200美金,人人可手搓QwQ,清華、螞蟻開源極速RL框架AReaL-boba

由於 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)帶來了新的 post-training scaling law,強化學習(RL,Reinforcement Learning)成為了大語言模型能力提升的新引擎。然而,針對大語言模型的大規模強化學習訓練門檻一直很高:
-
流程複雜、涉及模塊多(生成、訓練、獎勵判定等),為實現高效穩定的分佈式訓練帶來很多挑戰;
-
R1/o1 類推理模型的輸出長度很長(超過 10K),並且隨著訓練持續變化,很容易造成顯存和效率瓶頸;
-
開源社區缺乏高質量強化學習訓練數據,以及完整可複現的訓練流程。
本週,螞蟻技術研究院和清華大學交叉信息院吳翼團隊,聯合發佈了訓練速度最快最穩定的開源強化學習訓練框架 AReaL(Ant Reasoning RL),並公開全部數據和完成可複現的訓練腳本。在最新的 AReaL v0.2 版本 AReaL-boba 中,其 7B 模型數學推理分數刷新同尺寸模型 AIME 分數紀錄,並且僅僅使用 200 條數據複刻 QwQ-32B,以不到 200 美金成本實現最強推理訓練效果。
-
項目鏈接:https://github.com/inclusionAI/AReaL
-
HuggingFace數據模型地址:https://huggingface.co/collections/inclusionAI/areal-boba-67e9f3fa5aeb74b76dcf5f0a
關於 AReaL-boba
AReaL 源自開源項目 ReaLHF,旨在讓每個人都能用強化學習輕鬆訓練自己的推理模型和智能體。AReaL 承諾完全開放與可複現,團隊將持續發佈與訓練 LRM 相關的所有代碼、數據集和訓練流程。所有核心組件全部開源,開發者可無阻礙地使用、驗證和改進 AReaL。
本次最新版本「boba」的命名一方面源自團隊對珍珠奶茶的偏愛,另一面也是希望強化學習技術能如奶茶成為大眾飲品一般,滲透至 AI 開發的每個日常場景,普惠整個社區。
AReaL-boba 發佈亮點
訓練速度最快的開源框架
AReaL-boba 是首個全面擁抱 xAI 公司所採用的 SGLang 推理框架的開源訓練系統,對比初代 AReaL 訓練大幅度提升訓練吞吐:通過集成 SGLang 框架及多項工程優化,AReaL-boba 可以無縫適配各種計算資源下的強化學習訓練,實現吞吐在 1.5B 模型尺寸上速度提升 35%,在 7B 模型速度提升 60%,32B 模型速度提升 73%。
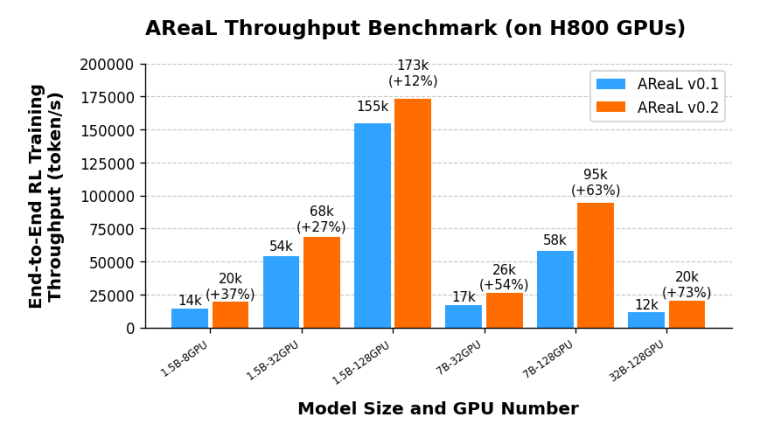 圖 1:AreaL-boba 對比初代 AReaL 訓練大幅度提升訓練吞吐
