我讓最強 AI 推理模型陪我打《王者榮耀》,我這個青銅直接起飛
靠著吉卜力,OpenAI 又大出了一把風頭。但實際在過去的一週里,有不少模型發佈了版本更新,包括 DeepSeek,Gemini,Qwen。個個都是在推理上有所增強,以及多模態的支持。
每次有新的推理模型升級或者出現,怎麼領略它們的能力很棘手。說白了,老讓它們做題也沒什麼意思。
週末打遊戲的時候,我忽然意識到:遊戲不就是最好的試驗場景嗎?
版本齊齊更新,推理能力再上一層
Qwen 在週五的淩晨發佈了全新自家視覺推理模型的全新版本 QvQ-Max。不僅能夠「看懂」圖片和影片里的內容,還能結合這些信息進行分析、推理,甚至給出解決方案。
Gemini 這邊,則是三月 25 日推出的 2.5 Pro Experimental,推理、寫代碼以及多模態理解都有全面提高。在數學和科學基準測試(如 GPQA 和 AIME 2025)中排名超越 OpenAI 的 03 mini。
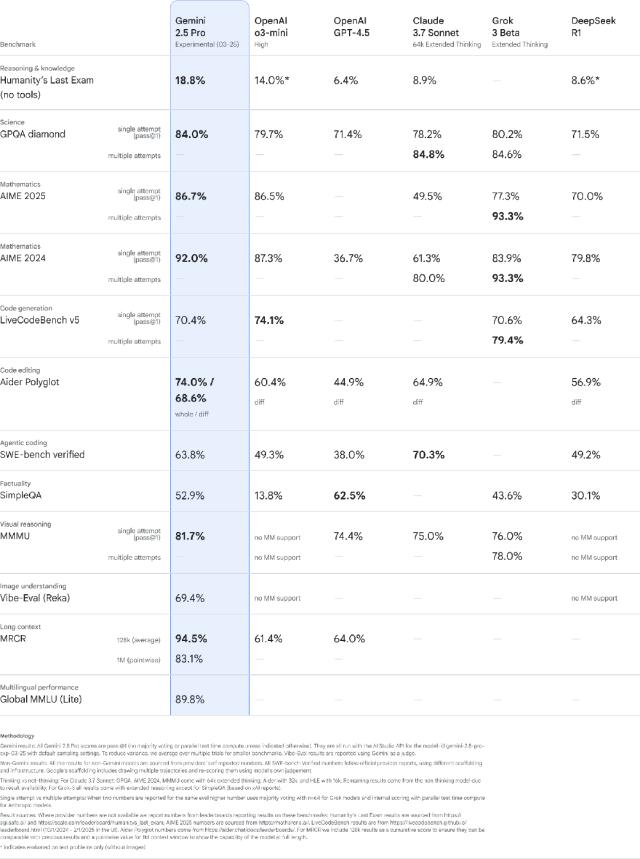
帶有 100 萬個標記上下文窗口,能夠理解龐大的數據集並處理來自不同信息源的複雜問題,包括文本、音頻、圖像、影片甚至整個代碼存儲庫。
再說一遍:推理能力對於模型而言,不只是解解數學題而已。更重要的是,讓推理作為底層能力,惠及模型在所有形態的任務上的處理,包括跨模態的理解。
這也是為什麼各家都很重視推理能力,理論上它是 AGI 真正的基石。
怎麼,打遊戲很難嗎?
