開始就有,只是一直以來都沒有公開發佈。
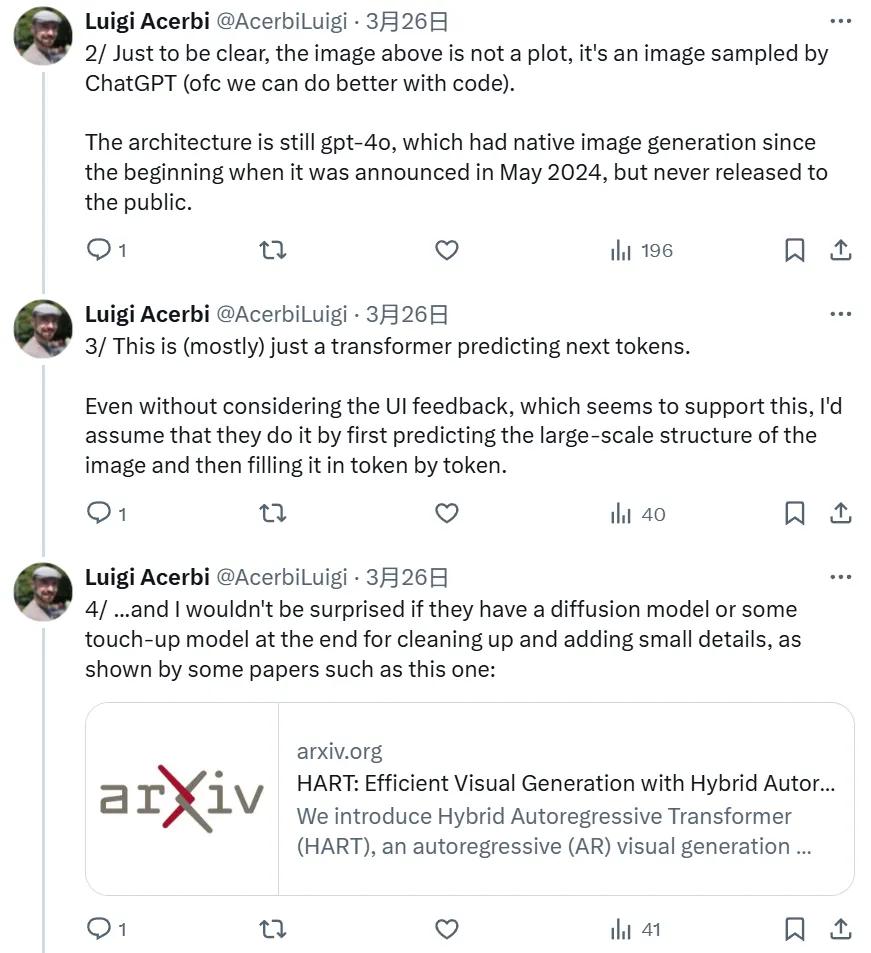
不過,Acerbi 教授也提到,OpenAI 可能使用了擴散模型或或一些修飾模型來為 GPT-4o 生成的圖像執行一些清理或添加小細節。
GPT-4o 原生圖像生成功能究竟是如何實現的?這一點終究還得等待 OpenAI 自己來揭秘。對此,你有什麼自己的猜想呢?
參考鏈接
https://x.com/karminski3/status/1905765848423211237
https://x.com/iScienceLuvr/status/1905730169631080564
https://x.com/AcerbiLuigi/status/1904793122015522922
https://x.com/Hesamation/status/1905762746056278278
https://x.com/jie_liu1/status/1905761704195346680