圖 1:AreaL-boba 對比初代 AReaL 訓練大幅度提升訓練吞吐使用 AReaL-boba 即可以 128 張 H800 規模在 1 天內訓練完成 SOTA 1.5B 推理模型,以 256 張 H800 規模在 2 天內完成 SOTA 7B 推理模型訓練。
AReaL 希望讓整個社區不論單機器,還是大規模分佈式訓練,都可以輕鬆高效率駕馭強化學習。
7B 模型數學推理分數斷崖領先
AReaL 團隊以 Qwen-R1-Distill-7B 模型為基礎模型,通過大規模強化學習訓練,即可在 2 天內取得領域最佳的數學推理能力,實現 AIME 2024 61.9 分、AIME 2025 48.3 分,刷新開源社區記錄,也大幅超越了 OpenAI o1-preview。相比基礎模型,AReaL-boba 通過強化學習讓模型能力實現躍升 —— 在 AIME 2024 上提升 6.9 分,在 AIME 2025 提升 8.6 分 —— 再次證明了 RL Scaling 的價值。
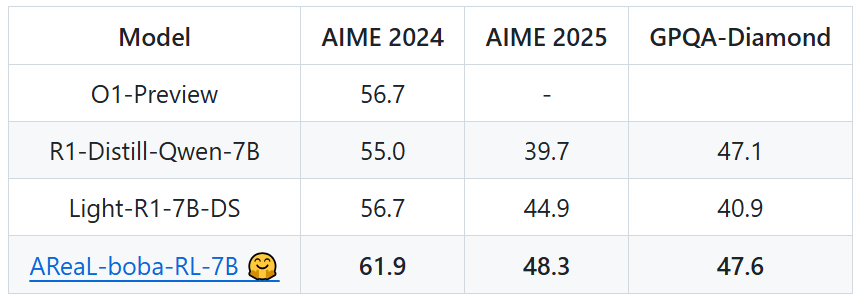 表 1: 同類參數模型的不同基準測試分數
表 1: 同類參數模型的不同基準測試分數同時 AReaL-boba 不僅開源了推理模型,也開源所有的訓練數據 AReaL-boba-106k,以及全部的訓練腳本和評估腳本,確保人人可複現。在項目官方倉庫上,AReaL 團隊也放出了極其詳細的技術筆記,總結了大量訓練中的關鍵點,包括 PPO 超參數、獎勵函數設置、正則化設置、長度上限設置等等。
通過創新性數據蒸餾技術,200 條數據複現 QwQ-32B
在 32B 模型尺寸上,AReaL 團隊進一步精簡訓練數據並發佈數據集 AReaL-boba-SFT-200 以及相關訓練腳本。基於 R1-Distill-Qwen-32B,AReaL-boba 使用僅僅 200 條數據並以輕量級 SFT 的方式,在 AIME 2024 上複刻了 QwQ-32B 的推理結果,相當於僅僅使用了 200 美金的計算成本,讓所有人都可以以極低的成本實現最強的推理訓練效果。
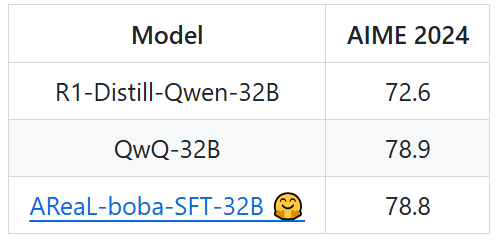 表 2:同類參數模型的 AIME 2024 分數
表 2:同類參數模型的 AIME 2024 分數結語
AReaL 團隊的核心成員均來自於螞蟻研究院強化學習實驗室以及交叉信息研究院吳翼團隊,項目也借鑒了大量優秀的開源項目,比如 DeepScaleR、SGLang、QwQ、Open-Reasoner-Zero、OpenRLHF、veRL、Light-R1 和 DAPO。作為國內第一個完整開源(數據、代碼、模型、腳本全開源)的強化學習項目團隊,AReaL 希望能真正實現 AI 訓練的普惠。
AReaL 團隊在項目列表中也列出了團隊後續的開源計劃和目標,包括異步訓練、訓練吞吐優化、數據集和算法升級,以及代碼和 Agent 智能體能力支持。讓我們期待 AReaL 團隊的下一個 release,猜猜是哪一款奶茶呢?