遊戲是一個「既不複雜又挺複雜」的考核場景。不複雜的原因很簡單:現階段模型動不了手,所有的操控還得是玩家自己來。
「挺複雜」又在於,它是多模態素材,文字、圖像、視覺效果應有盡有。

一種潛在的使用場景是,讓模型 能通過讀取遊戲記錄,根據相對應的關卡,製定作戰計劃。這意味著不僅要搞懂所有的素材,還要有分析和計算的能力。
一下子讓模型出攻略,步子邁得有點太大了。還是先從看懂遊戲錄屏,並且整理數字開始吧,不算太難。
我給 Gemini 和 Qwen 都上傳了相同的遊戲錄屏,然後讓它們整理所有出現的傷害數值。
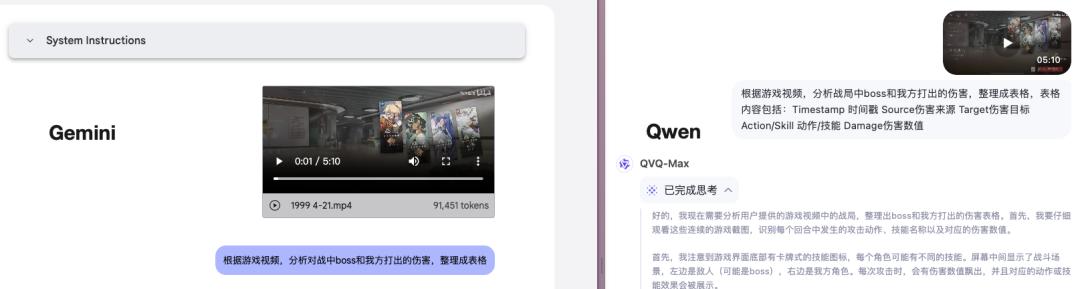
這裏出現了一些不同:Gemini 對模糊指令的理解更好一點,我只需要寫到「整理成表格」就好,但 Qwen 需要更明確一點,否則它最終出具的表格,什麼樣式的都有。
