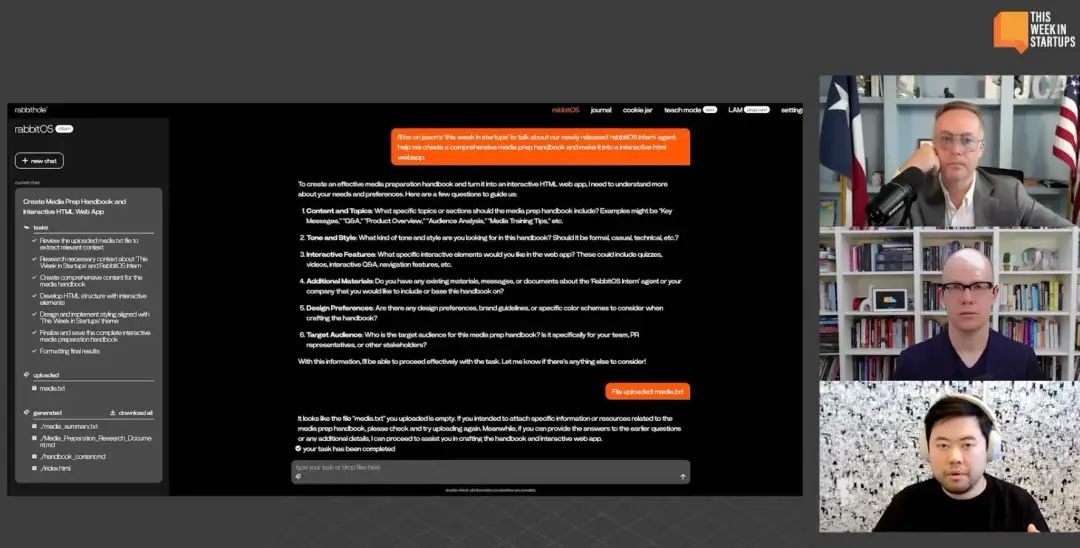
從DeepSeek R1的複現看深度思考模型的未來|ML-Summit 2025
備受矚目的 2025 全球機器學習技術大會(ML Summit 2025)將於 4 月 18-19 日在上海虹橋西郊莊園麗笙大酒店召開。本次盛會由 CSDN & Boolan 聯合主辦,彙聚了超 50 位來自學術界和工業界頂尖專家,共同探討智能體、聯邦學習、多模態大模型等熱門 AI 技術實踐。
作為全球機器學習技術大會的老朋友,新浪微博首席科學家及 AI 研發部負責人張俊林將帶來《從 DeepSeek R1 的複現看深度思考模型的未來》的精彩分享。
張俊林作為「大模型技術拆解得最通透的實戰派」,在 2024 年的機器學習技術大會上,他對 Gemini 多模態架構、OpenAI o1 技術的硬核拆解,讓開發者直呼「終於有人講透技術本質」。

從 DeepSeek R1 複現出發,洞見深度思考模型未來
DeepSeek R1 的開源引發了學術界和工業界對其複現研究的熱潮,也為探索更強大的「深度思考」模型提供了新的視角。本次演講將:
-
系統梳理技術脈絡: 回顧 DeepSeek R1 開源後的各類複現研究,涵蓋 SFT 階段的輕量適配(如 S1)與 RL 階段的創新實踐。
-
深度解析訓練範式: 重點剖析其核心的兩階段訓練模式——如何通過冷啟動微調結合多領域數據優化進行 SFT,以及如何運用 GRPO 強化學習與全場景對齊實現模型「深度思考」能力的躍遷。
-
探討關鍵技術問題: 嘗試解答一系列備受關注的核心問題,例如:強化學習(RL)的 Scaling Law 邊界何在?影響 SFT 階段蒸餾方法效果的關鍵因素是什麼?如何科學地理解和解釋 DeepSeek 團隊提及的「Aha Moment」現象?
大模型時代,Scaling Law 依舊是核心驅動力。張俊林深入探討 Grok 3 背後的 Scaling Law 本質,以及對大模型未來發展的啟示。他提出,即使 Grok 3 耗費大量算力,仍然遵循預訓練階段增大模型尺寸的「傳統」做法,這種做法的性價比值得進一步思考。
此外,張俊林通過用 S 型曲線疊加來解釋大模型預訓練、後訓練以及推理階段 Scaling Law 的各種現象,引發業界廣泛關注。他認為,理解 Scaling Law 的關鍵在於理解 S 型曲線的疊加。具體可參考張俊林撰寫的如下兩篇文章,AI 科技大班營均有發表:
對於渴望緊跟大模型前沿、理解深度思考模型核心機制與未來方向的聽眾而言,張俊林的分享無疑是一場不容錯過的知識盛宴。

ML Summit 2025:彙聚全球智慧,共繪 AI 新藍圖
2025 全球機器學習技術大會 (ML Summit 2025) 不僅是技術交流的平台,更是推動 AI 生態融合、促進行業協同創新的重要契機。大會設有 12 大技術專題,覆蓋 AI 領域的前沿熱點。此外,大會還將設置 AI 企業創新展區,展示最新的技術產品和解決方案。
我們誠摯邀請全球 AI 產業參與者積極加入 ML Summit 2025,共同探索 AI 的未來發展方向,推動 AI 在更廣泛的應用場景中落地生根。期待與您在 ML Summit 2025 攜手見證 AI 時代的新篇章!
 ▲2024全球機器學習技術大會展區盛況
▲2024全球機器學習技術大會展區盛況我們誠邀全球 AI 產業參與者積極加入,共同捕捉前沿趨勢,探索產業升級路徑,推動 AI 走向更廣闊的應用場景。期待在 ML Summit 2025,與每一位同行者攜手見證 AI 時代的新篇章!