ICLR 2025 | 真正「Deep」的「Research」,通過強化學習實現可自主進化的科研智能體來了!

CycleResearcher 研究團隊成員包括:張嶽教授,西湖大學人工智能系教授,工學院副院長,其指導的博士生朱敏郡、張鴻博、鮑光勝、訪問學生翁詣軒;UCL 訪問研究員楊林易博士,25 Fall 入職南方科技大學擬任獨立 PI,博士生導師,研究員。
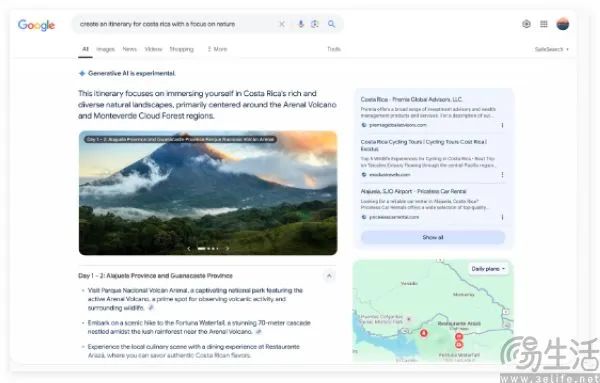
AI 技術不斷進步,科研自動化浪潮正在深刻改變學術世界!近日,來自西湖大學、UCL 等機構的研究團隊在自動化科研方向發佈了一項突破性的成果:CycleResearcher 。 CycleResearcher 首次實現了可訓練的科研流程的全鏈路端到端訓練,覆蓋智能文獻檢索、模型主動提問、強化學習迭代優化論文創新點、方法論架構設計、實驗設計到論文自動生成的完整閉環。
值得一提的是,同類功能在 OpenAI 商業化方案中需支付高達 2 萬美元 / 月的服務費用,而團隊開源了所有代碼、數據、和 Demo:

-
論文鏈接:https://openreview.net/forum?id=bjcsVLoHYs
-
網頁鏈接:https://ai-researcher.net/
-
代碼鏈接:https://github.com/zhu-minjun/Researcher
牛津大學教授 Will MacAskill 最新預言未來 AI 的增長率足以在不到 10 年的時間里,推動相當於 100 年的技術進步。如何讓 AI 實現「遞歸自我改進」成為瞭解決這個問題的關鍵!然而,現有的一系列工作包括 SakanaAI 公司於去年 8 月發佈的 AI Scientist、香港大學最近發佈的 AI-Researcher 都是基於調用 API 構建推理的框架去實現自動化科研,而無法被訓練優化。CycleResearcher(模型上傳於 24 年 8 月)是全球首個通過強化學習迭代優化訓練實現的 AI 科研智能體。
 圖 1: AI Researcher 功能展示圖
圖 1: AI Researcher 功能展示圖CycleResearcher 首次實現了通過強化學習進行科研過程的自動迭代改進,它能夠模擬完整的科研流程,包括文獻綜述、研究構思、論文撰寫,以及模擬實驗結果。
研究團隊主要乾了三件事情:
1)數據集: 發佈了兩個大規模數據集 Review-5k 和 Research-14k,用於評估和訓練學術論文評審和生成模型。
2)CycleResearcher 模型: 可以生成質量接近人類撰寫預印本的論文(評分 5.36 分),實現 31.07% 的接受率。
3)CycleReviewer 模型: 一個做論文評審的模型,在平均絕對誤差 (MAE) 方面顯示出令人鼓舞的結果,與人類評審員相比,平均絕對誤差(MAE)降低了 26.89%。
利用商業大型語言模型(LLMs)作為研究助理或想法生成器已經取得了顯著進展,但在多達上萬次模擬同行評議中通過反饋而自我進化的自動科研大模型從未實現過。這項研究的提出旨在解決了這個領域難題。
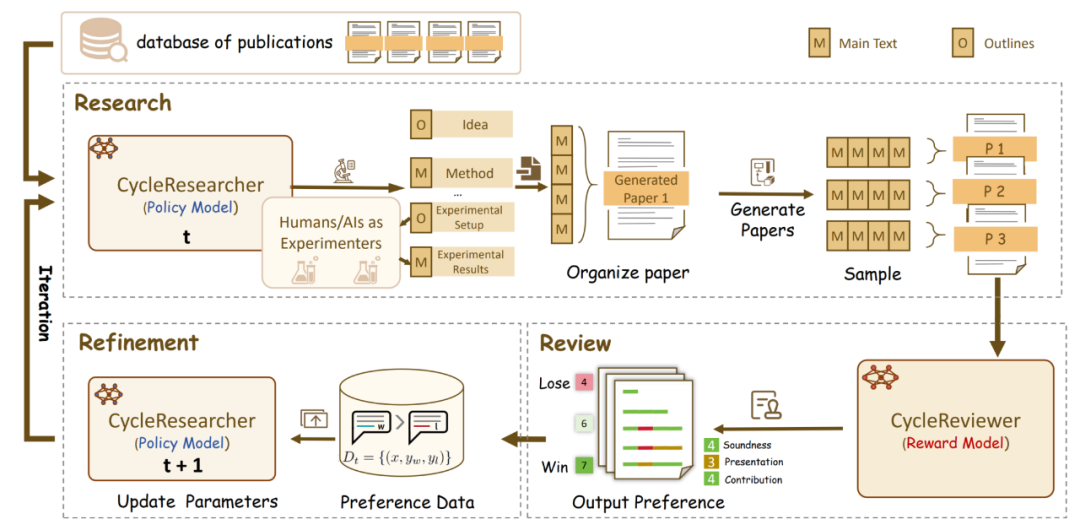 圖 2: CycleResearcher 訓練框架圖
圖 2: CycleResearcher 訓練框架圖創新點詳細解讀:
1. 高質量數據集與模型規模化:為訓練 CycleResearcher,研究團隊專門構建了包含近 1.5 萬篇高質量學術論文的數據集(Research-14K),數據來源覆蓋了 ICLR、NeurIPS、ICML、ACL、EMNLP、CVPR 和 ICCV 等頂級會議。提供了多個不同規模的模型(12B、72B、123B),滿足不同科研需求。
2. 強化學習與迭代反饋機制:如圖二所示,CycleResearcher 的核心技術,在於其採用迭代式偏好優化(Iterative SimPO)的訓練框架,這一方法使得在線強化學習(Online RLHF)成為了可能。這個框架包含兩個關鍵模型:策略模型 (CycleResearcger) 和獎勵模型 (DeepReveiwer)。