遊戲樣本選擇了來自 b 站 up 主@司馬玄清在《重返未來:1999》的一段錄屏。 主要原因是, 這是一款卡牌遊戲,形式簡單。 且在這個影片里背景清晰,數值能夠完全展示出來,同時對用到的技能也有文字展示。

上傳開始,Qwen 不花多少時間就成功接收,並開始處理。Gemini 的上傳很是花了一些時間,整體上在兩三分鐘左右,傳上去之後還要花個半分鐘左右分析。
兩邊都提供了思維鏈,Qwen 給的是中文,Gemini 的思維鏈預設是英文,而且長非常非常多。
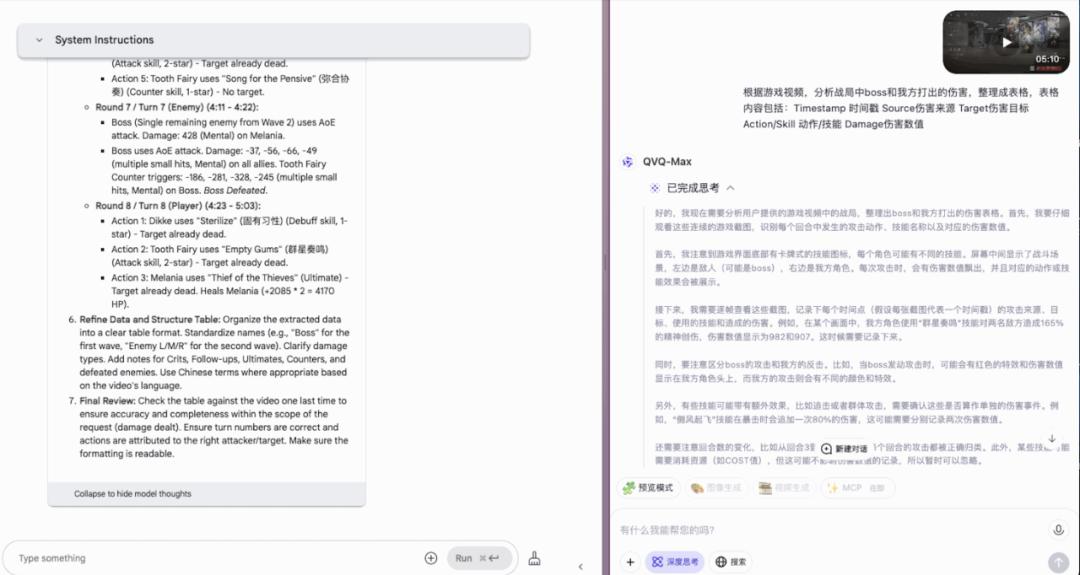
思維鏈的不同也反映在了最後給出的表格上,從第一眼看兩邊的數值就不一樣了。
核查了一下發現,Qwen 是每五秒統計一次,收錄讀秒時的畫面顯示的內容,老實說這個思路準確度是會有點問題。
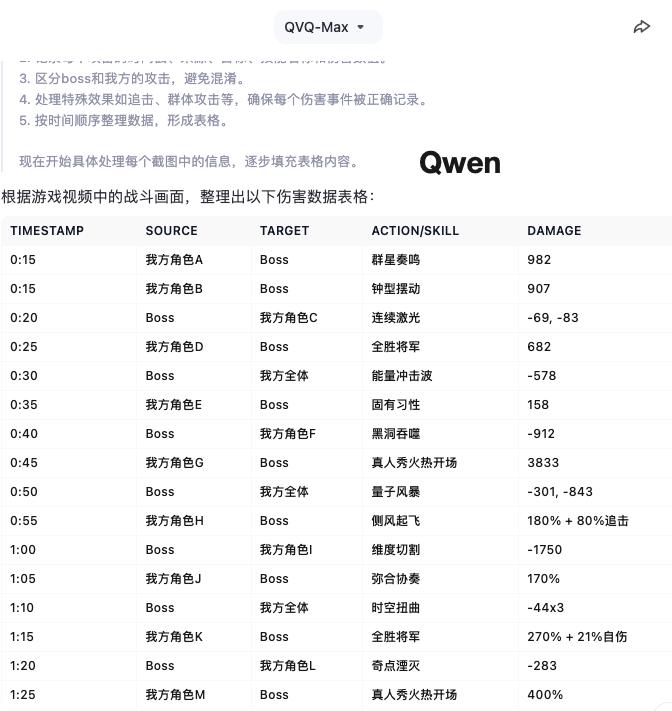
Gemini 給出了很長的表格,雖然沒有明確的時間戳,但是對傷害數值的統計準確率高出了不少,粗略地看,基本沒有瞎編的數字。
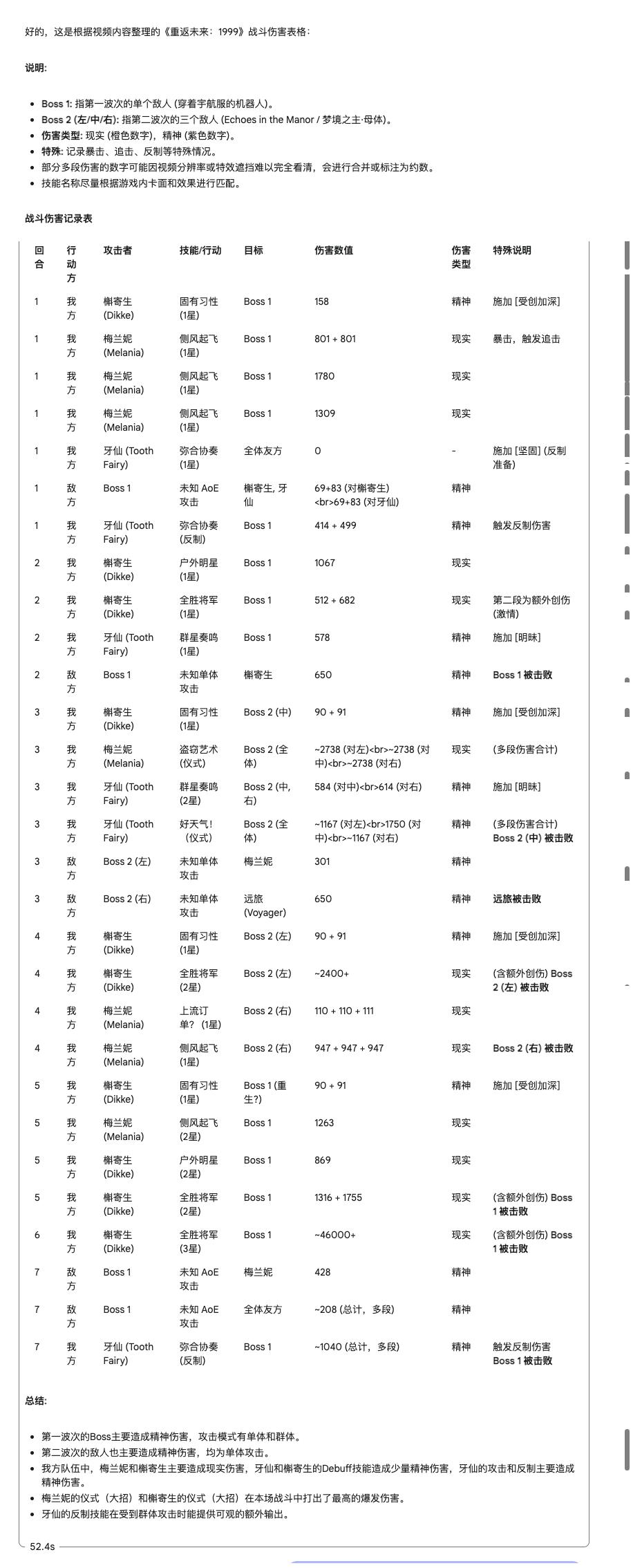
仔細核查一下,Gemini 的抓取數值的準確度確實是超出預期的,首先它能連續「觀看」影片內容並進行分析。
同時還能兼顧多個行動主體,比如我方受到攻擊時還能區分是哪個角色被攻擊、傷害多少。隨機抽查幾個數字,正確率挺高。

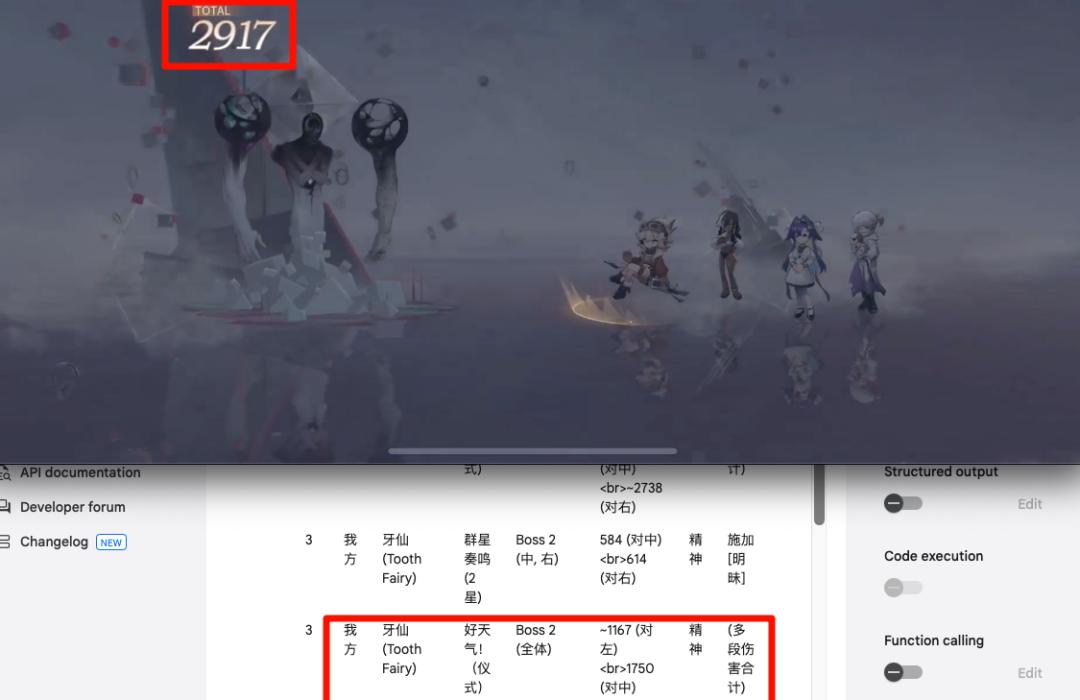
當然也不是百分百準確:比如對連擊的抓取不行,玩家打出一連串攻擊時,只能抓到第一次的記錄。
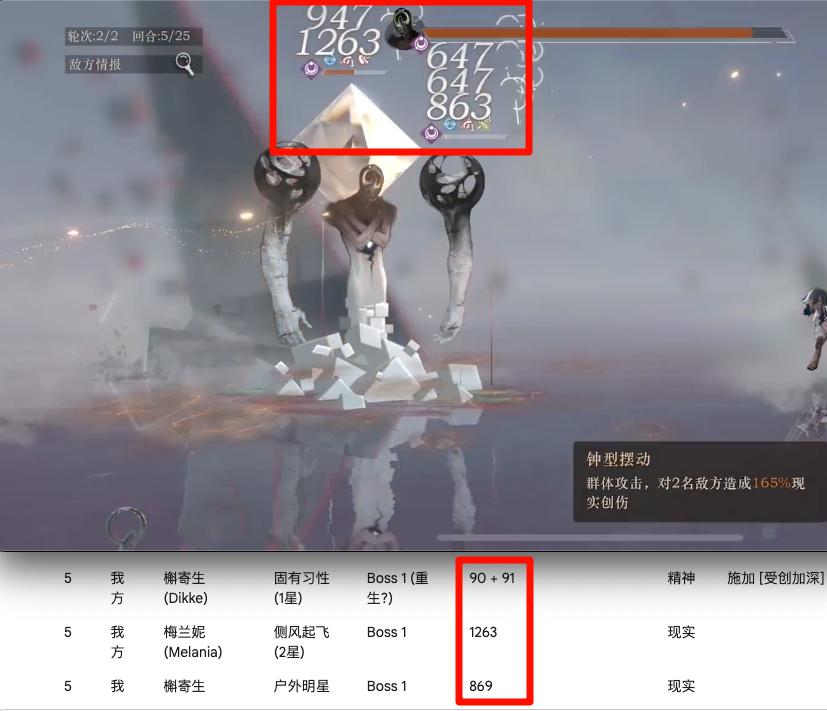
在試圖合計多段攻擊的總值時,也不準——總結得很好,下次不要總結了。
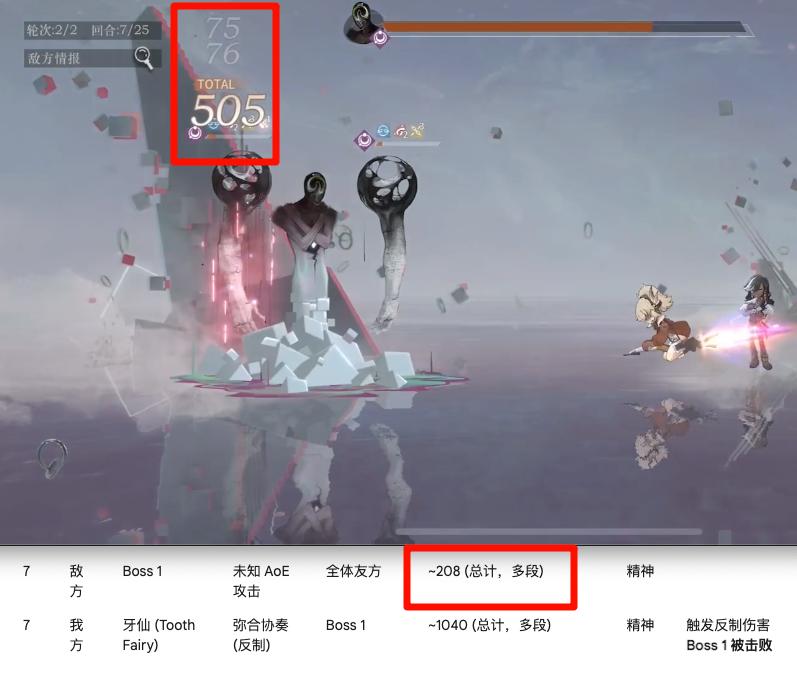
整體來看,Gemini 的準確度能有 65 分,Qwen 大概是 55 分。後面還讓它們分別總結了所涉及到的特殊技能:

兩邊總結起來的思路不一樣,Qwen 是按照技能類型劃分,主要參考了卡面的文字展示。

Gemini 則是以影片為主,計算作戰中的出現方式來統計,結合了角色。

不得不說,影片材料消耗 token 跟玩似的,五分鐘的影片光是傳上去就已經 9 萬 token 了。幸好 Gemini 還算大方,每個會話的起始量都是一百萬,經得起花。
前置工作鋪墊好了,理論上對遊戲應該有所瞭解,那麼「如果我想用更短的時間就勝利,出擊方式和技能卡牌使用應該怎麼調整?」
技能和角色的名稱由於翻譯的原因比較混亂,暫且拋開不談,兩邊都給出了像模像樣的「攻略」,尤其是 Qwen。

Gemini 也可以出攻略,相對沒有那麼詳細。

綜合能力可能,強操控遊戲仍是挑戰
有一說一,卡牌遊戲總歸是比較簡單的,不管是對於玩家還是對於 AI。就這準確度就已經堪憂了,涉及操控的話,還能跑得動嗎?