3. 指令微調(SFT)熱身階段:策略模型 CycleResearcher 負責生成論文的各個部分,它首先會進行廣泛的文獻綜述,從輸入的 bib 文件中獲取所有參考文獻及其摘要,全面瞭解研究背景。然後,它會交替生成論文的大綱和正文,確保邏輯流暢。具體來說,它會先生成動機和大綱中的主要思想,然後生成標題、摘要、引言和方法部分。接下來,概述實驗設置和結果,隨後生成實驗設計和模擬結果(注意,這裏的實驗結果是模擬的)。最後,它會分析實驗結果並形成結論。整個過程就像一位經驗豐富的科研人員在撰寫論文一樣,有條不紊,邏輯清晰。獎勵模型 CycleReviewer 則負責模擬同行評議,對生成的論文進行評估和反饋。它會從多個維度對論文進行打分,並給出具體的評審意見。
4. 迭代反饋訓練階段:研究人員首先通過拒絕采樣獲取樣本,通過 CycleReviewer 的打分構成偏好對,兩個模型相互配合,通過強化學習的方式不斷優化,CycleResearcher 根據 CycleReviewer 的反饋不斷改進自身的論文生成策略,CycleReviewer 則根據 CycleResearcher 生成的論文不斷提高自身的評審能力。兩個模型交互反饋,不斷優化策略。在 Iterative SimPO 算法中,SimPO 算法雖然可以幫助 AI 區分 「好」 論文和 「壞」 論文,但它不能保證 AI 生成的文本是流暢的。因此,我們將 SimPO 損失和 NLL 損失結合起來,讓 AI 模型既能寫出高質量的論文,又能保證文本的流暢性。
5. 實驗結果:CycleResearcher 生成論文的模擬評審平均得分達到 5.36 分,超過目前 AI Scientist 的 4.31 分,且十分接近人類真實預印本的平均水平(5.24 分)。同時,CycleResearcher 論文的接受率達到了 35.13%,遠高於 AI Scientist 的 0%。
總結
1: 這篇工作首次提出了一個用於自動化整個研究生命週期的迭代強化學習框架 通過集成 CycleResearcher(策略模型)和 CycleReviewer(獎勵模型),該框架能夠模擬真實世界的研究 – 評論 – 改進的迭代循環。
2: 團隊發佈了兩個大規模數據集,用於學術論文生成和評論的評估與訓練 Review-5k 和 Research-14k 數據集專為捕捉機器學習中同行評審和研究論文生成的複雜性而設計,為評估和訓練學術論文生成和評審模型提供了寶貴的資源。
3: CycleResearcher 在研究構思和實驗設計方面表現出一致的性能,可以達到人類撰寫預印本的論文質量,接近會議接受論文的質量。 這表明 LLM 可以在科學研究和同行評審過程中做出有意義的貢獻。
我們堅信科研工具應當開放共享,因此提供了完整的開源資源套件:
pip install ai_researcher開源套件包含:
1. 不同規模模型:所有模型均支持本地部署
-
CycleResearcher:提供 12B、72B 和 123B 三種規模
-
CycleReviewer:提供 8B、70B 和 123B 三種規模
-
DeepReviewer:提供 7B 和 14B 兩種規模
2. 大規模訓練數據集:
-
Review-5K:包含 4,989 篇論文的專業評審數據
-
Research-14K:包含 14,911 篇高質量論文的結構化數據
-
DeepReview-13K:包含 13,378 篇論文的多維度深度評審數據
3. 詳儘教程:
-
CycleResearcher 教程:https://github.com/zhu-minjun/Researcher/blob/main/Tutorial/tutorial_1.ipynb
-
CycleReviewer 教程:https://github.com/zhu-minjun/Researcher/blob/main/Tutorial/tutorial_2.ipynb
-
DeepReviewer 教程:https://github.com/zhu-minjun/Researcher/blob/main/Tutorial/tutorial_3.ipynb