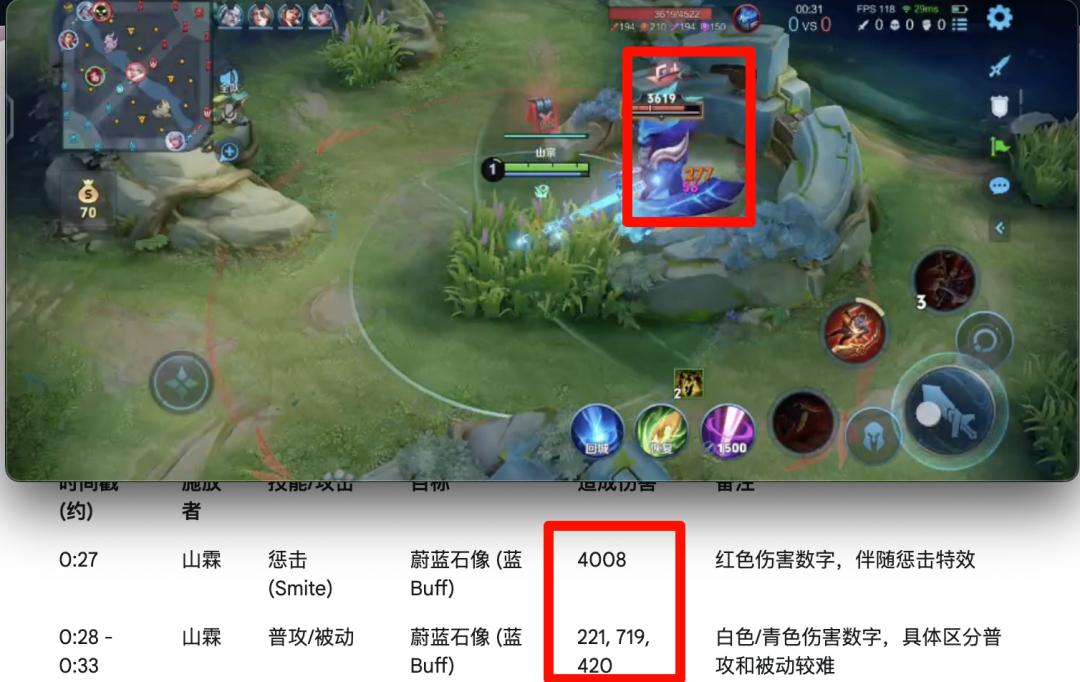
於是下面我找來了一段王者榮耀的影片,看看這回兩個模型的表現。
這次兩個模型都開始摸不著頭腦了。Qwen 給出了一個整理,但光看著就 bug 滿滿,而且沒有了時間戳甚至很難核對。

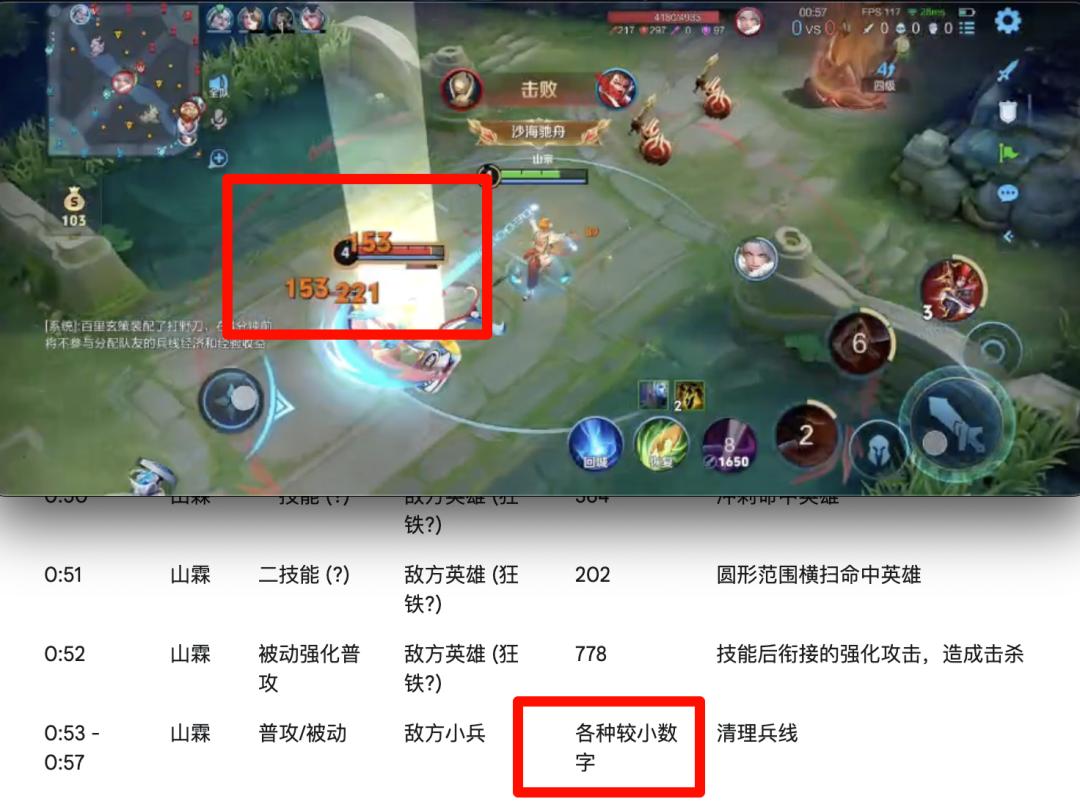
Gemini 還是按照之前的方式,給出了詳細的表格。但是按照時間戳一對比,數字也是很亂,它在備註里也寫到自己對一些傷害難以區分。
甚至當很多數字接連冒出來的時候,乾脆就直接摸魚,寫了一個「較小數字」就矇混過關了。
如果不能準確提取現有的數據,後面的推理分析就很不樂觀了。但我還是淺問了一下「按照現有的戰況,分析本局的勝率和敗率」。
Qwen 比較中規中矩,可以綜合讀取影片里所有相關的信息,比如等級、金幣數等等。
意外的是 Gemini,它不僅讀取了影片里的信息,還讀了音頻:這段錄像是同事現打的一段人機,錄製時環境嘈雜,竟然能被 Gemini 識別出來。它認為人機對戰中,只要不出錯,就是穩贏。
有點東西。
王者的難度屬實有點大,這個表現也不算意外。但整體上,兩個模型的表現都比想像中的好很多。
儘管兩邊的主打不一樣,Gemini 強調推理,Qwen 強調視覺,但都反映出了一開始所說的:以推理能力為基石,全面惠及不同維度的能力。
這也能在 Qwen QvQ-Max 的發佈報告中看到,團隊談到了為什麼要投入視覺在推理中:傳統的 AI 模型大多依賴文字輸入,比如回答問題、寫文章或者生成代碼。但現實生活中,很多信息並不是用文字表達的。
圖片、圖表甚至影片等多種形式,都包含著信息。一張圖片可能包含豐富的細節,比如顏色、形狀、位置關係等,而這些信息往往比文字更直觀、也更複雜。
而僅僅只是「看到」這些信息,還遠遠不夠。只有調動推理能力,「看懂」所有的信息,還能做出進一步分析,一切才有更豐富的應用層面的意義。
Gemini 和 Qwen 的表現為「模型即產品」又多添了一枚籌碼,當推理能力再上一個台階的時候,泛用性進一步提高,「通用型智能」初具形態,只是時間問題。
本文來自微信公眾號「APPSO」,作者:APPSO,36氪經授權發佈。